!pip install geopandasPour essayer les exemples présents dans ce tutoriel :

AstuceCompétences à l’issue de ce chapitre
- Comprendre l’importance cruciale du preprocessing pour garantir la cohérence entre les données et les hypothèses de modélisation, en s’appuyant sur l’écosystème robuste de Scikit-Learn ;
- Explorer la structure des données à l’aide de Pandas pour sélectionner les variables pertinentes avant modélisation ;
- Transformer les données continues selon les besoins du modèle : standardisation (distribution centrée-réduite) ou normalisation (norme unité), selon le contexte de l’algorithme ;
- Encoder les variables catégorielles via LabelEncoder, OrdinalEncoder ou OneHotEncoder pour les rendre utilisables en modélisation ;
- Gérer les valeurs manquantes grâce à l’imputation (moyenne, médiane, mode ou méthodes plus sophistiquées), au lieu de supprimer systématiquement les observations ;
- Détecter et traiter les valeurs aberrantes (outliers), en les identifiant via leur distribution, puis en les retirant si elles nuisent à la qualité du modèle ;
- Comprendre que, du point de vue de l’implémentation en Scikit, le preprocessing constitue un apprentissage : les paramètres estimés (moyenne, variance) sur l’ensemble d’entraînement peuvent être ré-appliqués à tout nouveau jeu de données, assurant que la distribution des données post-processing coïncide avec celle des données d’apprentissage.
1 Introduction
L’introduction de cette partie présentait les enjeux de l’adoption d’une approche algorithmique plutôt que statistique pour modéliser des processus empiriques. L’objectif de ce chapitre est d’introduire à la méthodologie du machine learning, aux choix qu’impliquent une approche algorithmique sur la structuration du travail sur les données. Ce sera également l’occasion de présenter l’écosystème du machine learning en Python et notamment la librairie centrale dans celui-ci: Scikit Learn.
L’objectif de ce chapitre est de présenter quelques éléments de préparation des données. Il s’agit d’une étape fondamentale, à ne pas négliger. Les modèles reposent sur certaines hypothèses, généralement relatives à la distribution théorique des variables, qui y sont intégrées.
Il est nécessaire de faire correspondre la distribution empirique à ces hypothèses, ce qui implique un travail de restructuration des données. Celui-ci permettra d’avoir des résultats de modélisation plus pertinents. Nous verrons dans le chapitre sur les pipelines comment industrialiser ces étapes de preprocessing afin de se simplifier la vie pour appliquer un modèle sur un jeu de données différent de celui sur lequel il a été estimé.
Ce chapitre, comme l’ensemble de la partie machine learning, est une introduction pratique illustrée dans une perspective de prédiction électorale. En l’occurrence, il s’agit de prédire les résultats des élections américaines de 2020 au niveau comté à partir de variables socio-démographiques. L’idée sous-jacente est qu’il existe des facteurs sociologiques, économiques ou démographiques influençant le vote mais dont on ne connaît pas bien les motifs ou les interactions complexes entre plusieurs facteurs.
1.1 Présentation de l’écosystème Scikit
Scikit Learn est aujourd’hui la librairie de référence dans l’écosystème du
Machine Learning. Il s’agit d’une librairie qui, malgré les très nombreuses
méthodes implémentées, présente l’avantage d’être un point d’entrée unifié.
Cet aspect unifié est l’une des raisons du succès précoce de celle-ci. R n’a
bénéficié que plus récemment d’une librairie unifiée,
à savoir tidymodels.
Une autre raison du succès de Scikit est son approche opérationnelle : la mise
en production de modèles développés via les pipelines Scikit est peu coûteuse.
Un chapitre spécial de ce cours est dédié aux pipelines.
Avec Romain Avouac, nous proposons un cours plus avancé
en dernière année d’ENSAE où nous présentons certains enjeux relatifs
à la mise en production de modèles développés avec Scikit.
Le guide utilisateur de Scikit est une référence précieuse,
à consulter régulièrement. La partie sur le preprocessing, objet de ce chapitre, est
disponible ici.
NoteScikit Learn, un succès français ! 🐓🥖🥐
Scikit Learn est une librairie open source issue des travaux de l’Inria 🇫🇷. Depuis plus de 10 ans, cette institution publique française développe et maintient ce package téléchargé 2 millions de fois par jour. En 2023, pour sécuriser la maintenance de ce package, une start up nommée Probabl.ai a été créée autour de l’équipe des développeurs.euses de Scikit.
Pour découvrir la richesse de l’écosystème Scikit, il
est recommandé de suivre le
MOOC scikit,
développé dans le cadre de l’initiative Inria Academy.
1.2 Préparation des données
L’exercice 1 permet, à ceux qui le désirent, d’essayer de le reconstituer pas à pas.
Les packages suivants sont nécessaires pour importer et visualiser les données d’élection :
Les sources de données étant diverses, le code qui construit la base finale est directement fourni.
Le travail de construction d’une base unique
est un peu fastidieux mais il s’agit d’un bon exercice, que vous pouvez tenter,
pour réviser Pandas:
AstuceExercice 1 (optionnel): construire la base de données
Cet exercice est OPTIONNEL
- Télécharger et importer le shapefile depuis ce lien
- Exclure les Etats suivants : “02”, “69”, “66”, “78”, “60”, “72”, “15”
- Importer les résultats des élections depuis ce lien
- Importer les bases disponibles sur le site de l’USDA en faisant attention à renommer les variables de code FIPS de manière identique dans les 4 bases
- Merger ces 4 bases dans une base unique de caractéristiques socioéconomiques
- Merger aux données électorales à partir du code FIPS
- Merger au shapefile à partir du code FIPS. Faire attention aux 0 à gauche dans certains codes. Il est
recommandé d’utiliser la méthode
str.lstrippour les retirer - Importer les données des élections 2000 à 2016 à partir du MIT Election Lab? Les données peuvent être directement requêtées depuis l’url https://minio.lab.sspcloud.fr/lgaliana/data/python-ENSAE/countypres_2000-2024.csv qui est un export manuel issu de https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/VOQCHQ
- Créer une variable
sharecomptabilisant la part des votes pour chaque candidat. Ne garder que les colonnes"year", "FIPS", "party", "candidatevotes", "share" - Faire une conversion
longtowideavec la méthodepivot_tablepour garder une ligne par comté x année avec en colonnes les résultats de chaque candidat dans cet état. - Merger à partir du code FIPS au reste de la base.
Si vous ne faites pas l’exercice 1, pensez à charger les données en executant la fonction get_data.py :
import requests
url = 'https://raw.githubusercontent.com/linogaliana/python-datascientist/main/content/modelisation/get_data.py'
r = requests.get(url, allow_redirects=True)
open('getdata.py', 'wb').write(r.content)
import getdata
votes = getdata.create_votes_dataframes()Néanmoins, avant de se concentrer sur la préparation des données, nous allons passer un peu de temps à explorer la structure des données à partir de laquelle nous désirons construire une modélisation. Ceci est indispensable afin de comprendre la nature de celles-ci et choisir une modélisation adéquate.
