!pip install pywaffle
!pip install spacy
!pip install plotnine
!pip install great_tables
!pip install wordcloudPour essayer les exemples présents dans ce tutoriel :

1 Introduction
1.1 Rappel
Comme évoqué dans l’introduction de cette partie sur le traitement automatique du langage, l’objectif principal des techniques que nous allons explorer est la représentation synthétique du langage.
Le natural language processing (NLP) ou traitement automatisé du langage (TAL) en Français, vise à extraire de l’information de textes à partir d’une analyse statistique du contenu. Cette définition permet d’inclure de nombreux champs d’applications au sein du NLP (traduction, analyse de sentiment, recommandation, surveillance, etc. ).
Cette approche implique de transformer un texte, qui est une information compréhensible par un humain, en un nombre, information appropriée pour un ordinateur dans le cadre d’une approche statistique ou algorithmique.
Transformer une information textuelle en valeurs numériques propres à une analyse statistique n’est pas une tâche évidente. Les données textuelles sont non structurées puisque l’information cherchée, qui est propre à chaque analyse, est perdue au milieu d’une grande masse d’informations qui doit, de plus, être interprétée dans un certain contexte (un même mot ou une phrase n’ayant pas la même signification selon le contexte).
Si cette tâche n’était pas assez difficile comme ça, on peut ajouter d’autres difficultés propres à l’analyse textuelle car ces données sont :
- bruitées : ortographe, fautes de frappe…
- changeantes : la langue évolue avec de nouveaux mots, sens…
- complexes : structures variables, accords…
- ambiguës : synonymie, polysémie, sens caché…
- propres à chaque langue : il n’existe pas de règle de passage unique entre deux langues
- de grande dimension : des combinaisons infinies de séquences de mots
1.2 Objectif du chapitre
Dans ce chapitre, nous allons nous restreindre aux méthodes fréquentistes dans le paradigme bag of words. Celles-ci sont un peu old school par rapport aux approches plus raffinées que nous évoquerons ultérieurement. Néanmoins, les présenter nous permettra d’évoquer un certain nombre d’enjeux typiques des données textuelles qui restent centraux dans le NLP moderne.
Le principal enseignement à retenir de cette partie est que les données textuelles étant à très haute dimension - le langage étant un objet riche - nous avons besoin de méthodes pour réduire le bruit de nos corpus textuels afin de mieux prendre en compte le signal en leur sein.
Cette partie est une introduction s’appuyant sur quelques ouvrages classiques de la littérature française ou anglo-saxonne. Seront notamment présentées quelques librairies faisant parti de la boite à outil minimale des data scientists: NLTK et SpaCy. Les chapitres suivants permettront de se focaliser sur la modélisation du langage.
NoteLa librairie SpaCy
NTLK est la librairie historique d’analyse textuelle en Python. Elle existe
depuis les années 1990. L’utilisation industrielle du NLP dans le monde
de la data science est néanmoins plus récente et doit beaucoup à la collecte
accrue de données non structurées par les réseaux sociaux. Cela a amené à
un renouvellement du champ du NLP, tant dans le monde de la recherche que dans
sa mise en application dans l’industrie de la donnée.
Le package spaCy est l’un des packages qui a permis
cette industrialisation des méthodes de NLP. Conçu autour du concept
de pipelines de données, il est beaucoup plus pratique à mettre en oeuvre
pour une chaîne de traitement de données textuelles mettant en oeuvre
plusieurs étapes de transformation des données.
1.3 Méthode
L’analyse textuelle vise à transformer le texte en données numériques manipulables. Pour cela il est nécessaire de se fixer une unité sémantique minimale. Cette unité textuelle peut être le mot ou encore une séquence de n mots (un ngram) ou encore une chaîne de caractères (e.g. la ponctuation peut être signifiante). On parle de token.
On peut ensuite utiliser diverses techniques (clustering, classification supervisée) suivant l’objectif poursuivi pour exploiter l’information transformée. Mais les étapes de nettoyage de texte sont indispensables. Sinon un algorithme sera incapable de détecter une information pertinente dans l’infini des possibles.
Les packages suivants seront utiles au cours de ce chapitre:
2 Bases d’exemple
2.1 Le Comte de Monte Cristo
La base d’exemple est le Comte de Monte Cristo d’Alexandre Dumas. Il est disponible gratuitement sur le site http://www.gutenberg.org (Project Gutemberg) comme des milliers d’autres livres du domaine public.
La manière la plus simple de le récupérer
est de télécharger avec le package request le fichier texte et le retravailler
légèrement pour ne conserver que le corpus du livre :
import requests
import re
url = "https://www.gutenberg.org/files/17989/17989-0.txt"
response = requests.get(url)
response.encoding = 'utf-8' # Assure le bon décodage
raw = response.text
dumas = (
raw
.split("*** START OF THE PROJECT GUTENBERG EBOOK 17989 ***")[1]
.split("*** END OF THE PROJECT GUTENBERG EBOOK 17989 ***")[0]
1)
def clean_text(text):
text = text.lower() # mettre les mots en minuscule
text = " ".join(text.split())
return text
dumas = clean_text(dumas)
dumas[10000:10500]- 1
- On extrait de manière un petit peu simpliste le contenu de l’ouvrage
" mes yeux. --vous avez donc vu l'empereur aussi? --il est entré chez le maréchal pendant que j'y étais. --et vous lui avez parlé? --c'est-à-dire que c'est lui qui m'a parlé, monsieur, dit dantès en souriant. --et que vous a-t-il dit? --il m'a fait des questions sur le bâtiment, sur l'époque de son départ pour marseille, sur la route qu'il avait suivie et sur la cargaison qu'il portait. je crois que s'il eût été vide, et que j'en eusse été le maître, son intention eût été de l'acheter; mais je lu"2.2 Le corpus anglo-saxon
Nous allons utiliser une base anglo-saxonne présentant trois auteurs de la littérature fantastique:
- Edgar Allan Poe, (EAP) ;
- HP Lovecraft (HPL) ;
- Mary Wollstonecraft Shelley (MWS).
Les données sont disponibles sur un CSV mis à disposition sur Github. L’URL pour les récupérer directement est
https://github.com/GU4243-ADS/spring2018-project1-ginnyqg/raw/master/data/spooky.csv.
Le fait d’avoir un corpus confrontant plusieurs auteurs nous permettra de comprendre la manière dont les nettoyages de données textuelles favorisent les analyses comparatives.
Nous pouvons utiliser le code suivant pour lire et préparer ces données:
import pandas as pd
url='https://github.com/GU4243-ADS/spring2018-project1-ginnyqg/raw/master/data/spooky.csv'
#1. Import des données
horror = pd.read_csv(url,encoding='latin-1')
#2. Majuscules aux noms des colonnes
horror.columns = horror.columns.str.capitalize()
#3. Retirer le prefixe id
horror['ID'] = horror['Id'].str.replace("id","")
horror = horror.set_index('Id')Le jeu de données met ainsi en regard un auteur avec une phrase qu’il a écrite :
horror.head()| Text | Author | ID | |
|---|---|---|---|
| Id | |||
| id26305 | This process, however, afforded me no means of... | EAP | 26305 |
| id17569 | It never once occurred to me that the fumbling... | HPL | 17569 |
| id11008 | In his left hand was a gold snuff box, from wh... | EAP | 11008 |
| id27763 | How lovely is spring As we looked from Windsor... | MWS | 27763 |
| id12958 | Finding nothing else, not even gold, the Super... | HPL | 12958 |
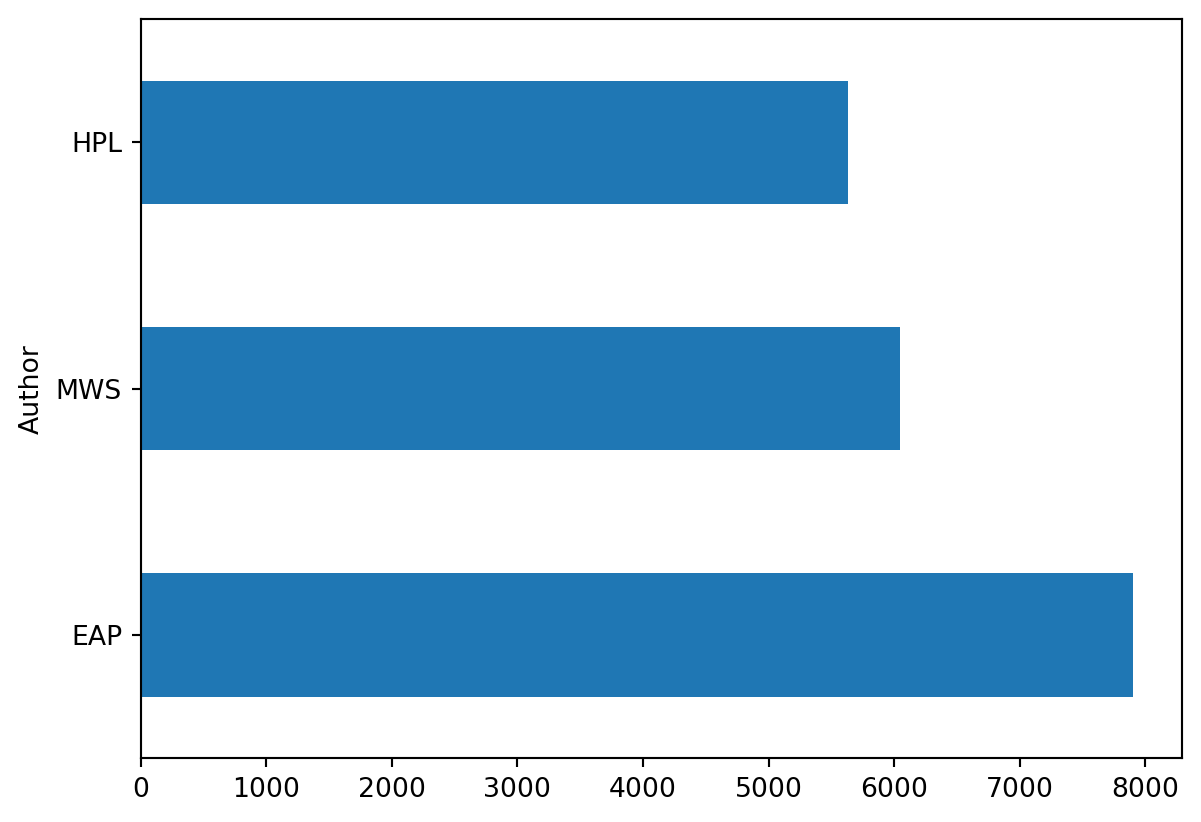
On peut se rendre compte que les extraits des 3 auteurs ne sont pas forcément équilibrés dans le jeu de données. Si on utilise ultérieurement ce corpus pour de la modélisation, il sera nécessaire de tenir compte de ce déséquilibre.
