import re
import pandas as pdIf you want to try the examples in this tutorial:

TipSkills you will acquire in this chapter
- Understand how regular expressions (regex) offer powerful tools for working with text, especially where simple string methods like
str.findfall short
- Master the core concepts of regex: character classes (e.g.
[a-z]), quantifiers (?,*,+,{}), anchors, and metacharacters
- Use Python’s
remodule functions—such asfindall,search,match,sub, andfinditer—to search, extract, or replace text patterns
- Apply regex effectively to tabular data using
pandasvectorized string methods likestr.contains,str.extract,str.findall,str.replace, andstr.count
- Practice these skills through hands-on exercises such as extracting dates from text or pulling out email addresses and publication years from a DataFrame
1 Introduction
Python offers a lot of very useful functionalities for handling textual data. This is one of the reasons for its success in the natural language processing (NLP) community (see the dedicated section).
In previous chapters, we sometimes needed to search for basic textual elements. This was possible with the str.find method from the Pandas package, which is a vectorized version of the basic find method. We could also use the basic method directly, especially when performing web scraping.
However, this search function quickly reaches its limits. For instance, if we want to find both the singular and plural occurrences of a term, we will need to use the find method at least twice. For conjugated verbs, it becomes even more complex, especially if their form changes according to the subject.
For complicated expressions, it is advisable to use regular expressions or “regex”. This is a feature found in many programming languages. It is a form of grammar that allows for searching for patterns.
Part of the content in this section is an adaptation of the
collaborative documentation on R called utilitR to which I contributed. This chapter also draws from the book R for Data Science which presents a very pedagogical chapter on regex.
We will use the package re to illustrate our examples of regular expressions. This is the reference package used by Pandas in the background to vectorize text searches.
TipTip
Regular expressions (regex) are notoriously difficult to master. There are tools that make working with regular expressions easier.
The reference tool for this is [https://regex101.com/] which allows you to test
regexinPythonwith an explanation accompanying the test.Similarly, this site has a cheat sheet at the bottom of the page.
The Regex Crossword games allow you to learn regular expressions while having fun.
It can be useful to ask assistant AIs, such as Github Copilot or ChatGPT, for a first version of a regex by explaining the content you want to extract. This can save a lot of time, except when the AI is overconfident and offers you a completely wrong regex…
2 Principle
Regular expressions are a tool used to describe a set of possible strings according to a precise syntax, and thus define a pattern. Regular expressions are used, for example, when you want to extract a part of a string or replace a part of a string. A regular expression takes the form of a string, which can contain both literal elements and special characters with logical meaning.
For example, "ch.+n" is a regular expression that describes the following pattern: the literal string ch, followed by any string of at least one character (.+), followed by the letter n. In the string "J'ai un chien.", the substring "chien" matches this pattern. The same goes for "chapeau ron" in "J'ai un chapeau rond". In contrast, in the string "La soupe est chaude.", no substring matches this pattern (because no n appears after the ch).
To convince ourselves, we can look at the first two cases:
pattern = "ch.+n"
print(re.search(pattern, "La soupe est chaude."))NoneIn the previous example, we had two adjacent quantifiers .+. The first (.) means any character1. The second (+) means “repeat the previous pattern”. In our case, the combination .+ allows us to repeat any character before finding an n. The number of times is indeterminate: it may not be necessary to intersperse characters before the n or it may be necessary to capture several:
print(re.search(pattern, "J'ai un chino"))
print(re.search(pattern, "J'ai un chiot très mignon."))<re.Match object; span=(8, 12), match='chin'>
<re.Match object; span=(8, 25), match='chiot très mignon'>2.1 Character classes
When searching, we are interested in characters and often in character classes: we look for a digit, a letter, a character in a specific set, or a character that does not belong to a specific set. Some sets are predefined, others must be defined using brackets.
To define a character set, you need to write this set within brackets. For example, [0123456789] denotes a digit. Since it is a sequence of consecutive characters, we can summarize this notation as [0-9].
