This chapter introduces the basics of the Python environment for data science, focusing on the modularity of the language and the use of Jupyternotebooks. It presents the essentials for setting up a functional Python environment, explains the advantages of IDEs such as VSCode, and offers a hands-on introduction to interactive notebooks. The chapter also discusses error handling and the importance of ongoing training in Python, providing useful resources for staying up to date in this dynamic ecosystem.
Author
Lino Galiana
Published
2026-07-25
TipSkills you will acquire in this chapter
Understand the key aspects of Pythons modularity
Get familiar with the day-to-day working environment of a data scientist, especially the use of notebooks
Know how to approach and troubleshoot errors effectively
Recognize the importance of continuous learning in Python and discover some useful resources to support it.
1 Introduction
The richness of open-source languages comes from the ability
to use packages
developed by specialists. Python is particularly
well-endowed in this area. To caricature, it is sometimes said
that Python is the second-best language for all tasks, which makes it the best language.
Indeed, the malleability of Python means that it can be
approached in very different ways
depending on whether you are a SysAdmin, a web developer, or a
data scientist. It is this latter profile that will interest us here.
However, this richness poses a challenge when starting to
learn Python or reusing code
written by others. Proprietary statistical
languages operate in a top-down model, where, once a license is acquired,
you simply install the software and follow the documentation provided by
the developing company to proceed. In open source languages, the approach is more bottom up: the ecosystem is enriched by contributions and documentation from various sources. Several ways of doing the same thing coexist, and it is part of the work to take the time to choose the best approach.
There are primarily two ways to use Python for data science1:
Local installation: Install the Python software on your machine, configure a suitable environment (usually via Anaconda), and use a development tool, such as Jupyter or VSCode, to write and execute Python code. We will revisit these three levels of abstraction in the next section.
Using an online environment: Access a preconfigured Python environment via your browser, hosted on a remote machine. This machine will execute the code you edit from your browser. This method is particularly recommended for beginners or for those who do not want to deal with system configuration.
The second approach is related to cloud services. In the context of this course, as will be explained later, we offer two solutions: SSPCloud, a cloud developed by the French administration and provided free of charge to students, researchers, and public officials, or Google Colab.
The two methods are briefly described below. The local installation method is presented to introduce useful concepts but is not detailed as it can be complex and prone to configuration issues. If you choose this route, be prepared to encounter technical difficulties and sometimes obscure configurations, often requiring tedious searches to resolve problems that you would probably not have encountered in an online environment.
2 Ingredients for a functional Python environment
As mentioned earlier, using Python locally for data science relies on three main elements: the Python interpreter, a virtual environment, and an integrated development environment (IDE). Each of these components plays a complementary role in the development process.
2.1Python Interpreter
This refers to the programming language itself. Installing Python on your machine is the essential first step, as it provides the interpreter needed to run your Python code. At this stage, it is only the base language and a command-line tool.
NoteIllustration
If you have access to a command line in an environment where Python is available and properly configured (including being added to the PATH), you can already run Python through the command line2
An example of creating a file example.py from the command line and using it from the command line. Since creating files from the command line is not a realistic working mode, we will explain how to create files using a text editor.
2.2Python Environment
The Python language is built, like other open-source languages, with a basic core and additional packages. It is these packages that form the rich and dynamic ecosystem of Python, making it such a comfortable language.
Python is an open-source language, which means that anyone can offer their code for reuse in the form of a package. There are platforms that centralize community packages, with the main one in the Python ecosystem being PyPI.
An environment refers to the collection of packages available to Python for performing specific tasks. Python is not installed with all the packages available on PyPI, so it is up to you to enrich your environment by installing new packages as needed.
If your Python is correctly configured, you can install new packages using pip install3. We will use many packages in this course, so this command will come up regularly.
Once installed, a script must declare a package before using it (otherwise Python won’t know where to find specific functions). This is the purpose of the import command. For example, import pandas as pd allows you to use the Pandas package (provided it is already installed).