(
horror
.value_counts('Author')
.plot(kind = "barh")
)
3 Premières analyses de fréquence
L’approche usuelle en statistique, qui consiste à faire une analyse descriptive avant de mettre en oeuvre une modélisation, s’applique également à l’analyse de données textuelles. La fouille de documents textuels implique ainsi, en premier lieu, une analyse statistique afin de déterminer la structure du corpus.
Avant de s’adonner à une analyse systématique du champ lexical de chaque auteur, on va se focaliser dans un premier temps sur un unique mot, le mot fear.
3.1 Exploration ponctuelle
AstuceTip
L’exercice ci-dessous présente une représentation graphique nommée waffle chart. Il s’agit d’une approche préférable aux camemberts (pie chart) qui sont des graphiques manipulables car l’oeil humain se laisse facilement berner par cette représentation graphique qui ne respecte pas les proportions.
AstuceExercice 1 : Fréquence d’un mot
Dans un premier temps, nous allons nous concentrer sur notre corpus anglo-saxon (horror)
- Compter le nombre de phrases, pour chaque auteur, où apparaît le mot
fear. - Utiliser
pywafflepour obtenir les graphiques ci-dessous qui résument de manière synthétique le nombre d’occurrences du mot “fear” par auteur. - Refaire l’analyse avec le mot “horror”.
Le comptage obtenu devrait être le suivant
| wordtoplot | |
|---|---|
| Author | |
| EAP | 70 |
| HPL | 160 |
| MWS | 211 |
Ceci permet d’obtenir le waffle chart suivant :
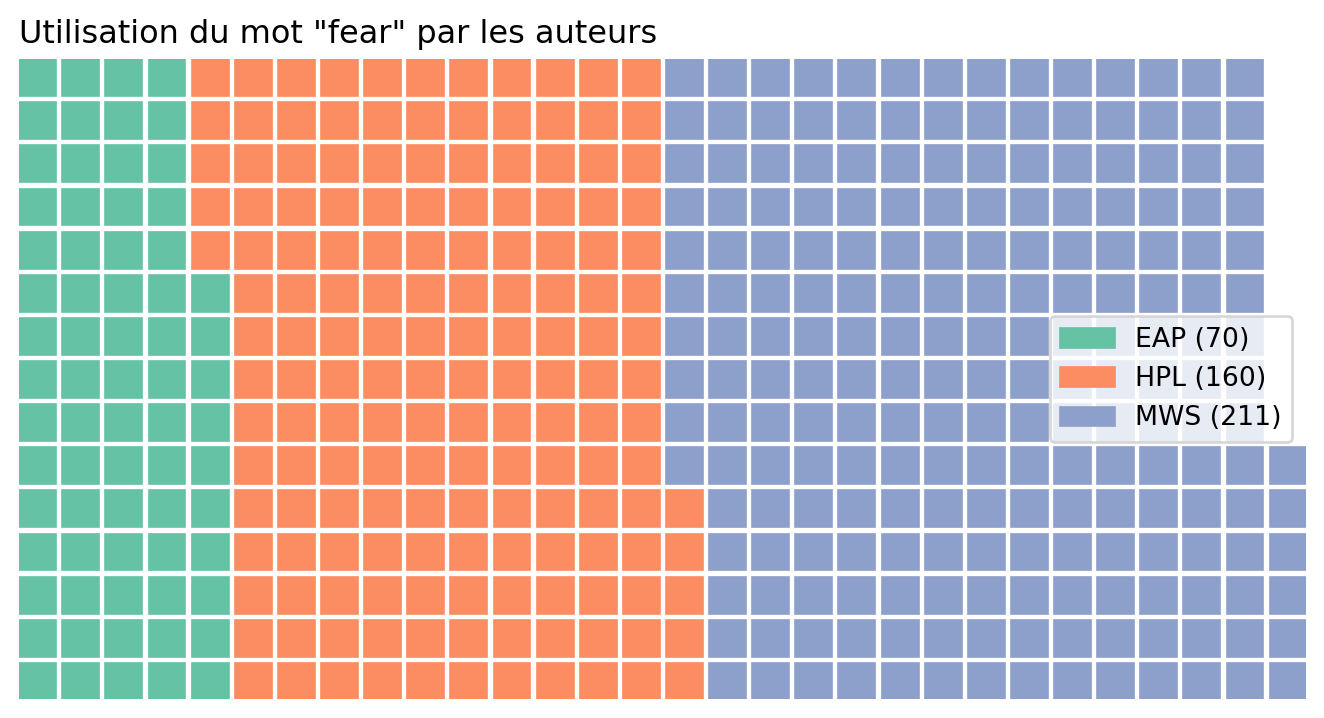
On remarque ainsi de manière très intuitive le déséquilibre de notre jeu de données lorsqu’on se focalise sur le terme “peur” où Mary Shelley représente près de 50% des observations.
Si on reproduit cette analyse avec le terme “horror”, on retrouve la figure suivante:
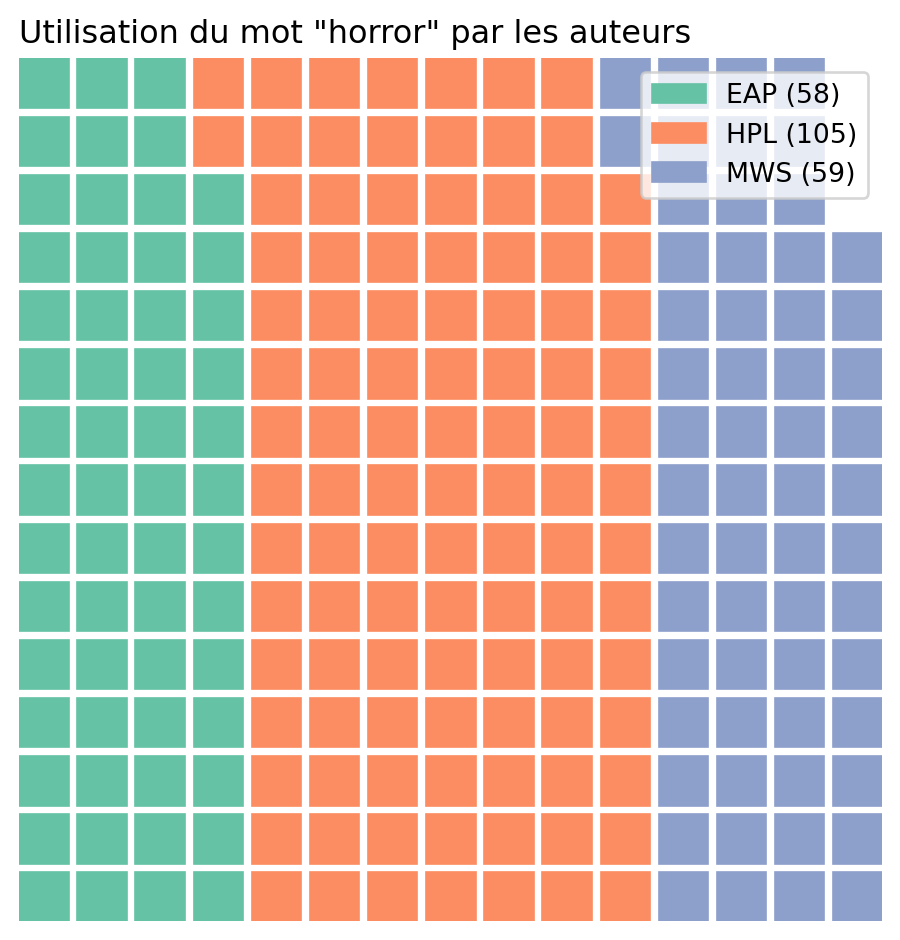
3.2 Transformation d’un texte en tokens
Dans l’exercice précédent, nous faisions une recherche ponctuelle, qui ne passe pas vraiment à l’échelle. Pour généraliser cette approche, on découpe généralement un corpus en unités sémantiques indépendantes : les tokens.