For example, if we want to find all patterns that start with a c followed by an h and then a vowel (a, e, i, o, u), we can try this regular expression:
re.findall("[c][h][aeiou]", "chat, chien, veau, vache, chèvre")['cha', 'chi', 'che']It would be more practical to use Pandas in this case to isolate the lines that meet the logical condition (by adding the accents that are otherwise not included):
import pandas as pd
txt = pd.Series("chat, chien, veau, vache, chèvre".split(", "))
txt.str.match("ch[aeéèiou]")0 True
1 True
2 False
3 False
4 True
dtype: boolHowever, the usage of character classes as shown above is not the most common. They are preferred for identifying complex patterns rather than a sequence of literal characters. Memory aid tables illustrate some of the most common character classes ([:digit:] or \d…)
2.2 Quantifiers
We encountered quantifiers with our first regular expression. They control the number of times a pattern is matched.
The most common are:
?: 0 or 1 match;+: 1 or more matches;*: 0 or more matches.
For example, colou?r will match both the American and British spellings:
re.findall("colou?r", "Did you write color or colour?")['color', 'colour']These quantifiers can of course be combined with other types of characters, especially character classes. This can be extremely useful. For example, \d+ will capture one or more digits, \s? will optionally add a space, [\w]{6,8} will match a word between six and eight letters.
It is also possible to define the number of repetitions with {}:
{n}matches exactly n times;{n,}matches at least n times;{n,m}matches between n and m times.
However, the repetition of terms by default only applies to the last character preceding the quantifier. We can confirm this with the example above:
print(re.match("toc{4}","toctoctoctoc"))NoneTo address this issue, parentheses are used. The principle is the same as with numeric rules: parentheses allow for introducing hierarchy. To revisit the previous example, we get the expected result thanks to the parentheses:
print(re.match("(toc){4}","toctoctoctoc"))
print(re.match("(toc){5}","toctoctoctoc"))
print(re.match("(toc){2,4}","toctoctoctoc"))<re.Match object; span=(0, 12), match='toctoctoctoc'>
None
<re.Match object; span=(0, 12), match='toctoctoctoc'>
NoteNote
The regular expression algorithm always tries to match the largest piece to the regular expression.
For example, consider an HTML string:
s = "<h1>Super titre HTML</h1>"The regular expression re.findall("<.*>", s) potentially matches three pieces:
<h1></h1><h1>Super titre HTML</h1>
It is the last one that will be chosen, as it is the largest. To select the smallest, you need to write the quantifiers like this: *?, +?. Here are a few examples:
s = "<h1>Super titre HTML</h1>\n<p><code>Python</code> est un langage très flexible</p>"
print(re.findall("<.*>", s))
print(re.findall("<p>.*</p>", s))
print(re.findall("<p>.*?</p>", s))
print(re.compile("<.*?>").findall(s))['<h1>Super titre HTML</h1>', '<p><code>Python</code> est un langage très flexible</p>']
['<p><code>Python</code> est un langage très flexible</p>']
['<p><code>Python</code> est un langage très flexible</p>']
['<h1>', '</h1>', '<p>', '<code>', '</code>', '</p>']2.3 Cheat sheet
The table below serves as a cheat sheet for regex:
| Regular expression | Meaning |
|---|---|
"^" |
Start of the string |
"$" |
End of the string |
"\\." |
A dot |
"." |
Any character |
".+" |
Any non-empty sequence of characters |
".*" |
Any sequence of characters, possibly empty |
"[:alnum:]" |
An alphanumeric character |
"[:alpha:]" |
A letter |
"[:digit:]" |
A digit |
"[:lower:]" |
A lowercase letter |
"[:punct:]" |
A punctuation mark |
"[:space:]" |
A space |
"[:upper:]" |
An uppercase letter |
"[[:alnum:]]+" |
A sequence of at least one alphanumeric character |
"[[:alpha:]]+" |
A sequence of at least one letter |
"[[:digit:]]+" |
A sequence of at least one digit |
"[[:lower:]]+" |
A sequence of at least one lowercase letter |
"[[:punct:]]+" |
A sequence of at least one punctuation mark |
"[[:space:]]+" |
A sequence of at least one space |
"[[:upper:]]+" |
A sequence of at least one uppercase letter |
"[[:alnum:]]*" |
A sequence of alphanumeric characters, possibly empty |
"[[:alpha:]]*" |
A sequence of letters, possibly empty |
"[[:digit:]]*" |
A sequence of digits, possibly empty |
"[[:lower:]]*" |
A sequence of lowercase letters, possibly empty |
"[[:upper:]]*" |
A sequence of uppercase letters, possibly empty |
"[[:punct:]]*" |
A sequence of punctuation marks, possibly empty |
"[^[:alpha:]]+" |
A sequence of at least one character that is not a letter |
"[^[:digit:]]+" |
A sequence of at least one character that is not a digit |
"\|" |
Either the expression x or y is present |
[abyz] |
One of the specified characters |
[abyz]+ |
One or more of the specified characters (possibly repeated) |
[^abyz] |
None of the specified characters are present |
Some character classes have lighter syntax because they are very common. Among them:
| Regular expression | Meaning |
|---|---|
\d |
Any digit |
\D |
Any character that is not a digit |
\s |
Any space (space, tab, newline) |
\S |
Any character that is not a space |
\w |
Any word character (letters and numbers) |
\W |
Any non-word character (letters and numbers) |
In the following exercise, you will be able to practice the previous examples on a slightly more complete regex. This exercise does not require knowledge of the nuances of the re package; you will only need re.findall.
