AstuceObjet de ce chapitre
- Démarche scientifique et technique à adopter face à un nouveau jeu de données ;
- Découvrir les principaux fournisseurs de données en France et les moyens d’accéder à celles-ci ;
- Discuter des enjeux éthiques derrière le travail des data scientists et des chercheurs en science quantitative
Pour bien débuter des travaux sur une base de données, il est nécessaire de se poser quelques questions de bon sens et de suivre une démarche scientifique dont un certain nombre de gestes prennent une forme assez simple.
Dans un projet sur des jeux de données, on peut schématiquement séparer les étapes en quatre grandes parties :
- La récupération et structuration des données ;
- L’analyse de celle-ci, notamment la production de statistiques descriptives indispensables pour orienter les exploitations ultérieures ;
- La modélisation ;
- La valorisation finale des étapes précédentes et la communication de résultats ou la mise en œuvre d’une chaîne de production.
Ce cours explore ces différentes étapes de manière progressive grâce à
l’écosystème Python qui est très complet. Chaque chapitre du cours
peut être vu comme une manière de progresser dans ce fil conducteur.
Dans ce chapitre, nous allons plutôt mettre en avant quelques réflexions
à avoir avant de se lancer dans chaque étape.
1 Lors de la récupération des données
1.1 Réflexions à mener en amont
La phase de constitution de son jeu de données sous-tend tout le projet qui suit.
La première question à se poser est “de quelles données ai-je besoin pour répondre à ma problématique ?”. Cette problématique pourra éventuellement être affinée en fonction des besoins mais les travaux sont généralement de meilleure qualité lorsque la problématique amène à la réflexion sur les données disponibles plutôt que l’inverse.
Ensuite, “qui produit et met à disposition ces données” ?
Les sources disponibles sur internet sont-elles fiables ?
Les sites d’open data gouvernementaux sont par exemple assez fiables mais autorisent parfois l’archivage de données restructurées par des tiers et non des producteurs officiels. A l’inverse, sur Kaggle ou sur Github la source de certains jeux de données n’est pas tracée ce qui rend compliquée la confiance sur la qualité de la donnée
Une fois identifié une ou plusieurs sources de données, est-ce que je peux les compléter avec d’autres données ? (dans ce cas, faire attention à avoir des niveaux de granularité adéquats).
1.2 Qui produit et diffuse des données en France ?
Lors de la phase de recherche de jeux de données, il est essentiel de connaître les principaux acteurs qui produisent et diffusent des données. Voici un panorama de l’écosystème français de la diffusion de données.
1.2.1 L’Insee et la statistique publique
En premier lieu, les instituts statistiques comme l’Insee (Institut National de la Statistique et des Études Économiques) en France ainsi que les services statistiques ministériels (SSM)1 produisent des données fiables sur de nombreuses problématiques socioéconomiques. Celles-ci sont des statistiques agrégées pouvant, pour certaines sources de données locales, être très fines. Ces statistiques sont produites par le biais d’enquêtes, de données individuelles issues de fichiers administratifs dont l’accès est permis par une loi de 1951 (voir la partie sur la réglementation des données 👇️) ou par l’exploitation de sources de données alternatives, issues par exemple de producteurs privés.
L’Insee produit également des études approfondies exploitant les données qu’elle produit et qu’il est pertinent de lire lorsqu’on découvre une problématique socioéconomique.
Parmi les best-sellers des sources de données disponibles sur le site insee.fr, on retrouve les données du recensement, les chiffres du chômage, le taux d’inflation, le PIB, le fichier des prénoms. Toutes ces sources mesurées par l’Insee, qui sont si utilisées dans le débat public, ont généralement des définitions internationales pour permettre des comparaisons dans le temps et l’espace.
Dans ce cours, nous utiliserons quelques fois des sources diffusées par l’Insee pour avoir des données contextuelles à un niveau agrégé.