AstuceTip
Nous allons avoir besoin d’importer un certain nombre de corpus prêts à l’emploi pour utiliser les librairies NTLK ou SpaCy. Les instructions ci-dessous permettront de récupérer toutes ces ressources
Pour récupérer tous nos corpus NLTK prêts à l’emploi, nous faisons
import nltk
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('punkt_tab')
nltk.download('genesis')
nltk.download('wordnet')
nltk.download('omw-1.4')En ce qui concerne SpaCy, il est nécessaire d’utiliser
la ligne de commande:
!python -m spacy download fr_core_news_sm
!python -m spacy download en_core_web_smPlutôt que d’implémenter soi-même un tokenizer inefficace, il est plus approprié d’en appliquer un issu d’une librairie spécialisée. Historiquement, le plus simple était de prendre le tokenizer de NLTK, la librairie historique de text mining en Python:
from nltk.tokenize import word_tokenize
word_tokenize(dumas[10000:10500])Comme on le voit, cette librairie ne fait pas les choses dans le détail et a quelques incohérences: j'y étais est séparé en 4 sèmes (['j', "'", 'y', 'étais']) là où l'acheter reste un unique sème. NLTK est en effet une librairie anglo-saxonne et l’algorithme de séparation n’est pas toujours adapté aux règles grammaticales françaises. Il vaut mieux dans ce cas privilégier SpaCy, la librairie plus récente pour faire ce type de tâche. En plus d’être très bien documentée, elle est mieux adaptée pour les langues non anglo-saxonnes. En l’occurrence, comme le montre l’exemple de la documentation sur les tokenizers, l’algorithme de séparation présente un certain raffinement
 Celui-ci peut être appliqué de cette manière:
Celui-ci peut être appliqué de cette manière:
import spacy
from spacy.tokenizer import Tokenizer
nlp = spacy.load("fr_core_news_sm")
doc = nlp(dumas[10000:10500])
text_tokenized = []
for token in doc:
text_tokenized += [token.text]
", ".join(text_tokenized)" , mes, yeux, ., --vous, avez, donc, vu, l', empereur, aussi, ?, --il, est, entré, chez, le, maréchal, pendant, que, j', y, étais, ., --et, vous, lui, avez, parlé, ?, --c', est, -, à, -, dire, que, c', est, lui, qui, m', a, parlé, ,, monsieur, ,, dit, dantès, en, souriant, ., --et, que, vous, a, -t, -il, dit, ?, --il, m', a, fait, des, questions, sur, le, bâtiment, ,, sur, l', époque, de, son, départ, pour, marseille, ,, sur, la, route, qu', il, avait, suivie, et, sur, la, cargaison, qu', il, portait, ., je, crois, que, s', il, eût, été, vide, ,, et, que, j', en, eusse, été, le, maître, ,, son, intention, eût, été, de, l', acheter, ;, mais, je, lu"Comme on peut le voir, il reste encore beaucoup d’éléments polluants notre structuration de corpus, à commencer par la ponctuation. Nous allons néanmoins pouvoir facilement retirer ceux-ci ultérieurement, comme nous le verrons.
3.3 Le nuage de mot: une première analyse généralisée
A ce stade, nous n’avons encore aucune appréhension de la structure de notre corpus : nombre de mots, mots les plus représentés, etc.
Pour se faire une idée de la structure de notre corpus, on peut commencer par compter la distribution des mots dans l’oeuvre de Dumas. Commençons par le début de l’oeuvre, à savoir les 30 000 premiers mots et comptons les mots uniques :
from collections import Counter
doc = nlp(dumas[:30000])
# Extract tokens, convert to lowercase and filter out punctuation and spaces
tokens = [token.text.lower() for token in doc if not token.is_punct and not token.is_space]
# Count the frequency of each token
token_counts = Counter(tokens)Nous avons déjà de nombreux mots différents dans le début de l’oeuvre.
len(token_counts)1401Nous voyons la haute dimensionnalité du corpus puisque nous avons près de 1500 mots différents sur les 30 000 premiers mots de l’oeuvre de Dumas.