NoteIllustration
Here is an illustration of how package management works in Python
Linux terminal
1python -c "import geopandas as gpd"pip install geopandas2python -c "import geopandas as gpd ; print(gpd.GeoDataFrame)"
1
This should cause an error if GeoPandas is not installed
ModuleNotFoundError: No module named 'geopandas'
2
The error should be gone
ImportantImportant
It is discouraged to use global imports like from pkg import *. For example, consider two modules that provide a sqrt function:
# Don't do that please !from numpy import*from math import*sqrt([4, 3])
Global imports load all functions and variables from the numpy and math modules into the global namespace, which can lead to naming conflicts.
First, this can lead to unpredictable results, as if the implementations differ, how do you know whether it’s the numpy or math package function that was used? Here, it will be the math package function, imported last, which will cause an error: the math module only handles integers, not vectors, unlike numpy.
Second, it makes the code less readable, as it becomes difficult to know where each function or variable used comes from, complicating maintenance and debugging.
It is therefore preferable to import only the necessary functions or use explicit aliases, such as import numpy as np and import math, to avoid these issues.
import numpy as npfrom math import sqrtnp.sqrt([3,4])sqrt(3)
2.2.1 Development environments and notebooks
Using Python via the command line is fundamental in the application world. However, it’s impractical to write your code directly in the command line on a daily basis. Fortunately, there are suitable editors known as IDEs. These are software that provide a convenient interface for writing and executing your code. They offer features to simplify code reading and writing: syntax highlighting, autocompletion, debugging, formal code quality diagnostics, etc.
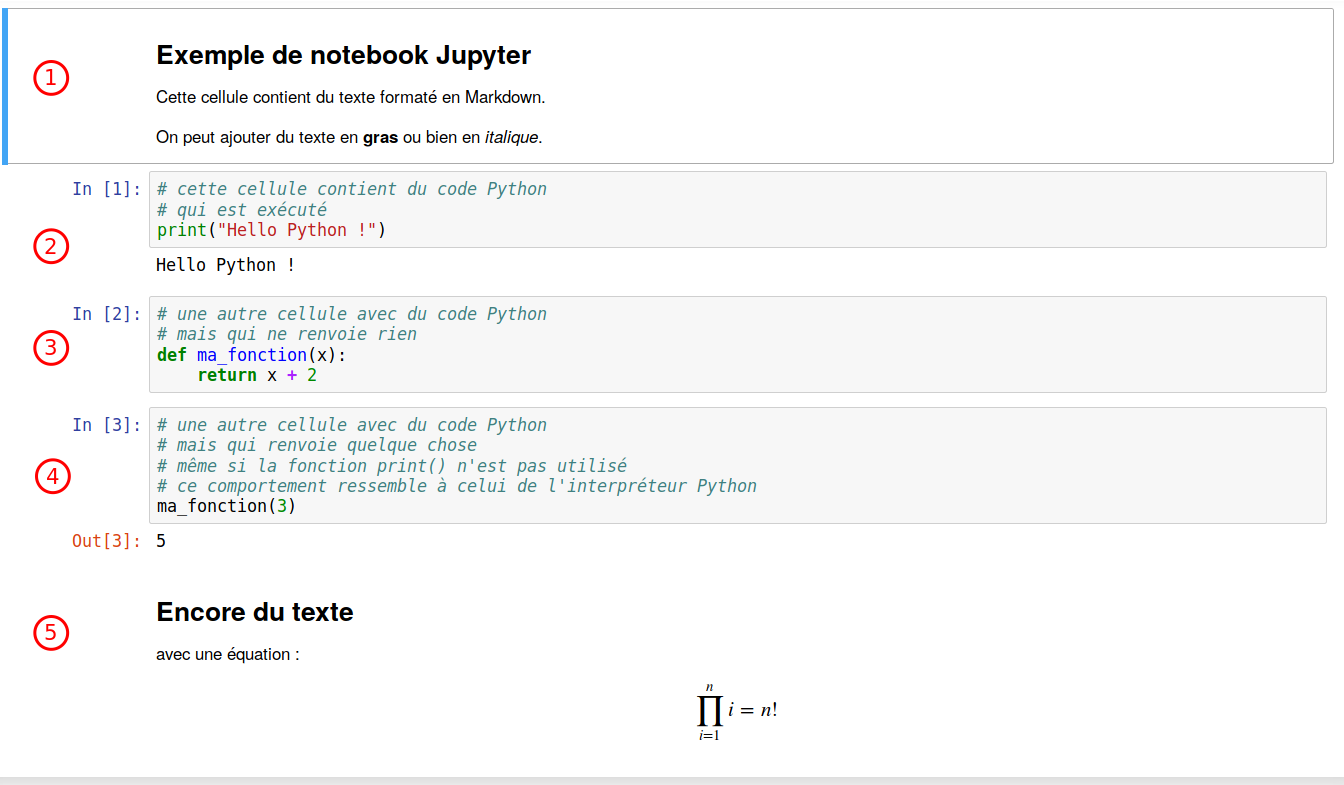
Jupyter notebooks4 offer an interactive interface that allows you to write Python code, test it, and see the result below the instruction rather than in a separate console. Jupyter notebooks are essential in the fields of data science and education and research because they greatly simplify exploration and experimentation.