This exercise will use the following string:
s = """date 0 : 14/9/2000
date 1 : 20/04/1971 date 2 : 14/09/1913 date 3 : 2/3/1978
date 4 : 1/7/1986 date 5 : 7/3/47 date 6 : 15/10/1914
date 7 : 08/03/1941 date 8 : 8/1/1980 date 9 : 30/6/1976"""
s'date 0 : 14/9/2000\ndate 1 : 20/04/1971 date 2 : 14/09/1913 date 3 : 2/3/1978\ndate 4 : 1/7/1986 date 5 : 7/3/47 date 6 : 15/10/1914\ndate 7 : 08/03/1941 date 8 : 8/1/1980 date 9 : 30/6/1976'
TipExercise 1
- First, extract the day of birth.
- The first digit of the day is 0, 1, 2, or 3. Translate this into a
[X-X]sequence. - The second digit of the day is between 0 and 9. Translate this into the appropriate sequence.
- Note that the first digit of the day is optional. Insert the appropriate quantifier between the two character classes.
- Add the slash after the pattern.
- Test with
re.findall. You should get many more matches than needed. This is normal; at this stage, the regex is not yet finalized.
- The first digit of the day is 0, 1, 2, or 3. Translate this into a
- Follow the same logic for the months, noting that Gregorian calendar months never exceed the first dozen. Test with
re.findall. - Do the same for the birth years, noting that, unless proven otherwise, for people alive today, the relevant millennia are limited. Test with
re.findall. - This regex is not natural; one could be satisfied with generic character classes
\d, even though they might practically select impossible birth dates (e.g.,43/78/4528). This would simplify the regex, making it more readable. Don’t forget the usefulness of quantifiers. - How can the regex be adapted to always be valid for our cases but also capture dates of the type
YYYY/MM/DD? Test with1998/07/12.
At the end of question 1, you should have this result:
['14/',
'9/',
'20/',
'04/',
'14/',
'09/',
'2/',
'3/',
'1/',
'7/',
'7/',
'3/',
'15/',
'10/',
'08/',
'03/',
'8/',
'1/',
'30/',
'6/']At the end of question 2, you should have this result, which is starting to take shape:
['14/9',
'20/04',
'14/09',
'2/3',
'1/7',
'7/3',
'15/10',
'08/03',
'8/1',
'30/6']At the end of question 3, you should be able to extract the dates:
['14/9/2000',
'20/04/1971',
'14/09/1913',
'2/3/1978',
'1/7/1986',
'7/3/47',
'15/10/1914',
'08/03/1941',
'8/1/1980',
'30/6/1976']If all goes well, by question 5, your regex should work:
['14/9/2000',
'20/04/1971',
'14/09/1913',
'2/3/1978',
'1/7/1986',
'7/3/47',
'15/10/1914',
'08/03/1941',
'8/1/1980',
'30/6/1976',
'1998/07/12']3 Main re functions
Here is a summary table of the main functions of the re package with examples.