token_count_all = list(token_counts.items())
# Create a DataFrame from the list of tuples
token_count_all = pd.DataFrame(token_count_all, columns=['word', 'count'])Si on regarde la distribution de la fréquence des mots, exercice que nous prolongerons ultérieurement en évoquant la loi de Zipf, nous pouvons voir que de nombreux mots sont unique (près de la moitié des mots), que la densité de fréquence descend vite et qu’il faudrait se concentrer un peu plus sur la queue de distribution que ne le permet la figure suivante :
from plotnine import *
(
ggplot(token_count_all) +
geom_histogram(aes(x = "count")) +
scale_x_log10()
)/home/runner/work/python-datascientist/python-datascientist/.venv/lib/python3.13/site-packages/plotnine/stats/stat_bin.py:112: PlotnineWarning: 'stat_bin()' using 'bins = 42'. Pick better value with 'binwidth'.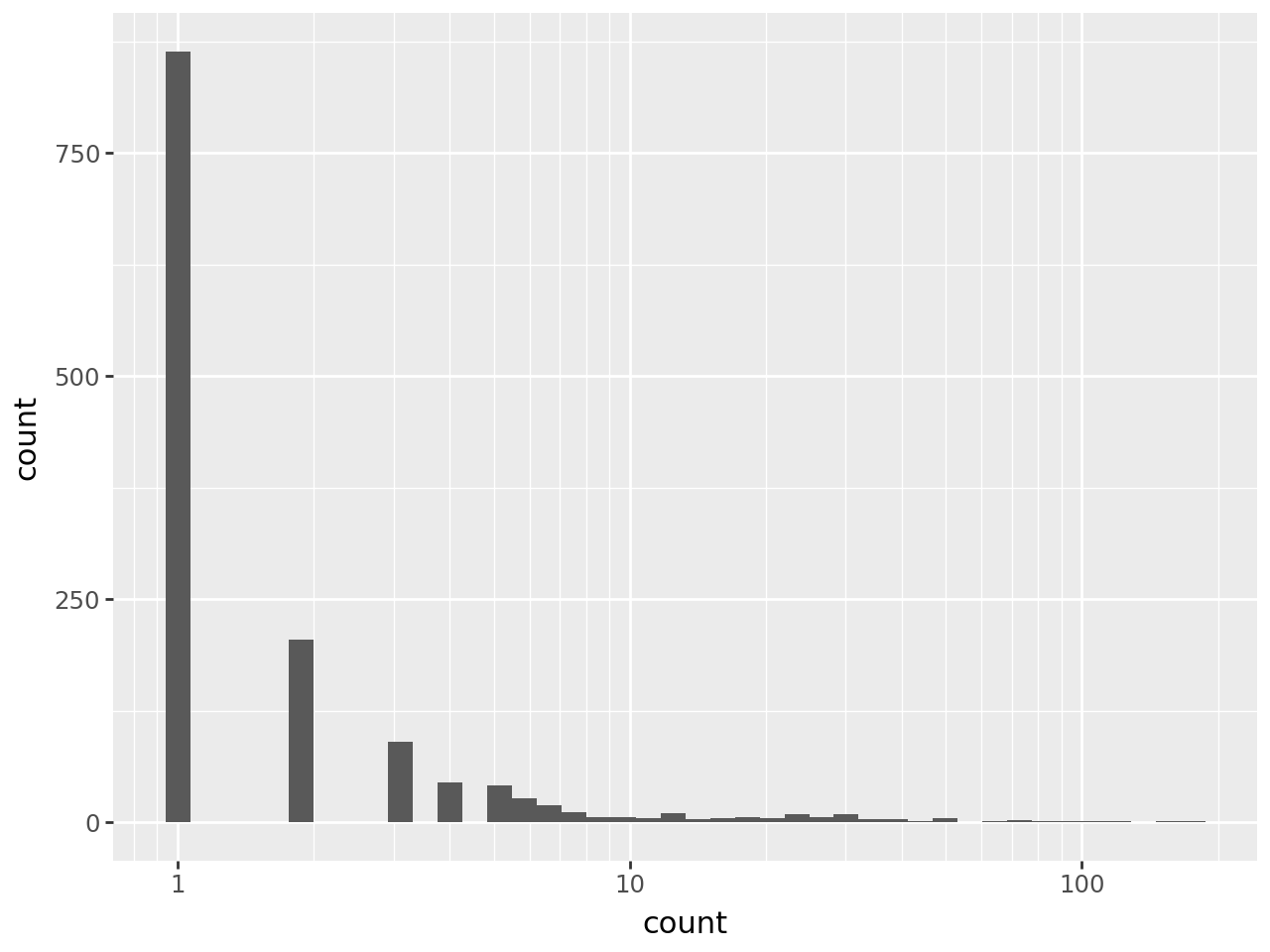
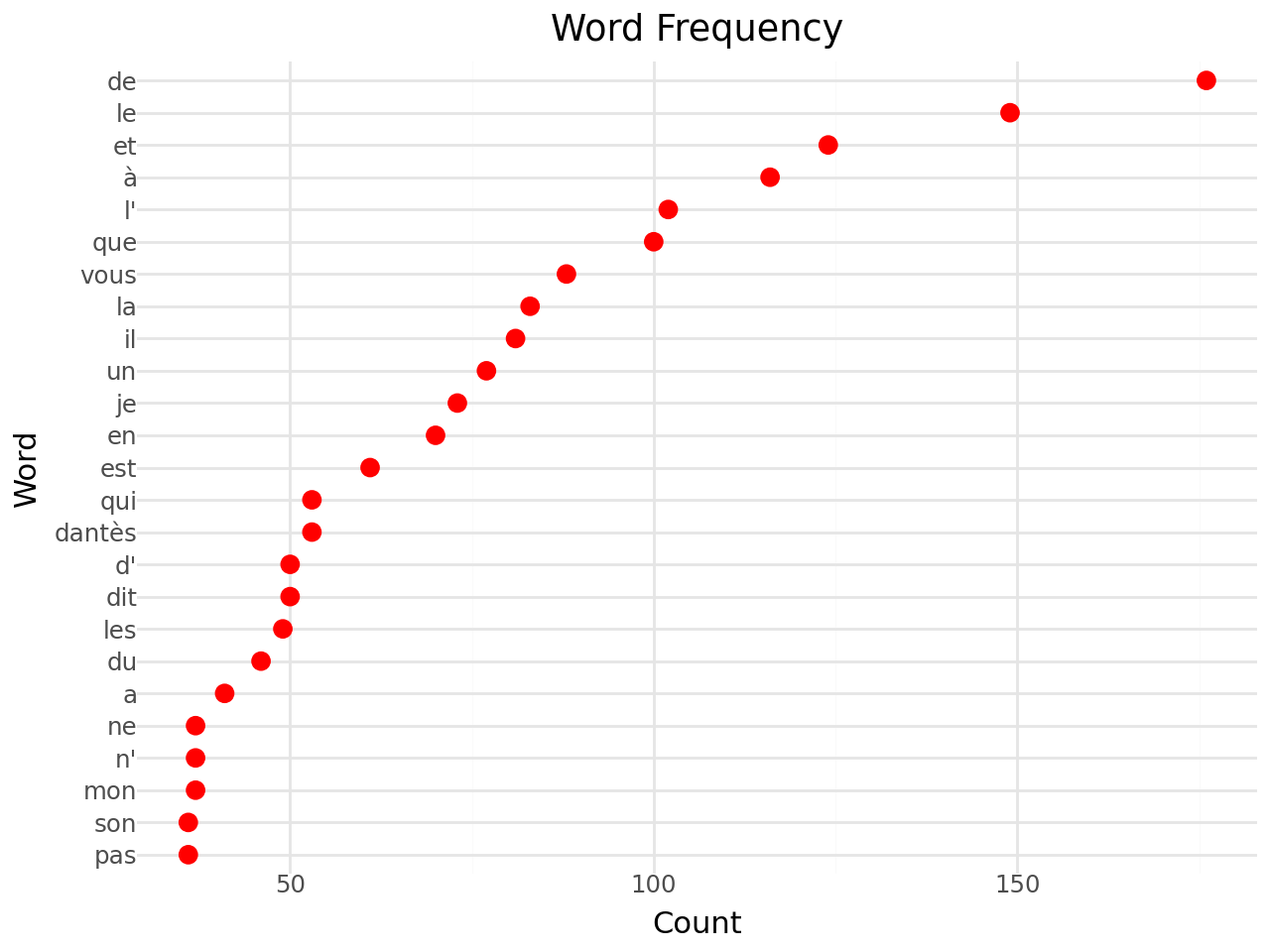
Maintenant, si on regarde les 25 mots les plus fréquents, on peut voir que ceux-ci ne sont pas très intéressants pour analyser le sens de notre document :
# Sort the tokens by frequency in descending order
sorted_token_counts = token_counts.most_common(25)
sorted_token_counts = pd.DataFrame(sorted_token_counts, columns=['word', 'count'])| Mot | Nombre d'occurrences | |
|---|---|---|
| de | 176 | |
| le | 149 | |
| et | 124 | |
| à | 116 | |
| l' | 102 | |
| que | 100 | |
| vous | 88 | |
| la | 83 | |
| il | 81 | |
| un | 77 | |
| je | 73 | |
| en | 70 | |
| est | 61 | |
| qui | 53 | |
| dantès | 53 | |
| d' | 50 | |
| dit | 50 | |
| les | 49 | |
| du | 46 | |
| a | 41 | |
| ne | 37 | |
| n' | 37 | |
| mon | 37 | |
| son | 36 | |
| pas | 36 | |
| Nombre d'apparitions sur les 30 000 premiers caractères du Comte de Monte Cristo | ||
Si on représente graphiquement ce classement
(
ggplot(sorted_token_counts, aes(x='word', y='count')) +
geom_point(stat='identity', size = 3, color = "red") +
scale_x_discrete(
limits=sorted_token_counts.sort_values("count")["word"].tolist()
) +
coord_flip() +
theme_minimal() +
labs(title='Word Frequency', x='Word', y='Count')
)
Nous nous concentrerons ultérieurement sur ces mots-valises car il sera important d’en tenir compte pour les analyses approfondies de nos documents.
Nous avons pu, par ces décomptes de mots, avoir une première intutition de la nature de notre corpus. Néanmoins, une approche un peu plus visuelle serait pertinente pour avoir un peu plus d’intuitions.
Les nuages de mots (wordclouds) sont des représentations graphiques assez pratiques pour visualiser
les mots les plus fréquents, lorsqu’elles ne sont pas utilisées à tort et à travers.
Les wordclouds sont très simples à implémenter en Python
avec le module Wordcloud. Quelques paramètres de mise en forme
permettent même d’ajuster la forme du nuage à
une image.
AstuceExercice 2 : Wordcloud
- En utilisant la fonction
wordCloud, faire trois nuages de mot pour représenter les mots les plus utilisés par chaque auteur du corpushorror1. - Faire un nuage de mot du corpus
dumasen utilisant un masque comme celui-ci
Exemple de masque pour la question 2

Les nuages de points obtenus à la question 1 sont les suivants:
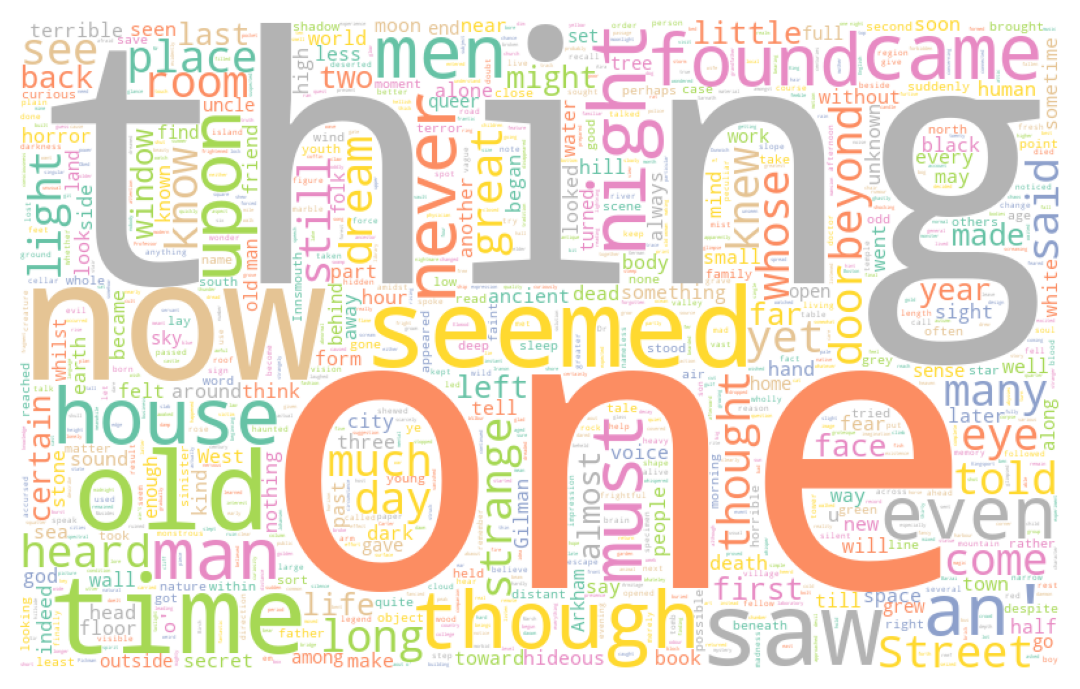
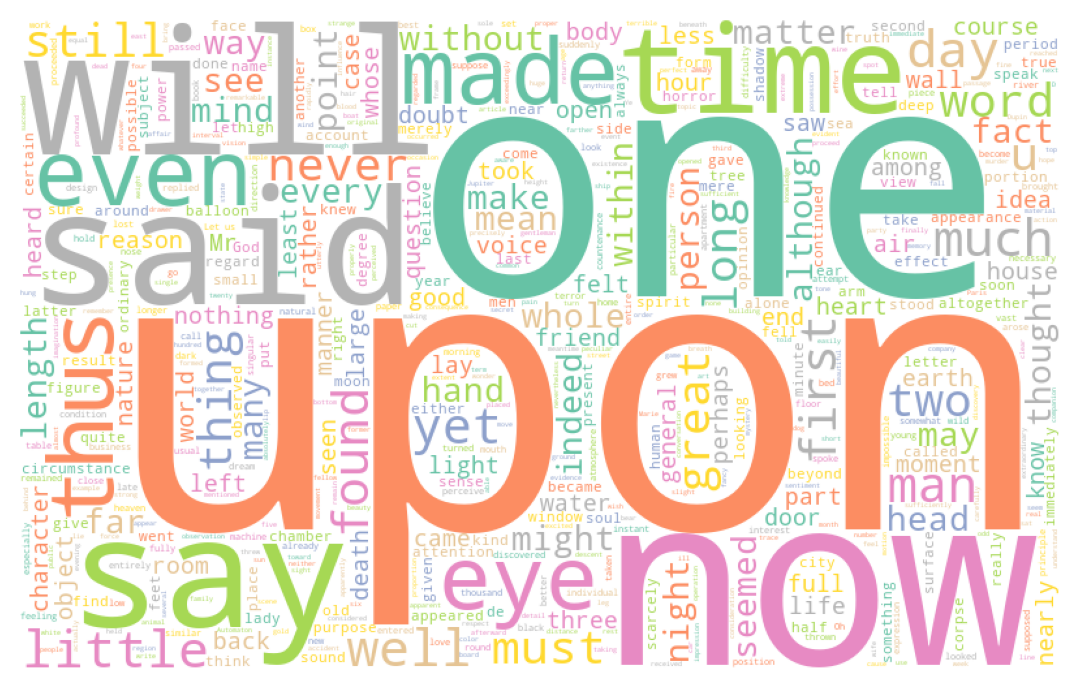
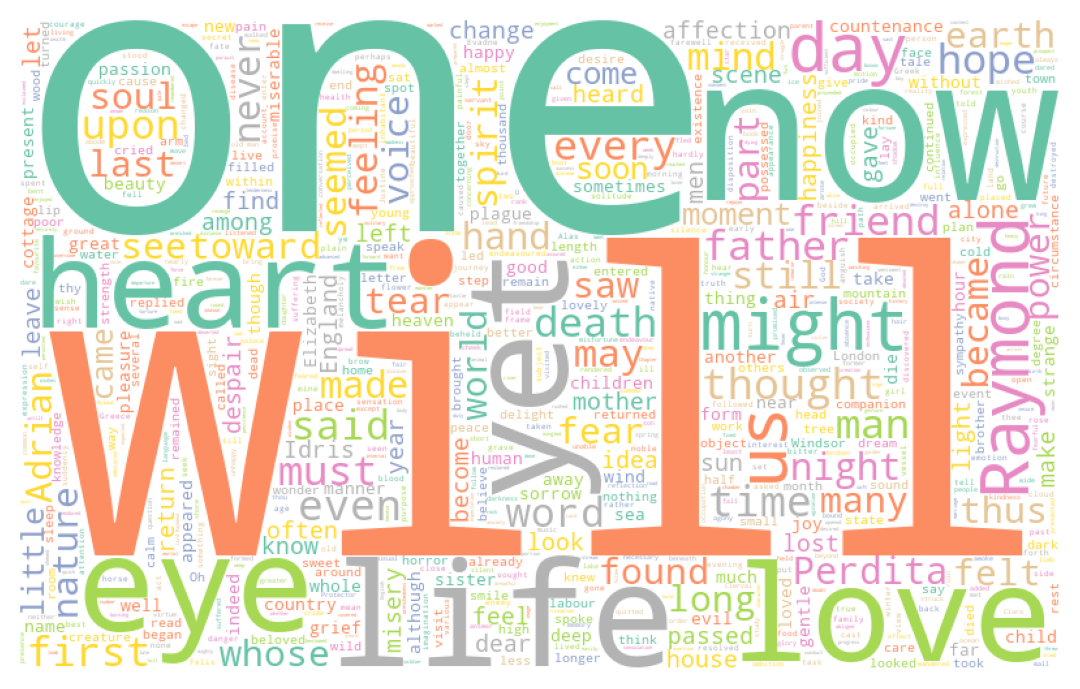
Alors que celui obtenu à partir de l’oeuvre de Dumas prend la forme

Si nous n’en étions pas convaincus, ces visualisations montrent clairement qu’il est nécessaire de nettoyer notre texte. Par exemple, en ce qui concerne l’oeuvre du Dumas, le nom du personnage principal, Dantès, est ainsi masqué par un certain nombre d’articles ou mots de liaison qui perturbent l’analyse. En ce qui concerne le corpus anglo-saxon, ce sont des termes similaires, comme “the”, “of”, etc.