Ce code introduit une base nommée votes dans l’environnement. Il s’agit d’une base rassemblant les différentes sources. Elle a l’aspect
suivant :
votes.loc[:, votes.columns != "geometry"].head(3)| STATEFP | COUNTYFP | COUNTYNS | AFFGEOID | GEOID | NAME | LSAD | ALAND | AWATER | FIPS_x | ... | share_2020_GREEN | share_2020_LIBERTARIAN | share_2020_OTHER | share_2020_REPUBLICAN | share_2024_DEMOCRAT | share_2024_LIBERTARIAN | share_2024_OTHER | share_2024_REPUBLICAN | share_2024_other | winner | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 29 | 227 | 00758566 | 0500000US29227 | 29227 | Worth | 06 | 690564983 | 493903 | 29227 | ... | 0.000000 | 0.012647 | 0.000903 | 0.792231 | 0.171946 | 0.008145 | 0.001810 | 0.818100 | NaN | republican |
| 1 | 31 | 061 | 00835852 | 0500000US31061 | 31061 | Franklin | 06 | 1491355860 | 487899 | 31061 | ... | NaN | 0.006381 | NaN | 0.833527 | 0.147500 | 0.005625 | 0.002500 | 0.844375 | NaN | republican |
| 2 | 36 | 013 | 00974105 | 0500000US36013 | 36013 | Chautauqua | 06 | 2746047476 | 1139407865 | 36013 | ... | 0.003396 | 0.012648 | 0.014573 | 0.583119 | 0.389156 | 0.000775 | 0.001656 | 0.608412 | NaN | republican |
3 rows × 325 columns
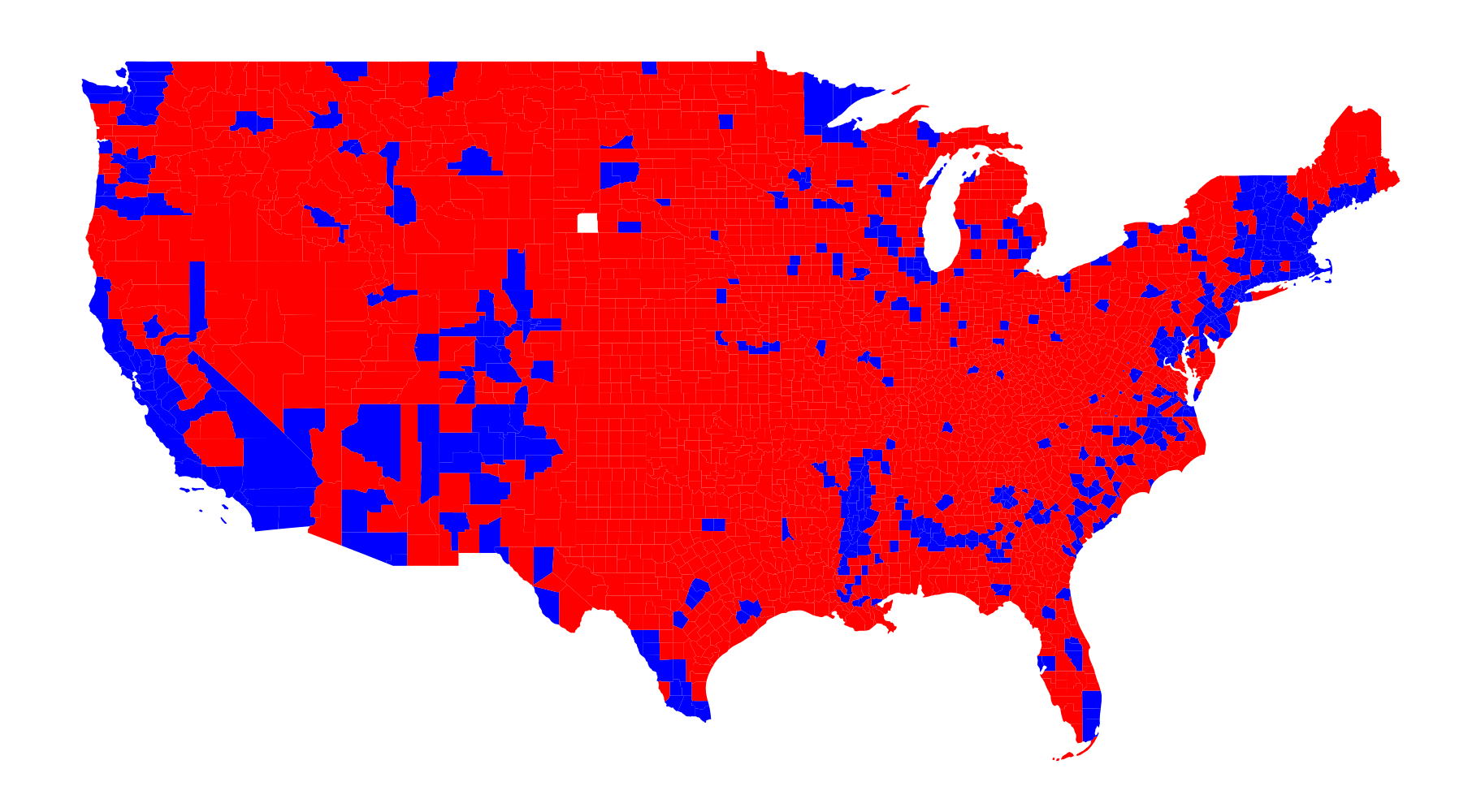
La carte choroplèthe suivante permet de visualiser rapidement les résultats (l’Alaska et Hawaï ont été exclus).
Code pour reproduire cette carte
from plotnine import *
# republican : red, democrat : blue
color_dict = {'republican': '#FF0000', 'democrats': '#0000FF'}
(
ggplot(votes) +
geom_map(aes(fill = "winner")) +
scale_fill_manual(color_dict) +
labs(fill = "Winner") +
theme_void() +
theme(legend_position = "bottom")
)
ImportantLe piège territorial
Comme cela a été évoqué dans le chapitre consacré à la cartographie, les cartes choroplèthes peuvent donner une impression fallacieuse que le parti Républicain a gagné largement en 2020 car ce type de représentation graphique donne plus d’importance aux grands espaces plutôt qu’aux espaces denses. Ceci explique que ce type de carte ait pu servir de justification pour contester les résultats du vote.
Il existe des représentations à privilégier pour ce type de phénomènes où la densité est importante. L’une des représentations à privilégier est les ronds proportionnels (voir Insee (2018), “Le piège territorial en cartographie”). Les cercles proportionnels permettent ainsi à l’oeil de se concentrer sur les zones les plus denses et non sur les grands espaces. Cette fois, on voit bien que le vote démocrate est majoritaire, ce que cachait l’aplat de couleur.
Le GIF “Land does not vote, people do”, qui avait eu un certain succès en 2020, propose un autre mode de visualisation.
La carte originale a été construite avec JavaScript. Cependant,
on dispose avec Python de plusieurs outils
pour répliquer, à faible coût, cette carte
grâce à
l’une des surcouches à JavaScript vues dans la partie visualisation.
Code pour reproduire cette carte interactive
import numpy as np
import pandas as pd
import geopandas as gpd
import plotly
import plotly.graph_objects as go
centroids = votes.copy()
centroids.geometry = centroids.centroid
centroids['size'] = centroids['CENSUS_2020_POP'] / 10000 # to get reasonable plotable number
color_dict = {"republican": '#FF0000', 'democrats': '#0000FF'}
centroids["winner"] = np.where(centroids['votes_gop'] > centroids['votes_dem'], 'republican', 'democrats')
centroids['lon'] = centroids['geometry'].x
centroids['lat'] = centroids['geometry'].y
centroids = pd.DataFrame(
centroids.loc[
: ,
["county_name",'lon','lat','winner', 'CENSUS_2020_POP',"state_name"]
]
)
groups = centroids.groupby('winner')
df = centroids.copy()
df['color'] = df['winner'].replace(color_dict)
df['size'] = df['CENSUS_2020_POP']/6000
df['text'] = df['CENSUS_2020_POP'].astype(int).apply(lambda x: '<br>Population: {:,} people'.format(x))
df['hover'] = df['county_name'].astype(str) + df['state_name'].apply(lambda x: ' ({}) '.format(x)) + df['text']
fig_plotly = go.Figure(
data=go.Scattergeo(
locationmode = 'USA-states',
lon=df["lon"], lat=df["lat"],
text = df["hover"],
mode = 'markers',
marker_color = df["color"],
marker_size = df['size'],
hoverinfo="text"
)
)
fig_plotly.update_traces(
marker = {'opacity': 0.5, 'line_color': 'rgb(40,40,40)', 'line_width': 0.5, 'sizemode': 'area'}
)
fig_plotly.update_layout(
title_text = "Reproduction of the \"Acres don't vote, people do\" map <br>(Click legend to toggle traces)",
showlegend = True,
geo = {"scope": 'usa', "landcolor": 'rgb(217, 217, 217)'}
)
fig_plotly.show()/tmp/ipykernel_7880/1328083585.py:9: UserWarning: Geometry is in a geographic CRS. Results from 'centroid' are likely incorrect. Use 'GeoSeries.to_crs()' to re-project geometries to a projected CRS before this operation.
2 La démarche générale
Dans ce chapitre, nous allons nous focaliser sur la préparation des données à faire en amont du travail de modélisation. Cette étape est indispensable pour s’assurer de la cohérence entre les données et les hypothèses de modélisation mais aussi pour produire des analyses valides scientifiquement.
La démarche générale que nous adopterons dans ce chapitre, et qui sera ensuite raffinée dans les prochains chapitres, est la suivante :
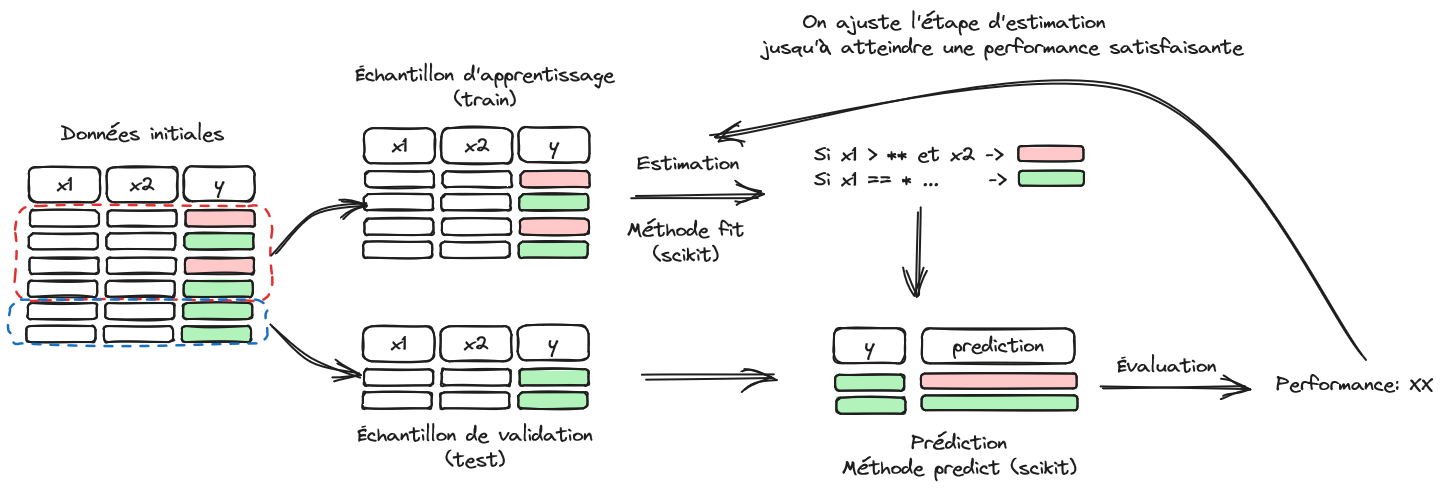
La Figure 2.1 illustre la structuration d’un problème de machine learning.
Tout d’abord, on découpe l’ensemble des données disponibles en deux parties, échantillons d’apprentissage et de validation. Le premier sert à entraîner un modèle et la qualité des prédictions de celui-ci est évaluée sur le deuxième pour limiter le biais de surapprentissage. Le chapitre suivant approfondira cette question de l’évaluation des modèles. A ce stade de notre progression, on se concentrera dans ce chapitre sur la question des données.