1.2.2 L’IGN
L’IGN (Institut National de l’Information Géographique et Forestière) est un autre acteur important qui produit et diffuse des données géographiques et cartographiques de haute qualité en France. Ces données couvrent divers aspects du territoire national, allant des cartes topographiques aux informations sur l’occupation des sols, et sont essentielles pour des projets ayant une dimension géographique.
Nous utiliserons fréquemment certains fonds de carte produit par l’IGN lors de nos chapitres d’analyse spatial.
1.2.3 Les autres administrations et collectivités locales
Contrairement aux administrations de la statistique publique, le reste de l’administration française n’a pas comme mission principale de diffuser du savoir statistique. Néanmoins, les données peuvent occuper une place importante dans les processus internes de ces administrations.
Par exemple, la DGFiP (Direction Générale des Finances Publiques) dispose d’énormément de données issues des déclarations fiscales des Français. Contrairement à l’Insee qui va s’intéresser à ces données pour, par exemple, avoir une vision exhaustive des inégalités économiques ou de la situation des entreprises françaises, la DGFiP s’y intéresse à des fins de gestion régalienne de l’administration et se posera des questions telles que “les ressources correspondent-elles aux attentes et permettront-elles de financer le budget de l’Etat ?”.
Les collectivités locales mettent à disposition un large éventail de données locales. Ces données couvrent divers domaines dans leur champ de compétence : aménagement, infrastructures, budget… Elles sont très pratiques pour des études spécifiques à une région ou une ville, en complément de données locales fournies par d’autres acteurs, notamment l’Insee. Par exemple, dans le cadre de ce cours, nous utiliserons à plusieurs reprises le portail Open Data de la Ville de Paris.
NoteLa DINUM et le portail data.gouv
La DINUM (Direction Interministérielle du Numérique) est une administration centrale en France chargée de coordonner les initiatives numériques au sein de l’État. Elle joue un rôle crucial dans la diffusion des données publiques à travers la plateforme data.gouv qui centralise et met à disposition des milliers de jeux de données produits par les administrations publiques, facilitant ainsi leur réutilisation pour des projets de recherche, d’innovation, ou d’intérêt public.
1.2.4 Les projets contributifs et crowd-sourcés
Des initiatives comme OpenStreetMap, Wikidata, ou OpenFoodFacts reposent sur la contribution volontaire de nombreux utilisateurs pour produire et maintenir des jeux de données. Ces projets sont particulièrement utiles pour obtenir des données géospatiales, encyclopédiques ou sur les produits de consommation, respectivement.
1.2.5 Les données issues d’acteurs privés
Du fait de la numérisation de l’économie, de nombreuses entreprises collectent des données sur leurs utilisateurs ou clients dans le cadre de leurs activités. Ces données, souvent volumineuses et variées, peuvent être exploitées à de multiples fins, notamment pour des analyses de marché ou des études comportementales. L’exploitation de la donnée est certes le coeur de métier d’une partie des entreprises du numérique (notamment les réseaux sociaux) mais de nombreux acteurs exploitent en interne leurs données clients. En Europe, le cadre réglementaire est, depuis 2018, le RGPD (Règlement général sur la protection des données) qui définit les conditions de collecte, stockage et exploitation de données personnelles.
Certaines entreprises peuvent également mettre à disposition ces données, ou une version agrégée, par le biais de projets de recherche ou d’accès via des API. Celles-ci peuvent être intéressantes pour répondre à des questions ciblées, à condition de ne pas oublier qu’elles sont produites à partir d’une certaine clientèle et que l’extrapolation à la population générale n’est pas toujours possible.
1.3 Structuration des données
Vient ensuite la phase de mise en forme et nettoyage des jeux de données récupérés. Cette étape est primordiale et est généralement celle qui mobilise le plus de temps. Pendant quelques années, on parlait de data cleaning. Cependant, cela a pu, implicitement, laisser penser qu’il s’agissait d’une tâche subalterne. On commence à lui préférer le concept de data wrangling ou feature engineering qui souligne bien qu’il s’agit d’une compétence qui nécessite beaucoup de compétences.