We have mainly used re.findall so far, which is one of the most practical functions in the package. re.sub and re.search are also quite useful. The others are less critical but can be helpful in specific cases.
| Function | Purpose |
|---|---|
re.match(<regex>, s) |
Find and return the first match of the regular expression <regex> from the beginning of the string s |
re.search(<regex>, s) |
Find and return the first match of the regular expression <regex> regardless of its position in the string s |
re.finditer(<regex>, s) |
Find and return an iterator storing all matches of the regular expression <regex> regardless of their position(s) in the string s. Typically, a loop is performed over this iterator |
re.findall(<regex>, s) |
Find and return all matches of the regular expression <regex> regardless of their position(s) in the string s as a list |
re.sub(<regex>, new_text, s) |
Find and replace all matches of the regular expression <regex> regardless of their position(s) in the string s |
To illustrate these functions, here are some examples:
Example of re.match 👇
re.match can only capture a pattern at the start of a string. Its utility is thus limited. Let’s capture toto:
re.match("(to){2}", "toto at the beach")<re.Match object; span=(0, 4), match='toto'>Example of re.search 👇
re.search is more powerful than re.match, allowing capture of terms regardless of their position in a string. For example, to capture age:
re.search("age", "toto is of age to go to the beach")<re.Match object; span=(11, 14), match='age'>And to capture exclusively “age” at the end of the string:
re.search("age$", "toto is of age to go to the beach")Example of re.finditer 👇
re.finditer is, in my opinion, less practical than re.findall. Its main use compared to re.findall is capturing the position within a text field:
s = "toto is of age to go to the beach"
for match in re.finditer("age", s):
start = match.start()
end = match.end()
print(f'String match "{s[start:end]}" at {start}:{end}')String match "age" at 11:14Example of re.sub 👇
re.sub allows capturing and replacing expressions. For example, let’s replace “age” with “âge”. But be careful, you don’t want to do this when the pattern is present in “beach”. So, we’ll add a negative condition: capture “age” only if it is not at the end of the string (which translates to regex as ?!$).
re.sub("age(?!$)", "âge", "toto a l'age d'aller à la plage")"toto a l'âge d'aller à la plage"
TipWhen to use re.compile and raw strings?
re.compile can be useful when you use a regular expression multiple times in your code. It allows you to compile the regular expression into an object recognized by re, which can be more efficient in terms of performance when the regular expression is used repeatedly or on large data sets.
Raw strings (raw string) are special strings in Python that start with r. For example, r"toto at the beach". They can be useful to prevent escape characters from being interpreted by Python. For instance, if you want to search for a string containing a backslash \ in a string, you need to use a raw string to prevent the backslash from being interpreted as an escape character (\t, \n, etc.). The tester https://regex101.com/ also assumes you are using raw strings, so it can be useful to get used to them.
4 Generalization with Pandas
Pandas methods are extensions of those in re that avoid looping to check each line with a regex. In practice, when working with DataFrames, the pandas API is preferred over re. Code of the form df.apply(lambda x: re.<function>(<regex>,x), axis = 1) should be avoided as it is very inefficient.
The names sometimes change slightly compared to their re equivalents.
| Method | Description |
|---|---|
str.count() |
Count the number of occurrences of the pattern in each line |
str.replace() |
Replace the pattern with another value. Vectorized version of re.sub() |
str.contains() |
Test if the pattern appears, line by line. Vectorized version of re.search() |
str.extract() |
Extract groups that match a pattern and return them in a column |
str.findall() |
Find and return all occurrences of a pattern. If a line contains multiple matches, a list is returned. Vectorized version of re.findall() |
Additionally, there are str.split() and str.rsplit() methods which are quite useful.
Example of str.count 👇
You can count the number of times a pattern appears with str.count:
df = pd.DataFrame({"a": ["toto", "titi"]})
df['a'].str.count("to")0 2
1 0
Name: a, dtype: int64Example of str.replace 👇
Replace the pattern “ti” at the end of the string:
df = pd.DataFrame({"a": ["toto", "titi"]})
df['a'].str.replace("ti$", " punch")0 toto
1 titi
Name: a, dtype: strExample of str.contains 👇
Check the cases where our line ends with “ti”:
df = pd.DataFrame({"a": ["toto", "titi"]})
df['a'].str.contains("ti$")0 False
1 True
Name: a, dtype: boolExample of str.findall 👇
df = pd.DataFrame({"a": ["toto", "titi"]})
df['a'].str.findall("to")0 [to, to]
1 []
Name: a, dtype: object
WarningWarning
Currently, it is not necessary to add the regex = True argument, but this should be the case in a future version of pandas. It might be worth getting into the habit of adding it.
5 For more information
- Collaborative documentation on
RnamedutilitR - R for Data Science
- Regular Expression HOWTO in the official
Pythondocumentation - The reference tool [https://regex101.com/] for testing regular expressions
- This site which has a cheat sheet at the bottom of the page.