La librairie Scikit est particulièrement pratique parce qu’elle propose énormément d’algorithmes de machine learning avec quelques points d’entrée unifiée, notamment les méthodes fit et predict. Néanmoins, l’unification va au-delà de l’entraînement d’algorithmes. Toutes les étapes de préparation de données qui sont intégrées dans Scikit proposent ces deux mêmes points d’entrée. Autrement dit, les préparations de données sont construites comme une estimation de paramètres qui peut être réappliquée sur un autre jeu de données. Par exemple, cette préparation de données peut être une estimation de moyenne et variance pour normaliser des variables. La moyenne et la variance seront évaluées sur l’échantillon d’apprentissage et les mêmes moyennes et variances pourront être réappliquées sur un autre jeu de données pour le normaliser de la même façon.
3 Explorer la structure des données
La première étape nécessaire à suivre avant de se lancer dans la modélisation est de déterminer les variables à inclure dans le modèle.
Les fonctionnalités de Pandas sont, à ce niveau, suffisantes pour explorer des structures simples.
Néanmoins, lorsqu’on est face à un jeu de données présentant de
nombreuses variables explicatives (features en machine learning, covariates en économétrie),
il est souvent judicieux d’avoir une première étape de sélection de variables,
ce que nous verrons par la suite dans la partie dédiée.
Avant d’être en mesure de sélectionner le meilleur ensemble de variables explicatives, nous allons en prendre un nombre restreint et arbitraire. La première tâche est de représenter les relations entre les données, notamment la relation des variables explicatives à la variable dépendante (le score du parti républicain) ainsi que les relations entre les variables explicatives.
Pour le prochain exercice, afin d’illustrer le principe de l’inspection visuelle des corrélations, nous n’allons garder qu’un nombre limité de variables, choisies de manière quelle que peu arbitraire.
df2 = votes.set_index("GEOID").loc[
: ,
[
"winner", "votes_gop",
'Unemployment_rate_2019', 'Median_Household_Income_2021',
'Percent of adults with less than a high school diploma, 2018-22',
"Percent of adults with a bachelor's degree or higher, 2018-22"
]
]
df2 = df2.dropna()
AstuceExercice 2 (optionnel) : Regarder les corrélations entre les variables
Cet exercice est OPTIONNEL
Représenter grâce à un graphique la matrice de corrélation. Vous pouvez utiliser le package seaborn et sa fonction heatmap.
La matrice de corrélation peut être construite de plusieurs manières, en fonction du framework de prédilection (cf. le chapitre consacré à la visualisation). Voici celui obtenu avec seaborn, qui convient bien pour une visualisation rapide mais sur lequel il faudrait fournir un travail non négligeable pour obtenir un graphique prêt à la publication:
Code to produce correlation matrix with seaborn
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
column_labels = {
'votes_gop': 'GOP votes',
'Unemployment_rate_2019': 'Unemployment\n(2019)',
'Median_Household_Income_2021': 'Median Income\n(2021)',
'Percent of adults with less than a high school diploma, 2018-22': 'Less than HS diploma\n(2018–22)',
'Percent of adults with a bachelor\'s degree or higher, 2018-22': 'Bachelor\'s degree or\nhigher (2018–22)'
}
corr = (
df2.drop("winner", axis = 1)
.rename(columns=column_labels)
.corr()
)
mask = np.zeros_like(corr, dtype=bool)
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
fig = plt.figure()
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
g = sns.heatmap(
corr,
mask=mask, # Mask upper triangular matrix
cmap=cmap,
annot=True,
vmax=.3,
vmin=-.3,
center=0, # The center value of the legend. With divergent cmap, where white is
square=True,
linewidths=.5,
cbar_kws={"shrink": .5}
)
g
plt.xticks(rotation=30, ha='right')
plt.yticks(rotation=0)
plt.show()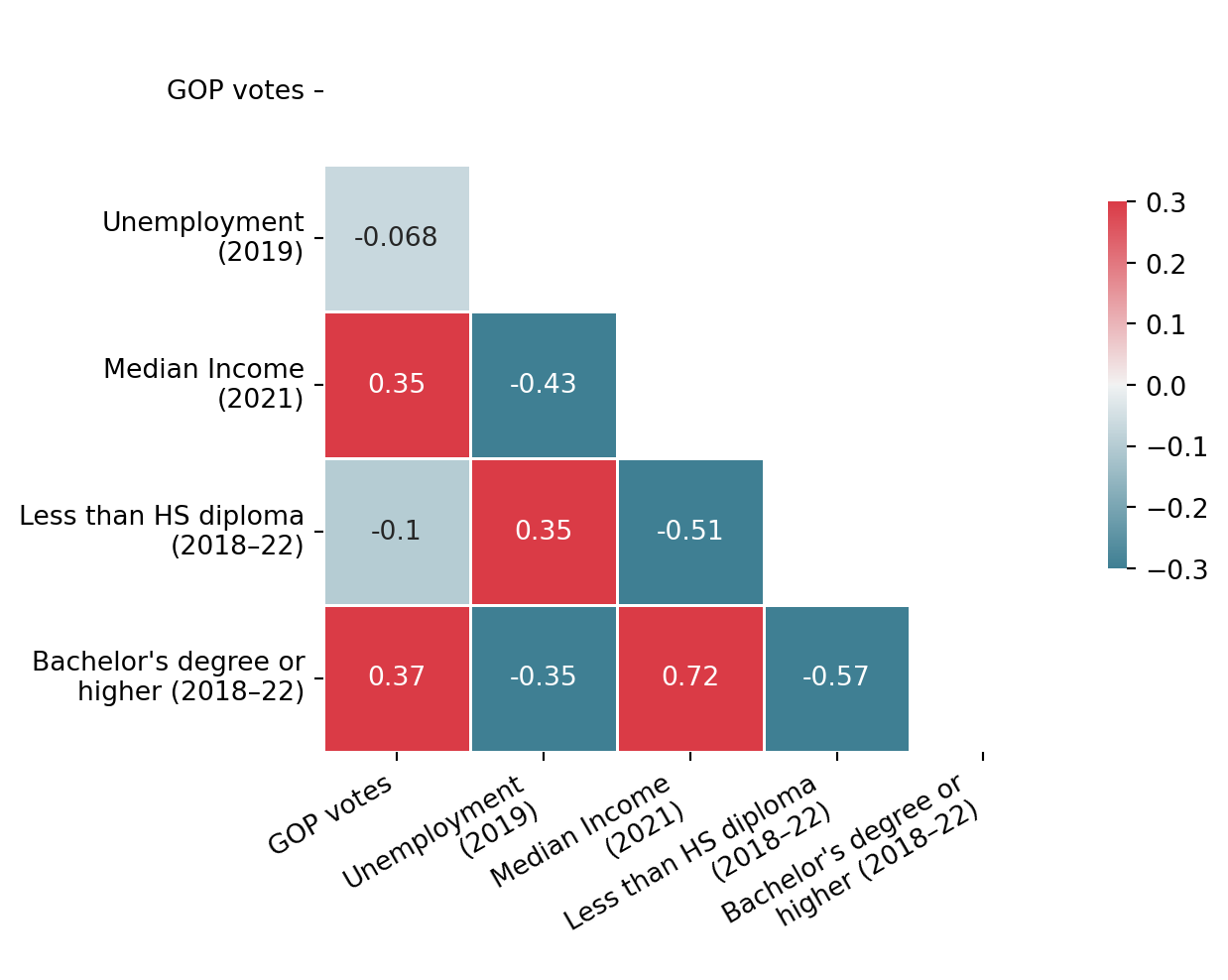
On peut également obtenir une figure similaire, mais un peu plus propre, grâce à plotnine, l’équivalent de la librairie R ggplot en Python (pour en savoir plus, retourner au chapitre consacré à la visualisation). Comme on trouve moins de source d’inspiration en Python (car en R on a profusion d’exemples) sur internet pour cette librairie, plus récente que matplotlib ou seaborn, le code est directement donné1.