Un jeu de données propre est un jeu de données dont la structure est adéquate et n’entraînera pas d’erreur, visible ou non, lors de la phase d’analyse. Comme nous aurons l’occasion de le définir dans les premiers chapitres de la partie Manipulation, l’horizon idéal de structuration est une donnée tidy, c’est-à-dire organisée sous forme de tableau bien structuré.
Voici quelques caractéristiques d’un jeu de données propre :
- les informations manquantes sont bien comprises et traitées.
NumpyetPandasproposent un certain formalisme sur le sujet qu’il est utile d’adopter en remplaçant parNaNles observations manquantes. Cela implique de faire attention à la manière dont certains producteurs codent les valeurs manquantes : certains ont la facheuse tendance à être imaginatifs sur les codes pour valeurs manquantes : “-999”, “XXX”, “NA” - les variables servant d’identifiants sont bien les mêmes d’une table à l’autre (notamment dans le cas de jointures) : même format, même modalités…
- pour des variables textuelles, qui peuvent être mal renseignées, avoir corrigé les éventuelles fautes (ex “Rolland Garros” -> “Roland Garros”)
- créer des variables qui synthétisent l’information dont vous avez besoin
- supprimer les éléments inutiles (colonne ou ligne vide)
- renommer les colonnes avec des noms compréhensibles
2 Lors de l’analyse descriptive
Une fois les jeux de données nettoyés, vous pouvez plus sereinement étudier l’information présente dans les données. Cette phase et celle du nettoyage ne sont pas séquentielles, en réalité vous devrez régulièrement passer de votre nettoyage à quelques statistiques descriptives qui vous montreront un problème, retourner au nettoyage etc.
Les questions à se poser pour “challenger” le jeu de données :
- Est-ce que mon échantillon est bien représentatif de ce qui m’intéresse ? N’avoir que 2000 communes sur les 35000 n’est pas nécessairement un problème mais il est bon de s’être posé la question.
- Est-ce que les ordres de grandeur sont bons ? Pour cela, confronter vos premières statistiques descriptives à vos recherches internet. Par exemple trouver que les maisons vendues en France en 2020 font en moyenne 400 m² n’est pas un ordre de grandeur réaliste.
- Est-ce que je comprends toutes les variables de mon jeu de données ? Est-ce qu’elles se “comportent” de la bonne façon ? À ce stade, il est parfois utile de se faire un dictionnaire de variables (qui explique comment elles sont construites ou calculées). On peut également mener des études de corrélation entre nos variables.
- Est-ce que j’ai des outliers, i.e. des valeurs aberrantes pour certains individus ? Dans ce cas, il faut décider quel traitement on leur apporte (les supprimer, appliquer une transformation logarithmique, les laisser tel quel) et surtout bien le justifier.
- Est-ce que j’ai des premiers grands messages sortis de mon jeu de données ? Est-ce que j’ai des résultats surprenants ? Si oui, les ai-je creusés suffisamment pour voir si les résultats tiennent toujours ou si c’est à cause d’un souci dans la construction du jeu de données (mal nettoyées, mauvaise variable…)
3 Lors de la modélisation
À cette étape, l’analyse descriptive doit avoir donné quelques premières pistes pour savoir dans quelle direction vous voulez mener votre modèle. Une erreur de débutant est de se lancer directement dans la modélisation parce qu’il s’agirait d’une compétence plus poussée. Cela amène généralement à des analyses de pauvre qualité : la modélisation tend généralement à confirmer les intuitions issues de l’analyse descriptive. Si cette dernière n’a pas été sérieusement entreprise, l’interprétation des résultats d’un modèle peut s’avérer inutilement complexe.
Un bagage statistique et économétrique aide à avoir de meilleures intuitions sur les résultats issus d’un modèle. Il n’est pas inutile de voir que les autres cours de votre cursus statistique (Économétrie 1, Séries Temporelles, Sondages, Analyse des données, etc.) peuvent vous aider à trouver le modèle le plus adapté à votre question.