- The games on Regex Crossword allow you to learn regular expressions while having fun
6 Additional exercises
6.1 Extracting email addresses
This is a classic use of regex
text_emails = 'Hello from toto@gmail.com to titi.grominet@yahoo.com about the meeting @2PM'
TipExercise 2: Extracting email addresses
Use the structure of an email address [XXXX]@[XXXX] to retrieve this content.
['toto@gmail.com', 'titi.grominet@yahoo.com']6.2 Extracting years from a pandas DataFrame
The general objective of the exercise is to clean columns in a DataFrame using regular expressions.
TipExercise 3
The dataset in question contains books from the British Library and some related information. The dataset is available here: https://raw.githubusercontent.com/realpython/python-data-cleaning/master/Datasets/BL-Flickr-Images-Book.csv
The “Date of Publication” column is not always a year; sometimes there are other details. The goal of the exercise is to have a clean book publication date and to examine the distribution of publication years.
To do this, you can:
Either choose to perform the exercise without help. Your reading of the instructions ends here. You should carefully examine the dataset and transform it yourself.
Or follow the step-by-step instructions below.
Guided version 👇
- Read the data from the URL
https://raw.githubusercontent.com/realpython/python-data-cleaning/master/Datasets/BL-Flickr-Images-Book.csv. Be careful with the separator. - Keep only the columns
['Identifier', 'Place of Publication', 'Date of Publication', 'Publisher', 'Title', 'Author']. - Observe the ‘Date of Publication’ column and note the issues with some rows (e.g., row 13).
- Start by looking at the number of missing values. We cannot do better after regex, and normally we should not have fewer…
- Determine the regex pattern for a publication date. Presumably, there are 4 digits forming a year. Use the
str.extract()method with theexpand = Falseargument (to keep only the first date matching our pattern)? - We have 2
NaNvalues that were not present at the start of the exercise. What are they and why? - What is the distribution of publication dates in the dataset? You can, for example, display a histogram using the
plotmethod with thekind = "hist"argument.
Here is an example of the problem to detect in question 3:
| Date of Publication | Title | |
|---|---|---|
| 13 | 1839, 38-54 | De Aardbol. Magazijn van hedendaagsche land- e... |
| 14 | 1897 | Cronache Savonesi dal 1500 al 1570 ... Accresc... |
| 15 | 1865 | See-Saw; a novel ... Edited [or rather, writte... |
| 16 | 1860-63 | Géodésie d'une partie de la Haute Éthiopie,... |
| 17 | 1873 | [With eleven maps.] |
| 18 | 1866 | [Historia geográfica, civil y politica de la ... |
| 19 | 1899 | The Crisis of the Revolution, being the story ... |
Question 4 answer should be
np.int64(181)With our regex (question 5), we obtain a DataFrame that is more in line with our expectations:
| Date of Publication | year | |
|---|---|---|
| 0 | 1879 [1878] | 1879 |
| 7 | NaN | NaN |
| 13 | 1839, 38-54 | 1839 |
| 16 | 1860-63 | 1860 |
| 23 | 1847, 48 [1846-48] | 1847 |
| ... | ... | ... |
| 8278 | 1883, [1884] | 1883 |
| 8279 | 1898-1912 | 1898 |
| 8283 | 1831, 32 | 1831 |
| 8284 | [1806]-22 | 1806 |
| 8286 | 1834-43 | 1834 |
1759 rows × 2 columns
As for the new NaN values, they are rows that did not contain any strings resembling years:
| Date of Publication | year | |
|---|---|---|
| 1081 | 112. G. & W. B. Whittaker | NaN |
| 7391 | 17 vols. University Press | NaN |
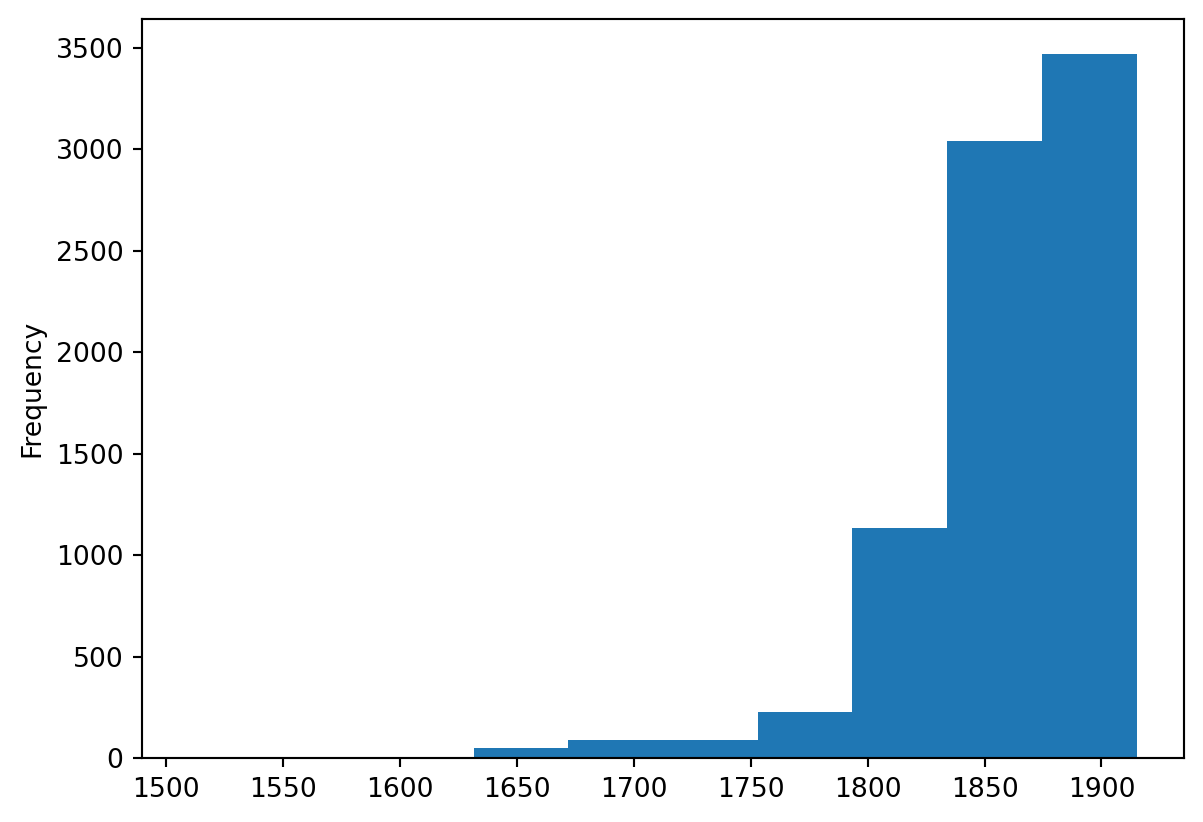
Finally, we obtain the following histogram of publication dates:
Informations additionnelles
NotePython environment
This site was built automatically through a Github action using the Quarto
The environment used to obtain the results is reproducible via uv. The pyproject.toml file used to build this environment is available on the linogaliana/python-datascientist repository
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
To use exactly the same environment (version of Python and packages), please refer to the documentation for uv.
NoteFile history
| SHA | Date | Author | Description |
|---|---|---|---|
| d555fa72 | 2025-09-24 08:39:27 | lgaliana | warninglang partout |
| 794ce14a | 2025-09-15 16:21:42 | lgaliana | retouche quelques abstracts |
| c3d51646 | 2025-08-12 17:28:51 | Lino Galiana | Ajoute un résumé au début de chaque chapitre (première partie) (#634) |
| 94648290 | 2025-07-22 18:57:48 | Lino Galiana | Fix boxes now that it is better supported by jupyter (#628) |
| 91431fa2 | 2025-06-09 17:08:00 | Lino Galiana | Improve homepage hero banner (#612) |
| 3f1d2f3f | 2025-03-15 15:55:59 | Lino Galiana | Fix problem with uv and malformed files (#599) |
| 6c6dfe52 | 2024-12-20 13:40:33 | lgaliana | eval false for API chapter |
| 9d8e69c3 | 2024-10-21 17:10:03 | lgaliana | update badges shortcode for all manipulation part |
| 1953609d | 2024-08-12 16:18:19 | linogaliana | One button is enough |
| c3f6cbc8 | 2024-08-12 12:18:22 | linogaliana | Correction LUA filters |
| f4e08292 | 2024-08-12 14:12:06 | Lino Galiana | Traduction chapitre regex (#539) |
| 0d4cf51e | 2024-08-08 06:58:53 | linogaliana | restore URL regex chapter |
| 580cba77 | 2024-08-07 18:59:35 | Lino Galiana | Multilingual version as quarto profile (#533) |
| 101465fb | 2024-08-07 13:56:35 | Lino Galiana | regex, webscraping and API chapters in 🇬🇧 (#532) |
| 065b0abd | 2024-07-08 11:19:43 | Lino Galiana | Nouveaux callout dans la partie manipulation (#513) |
| 06d003a1 | 2024-04-23 10:09:22 | Lino Galiana | Continue la restructuration des sous-parties (#492) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 3fba6124 | 2023-12-17 18:16:42 | Lino Galiana | Remove some badges from python (#476) |
| a06a2689 | 2023-11-23 18:23:28 | Antoine Palazzolo | 2ème relectures chapitres ML (#457) |