Code to produce correlation matrix with plotnine
corr = (
df2.drop("winner", axis = 1)
.rename(columns=column_labels)
.corr()
)
# 2. Transformation en format long
corr_long = corr.reset_index().melt(id_vars='index')
corr_long.columns = ['var1', 'var2', 'corr']
# 3. Supprimer la diagonale supérieure
corr_long['mask'] = corr_long.apply(lambda row: sorted([row['var1'], row['var2']]), axis=1)
corr_long['keep'] = corr_long['mask'].duplicated(keep='first')
corr_long = corr_long[~corr_long['keep']].drop(columns=['mask', 'keep'])
# 4. Ordre cohérent
var_order = corr.columns.tolist()
corr_long['var1'] = pd.Categorical(corr_long['var1'], categories=var_order, ordered=True)
corr_long['var2'] = pd.Categorical(corr_long['var2'], categories=var_order[::-1], ordered=True)
# 5. Groupe pour texte contrasté
corr_long['p_group'] = np.where(corr_long['corr'].abs() > 0.2, 'white', 'black')
# 5. Création du plot
p = (
ggplot(corr_long, aes(x='var1', y='var2', fill='corr'))
+ geom_tile(width=0.95, height=0.95)
+ geom_text(aes(label='round(corr, 2)', color='p_group'), size=9, show_legend=False)
+ scale_fill_gradient2(low='blue', mid='white', high='red', midpoint=0, limits=(-1, 1))
+ scale_color_manual(values={'white': 'white', 'black': 'black'})
+ coord_fixed()
+ labs(x = "", y = "")
+ theme(
axis_text_x=element_text(rotation=45, ha='right'),
figure_size=(8, 6),
panel_background=element_rect(fill='white'),
legend_position = "none"
)
)
p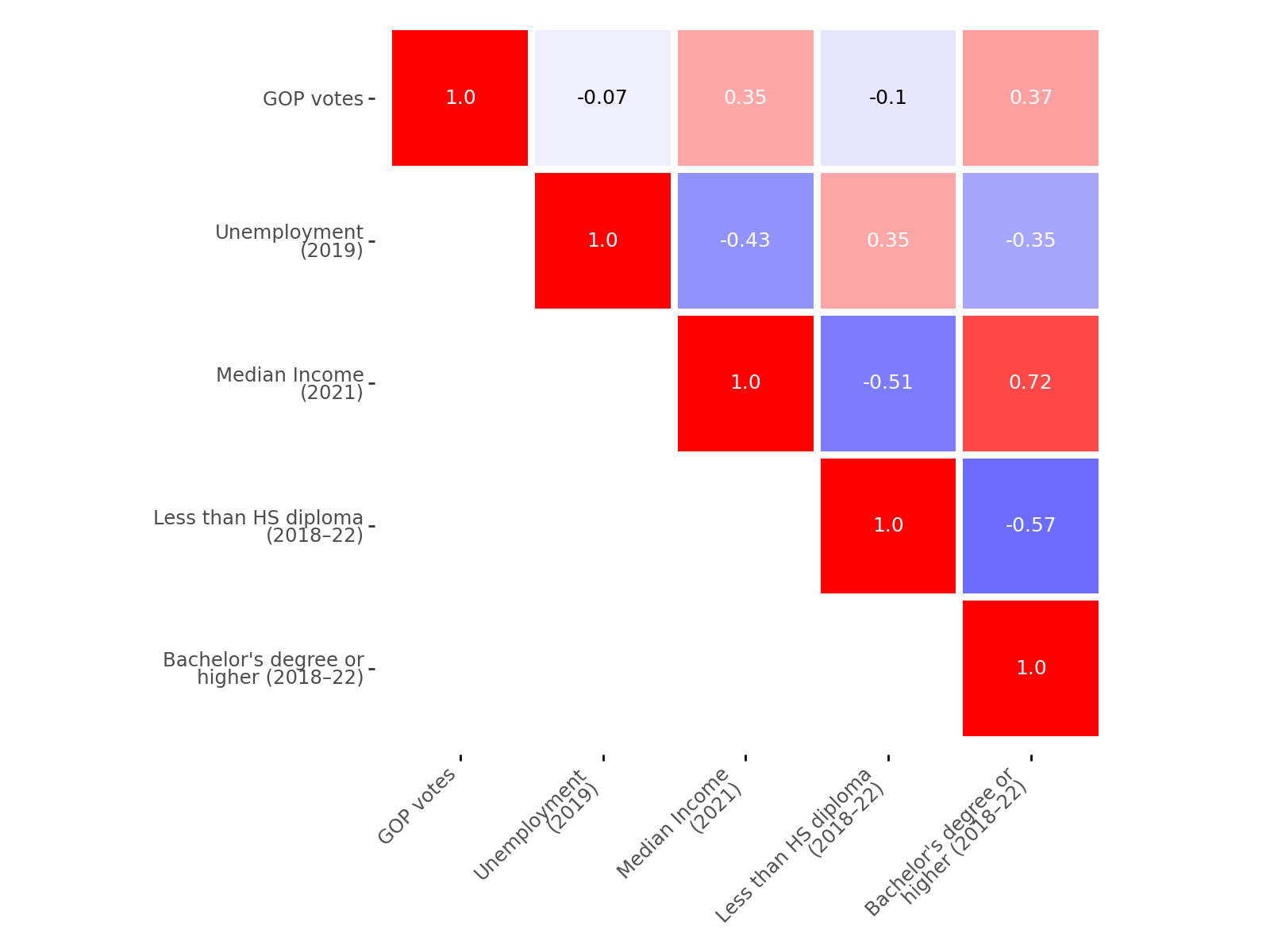
Dernier exemple, on peut aussi construire cette matrice de corrélation avec Plotly, même si ce n’est pas l’écosystème le plus pratique.
Code to produce correlation matrix with plotly
import plotly.express as px
import pandas as pd
import numpy as np
# Compute correlation matrix
corr = (
df2.drop("winner", axis=1)
.round(2)
.rename(columns=column_labels)
.corr()
)
# Mask upper triangle
mask = np.triu(np.ones_like(corr, dtype=bool))
corr_masked = corr.mask(mask)
# Plot heatmap
fig = px.imshow(
corr_masked.values,
x=corr.columns,
y=corr.columns,
color_continuous_scale='RdBu_r', # <- reversed color scale
zmin=-1,
zmax=1,
text_auto=".2f"
)
# Customize hover
fig.update_traces(
hovertemplate="Var 1: %{y}<br>Var 2: %{x}<br>Corr: %{z:.2f}<extra></extra>"
)
# Layout tweaks
fig.update_layout(
coloraxis_showscale=False,
xaxis=dict(showticklabels=False, title=None, ticks=''), # remove axis title and ticks
yaxis=dict(showticklabels=True, title=None, ticks=''),
plot_bgcolor="rgba(0,0,0,0)",
margin=dict(t=10, b=10, l=10, r=10), # <-- shrink ALL margins
width=600,
height=600
)
fig.show()De manière assez attendue, les corrélations (en valeur absolue) les plus fortes concernent le revenu et le niveau de diplôme. On peut aussi noter que le revenu est corrélé positivement au score des républicains. Néanmoins, ce résultat n’est pas toutes choses égales par ailleurs. Pour pouvoir aller plus loin dans l’analyse, il faudra introduire une forme de modélisation pour contrôler des relations croisées entre nos caractéristiques.
4 Transformer les données
Les différences d’échelle ou de distribution entre les variables peuvent diverger des hypothèses sous-jacentes dans les modèles.
Par exemple, dans le cadre
de la régression linéaire, les variables catégorielles ne sont pas traitées à la même
enseigne que les variables ayant valeur dans \(\mathbb{R}\). Une variable
discrète (prenant un nombre fini de valeurs) devra être transformée en suite de
variables 0/1 (des dummies) par rapport à une modalité de référence pour être en adéquation
avec les hypothèses de la régression linéaire.
On appelle ce type de transformation
one-hot encoding, sur laquelle nous reviendrons. Il s’agit d’une transformation,
parmi d’autres, disponibles dans Scikit pour mettre en adéquation un jeu de
données et des hypothèses mathématiques.
L’ensemble de ces tâches de préparation de données s’appelle le preprocessing ou le feature engineering. L’un des intérêts
d’utiliser Scikit est qu’on peut considérer qu’une tâche de preprocessing
est, en fait, une tâche d’apprentissage. En effet, le preprocessing
consiste à apprendre des paramètres d’une structure
de données (par exemple estimer moyennes et variances pour les retrancher à chaque
observation) et on peut très bien appliquer ces paramètres
à des observations qui n’ont pas servi à construire
ceux-ci. Autrement dit, cette préparation de données s’intègre très bien dans le pipeline Figure 2.1.
4.1 Preprocessing de variables continues
Nous allons voir deux processus très classiques de preprocessing pour des variables continues :
La standardisation transforme des données pour que la distribution empirique suive une loi \(\mathcal{N}(0,1)\).
La normalisation transforme les données de manière à obtenir une norme (\(\mathcal{l}_1\) ou \(\mathcal{l}_2\)) unitaire. Autrement dit, avec la norme adéquate, la somme des éléments est égale à 1.
Il en existe d’autres, par exemple le MinMaxScaler pour renormaliser les variables en fonction des bornes minimales et maximales des valeurs observées. Le choix de la méthode à mettre en oeuvre dépend du type d’algorithmes choisis par la suite: les hypothèses des k plus proches voisins (knn) seront différentes de celles d’une random forest. C’est pour cette raison que, normalement, on définit des pipelines complets, intégrant à la fois preprocessing et apprentissage. Ce sera l’objet des prochains chapitres.
Mise en gardeCaution
Pour les statisticiens.ennes,
le terme normalization dans le vocable Scikit peut avoir un sens contre-intuitif.
On s’attendrait à ce que la normalisation consiste à transformer une variable de manière à ce que \(X \sim \mathcal{N}(0,1)\).
C’est, en fait, la standardisation en Scikit qui fait cela.
4.1.1 Standardisation
La standardisation consiste à transformer des données pour que la distribution empirique suive une loi \(\mathcal{N}(0,1)\). Pour être performants, la plupart des modèles de machine learning nécessitent souvent d’avoir des données dans cette distribution. Même lorsque ce n’est pas indispensable, par exemple avec des régressions logistiques, cela peut accélérer la vitesse de convergence des algorithmes.
AstuceExercice 3: Standardisation
- Standardiser la variable
Median_Household_Income_2021(ne pas écraser les valeurs !) et regarder l’histogramme avant/après normalisation. Cette transformation est à appliquer à toute la colonne ; les prochaines questions se préoccuperont du sujet de découpage d’échantillon et d’extrapolation.
Note : On obtient bien une distribution centrée à zéro et on pourrait vérifier que la variance empirique soit bien égale à 1. On pourrait aussi vérifier que ceci est vrai également quand on transforme plusieurs colonnes à la fois.
- Créer
scaler, unTransformerque vous construisez sur les 1000 premières lignes de votre DataFramedf2à l’exception de la variable à expliquerwinner. Vérifier la moyenne et l’écart-type de chaque colonne sur ces mêmes observations.
Note : Les paramètres qui seront utilisés pour une standardisation ultérieure sont stockés dans les attributs .mean_ et .scale_
On peut voir ces attributs comme des paramètres entraînés sur un certain jeu de données et qu’on peut réutiliser sur un autre, à condition que les dimensions coïncident.