Un point important à avoir en tête est que la méthode sera guidée par l’objectif et non l’inverse. Parmi les questions à considérer :
- Est-ce que vous voulez expliquer ou prédire ? Selon votre réponse à cette question, vous n’allez pas adopter la même approche scientifique ni les mêmes algorithmes.
- Est-ce que vous voulez classer un élément dans une catégorie (de manière supervisée via de la classification ou non supervisée avec du clustering) ou prédire une valeur numérique (régression) ?
En fonction des modèles que vous aurez déjà vus en cours et des questions que vous souhaiterez résoudre sur votre jeu de données, le choix du modèle sera souvent assez direct.
3.1 Lors de la phase de valorisation des travaux
La mise à disposition de code sur Github ou Gitlab est une incitation très forte pour produire du code de qualité. Il est ainsi recommandé de systématiquement utiliser ces plateformes pour la mise à disposition de code. C’est d’ailleurs une consigne obligatoire pour la validation de ce cours.
Cependant, les gains de qualité ne sont pas la seule raison d’adopter l’utilisation de Github ou Gitlab au quotidien. Le cours que je donne avec Romain Avouac en troisième année d’ENSAE (ensae-reproductibilite.github.io/website/) évoque l’un des principaux gains à utiliser ces plateformes, à savoir la possibilité de mettre à disposition automatiquement différents livrables pour valoriser son travail auprès de différents publics.
Selon le public visé, la communication ne sera pas identique. Le code peut intéresser les personnes désirant avoir des détails sur la méthodologie mise en œuvre en pratique mais il peut s’agir d’un format rebutant pour d’autres publics. Une visualisation de données dynamiques parlera à des publics moins experts de la donnée mais est plus dure à mettre en œuvre qu’un graphique standard.
Mise en gardeCaution
Les notebooks Jupyter ont eu beaucoup de succès dans le monde de la data science pour partager des travaux. Pourtant il ne s’agit pas forcément toujours du meilleur format. En effet, beaucoup de notebooks tentent à empiler des pavés de code et du texte, ce qui les rend difficilement lisibles2.
Sur un projet conséquent, il vaut mieux reporter le plus de code possible dans des scripts bien structurés et avoir un notebook qui appelle ces scripts pour produire des outputs. Ou alors ne pas utiliser un notebook et privilégier un autre format (un tableau de bord, un site web, une appli réactive…).
Dans le cours de dernière année de l’ENSAE, Mise en production de projets data science, Romain Avouac et moi revenons sur les moyens de communication et de partage de code alternatifs au notebook.
Si ce cours propose des notebooks, c’est parce qu’ils sont particulièrement adéquats pour l’apprentissage de Python. Les possibilités d’intercaler du texte entre deux blocs de code et l’interactivité sont des fonctionnalités idéales pour la pédagogie. Quand vous serez plus à l’aise avec Python, vous pourrez sortir du notebook pour aller vers l’exécution de scripts.
4 Éthique et responsabilité du data scientist
4.1 La reproductibilité est importante
Les données sont une représentation synthétique de la réalité, et les conclusions de certaines analyses peuvent avoir un impact réel sur la vie des citoyens. Par exemple, les chiffres erronés présentés par Reinhart et Rogoff (2010) ont servi de justification théorique à des politiques d’austérité qui ont eu des conséquences graves pour certains citoyens dans des pays en crise3. En Grande-Bretagne, le recensement des personnes contaminées par le Covid en 2020, ainsi que de leurs proches pour le suivi de l’épidémie, a été incomplet en raison de troncatures dues à l’utilisation d’un format de stockage des données inapproprié (tableur Excel)4.
Un autre exemple est celui du credit scoring mis en œuvre aux États-Unis. La citation ci-dessous, tirée de l’article de Hurley et Adebayo (2016), illustre les conséquences et les aspects problématiques d’un système de construction automatisée d’un score de crédit :
Consumers have limited ability to identify and contest unfair credit decisions, and little chance to understand what steps they should take to improve their credit. Recent studies have also questioned the accuracy of the data used by these tools, in some cases identifying serious flaws that have a substantial bearing on lending decisions. Big-data tools may also risk creating a system of “creditworthinessby association” in which consumers’ familial, religious, social, and other affiliations determine their eligibility for an affordable loan.