Ces mots sont des stop words. Ceci est une démonstration par l’exemple qu’il vaut mieux nettoyer le texte avant de l’analyser (sauf si on est intéressé par la loi de Zipf, cf. exercice suivant).
3.4 Aparté: la loi de Zipf
Zipf, dans les années 1930, a remarqué une régularité statistique dans Ulysse, l’oeuvre de Joyce. Le mot le plus fréquent apparaissait \(x\) fois, le deuxième mot le plus fréquent 2 fois moins, le suivant 3 fois moins que le premier, etc. D’un point de vue statistique, cela signifie que la fréquence d’occurrence \(f(n_i)\) d’un mot est liée à son rang \(n_i\) dans l’ordre des fréquences par une loi de la forme
\[f(n_i) = c/n_i\]
où \(c\) est une constante.
Plus généralement, on peut dériver la loi de Zipf d’une distribution exponentiellement décroissante des fréquences : \(f(n_i) = cn_{i}^{-k}\). Sur le plan empirique, cela signifie qu’on peut utiliser les régressions poissonniennes pour estimer les paramètres de la loi, ce qui prend la spécification suivante
\[ \mathbb{E}\bigg( f(n_i)|n_i \bigg) = \exp(\beta_0 + \beta_1 \log(n_i)) \]
Les modèles linéaires généralisés (GLM) permettent de faire ce type de régression. En Python, ils sont disponibles par le biais du package statsmodels, dont les sorties sont très inspirées des logiciels payants spécialisés dans l’économétrie comme Stata.
count_words = pd.DataFrame({'counter' : horror
.groupby('Author')
.apply(lambda s: ' '.join(s['Text']).split())
.apply(lambda s: Counter(s))
.apply(lambda s: s.most_common())
.explode()}
)
count_words[['word','count']] = pd.DataFrame(count_words['counter'].tolist(), index=count_words.index)
count_words = count_words.reset_index()
count_words = count_words.assign(
tot_mots_auteur = lambda x: (x.groupby("Author")['count'].transform('sum')),
freq = lambda x: x['count'] / x['tot_mots_auteur'],
rank = lambda x: x.groupby("Author")['count'].transform('rank', ascending = False)
)Commençons par représenter la relation entre la fréquence et le rang:
from plotnine import *
g = (
ggplot(count_words) +
geom_point(aes(y = "freq", x = "rank", color = 'Author'), alpha = 0.4) +
scale_x_log10() + scale_y_log10() +
theme_minimal()
)Nous avons bien, graphiquement, une relation log-linéaire entre les deux :
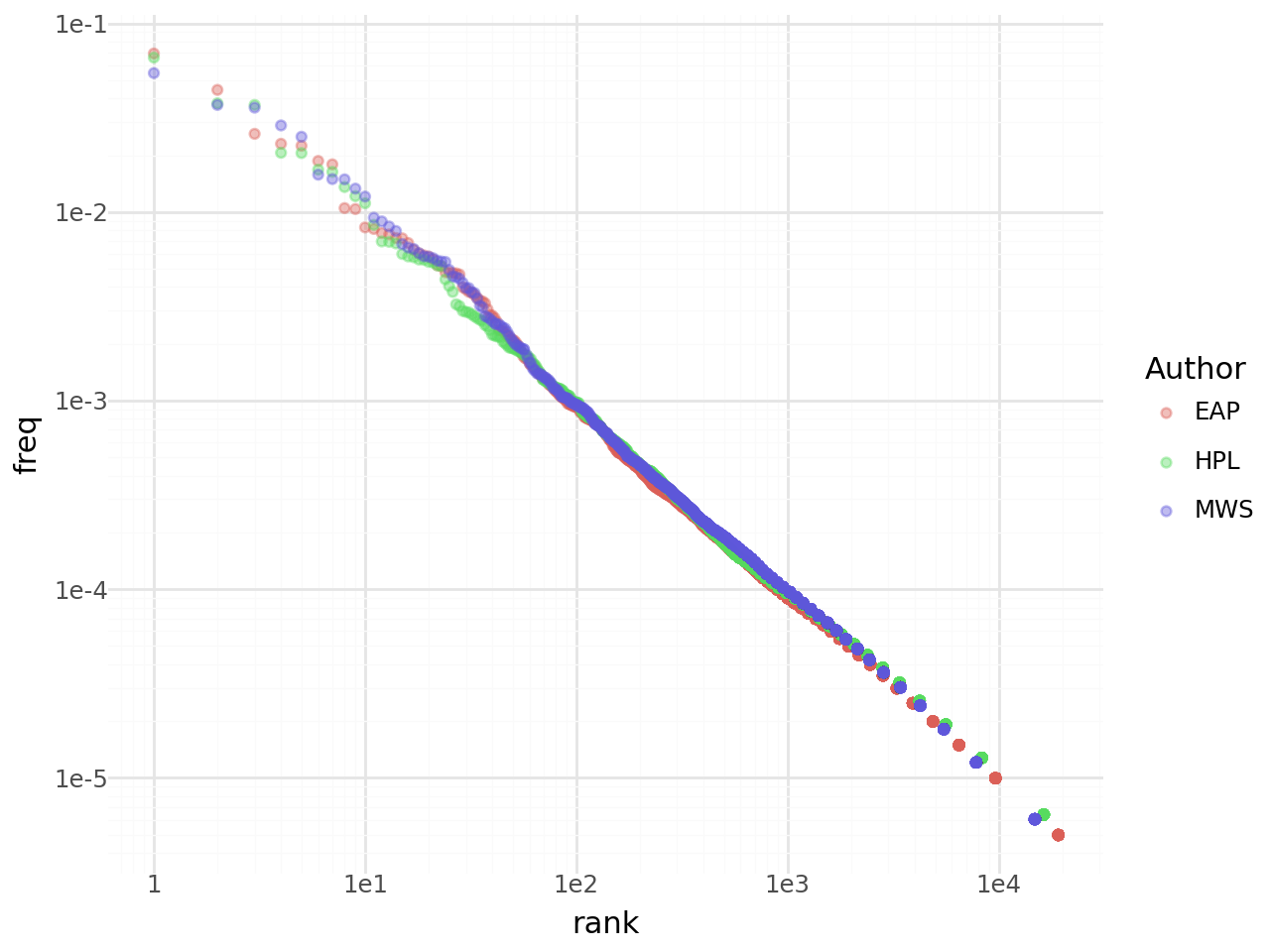
Avec statsmodels, vérifions plus formellement cette relation:
import statsmodels.api as sm
import numpy as np
exog = sm.add_constant(np.log(count_words['rank'].astype(float)))
model = sm.GLM(count_words['freq'].astype(float), exog, family = sm.families.Poisson()).fit()
# Afficher les résultats du modèle
print(model.summary()) Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: freq No. Observations: 69301
Model: GLM Df Residuals: 69299
Model Family: Poisson Df Model: 1
Link Function: Log Scale: 1.0000
Method: IRLS Log-Likelihood: -23.011
Date: Sat, 25 Jul 2026 Deviance: 0.065676
Time: 17:48:22 Pearson chi2: 0.0656
No. Iterations: 5 Pseudo R-squ. (CS): 0.0002431
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const -2.4388 1.089 -2.239 0.025 -4.574 -0.303
rank -0.9831 0.189 -5.196 0.000 -1.354 -0.612
==============================================================================Le coefficient de la régression est presque 1 ce qui suggère bien une relation quasiment log-linéaire entre le rang et la fréquence d’occurrence d’un mot. Dit autrement, le mot le plus utilisé l’est deux fois plus que le deuxième mot le plus fréquent qui l’est trois plus que le troisième, etc. On retrouve bien empiriquement cette loi sur ce corpus de trois auteurs.