- Appliquer
scalersur les autres lignes du DataFrame et comparer les distributions obtenues de la variableMedian_Household_Income_2019.
Note : Une fois appliqués à un autre DataFrame, on peut remarquer que la distribution n’est pas exactement centrée-réduite dans le DataFrame sur lequel les paramètres n’ont pas été estimés. C’est normal, l’échantillon initial n’était pas aléatoire, les moyennes et variances de cet échantillon n’ont pas de raison de coïncider avec les moments de l’échantillon complet.
Avant standardisation, notre variable a cette distribution:

Après standardisation, l’échelle de la variable a changé.
/home/runner/work/python-datascientist/python-datascientist/.venv/lib/python3.13/site-packages/plotnine/stats/stat_bin.py:112: PlotnineWarning: 'stat_bin()' using 'bins = 57'. Pick better value with 'binwidth'.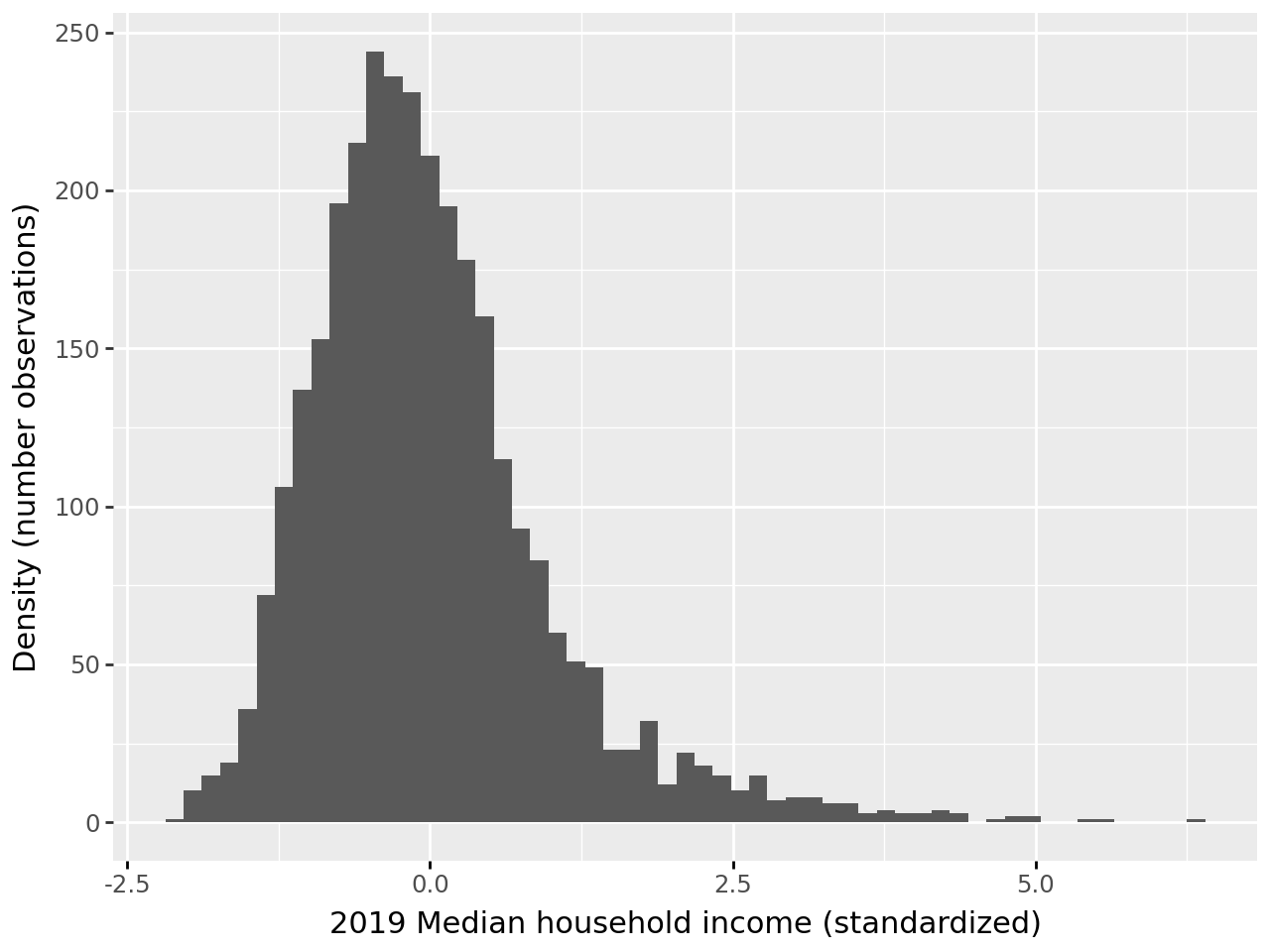
On obtient bien une moyenne égale à 0 et une variance égale à 1, aux approximations numériques prêt :
| Statistique | Valeur | |
|---|---|---|
| 0 | Mean | 0.000000 |
| 1 | Variance | 1.000323 |
À la question 2, si on essaie de représenter les statistiques obtenues dans un tableau lisible, on obtient
| Variable | Mean before Scaling | Std before Scaling | Mean after Scaling | Std after Scaling |
|---|---|---|---|---|
| votes_gop | ||||
| Unemployment_rate_2019 | ||||
| Median_Household_Income_2021 | ||||
| Percent of adults with less than a high school diploma, 2018-22 | ||||
| Percent of adults with a bachelor's degree or higher, 2018-22 | ||||
| y_standard |
On voit très clairement dans ce tableau que la standardisation a bien fonctionné.
Maintenant, si on construit un transformer formel pour nos variables (question 3)
StandardScaler()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Fitted attributes
6 features
| votes_gop |
| Unemployment_rate_2019 |
| Median_Household_Income_2021 |
| Percent of adults with less than a high school diploma, 2018-22 |
| Percent of adults with a bachelor's degree or higher, 2018-22 |
| y_standard |
On peut extrapoler notre standardiseur à un ensemble plus large de données. Si on regarde la distribution obtenue sur les 1000 premières lignes (question 3), on retrouve une échelle cohérente avec une loi \(\mathcal{N(0,1)}\) pour la variable de chômage:
En revanche on voit que cette distribution ne correspond pas à celle qui permettrait de normaliser vraiment le reste des données.
C’est une illustration d’un problème classique en machine learning, le data drift, qui arrive lorsqu’on essaie d’extrapoler à des données dont la distribution ne correspond plus à celle des données d’apprentissage. Ce type de situation arrive typiquement lorsqu’on a entraîné un algorithme sur un échantillon biaisé de la population ou lorsqu’on a des séries temporelles non stationnaires. Il est donc important de bien réfléchir à la constitution de l’échantillon d’apprentissage et aux possibilités d’extrapolation sur une population plus large : la validité externe du modèle - préparation des données ou algorithme d’apprentissage - peut être nulle si cette étape a été réalisée de manière hâtive.
ImportantLe data drift
Le data drift désigne un changement dans la distribution des données au fil du temps, entraînant une dégradation des performances d’un modèle de machine learning qui, par construction, a été entraîné sur des données passées.
Ce phénomène peut survenir à cause de variations dans la population cible, de changements dans les caractéristiques des données ou de facteurs externes.
Il est crucial de détecter le data drift pour ajuster ou réentraîner le modèle, afin de maintenir sa pertinence et sa précision. Les techniques de détection incluent des tests statistiques et le suivi de métriques spécifiques.
4.1.2 Normalisation
La normalisation est l’action de transformer les données de manière
à obtenir une norme (\(\mathcal{l}_1\) ou \(\mathcal{l}_2\)) unitaire.
Autrement dit, avec la norme adéquate, la somme des éléments est égale à 1.
Par défaut, la norme utilisée par Scikit est une norme \(\mathcal{l}_2\).
Cette transformation est particulièrement utilisée en classification de texte ou pour effectuer du clustering.
Au passage, ceci est l’occasion de découvrir comment découper ses données en plusieurs échantillons grâce à la fonction train_test_split de Scikit. Nous allons faire un échantillon de 70% des données pour estimer les paramètres de normalisation (phase d’apprentissage) et extrapoler aux 30% de données restantes. Cette répartition est assez classique mais est bien-sûr adaptable selon les projets. L’avantage d’utiliser train_test_split plutôt que de faire soi-même les échantillonnages avec la méthode sample de Pandas est que la fonction de Scikit permettra d’aller beaucoup plus loin dans le paramétrage de l’échantillonnage, notamment si on désire de la stratification, tout en étant fiable. Faire ceci de manière manuelle est fastidieux et risqué car potentiellement complexe à mettre en oeuvre sans erreur.
AstuceExercice 4 : Normalisation
- A l’aide de la documentation de la fonction
train_test_splitdeScikit, créer deux échantillons (respectivement 70% et 30% des données). - Normaliser la variable
Median_Household_Income_2021(ne pas écraser les valeurs !) et regarder l’histogramme avant/après normalisation. - Vérifier que la norme \(\mathcal{l}_2\) est bien égale à 1 (grâce à la fonction
np.linalg.normet l’argumentaxis=1pour les 10 premières observations, sur l’ensemble d’entraînement puis sur les autres observations.