Hurley et Adebayo (2016)
Ces problèmes sont malheureusement assez structurels dans le domaine de la recherche. Une équipe de chercheurs de Princeton a pu parler de “crise de la reproductibilité” dans le domaine du machine learning suite à de nombreux échecs à répliquer certaines études (Kapoor et Narayanan 2022). Comme l’évoque Guinnane (2023), de nombreuses études d’histoire économique s’appuient sur des chiffres de population sans fondement.
Certains journaux académiques ont décidé de mettre en oeuvre une approche plus transparente et reproductible. L’American Economic Review (AER), l’une des revues du “top 5” en économie, a une politique assez proactive sur le sujet grâce à son data editor Lars Vilhuber.
4.2 Lutter contre les biais cognitifs
La transparence sur les intérêts et limites d’une méthode mise en oeuvre est donc importante. Cette exigence de la recherche, parfois oubliée à cause de la course aux résultats novateurs, mérite également d’être appliquée en entreprise ou administration. Même sans intention manifeste de la part de la personne qui analyse des données, une mauvaise interprétation est toujours possible.
Tout en valorisant un résultat, il est possible d’alerter sur certaines limites. Il est important, dans ses recherches comme dans les discussions avec d’autres interlocuteurs, de faire attention au biais de confirmation qui consiste à ne retenir que l’information qui correspond à nos conceptions a priori et à ne pas considérer celles qui pourraient aller à l’encontre de celles-ci :

Certaines représentations de données sont à exclure car des biais cognitifs peuvent amener à des interprétations erronées5. Dans le domaine de la visualisation de données, les camemberts (pie chart) ou les diagrammes radar sont par exemple à exclure car l’oeil humain perçoit mal ces formes circulaires. Pour une raison similaire, les cartes avec aplat de couleur (cartes choroplèthes) sont trompeuses. Les posts de blog pour datawrapper de Lisa Charlotte Muth ou ceux d’Eric Mauvière sont d’excellentes ressources pour apprendre les bonnes et mauvaises pratiques de visualisation (voir la partie visualisation de ce cours pour plus de détails).
4.3 Réglementation des données
Le cadre réglementaire de protection des données a évolué ces dernières années avec le RGPD. Cette réglementation a permis de mieux faire saisir le fait que la collecte de données se justifie au nom de finalités plus ou moins bien identifiées. Prendre conscience que la confidentialité des données se justifie pour éviter la dissémination non contrôlée d’informations sur une personne est important. Des données particulièrement sensibles, notamment les données de santé, peuvent être plus contraignantes à traiter que des données peu sensibles.
En Europe, par exemple, les agents du service statistique public (Insee ou services statistiques ministériels) sont tenus au secret professionnel (article L121-6 du Code général de la fonction publique), qui leur interdit la communication des informations confidentielles dont ils sont dépositaires au titre de leurs missions ou fonctions, sous peine des sanctions prévues par l’article 226-13 du Code pénal (jusqu’à un an d’emprisonnement et 15 000 € d’amende). Le secret statistique, défini dans une loi de 1951, renforce cette obligation dans le cas de données détenues pour des usages statistiques. Il interdit strictement la communication de données individuelles ou susceptibles d’identifier les personnes, issues de traitements à finalités statistiques, que ces traitements proviennent d’enquêtes ou de bases de données. Le secret statistique exclut par principe de diffuser des données qui permettraient l’identification des personnes concernées, personnes physiques comme personnes morales. Cette obligation limite la finesse des informations disponibles en diffusion
Ce cadre contraignant s’explique par l’héritage de la Seconde Guerre Mondiale et le désir de ne plus revivre une situation où la collecte d’information sert une action publique basée sur la discrimination entre catégories de la population.