They allow you to combine text in Markdown format (a lighter markup text format than HTML or \(\LaTeX\)), Python code, and HTML code for visualizations and animations in a single document.
Initially, Jupyter was the only software offering these interactive features. Now, there are other ways to benefit from notebook advantages while having an IDE with more comprehensive features than Jupyter. For this reason, as of 2024, it is more practical to use VSCode, a general-purpose code editor but offering excellent features in Python, than Jupyter. For more information on using notebooks in VSCode, refer to the official documentation.
3 Using notebooks in the context of this course
The best way to learn Python or notebooks is through practice, so all chapters of this course will be executable in notebook format. The following buttons allow you to open this chapter in notebook format in different environments:
On Github , only for viewing and downloading notebooks as Github is not a development and execution environment for notebooks;
On SSPCloud, a modern cloud platform developed by Insee and provided free of charge to public agents, students, researchers, and agents of European public statistical institutes. As mentioned in the dedicated box, this is the recommended entry point for notebooks for anyone who has access to it. Notebooks can be opened there via VSCode (recommended approach) or Jupyter, with command-line access and appropriate rights for package installation guaranteed in both interfaces. In addition to these already desirable features for discovering Python, other useful features for continuous learning are explored in more detail in the third year in the course on “Deploying Data Science Projects”: free GPU access, interfacing with other cloud technologies such as object storage systems, etc.
Google Colab is a free online service based on the Jupyter interface that provides access to Python resources run on Google’s servers.
ImportantRecommended environment for this course
For public sector employees or students from partner schools, it is recommended to use the SSPCloud button, which is a modern, powerful, and flexible cloud infrastructure developed by Insee and accessible at https://datalab.sspcloud.fr5.
As mentioned, VSCode is a much more complete environment than Jupyter for using notebooks.
4 Exercise to Explore Basic Notebook Features
All the chapters of this course are designed as a narrative aiming to address a problem with intermediate exercises serving as milestones. They are easily identifiable in the following format:
TipTip
An example of an exercise box
The following exercise aims to familiarize you with using Jupyter notebooks in Python if you are not familiar with this environment. It illustrates basic features such as writing code, executing cells, adding text, and visualizing data.
To do this, open this chapter in a notebook-compatible environment: 6
TipExercise 1
Under this exercise, create a code cell. Write a Python code that displays the phrase: “Welcome to a notebook!” and then execute the cell. Modify your code and re-run it.
By searching online, add a new cell and change its type to “Markdown”. In this cell, write a short text including the following elements:
A small part in italics
An unordered list
A level 2 heading (equivalent to <h2> in HTML or \subsection in \(\LaTeX\))
An equation
Create a code cell anywhere in the document. Create a list of integers from 1 to 10 named numbers. Display this list.
Create a new code cell. Use the code below this exercise to generate a figure.
The figure obtained at the end of the exercise will look like this:
5 How to solve errors?
Encountering errors is completely natural and expected when learning (and even after!) a programming language. Resolving these errors is a great opportunity to understand how the language works and to become self-sufficient in its use. Here is a suggested sequence of steps to follow (in this order) to resolve an error:
Read the logs carefully, i.e., the outputs returned by Python in case of an error. Often, they are informative and may contain the answer directly.