/home/runner/work/python-datascientist/python-datascientist/.venv/lib/python3.13/site-packages/plotnine/stats/stat_bin.py:112: PlotnineWarning: 'stat_bin()' using 'bins = 46'. Pick better value with 'binwidth'.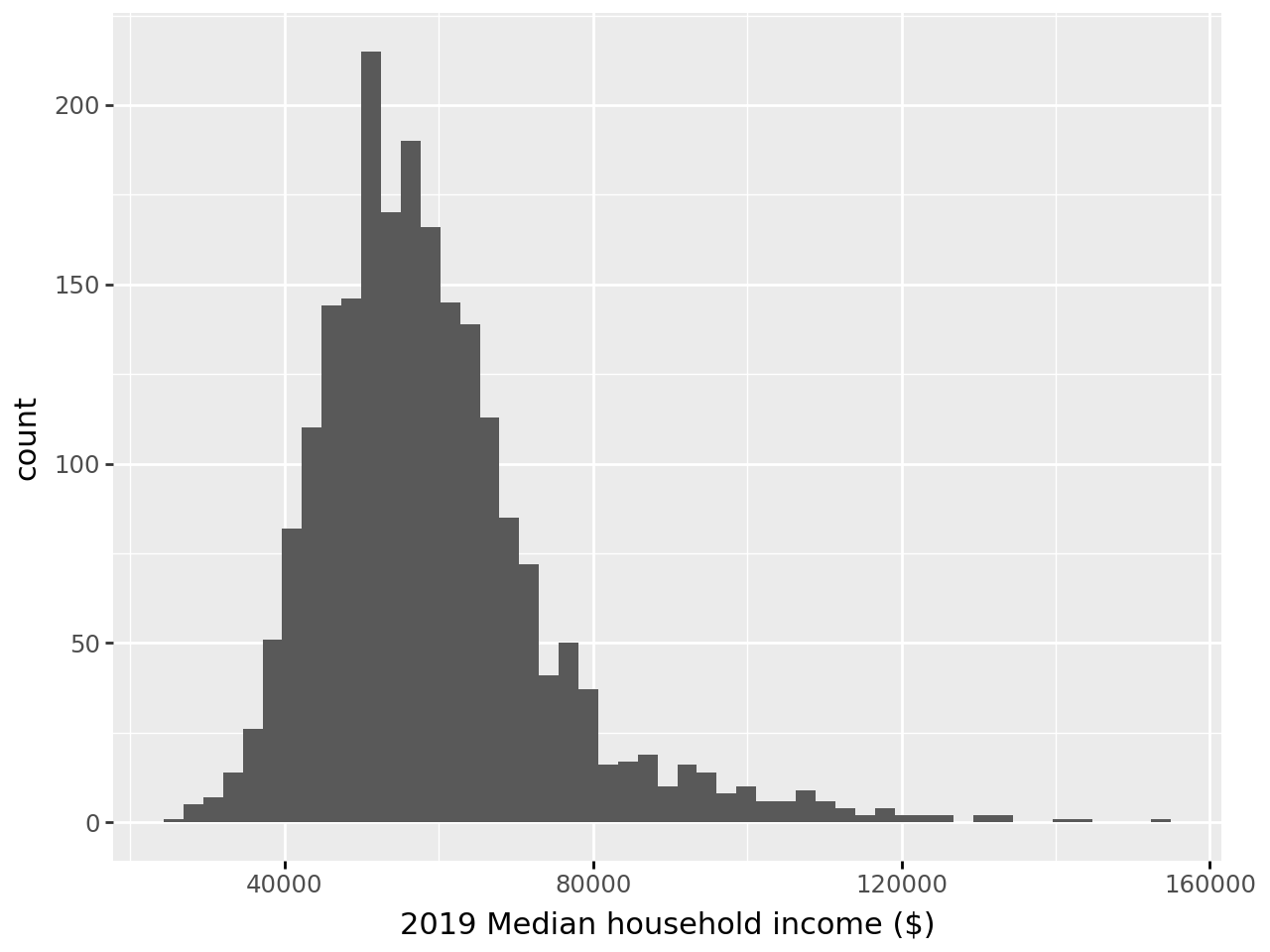
/home/runner/work/python-datascientist/python-datascientist/.venv/lib/python3.13/site-packages/plotnine/stats/stat_bin.py:112: PlotnineWarning: 'stat_bin()' using 'bins = 119'. Pick better value with 'binwidth'.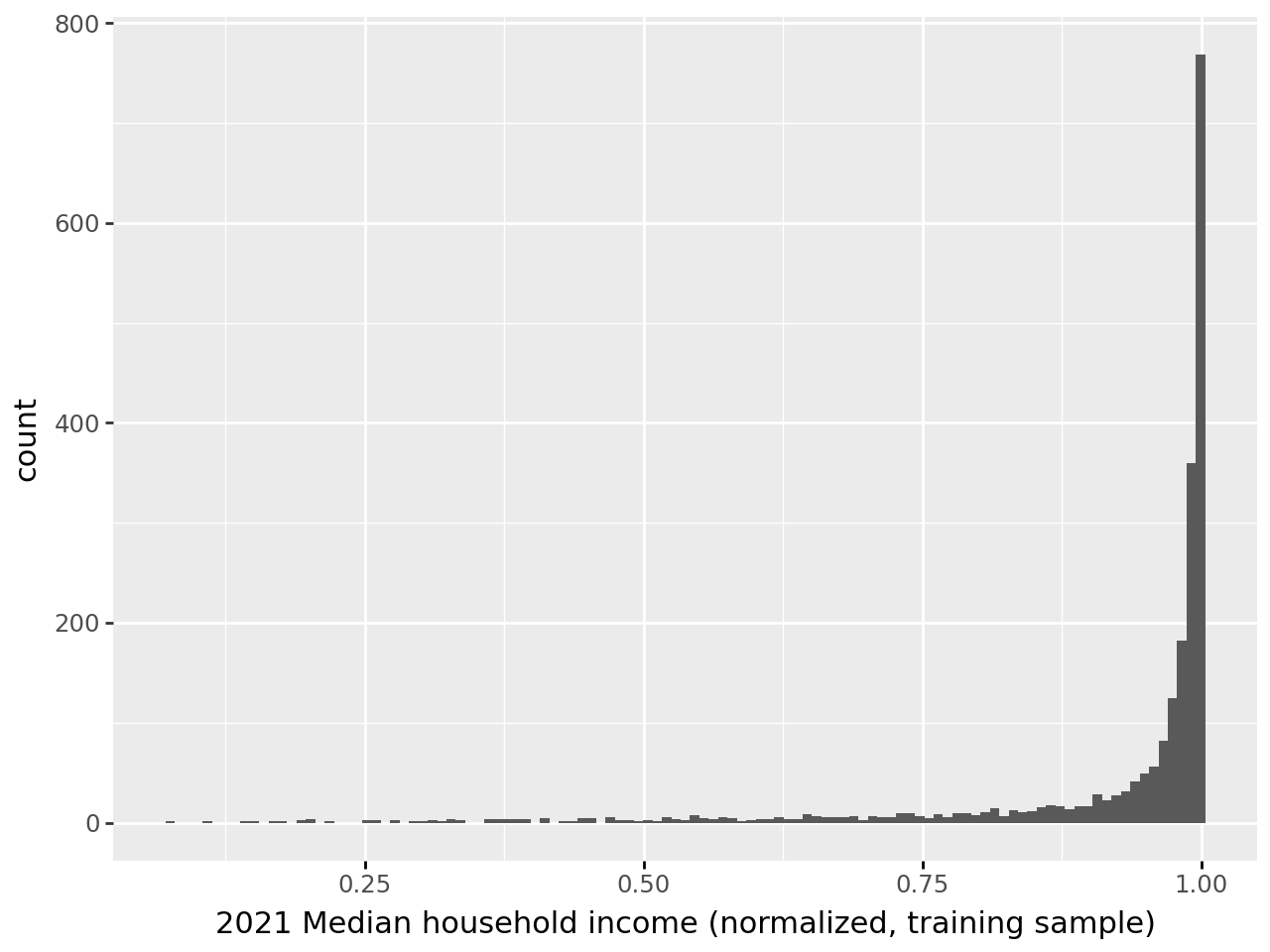
/home/runner/work/python-datascientist/python-datascientist/.venv/lib/python3.13/site-packages/plotnine/stats/stat_bin.py:112: PlotnineWarning: 'stat_bin()' using 'bins = 80'. Pick better value with 'binwidth'.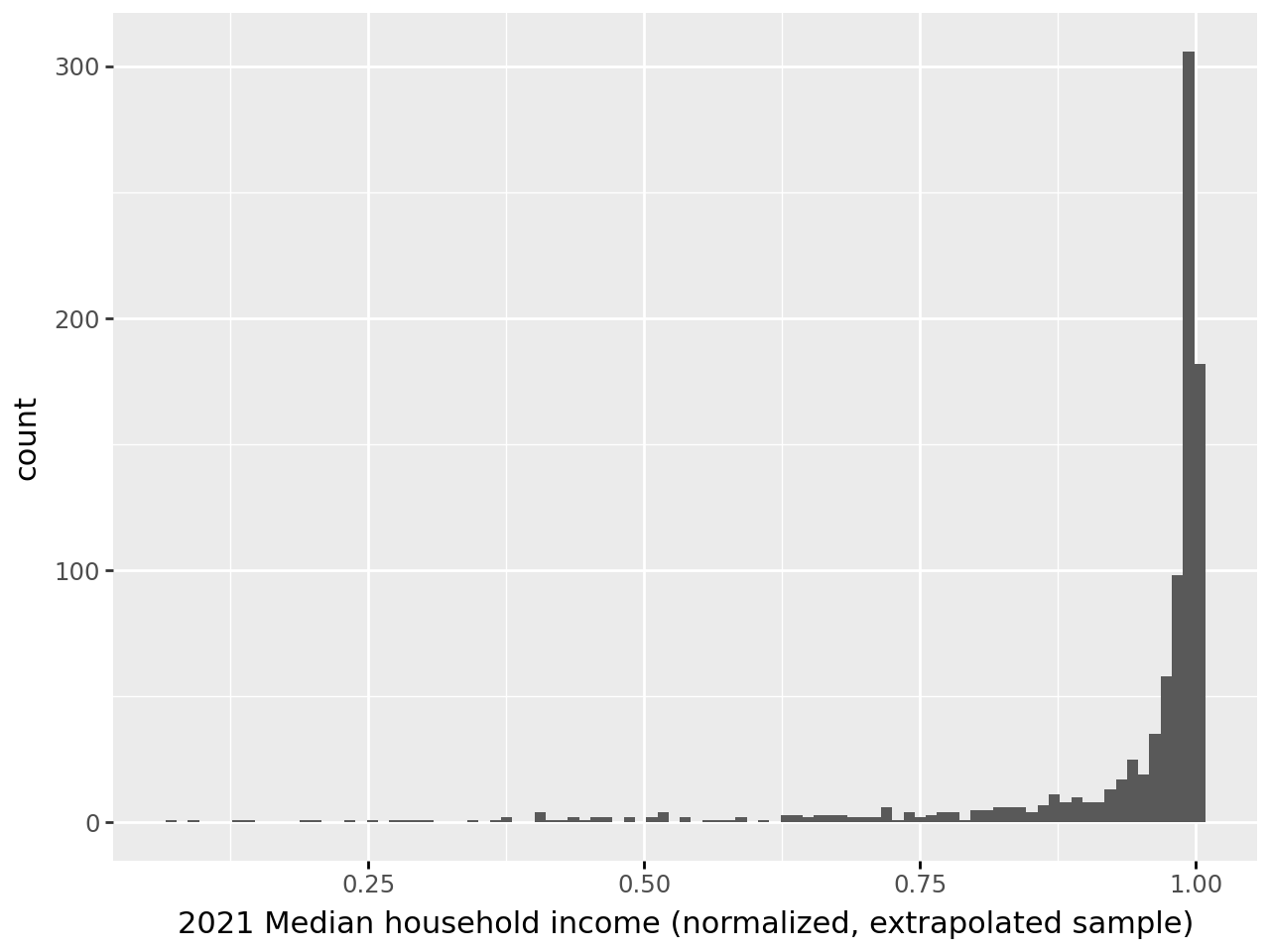
Enfin, si on calcule la norme, on obtient bien le résultat attendu à la fois sur l’échantillon train et sur l’échantillon extrapolé.