4 Nettoyage de textes
4.1 Retirer les stop words
Nous l’avons vu, que ce soit en Français ou Anglais, un certain nombre de mots de liaisons, nécessaires sur le plan grammatical mais peu porteur d’information, nous empêchent de saisir les principaux mots vecteurs d’information dans notre corpus.
Il est donc nécessaire de nettoyer notre corpus en retirant ces termes. Ce travail de nettoyage va d’ailleurs au-delà d’un simple retrait de mots. C’est également l’occasion de retirer d’autres sèmes gênants, par exemple la ponctuation.
Commençons par télécharger le corpus de stopwords
import nltk
nltk.download('stopwords')[nltk_data] Downloading package stopwords to /home/runner/nltk_data...
[nltk_data] Package stopwords is already up-to-date!TrueLa liste des stopwords anglais dans NLTK
est la suivante:
from nltk.corpus import stopwords
", ".join(stopwords.words("english"))"a, about, above, after, again, against, ain, all, am, an, and, any, are, aren, aren't, as, at, be, because, been, before, being, below, between, both, but, by, can, couldn, couldn't, d, did, didn, didn't, do, does, doesn, doesn't, doing, don, don't, down, during, each, few, for, from, further, had, hadn, hadn't, has, hasn, hasn't, have, haven, haven't, having, he, he'd, he'll, her, here, hers, herself, he's, him, himself, his, how, i, i'd, if, i'll, i'm, in, into, is, isn, isn't, it, it'd, it'll, it's, its, itself, i've, just, ll, m, ma, me, mightn, mightn't, more, most, mustn, mustn't, my, myself, needn, needn't, no, nor, not, now, o, of, off, on, once, only, or, other, our, ours, ourselves, out, over, own, re, s, same, shan, shan't, she, she'd, she'll, she's, should, shouldn, shouldn't, should've, so, some, such, t, than, that, that'll, the, their, theirs, them, themselves, then, there, these, they, they'd, they'll, they're, they've, this, those, through, to, too, under, until, up, ve, very, was, wasn, wasn't, we, we'd, we'll, we're, were, weren, weren't, we've, what, when, where, which, while, who, whom, why, will, with, won, won't, wouldn, wouldn't, y, you, you'd, you'll, your, you're, yours, yourself, yourselves, you've"Celle de SpaCy est plus riche (nous avons déjà téléchargé le corpus en_core_web_sm en question):
nlp_english = spacy.load('en_core_web_sm')
stop_words_english = nlp_english.Defaults.stop_words
", ".join(stop_words_english)"done, did, although, n’t, often, already, ‘re, ’ve, had, via, please, seemed, against, once, anywhere, us, along, until, though, ’ll, show, re, sixty, another, would, there, few, cannot, it, in, yours, anything, beforehand, such, ‘s, on, go, eight, before, your, could, its, made, five, take, whatever, hence, being, sometime, and, have, other, then, above, whenever, do, are, is, whoever, mostly, ‘m, who, three, wherever, whereas, empty, among, 'll, everywhere, see, ’m, were, than, ’s, latter, very, except, this, nor, part, must, latterly, move, how, one, becoming, under, off, onto, something, sometimes, whom, ourselves, last, back, below, never, for, if, anyhow, hundred, become, every, around, therefore, anyway, more, side, thence, own, less, enough, due, or, full, within, hereupon, she, whether, will, again, herein, be, used, somehow, further, quite, he, does, first, 's, indeed, get, thereby, am, i, yourselves, also, thus, whereafter, using, seems, as, anyone, hereafter, about, doing, forty, each, several, themselves, keep, ’d, whither, a, an, towards, without, put, of, others, rather, say, third, we, which, perhaps, twelve, wherein, besides, amongst, itself, next, either, thereupon, nothing, at, so, make, during, still, former, ‘ll, bottom, they, really, herself, should, why, him, any, because, what, nobody, 'd, fifty, can, up, least, alone, everything, mine, between, may, whose, top, might, call, per, hereby, to, 've, regarding, from, her, beside, front, just, no, upon, nowhere, since, them, whereby, thru, noone, too, however, the, six, now, yourself, becomes, behind, into, toward, me, nevertheless, both, through, somewhere, became, you, over, namely, their, thereafter, two, everyone, none, those, ‘ve, same, together, himself, while, with, most, whereupon, meanwhile, across, my, only, someone, give, whole, name, n‘t, beyond, been, seem, moreover, ours, elsewhere, was, many, therein, amount, nine, hers, when, myself, ca, twenty, that, n't, seeming, whence, where, always, some, all, yet, his, various, 're, here, otherwise, 'm, has, serious, our, after, out, these, not, else, fifteen, four, afterwards, by, throughout, unless, ten, neither, ever, ‘d, well, formerly, eleven, but, down, even, much, ’re, almost"Si cette fois on prend la liste des stopwords français dans NLTK:
", ".join(stopwords.words("french"))'au, aux, avec, ce, ces, dans, de, des, du, elle, en, et, eux, il, ils, je, la, le, les, leur, lui, ma, mais, me, même, mes, moi, mon, ne, nos, notre, nous, on, ou, par, pas, pour, qu, que, qui, sa, se, ses, son, sur, ta, te, tes, toi, ton, tu, un, une, vos, votre, vous, c, d, j, l, à, m, n, s, t, y, été, étée, étées, étés, étant, étante, étants, étantes, suis, es, est, sommes, êtes, sont, serai, seras, sera, serons, serez, seront, serais, serait, serions, seriez, seraient, étais, était, étions, étiez, étaient, fus, fut, fûmes, fûtes, furent, sois, soit, soyons, soyez, soient, fusse, fusses, fût, fussions, fussiez, fussent, ayant, ayante, ayantes, ayants, eu, eue, eues, eus, ai, as, avons, avez, ont, aurai, auras, aura, aurons, aurez, auront, aurais, aurait, aurions, auriez, auraient, avais, avait, avions, aviez, avaient, eut, eûmes, eûtes, eurent, aie, aies, ait, ayons, ayez, aient, eusse, eusses, eût, eussions, eussiez, eussent'On voit que celle-ci n’est pas très riche et mériterait d’être plus complète. Celle de SpaCy correspond mieux à ce qu’on attend
stop_words_french = nlp.Defaults.stop_words