Search on the internet (preferably in English and on Google). For example, providing the error name and part of the informative error message returned by Python usually helps to orient the search results towards what you are looking for.
Often, the search will lead you to the Stackoverflow forum, which is designed for this purpose. If you really can’t find the answer to your problem, you can post on Stackoverflow by detailing the problem encountered so that forum users can reproduce it and find a solution.
Official documentation (of Python and various packages) is often a bit dry but generally exhaustive. It helps to understand how to use the various objects. For example, for functions: what they expect as input, parameters and their types, what they return as output, etc.
Code assistant AIs (ChatGPT, Github Copilot) can be very helpful. By providing them with appropriate instructions and verifying the generated code to avoid hallucinations, you can save a lot of time with these tools.
TipExercise 2: Learning by Making Mistakes
Fix the cell below so that it no longer produces an error
pd.DataFrame(x)
---------------------------------------------------------------------------NameError Traceback (most recent call last)
CellIn[4], line 1----> 1 pd.DataFrame(x)
NameError: name 'pd' is not defined
6 How to continue learning after this course
6.1 Website content
This course is an introduction to data science with Python. Most of the content is designed for those who are new to the subject or wish to explore a specific topic in this field, such as NLP.
However, this course also reflects my nearly decade-long experience 👴 with Python on various data sources, infrastructures, and problems: it is thus somewhat editorialized (“opinionated” as the Anglo-Saxons would say) to highlight certain expectations for data scientists and to help you avoid the same pitfalls I encountered in the past.
This course also provides content to go beyond the first few months of learning. Not all the content on this site is taught; some advanced sections and even chapters are intended for continuous learning and can be used several months after discovering this course.
pythonds.linogaliana.fr is continuously updated to reflect the evolving Python ecosystem. The notebooks will remain available beyond the teaching semester.
6.2 Technical monitoring
The rich and thriving Python ecosystem means you must stay attentive to its developments to avoid becoming outdated. While with monolithic languages like SAS or Stata one could rely solely on official documentation without ongoing technical monitoring, this is not feasible with Python or R. This course itself is continuously evolving, which is quite demanding 😅, to keep up with the ecosystem changes.
Social networks like LinkedIn or X, and content aggregators like Medium or Towards Data Science, offer posts of varying quality, but maintaining continuous technical monitoring on these topics is not useless: over time, it can help identify new trends. The site Real Python generally provides very good posts, comprehensive and educational. Github can also be useful for technical monitoring: by looking at trending projects, you can see the trends that will emerge soon.
Regarding printed books, some are of very high quality. However, it is important to pay attention to their update dates: the rapid pace of some elements of the ecosystem can render them outdated very quickly. It is generally more useful to have a recent but non-exhaustive post than a complete but outdated book.
TipUseful newsletters
There are many well-crafted newsletters for regularly tracking developments in the data science ecosystem. For me, they are the primary source of fresh information.
If you had to subscribe to only one newsletter, the most important to follow is Andrew Ng’s, “The Batch”. It provides reflections on academic advances in neural networks, evolution of the software and institutional ecosystem, making it an excellent food for thought.
Fairly technical, the videos by Andrej Karpathy (data scientist at OpenAI) are very informative for understanding the workings of state-of-the-art language models. Similarly, content produced by Sebastian Raschka helps in knowing the latest advancements in research on the topic.
General newsletters from Data Elixir and Alpha Signal keep you updated with the latest news. In the field of data visualization, newsletters from DataWrapper provide accessible content on the subject.
Informations additionnelles
NotePython environment
This site was built automatically through a Github action using the Quarto reproducible publishing software (version 1.8.26).