| X_train_norm2 | X_test_norm2 | |
|---|---|---|
| 0 | 1.0 | 1.0 |
| 1 | 1.0 | 1.0 |
| 2 | 1.0 | 1.0 |
| 3 | 1.0 | 1.0 |
| 4 | 1.0 | 1.0 |
4.2 Encodage des valeurs catégorielles
Les données catégorielles doivent être recodées sous forme de valeurs numériques pour être intégrés aux modèles de machine learning.
Cela peut être fait de plusieurs manières avec Scikit :
LabelEncoder: transforme un vecteur["a","b","c"]en vecteur numérique[0,1,2]. Cette approche a l’inconvénient d’introduire un ordre dans les modalités, ce qui n’est pas toujours souhaitable.OrdinalEncoder: une version généralisée duLabelEncoderqui a vocation à s’appliquer sur des matrices (\(X\)), alors queLabelEncoders’applique plutôt à un vecteur (\(y\)).
En ce qui concerne le one hot encoding, il est possible d’utiliser plusieurs méthodes :
pandas.get_dummieseffectue une opération de dummy expansion. Un vecteur de taille n avec K catégories sera transformé en matrice de taille \(n \times K\) pour lequel chaque colonne sera une variable dummy pour la modalité k. Il y a ici \(K\) modalités et il y a donc multicolinéarité. Avec une régression linéaire avec constante, il convient de retirer une modalité avant l’estimation.OneHotEncoderest une version généralisée (et optimisée) de la dummy expansion. C’est la méthode recommandée.
4.3 Imputation
Les données peuvent souvent contenir des valeurs manquantes, autrement dit des observations de notre DataFrame contenant un NaN. Ces trous dans les données peuvent être à l’origine de bugs ou de mauvaises interprétations lorsque l’on passe à la modélisation.
Pour y remédier, une première approche peut être de retirer toutes les observations présentant un NaN dans au moins une des ses colonnes.
Cependant, si notre table contient beaucoup de NaN, ou bien que ces derniers sont répartis sur de nombreuses colonnes,
c’est aussi prendre le risque de retirer un nombre important de lignes, et avec cela de l’information importante pour un modèle car les valeurs manquantes sont rarement réparties de manière aléatoire.
Même si dans plusieurs situations, cette solution reste tout à fait viable, il existe une autre approche plus robuste appelée imputation. Cette méthode consiste à remplacer les valeurs manquantes par une valeur donnée. Par exemple :
- Imputation par la moyenne : remplacer tous les
NaNdans une colonne par la valeur moyenne de la colonne ; - Imputation par la médiane sur le même principe, ou par la valeur de la colonne la plus fréquente pour les variables catégorielles ;
- Imputation par régression : se servir d’autres variables pour essayer d’interpoler une valeur de remplacement adaptée.
Des méthodes plus complexes existent mais dans de nombreux cas, les approches ci-dessus peuvent suffire pour donner des résultats beaucoup plus satisfaisants.
Le package Scikit permet de faire de l’imputation de manière très simple (documentation ici).
4.4 Gestion des valeurs aberrantes (outliers)
Les valeurs aberrantes (outliers en anglais) sont des observations qui se situent significativement à l’extérieur de la tendance générale des autres observations dans un ensemble de données. En d’autres termes, ce sont des points de données qui se démarquent de manière inhabituelle par rapport à la distribution globale des données. Cela peut être dû à des erreurs de remplissage, des personnes ayant mal répondu à un questionnaire, ou parfois simplement des valeurs extrêmes qui peuvent biaiser un modèle de façon trop importante.
A titre d’exemple, cela va être 3 individus mesurant plus de 4 mètres dans une population, ou bien des revenus de ménage dépassant les 10M d’euros par mois sur l’échelle d’un pays, etc.
Une bonne pratique peut donc être de systématiquement regarder la distribution des variables à disposition, pour se rendre compte si certaines valeurs s’éloignent de façon trop importante des autres. Ces valeurs vont parfois nous intéresser, si, par exemple, on se concentre uniquement sur les très hauts revenus (top 0.1%) en France. Cependant, ces données vont souvent nous gêner plus qu’autre chose, surtout si elles n’ont pas de sens dans le monde réel.
Si l’on estime que la présence de ces données extrêmes, ou outliers, dans notre base de données vont être problématiques plus qu’autre chose, alors il est tout à fait entendable et possible de simplement les retirer. La plupart du temps, on va se donner une proportion des données à retirer, par exemple 0.1%, 1% ou 5%, puis retirer dans les deux queues de la distribution les valeurs extrêmes correspondantes.
Plusieurs packages permettent de faire ce type d’opérations, qui sont parfois plus complexes si on s’intéresse aux outlier sur plusieurs variables.
On pourra notamment citer la fonction IsolationForest() du package sklearn.ensemble.
4.5 Exercice d’application
Mise en gardeAttention aux nouvelles modalités !
Les transformers créent un mapping entre des modalités textuelles et des valeurs numériques. Cela présuppose que les données sur lesquelles a été construit ce mapping intègrent l’ensemble des valeurs possibles pour les modalités textuelles.
Néanmoins, si de nouvelles modalités apparaissent, le classifieur ne saura pas comment celles-ci doivent être transformées en valeurs numériques. Cela provoquera une erreur pour Scikit. Cette erreur technique est logique puisqu’il faudrait mettre à jour non seulement le mapping mais aussi l’estimation des paramètres sous-jacents.
AstuceExercice 5 : Encoder des variables catégorielles
Créer
dfqui conserve uniquement les variablesstate_nameetcounty_namedansvotes.Appliquer à
state_nameunLabelEncoderNote : Le résultat du label encoding est relativement intuitif, notamment quand on le met en relation avec le vecteur initial.Regarder la dummy expansion de
state_nameAppliquer un
OrdinalEncoderàdf.loc[: , ['state_name', 'county_name']]Note : Le résultat du ordinal encoding est cohérent avec celui du label encodingAppliquer un
OneHotEncoderàdf.loc[:, ['state_name', 'county_name']]
Note : scikit optimise l’objet nécessaire pour stocker le résultat d’un modèle de transformation. Par exemple, le résultat de l’encoding One Hot est un objet très volumineux. Dans ce cas, scikit utilise une matrice Sparse.
Si on regarde les labels et leurs transpositions numériques via LabelEncoder
array([[23, 'Missouri'],
[25, 'Nebraska'],
[30, 'New York'],
...,
[41, 'Texas'],
[41, 'Texas'],
[41, 'Texas']], shape=(3108, 2), dtype=object)| Alabama | Arizona | Arkansas | California | Colorado | Connecticut | Delaware | District of Columbia | Florida | Georgia | ... | South Dakota | Tennessee | Texas | Utah | Vermont | Virginia | Washington | West Virginia | Wisconsin | Wyoming | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 1 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 4 | False | False | False | False | False | False | False | False | False | False | ... | False | True | False | False | False | False | False | False | False | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3103 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 3104 | False | False | False | False | False | False | False | False | False | False | ... | False | False | False | False | False | False | False | False | False | False |
| 3105 | False | False | False | False | False | False | False | False | False | False | ... | False | False | True | False | False | False | False | False | False | False |
| 3106 | False | False | False | False | False | False | False | False | False | False | ... | False | False | True | False | False | False | False | False | False | False |
| 3107 | False | False | False | False | False | False | False | False | False | False | ... | False | False | True | False | False | False | False | False | False | False |
3108 rows × 49 columns
Si on regarde l’OrdinalEncoder:
array([23., 25., 30., ..., 41., 41., 41.], shape=(3108,))<Compressed Sparse Row sparse matrix of dtype 'float64'
with 6216 stored elements and shape (3108, 1892)>Références
Insee. 2018. « Guide de sémiologie cartographique ».