", ".join(stop_words_french)"ou, d', meme, dixième, déja, c', étais, quatrième, ci, suivante, donc, dès, font, via, exactement, différente, desquelles, etaient, malgre, pour, seuls, j’, nouveau, tout, doit, pendant, de, quatrièmement, pas, aussi, autre, voilà, quant-à-soi, toi-meme, devant, different, premièrement, abord, etre, troisième, permet, cinquantième, hormis, dedans, quoi, proche, deux, quelques, precisement, on, uns, les, durant, semble, prealable, ô, mille, au, quatre, eux, lui-même, toujours, suivantes, gens, hi, suit, compris, aux, aura, quelles, auraient, na, nul, un, effet, cent, également, dire, cependant, tenant, celui-la, nôtres, soi, première, peuvent, cinquante, certaines, lequel, tend, s', da, seraient, rendre, elles-memes, antérieure, ouverts, dans, onze, dehors, avait, vais, sur, notre, pourrais, plus, â, sera, même, voici, suffit, derrière, quatorze, revoici, es, toi-même, celles-la, diverses, ha, il, chacune, procedant, directement, est, douze, hue, lui-meme, ni, une, sont, bas, dits, hors, là, préalable, relative, autrement, deja, cet, laquelle, pourrait, divers, t', enfin, ouvert, pouvait, relativement, malgré, egalement, seule, huit, se, vu, certaine, dix-sept, notamment, lors, elle, maintenant, ma, miennes, ont, hé, jusque, ait, lesquelles, etant, quatre-vingt, tienne, mais, puis, antérieur, j', memes, tu, restent, possibles, depuis, va, spécifiques, vingt, nôtre, certes, lorsque, seulement, elles, tel, parfois, auront, tellement, te, du, autrui, hem, et, cette, environ, quelle, étant, or, déjà, peu, auxquels, siennes, miens, avais, etait, duquel, étaient, revoila, eh, peux, houp, quel, ouias, voila, dix-neuf, deuxième, personne, attendu, cinq, parce, dite, moins, parmi, troisièmement, i, ayant, differents, celles-là, quant, lès, parle, as, plutôt, suivant, specifiques, telles, ouste, nous, possible, té, souvent, tiennes, toutes, a, vôtres, ai, ès, soi-meme, sent, dit, assez, semblent, etc, premier, neanmoins, par, antérieures, différents, soit, celui-là, vas, différentes, surtout, chaque, dejà, delà, longtemps, ça, quelqu'un, sans, reste, dessus, plutot, le, merci, pense, quelque, t’, quarante, etais, facon, mienne, votre, basee, juste, précisement, vé, parler, ouverte, suivre, moindres, concernant, touchant, moi, après, qui, ne, specifique, sait, ses, elle-meme, debout, m’, mêmes, sien, deuxièmement, peut, était, hui, sinon, auxquelles, elle-même, fais, parlent, entre, c’, suffisante, certain, partant, elles-mêmes, être, suffisant, mes, comment, seize, ainsi, seules, s’, devers, vers, maint, combien, douzième, suis, mon, en, qu’, y, jusqu, ceux, allaient, restant, hou, ces, celle-la, pourquoi, près, sa, trois, tous, nombreux, quinze, avoir, quiconque, celles, où, ah, siens, seront, devra, avons, six, tels, n’, importe, tres, outre, eux-mêmes, huitième, vous, stop, revoilà, car, celui, cela, laisser, allons, toute, tien, selon, seul, cinquantaine, ils, celles-ci, semblable, me, differentes, quand, telle, que, celui-ci, qu', spécifique, vos, tenir, ho, auquel, rend, avaient, ceux-ci, soi-même, ton, sous, n', la, dix, sauf, avec, sept, l’, envers, d’, dix-huit, quoique, pres, celle, pu, ta, façon, toi, derriere, leur, suivants, certains, trente, l', aurait, septième, ce, faisaient, celle-ci, très, mien, puisque, sienne, ceci, feront, dessous, doivent, son, treize, tiens, comme, afin, à, dont, différent, plusieurs, quels, retour, quelconque, apres, diverse, directe, tes, désormais, differente, chacun, eu, nos, excepté, desormais, bat, faisant, m', votres, leurs, vous-mêmes, onzième, desquels, tente, alors, sixième, vont, neuvième, nombreuses, soixante, anterieure, semblaient, fait, hep, serait, vôtre, je, aie, encore, unes, ceux-là, cinquième, lui, nous-mêmes, celle-là, lesquels, si, moi-même, tant, moi-meme, avant, o, aupres, chez, néanmoins, des, anterieures, autres, anterieur"
AstuceExercice 3 : Nettoyage du texte
- Reprendre l’ouvrage de Dumas et nettoyer celui-ci avec
Spacy. Refaire le nuage de mots et conclure. - Faire ce même exercice sur le jeu de données anglo-saxon. Idéalement, vous devriez être en mesure d’utiliser la fonctionnalité de pipeline de
SpaCy.
# Function to clean the text
def clean_text(doc):
# Tokenize, remove stop words and punctuation, and lemmatize
cleaned_tokens = [
token.lemma_ for token in doc if not token.is_stop and not token.is_punct
]
# Join tokens back into a single string
cleaned_text = " ".join(cleaned_tokens)
return cleaned_textCes retraitements commencent à porter leurs fruits puisque des mots ayant plus de sens commencent à se dégager, notamment les noms des personnages (Dantès, Danglart, etc.):
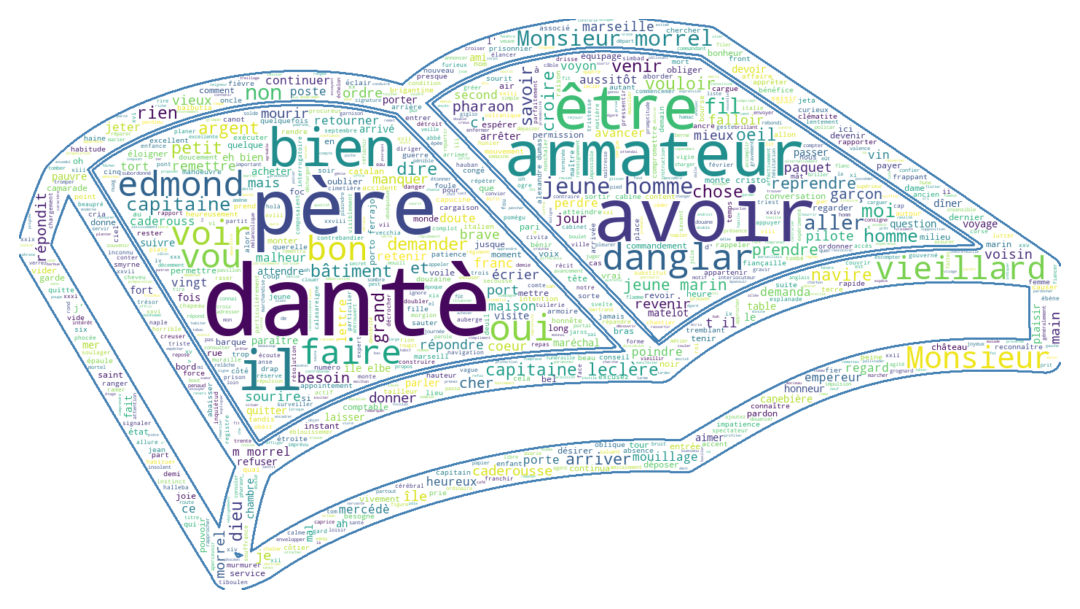

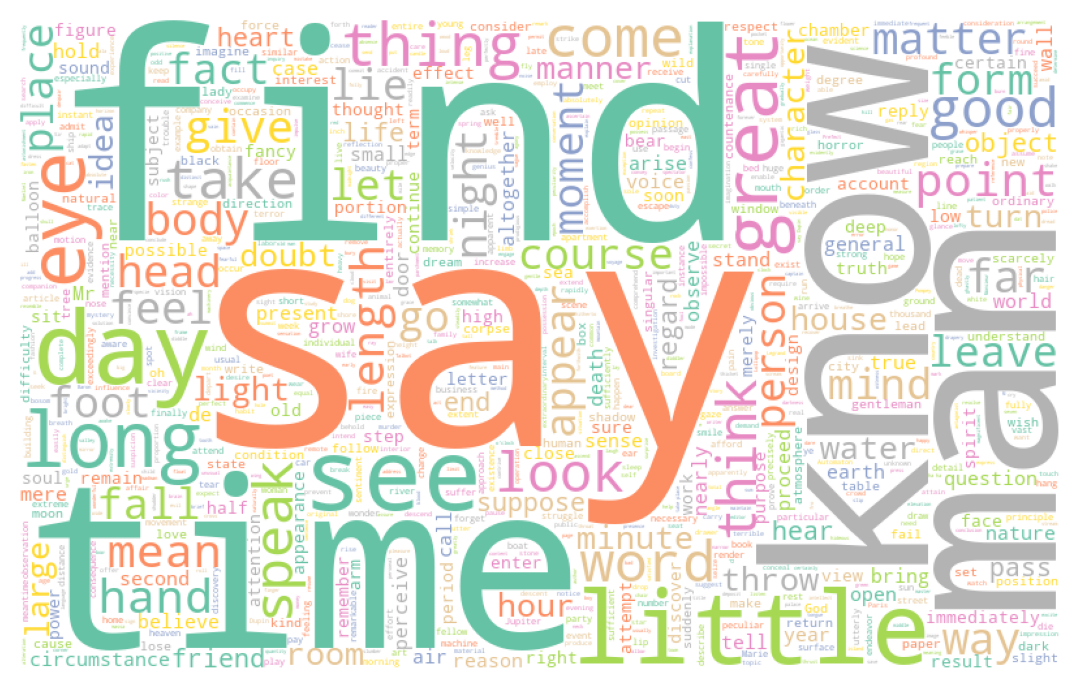

4.2 Racinisation et lemmatisation
Pour aller plus loin dans l’harmonisation d’un texte, il est possible de mettre en place des classes d’équivalence entre des mots. Par exemple, quand on désire faire une analyse fréquentiste, on peut être intéressé par considérer que “cheval” et “chevaux” sont équivalents. Selon les cas, différentes formes d’un même mot (pluriel, singulier, conjugaison) pourront être considérées comme équivalentes et seront remplacées par une même forme dite canonique.
Il existe deux approches dans le domaine :
- la lemmatisation qui requiert la connaissance des statuts grammaticaux (exemple : “chevaux” devient “cheval”) ;
- la racinisation (stemming) plus fruste mais plus rapide, notamment en présence de fautes d’orthographes. Dans ce cas, “chevaux” peut devenir “chev” mais être ainsi confondu avec “chevet” ou “cheveux”.
Cette approche a l’avantage de réduire la taille du vocabulaire à maîtriser pour l’ordinateur et le modélisateur. Il existe plusieurs algorithmes de stemming, notamment le Porter Stemming Algorithm ou le Snowball Stemming Algorithm.