4.4 Partager les moyens de reproduire une analyse
Un article récent de Nature,
qui reprend les travaux d’une équipe d’épidémiologistes (Gabelica, Bojčić, et Puljak 2022)
évoque le problème de l’accès aux données pour des chercheurs désirant reproduire
une étude. Même dans les articles scientifiques où il est mentionné que les
données peuvent être mises à disposition d’autres chercheurs, le partage
de celles-ci est rare :
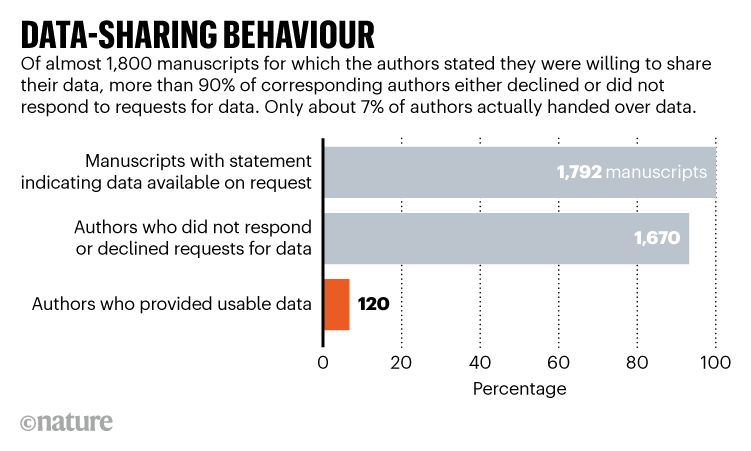
Ce constat, quelque peu inquiétant, est confirmé par une étude récente de Samuel et Mietchen (2023) qui a tenté d’exécuter un peu moins de 30 000 notebooks associés à des études scientifiques. Seuls 3% des notebooks reproduisent les résultats espérés.
Afin de partager les moyens de reproduire des publications sans diffuser des données potentiellement confidentielles, les jeux de données synthétiques sont de plus en plus utilisés. Par le biais de modèles de deep learning, il est ainsi possible de générer des jeux de données synthétiques complexes qui permettent de reproduire les principales caractéristiques d’un jeu de données tout en évitant, si le modèle a été bien calibré, de diffuser une information individuelle.
Dans l’administration française, les codes sources sont considérés comme des documents administratifs et peuvent donc être mis à disposition de tout citoyen sur demande à la Commission d’accès aux documents administratifs (CADA):
« Sont considérés comme documents administratifs, au sens des titres Ier, III et IV du présent livre, quels que soient leur date, leur lieu de conservation, leur forme et leur support, les documents produits ou reçus, dans le cadre de leur mission de service public, par l’État, les collectivités territoriales ainsi que par les autres personnes de droit public ou les personnes de droit privé chargées d’une telle mission. Constituent de tels documents notamment les dossiers, rapports, études, comptes rendus, procès-verbaux, statistiques, instructions, circulaires, notes et réponses ministérielles, correspondances, avis, prévisions, codes sources et décisions. »
Avis 20230314 - Séance du 30/03/2023 de la Commission d’accès aux documents administratifs
En revanche, les poids des modèles utilisés par l’administration, notamment ceux des modèles de machine learning ne sont pas réglementés de la même manière (Avis 20230314 de la CADA). En effet, comme il existe toujours un risque de rétro-ingénierie amenant à une révélation partielle des données d’entraînement lors d’un partage de modèle, les modèles entraînés sur des données sensibles (comme les décisions de justice étudiées par (l’avis 20230314 de la CADA)) n’ont pas vocation à être partagés.
4.5 Adopter une approche écologique
Le numérique constitue une part croissante des émissions de gaz à effet de serre. Représentant aujourd’hui 4 % des émissions mondiales de CO2, cette part devrait encore croître (Arcep 2019). Le monde de la data science est également concerné.