Informations additionnelles
NoteEnvironnement Python
Ce site a été construit automatiquement par le biais d’une action Github utilisant le logiciel de publication reproductible Quarto
L’environnement utilisé pour obtenir les résultats est reproductible par le biais d’uv. Le fichier pyproject.toml utilisé pour construire cet environnement est disponible sur le dépôt linogaliana/python-datascientist
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
Pour utiliser exactement le même environnement (version de Python et packages), se reporter à la documentation d’uv.
NoteHistorique du fichier
| SHA | Date | Author | Description |
|---|---|---|---|
| cf502001 | 2025-12-22 13:38:37 | Lino Galiana | Update de l’environnement (et retrait de yellowbricks au passage) (#665) |
| c216d383 | 2025-11-25 10:43:19 | lgaliana | Corrige typo loc pandas |
| d56f6e9e | 2025-11-25 08:30:59 | lgaliana | Un petit coup de neuf sur les consignes et corrections pandas related |
| c3d51646 | 2025-08-12 17:28:51 | Lino Galiana | Ajoute un résumé au début de chaque chapitre (première partie) (#634) |
| 8fe46396 | 2025-08-12 14:02:32 | lgaliana | Figures de la partie modélisation |
| 99ab48b0 | 2025-07-25 18:50:15 | Lino Galiana | Utilisation des callout classiques pour les box notes and co (#629) |
| 94648290 | 2025-07-22 18:57:48 | Lino Galiana | Fix boxes now that it is better supported by jupyter (#628) |
| 91431fa2 | 2025-06-09 17:08:00 | Lino Galiana | Improve homepage hero banner (#612) |
| 48dccf14 | 2025-01-14 21:45:34 | lgaliana | Fix bug in modeling section |
| 64c12dc5 | 2024-11-07 19:28:22 | lgaliana | English version |
| e945ff4a | 2024-11-07 18:02:05 | lgaliana | update |
| 1a8267a1 | 2024-11-07 17:11:44 | lgaliana | Finalize chapter and fix problem |
| 63b581f6 | 2024-11-07 10:48:51 | lgaliana | Normalisation |
| a2517095 | 2024-11-07 09:31:19 | lgaliana | Exemple |
| e0728909 | 2024-11-06 18:17:32 | lgaliana | Continue le cleaning |
| f3bbddce | 2024-11-06 16:48:47 | lgaliana | Commence revoir premier chapitre modélisation |
| c641de05 | 2024-08-22 11:37:13 | Lino Galiana | A series of fix for notebooks that were bugging (#545) |
| 1cdcd273 | 2024-08-08 07:19:23 | linogaliana | change url |
| 580cba77 | 2024-08-07 18:59:35 | Lino Galiana | Multilingual version as quarto profile (#533) |
| 06d003a1 | 2024-04-23 10:09:22 | Lino Galiana | Continue la restructuration des sous-parties (#492) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 3fba6124 | 2023-12-17 18:16:42 | Lino Galiana | Remove some badges from python (#476) |
| 417fb669 | 2023-12-04 18:49:21 | Lino Galiana | Corrections partie ML (#468) |
| 1f23de28 | 2023-12-01 17:25:36 | Lino Galiana | Stockage des images sur S3 (#466) |
| a06a2689 | 2023-11-23 18:23:28 | Antoine Palazzolo | 2ème relectures chapitres ML (#457) |
| b68369d4 | 2023-11-18 18:21:13 | Lino Galiana | Reprise du chapitre sur la classification (#455) |
| fd3c9557 | 2023-11-18 14:22:38 | Lino Galiana | Formattage des chapitres scikit (#453) |
| 889a71ba | 2023-11-10 11:40:51 | Antoine Palazzolo | Modification TP 3 (#443) |
| 9a4e2267 | 2023-08-28 17:11:52 | Lino Galiana | Action to check URL still exist (#399) |
| a8f90c2f | 2023-08-28 09:26:12 | Lino Galiana | Update featured paths (#396) |
| 80823022 | 2023-08-25 17:48:36 | Lino Galiana | Mise à jour des scripts de construction des notebooks (#395) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| 78ea2cbd | 2023-07-20 20:27:31 | Lino Galiana | Change titles levels (#381) |
| 29ff3f58 | 2023-07-07 14:17:53 | linogaliana | description everywhere |
| f21a24d3 | 2023-07-02 10:58:15 | Lino Galiana | Pipeline Quarto & Pages 🚀 (#365) |
| ebca985b | 2023-06-11 18:14:51 | Lino Galiana | Change handling precision (#361) |
| 129b0012 | 2022-12-26 20:36:01 | Lino Galiana | CSS for ipynb (#337) |
| f5f0f9c4 | 2022-11-02 19:19:07 | Lino Galiana | Relecture début partie modélisation KA (#318) |
| f10815b5 | 2022-08-25 16:00:03 | Lino Galiana | Notebooks should now look more beautiful (#260) |
| 494a85ae | 2022-08-05 14:49:56 | Lino Galiana | Images featured ✨ (#252) |
| d201e3cd | 2022-08-03 15:50:34 | Lino Galiana | Pimp la homepage ✨ (#249) |
| 640b9605 | 2022-06-10 15:42:04 | Lino Galiana | Finir de régler le problème plotly (#236) |
| 5698e303 | 2022-06-03 18:28:37 | Lino Galiana | Finalise widget (#232) |
| 7b9f27be | 2022-06-03 17:05:15 | Lino Galiana | Essaie régler les problèmes widgets JS (#231) |
| 12965bac | 2022-05-25 15:53:27 | Lino Galiana | :launch: Bascule vers quarto (#226) |
| 9c71d6e7 | 2022-03-08 10:34:26 | Lino Galiana | Plus d’éléments sur S3 (#218) |
| 8f99cd32 | 2021-12-08 15:26:28 | linogaliana | hide otuput |
| 9c5f718d | 2021-12-08 14:36:59 | linogaliana | format dico :sob: |
| 41c89864 | 2021-12-08 14:25:18 | linogaliana | correction erreur |
| 64747466 | 2021-12-08 14:08:06 | linogaliana | dict ici aussi |
| 8e73912d | 2021-12-08 12:32:17 | linogaliana | coquille plotly :sob: |
| 37042139 | 2021-12-08 11:57:51 | linogaliana | essaye avec un dict classique |
| 85565d5c | 2021-12-08 08:15:29 | linogaliana | reformat |
| 9ace7b92 | 2021-12-07 17:49:18 | linogaliana | évite la boucle crado |
| 3514e090 | 2021-12-07 16:05:28 | linogaliana | sépare et document |
| 63e67e67 | 2021-12-07 15:15:34 | Lino Galiana | Debug du plotly (temporaire) (#193) |
| 65cecdd8 | 2021-12-07 10:29:18 | Lino Galiana | Encore une erreur de nom de colonne (#192) |
| 81b7023a | 2021-12-07 09:27:35 | Lino Galiana | Mise à jour liste des colonnes (#191) |
| c3bf4d42 | 2021-12-06 19:43:26 | Lino Galiana | Finalise debug partie ML (#190) |
| d91a5eb1 | 2021-12-06 18:53:33 | Lino Galiana | La bonne branche c’est master |
| d86129c0 | 2021-12-06 18:02:32 | Lino Galiana | verbose |
| fb14d406 | 2021-12-06 17:00:52 | Lino Galiana | Modifie l’import du script (#187) |
| 37ecfa3c | 2021-12-06 14:48:05 | Lino Galiana | Essaye nom différent (#186) |
| 2c8fd0dd | 2021-12-06 13:06:36 | Lino Galiana | Problème d’exécution du script import data ML (#185) |
| 5d0a5e38 | 2021-12-04 07:41:43 | Lino Galiana | MAJ URL script recup data (#184) |
| 5c104904 | 2021-12-03 17:44:08 | Lino Galiana | Relec (antuki?) partie modelisation (#183) |
| 2a8809fb | 2021-10-27 12:05:34 | Lino Galiana | Simplification des hooks pour gagner en flexibilité et clarté (#166) |
| 2e4d5862 | 2021-09-02 12:03:39 | Lino Galiana | Simplify badges generation (#130) |
| 49e2826f | 2021-05-13 18:11:20 | Lino Galiana | Corrige quelques images n’apparaissant pas (#108) |
| 4cdb759c | 2021-05-12 10:37:23 | Lino Galiana | :sparkles: :star2: Nouveau thème hugo :snake: :fire: (#105) |
| 7f9f97bc | 2021-04-30 21:44:04 | Lino Galiana | 🐳 + 🐍 New workflow (docker 🐳) and new dataset for modelization (2020 🇺🇸 elections) (#99) |
| 347f50f3 | 2020-11-12 15:08:18 | Lino Galiana | Suite de la partie machine learning (#78) |
| 671f75a4 | 2020-10-21 15:15:24 | Lino Galiana | Introduction au Machine Learning (#72) |
Notes de bas de page
Celui-ci a été généré avec l’aide de
ChatGPTen quelques secondes. Cela m’a évité de me casser la tête sur la structure de données idéale pour reprendre l’exemple des heatmap de la documentation deplotnine.↩︎
Citation
BibTeX
@book{galiana2025,
author = {Galiana, Lino},
title = {Python pour la data science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {fr}
}
Veuillez citer ce travail comme suit :
Galiana, Lino. 2025. Python pour la data science. https://doi.org/10.5281/zenodo.8229676.