NoteNote
Pour disposer du corpus nécessaire à la lemmatisation, il faut, la première fois, télécharger celui-ci grâce aux commandes suivantes :
import nltk
nltk.download('wordnet')
nltk.download('omw-1.4')Prenons cette chaine de caractère,
"naples. comme d'habitude, un pilote côtier partit aussitôt du port, rasa le château d'if, et alla aborder le navire entre le cap de morgion et l'île de rion. aussitôt, co"La version racinisée est la suivante:
"napl,.,comm,d'habitud,,,un,pilot,côti,part,aussitôt,du,port,,,ras,le,château,d'if,,,et,alla,abord,le,navir,entre,le,cap,de,morgion,et,l'îl,de,rion,.,aussitôt,,,co"A ce niveau, les mots commencent à être moins intelligibles par un humain mais peuvent rester intelligible pour la machine. Ce choix n’est néanmoins pas neutre et sa pertinence dépend du cas d’usage.
Les lemmatiseurs permettront des harmonisations plus subtiles. Ils s’appuient sur des bases de connaissance, par exemple WordNet, une base lexicographique ouverte. Par exemple, les mots “women”, “daughters” et “leaves” seront ainsi lemmatisés de la manière suivante :
from nltk.stem import WordNetLemmatizer
lemm = WordNetLemmatizer()
for word in ["women","daughters", "leaves"]:
print(f"The lemmatized form of {word} is: {lemm.lemmatize(word)}")The lemmatized form of women is: woman
The lemmatized form of daughters is: daughter
The lemmatized form of leaves is: leaf
AstuceExercice 4 : Lemmatisation avec nltk
Sur le modèle précédent, utiliser un WordNetLemmatizer sur le corpus dumas[1030:1200] et observer le résultat.
La version lemmatisée de ce petit morceau de l’oeuvre de Dumas est la suivante:
"naples, ., comme, d'habitude, ,, un, pilote, côtier, partit, aussitôt, du, port, ,, rasa, le, château, d'if, ,, et, alla, aborder, le, navire, entre, le, cap, de, morgion, et, l'île, de, rion, ., aussitôt, ,, co"4.3 Limite
Dans les approches fréquentistes, où on recherche la proximité entre des textes par la co-occurrence de termes, cette question de la création de classes d’équivalence est fondamentale. Les mots sont identiques ou différents, il n’y a pas de différence subtile entre eux. Par exemple, on devra soit déclarer que “python” et “pythons” sont équivalents, soient qu’ils sont différents, sans différence de degré entre “pythons”, “anaconda” ou “table” par rapport à “python”. Les approches modernes, non plus exclusivement basées sur des fréquences d’apparition, permettront d’introduire de la subtilité dans la synthétisation de l’information présente dans les données textuelles.
Informations additionnelles
NoteEnvironnement Python
Ce site a été construit automatiquement par le biais d’une action Github utilisant le logiciel de publication reproductible Quarto
L’environnement utilisé pour obtenir les résultats est reproductible par le biais d’uv. Le fichier pyproject.toml utilisé pour construire cet environnement est disponible sur le dépôt linogaliana/python-datascientist
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
Pour utiliser exactement le même environnement (version de Python et packages), se reporter à la documentation d’uv.
NoteHistorique du fichier
| SHA | Date | Author | Description |
|---|---|---|---|
| 94648290 | 2025-07-22 18:57:48 | Lino Galiana | Fix boxes now that it is better supported by jupyter (#628) |
| 91431fa2 | 2025-06-09 17:08:00 | Lino Galiana | Improve homepage hero banner (#612) |
| df498c79 | 2025-05-24 19:10:07 | Lino Galiana | uv friendly pipeline (#605) |
| d6b67125 | 2025-05-23 18:03:48 | Lino Galiana | Traduction des chapitres NLP (#603) |
| 4181dab1 | 2024-12-06 13:16:36 | lgaliana | Transition |
| 1b7188a1 | 2024-12-05 13:21:11 | lgaliana | Embedding chapter |
| c641de05 | 2024-08-22 11:37:13 | Lino Galiana | A series of fix for notebooks that were bugging (#545) |
| 0908656f | 2024-08-20 16:30:39 | Lino Galiana | English sidebar (#542) |
| 5108922f | 2024-08-08 18:43:37 | Lino Galiana | Improve notebook generation and tests on PR (#536) |
| 8d23a533 | 2024-07-10 18:45:54 | Julien PRAMIL | Modifs 02_exoclean.qmd (#523) |
| 75950080 | 2024-07-08 17:24:29 | Julien PRAMIL | Changes into NLP/01_intro.qmd (#517) |
| 56b6442d | 2024-07-08 15:05:57 | Lino Galiana | Version anglaise du chapitre numpy (#516) |
| a3dc832c | 2024-06-24 16:15:19 | Lino Galiana | Improve homepage images (#508) |
| e660d769 | 2024-06-19 14:31:09 | linogaliana | improve output NLP 1 |
| 4f41cf6a | 2024-06-14 15:00:41 | Lino Galiana | Une partie sur les sacs de mots plus cohérente (#501) |
| 06d003a1 | 2024-04-23 10:09:22 | Lino Galiana | Continue la restructuration des sous-parties (#492) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 3437373a | 2023-12-16 20:11:06 | Lino Galiana | Améliore l’exercice sur le LASSO (#473) |
| 4cd44f35 | 2023-12-11 17:37:50 | Antoine Palazzolo | Relecture NLP (#474) |
| deaafb6f | 2023-12-11 13:44:34 | Thomas Faria | Relecture Thomas partie NLP (#472) |
| 4c060a17 | 2023-12-01 17:44:17 | Lino Galiana | Update book image location |
| 1f23de28 | 2023-12-01 17:25:36 | Lino Galiana | Stockage des images sur S3 (#466) |
| a1ab3d94 | 2023-11-24 10:57:02 | Lino Galiana | Reprise des chapitres NLP (#459) |
| a7711832 | 2023-10-09 11:27:45 | Antoine Palazzolo | Relecture TD2 par Antoine (#418) |
| 154f09e4 | 2023-09-26 14:59:11 | Antoine Palazzolo | Des typos corrigées par Antoine (#411) |
| 80823022 | 2023-08-25 17:48:36 | Lino Galiana | Mise à jour des scripts de construction des notebooks (#395) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| f2905a7d | 2023-08-11 17:24:57 | Lino Galiana | Introduction de la partie NLP (#388) |
| 78ea2cbd | 2023-07-20 20:27:31 | Lino Galiana | Change titles levels (#381) |
| a9b384ed | 2023-07-18 18:07:16 | Lino Galiana | Sépare les notebooks (#373) |
| 29ff3f58 | 2023-07-07 14:17:53 | linogaliana | description everywhere |
| f21a24d3 | 2023-07-02 10:58:15 | Lino Galiana | Pipeline Quarto & Pages 🚀 (#365) |
| 164fa689 | 2022-11-30 09:13:45 | Lino Galiana | Travail partie NLP (#328) |
| f10815b5 | 2022-08-25 16:00:03 | Lino Galiana | Notebooks should now look more beautiful (#260) |
| 494a85ae | 2022-08-05 14:49:56 | Lino Galiana | Images featured ✨ (#252) |
| d201e3cd | 2022-08-03 15:50:34 | Lino Galiana | Pimp la homepage ✨ (#249) |
| 12965bac | 2022-05-25 15:53:27 | Lino Galiana | :launch: Bascule vers quarto (#226) |
| 9c71d6e7 | 2022-03-08 10:34:26 | Lino Galiana | Plus d’éléments sur S3 (#218) |
| 3299f1d9 | 2022-01-08 16:50:11 | Lino Galiana | Clean NLP notebooks (#215) |
| 495599d7 | 2021-12-19 18:33:05 | Lino Galiana | Des éléments supplémentaires dans la partie NLP (#202) |
| 4f675284 | 2021-12-12 08:37:21 | Lino Galiana | Improve website appareance (#194) |
| 2a8809fb | 2021-10-27 12:05:34 | Lino Galiana | Simplification des hooks pour gagner en flexibilité et clarté (#166) |
| 04f8b8f6 | 2021-09-08 11:55:35 | Lino Galiana | echo = FALSE sur la page tuto NLP |
| 048e3dd6 | 2021-09-02 18:36:23 | Lino Galiana | Fix problem with Dumas corpus (#134) |
| 2e4d5862 | 2021-09-02 12:03:39 | Lino Galiana | Simplify badges generation (#130) |
| 49e2826f | 2021-05-13 18:11:20 | Lino Galiana | Corrige quelques images n’apparaissant pas (#108) |
| 4cdb759c | 2021-05-12 10:37:23 | Lino Galiana | :sparkles: :star2: Nouveau thème hugo :snake: :fire: (#105) |
| 48ed9d25 | 2021-05-01 08:58:58 | Lino Galiana | lien mort corrigé |
| 7f9f97bc | 2021-04-30 21:44:04 | Lino Galiana | 🐳 + 🐍 New workflow (docker 🐳) and new dataset for modelization (2020 🇺🇸 elections) (#99) |
| d164635d | 2020-12-08 16:22:00 | Lino Galiana | :books: Première partie NLP (#87) |
Notes de bas de page
To obtain the same results as shown below, you can set the argument
random_state=21.↩︎
Citation
BibTeX
@book{galiana2025,
author = {Galiana, Lino},
title = {Python pour la data science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {fr}
}
Veuillez citer ce travail comme suit :
Galiana, Lino. 2025. Python pour la data science. https://doi.org/10.5281/zenodo.8229676.