The environment used to obtain the results is reproducible via uv. The pyproject.toml file used to build this environment is available on the linogaliana/python-datascientist repository
pyproject.toml
[project]name ="python-datascientist"version ="0.1.0"description ="Source code for Lino Galiana's Python for data science course"readme ="README.md"requires-python =">=3.13,<3.14"dependencies = ["altair>=6.0.0","cartiflette","contextily==1.6.2","duckdb>=0.10.1","folium>=0.19.6","gdal==3.11.4","graphviz==0.20.3","great-tables>=0.12.0","gt-extras>=0.0.8","ipykernel>=6.29.5","jupyter>=1.1.1","jupyter-cache>=1.0.0","kaleido>=0.2.1","langchain-community>=0.3.27","loguru==0.7.3","markdown>=3.8","nbclient>=0.10.0","nbformat>=5.10.4","nltk>=3.9.1","pandas>=3.0","pip>=25.1.1","plotly>=6.1.2","plotnine>=0.15","polars>=1.8.2","pyarrow>=17.0.0","pynsee>=0.1.8","python-dotenv>=1.0.1","python-frontmatter>=1.1.0","pywaffle>=1.1.1","requests>=2.32.3","scikit-image>=0.24.0","scikit-learn>=1.8.0","scipy>=1.13.0","seaborn>=0.13.2","selenium<4.39.0","spacy>=3.8.4","webdriver-manager>=4.0.2","wordcloud==1.9.3",][tool.uv.sources]cartiflette = { git ="https://github.com/inseefrlab/cartiflette" }gdal = [ { index ="gdal-wheels", marker ="sys_platform == 'linux'" }, { index ="geospatial_wheels", marker ="sys_platform == 'win32'" },][[tool.uv.index]]name ="geospatial_wheels"url ="https://nathanjmcdougall.github.io/geospatial-wheels-index/"explicit = true[[tool.uv.index]]name ="gdal-wheels"url ="https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"explicit = true[dependency-groups]dev = ["nb-clean>=4.0.1",]
To use exactly the same environment (version of Python and packages), please refer to the documentation for uv.
NoteFile history
md`This file has been modified __${table_commit.length}__ times since its creation on ${creation_string} (last modified on ${last_modification_string})`
functionreplacePullRequestPattern(inputString, githubRepo) {// Use a regular expression to match the pattern #digitvar pattern =/#(\d+)/g;// Replace the pattern with ${github_repo}/pull/#digitvar replacedString = inputString.replace(pattern,'[#$1]('+ githubRepo +'/pull/$1)');return replacedString;}
table_commit = {// Get the HTML table by its class namevar table =document.querySelector('.commit-table');// Check if the table existsif (table) {// Initialize an array to store the table datavar dataArray = [];// Extract headers from the first rowvar headers = [];for (var i =0; i < table.rows[0].cells.length; i++) { headers.push(table.rows[0].cells[i].textContent.trim()); }// Iterate through the rows, starting from the second rowfor (var i =1; i < table.rows.length; i++) {var row = table.rows[i];var rowData = {};// Iterate through the cells in the rowfor (var j =0; j < row.cells.length; j++) {// Use headers as keys and cell content as values rowData[headers[j]] = row.cells[j].textContent.trim(); }// Push the rowData object to the dataArray dataArray.push(rowData); } }return dataArray}
// Get the element with class 'git-details'{var gitDetails =document.querySelector('.commit-table');// Check if the element existsif (gitDetails) {// Hide the element gitDetails.style.display='none'; }}
A third way to use Python, still under development, relies on a technology called WebAssembly. This approach allows executing Python code directly in the browser, offering a local execution experience without requiring complex installation.↩︎
You do not have direct access to the command line with Google Colab, only indirectly through the notebook interface by prefixing commands with !. On VSCode services provided by SSPCloud, the recommended interface for this course, you can access a command line by clicking ☰ > Terminal > New Terminal. On a personal installation of VSCode, this will be at the top in the Terminal > New Terminal menu.↩︎
More details on environments are available in the 3rd-year course “Deployment of Data Science Projects”, including different types of virtual environments (conda or venv) and their implications for Python computing chains.↩︎
Jupyter originated from the IPython project, an interactive environment for Python developed by Fernando Pérez in 2001. In 2014, the project evolved to support other programming languages in addition to Python, leading to the creation of the Jupyter project. The name “Jupyter” is an acronym referring to the three main languages it supports: Julia, Python, and R. Jupyter notebooks are crucial in the fields of data science and education and research because they greatly simplify exploration and experimentation.↩︎
For users of this infrastructure, the notebooks for this course are also listed, along with many other high-quality resources, on the Training page.↩︎
@book{galiana2025,
author = {Galiana, Lino},
title = {Python Pour La Data Science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {en}
}