| 69cf52bd | 2023-11-21 16:12:37 | Antoine Palazzolo | [On-going] Suggestions chapitres modélisation (#452) |
| 889a71ba | 2023-11-10 11:40:51 | Antoine Palazzolo | Modification TP 3 (#443) |
| a7711832 | 2023-10-09 11:27:45 | Antoine Palazzolo | Relecture TD2 par Antoine (#418) |
| 154f09e4 | 2023-09-26 14:59:11 | Antoine Palazzolo | Des typos corrigées par Antoine (#411) |
| 9a4e2267 | 2023-08-28 17:11:52 | Lino Galiana | Action to check URL still exist (#399) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| 130ed717 | 2023-07-18 19:37:11 | Lino Galiana | Restructure les titres (#374) |
| f0c583c0 | 2023-07-07 14:12:22 | Lino Galiana | Images viz (#371) |
| ef28fefd | 2023-07-07 08:14:42 | Lino Galiana | Listing pour la première partie (#369) |
| f21a24d3 | 2023-07-02 10:58:15 | Lino Galiana | Pipeline Quarto & Pages 🚀 (#365) |
| 62b2a7c2 | 2022-12-28 15:00:50 | Lino Galiana | Suite chapitre regex (#340) |
| 3c880d59 | 2022-12-27 17:34:59 | Lino Galiana | Chapitre regex + Change les boites dans plusieurs chapitres (#339) |
| f10815b5 | 2022-08-25 16:00:03 | Lino Galiana | Notebooks should now look more beautiful (#260) |
| 494a85ae | 2022-08-05 14:49:56 | Lino Galiana | Images featured ✨ (#252) |
| d201e3cd | 2022-08-03 15:50:34 | Lino Galiana | Pimp la homepage ✨ (#249) |
| 12965bac | 2022-05-25 15:53:27 | Lino Galiana | :launch: Bascule vers quarto (#226) |
| 9c71d6e7 | 2022-03-08 10:34:26 | Lino Galiana | Plus d’éléments sur S3 (#218) |
| 9a3f7ad8 | 2021-10-31 18:36:25 | Lino Galiana | Nettoyage partie API + Git (#170) |
| 2a8809fb | 2021-10-27 12:05:34 | Lino Galiana | Simplification des hooks pour gagner en flexibilité et clarté (#166) |
| b138cf3e | 2021-10-21 18:05:59 | Lino Galiana | Mise à jour TP webscraping et API (#164) |
| 2e4d5862 | 2021-09-02 12:03:39 | Lino Galiana | Simplify badges generation (#130) |
| a5f48243 | 2021-07-16 14:20:27 | Lino Galiana | Exo supplémentaire webscraping marmiton 🍝 (#121) (#124) |
| 4cdb759c | 2021-05-12 10:37:23 | Lino Galiana | :sparkles: :star2: Nouveau thème hugo :snake: :fire: (#105) |
| 6d010fa2 | 2020-09-29 18:45:34 | Lino Galiana | Simplifie l’arborescence du site, partie 1 (#57) |
| 66f9f87a | 2020-09-24 19:23:04 | Lino Galiana | Introduction des figures générées par python dans le site (#52) |
| 5c1e76d9 | 2020-09-09 11:25:38 | Lino Galiana | Ajout des éléments webscraping, regex, API (#21) |
Footnotes
Any character except for the newline (
\n). Keep this in mind; I have already spent hours trying to understand why my.did not capture what I wanted spanning multiple lines…↩︎
Citation
BibTeX citation:
@book{galiana2025,
author = {Galiana, Lino},
title = {Python Pour La Data Science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {en}
}
For attribution, please cite this work as:
Galiana, Lino. 2025. Python Pour La Data Science. https://doi.org/10.5281/zenodo.8229676.