L’utilisation de données de plus en plus massives, notamment la constitution de corpus monumentaux de textes, récupérés par scraping, est une première source de dépense d’énergie. De même, la récupération en continu de nouvelles traces numériques nécessite d’avoir des serveurs fonctionnels en continu. A cette première source de dépense d’énergie, s’ajoute l’entraînement des modèles qui peut prendre des jours, y compris sur des architectures très puissantes. Strubell, Ganesh, et McCallum (2019) estime que l’entraînement d’un modèle à l’état de l’art dans le domaine du NLP nécessite autant d’énergie que ce que consommeraient cinq voitures, en moyenne, au cours de l’ensemble de leur cycle de vie.
L’utilisation accrue de l’intégration continue, qui permet de mettre en oeuvre de manière automatisée l’exécution de certains scripts ou la production de livrables en continu, amène également à une dépense d’énergie importante. Il convient donc d’essayer de limiter l’intégration continue à la production d’output vraiment nouveaux.
NoteNote
Par exemple, cet ouvrage utilise de manière intensive
cette approche. Néanmoins, pour essayer de limiter
les effets pervers de la production en continu d’un
ouvrage extensif, seuls les chapitres modifiés
sont produits lors des prévisualisations mises en
oeuvre à chaque pull request sur le dépôt
Github.
Les data scientists doivent être conscients
des implications de leur usage intensif de
ressources et essayer de minimiser leur
impact. Par exemple, plutôt que ré-estimer
un modèle de NLP,
la méthode de l’apprentissage par transfert,
qui permet de transférer les poids d’apprentissage
d’un modèle à une nouvelle source, permet
de réduire les besoins computationnels.
De même, il peut être utile, pour prendre
conscience de l’effet d’un code trop long,
de convertir le temps de calcul en
émissions de gaz à effet de serre.
Le package codecarbon
propose cette solution en adaptant l’estimation
en fonction du mix énergétique du pays
en question. Mesurer étant le
prérequis pour prendre conscience puis comprendre,
ce type d’initiatives peut amener à responsabiliser
les data scientists et ainsi permettre un
meilleur partage des ressources.
Références
Arcep. 2019. « L’empreinte carbone du numérique ». Rapport de l’Arcep.
Gabelica, Mirko, Ružica Bojčić, et Livia Puljak. 2022. « Many researchers were not compliant with their published data sharing statement: mixed-methods study ». Journal of Clinical Epidemiology.
Guinnane, Timothy W. 2023. « We do not know the population of every country in the world for the past two thousand years ». The Journal of Economic History 83 (3): 912‑38.
Hurley, Mikella, et Julius Adebayo. 2016. « Credit scoring in the era of big data ». Yale JL & Tech. 18: 148.
Kapoor, Sayash, et Arvind Narayanan. 2022. « Leakage and the Reproducibility Crisis in ML-based Science ». arXiv. https://doi.org/10.48550/ARXIV.2207.07048.
Reinhart, Carmen M, et Kenneth S Rogoff. 2010. « Growth in a Time of Debt ». American economic review 100 (2): 573‑78.
Samuel, Sheeba, et Daniel Mietchen. 2023. « Computational reproducibility of Jupyter notebooks from biomedical publications ». https://arxiv.org/abs/2308.07333.
Strubell, Emma, Ananya Ganesh, et Andrew McCallum. 2019. « Energy and Policy Considerations for Deep Learning in NLP ». https://arxiv.org/abs/1906.02243.
Informations additionnelles
NoteEnvironnement Python
Ce site a été construit automatiquement par le biais d’une action Github utilisant le logiciel de publication reproductible Quarto
L’environnement utilisé pour obtenir les résultats est reproductible par le biais d’uv. Le fichier pyproject.toml utilisé pour construire cet environnement est disponible sur le dépôt linogaliana/python-datascientist
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
Pour utiliser exactement le même environnement (version de Python et packages), se reporter à la documentation d’uv.
NoteHistorique du fichier
| SHA | Date | Author | Description |
|---|---|---|---|
| 99ab48b0 | 2025-07-25 18:50:15 | Lino Galiana | Utilisation des callout classiques pour les box notes and co (#629) |
| 94648290 | 2025-07-22 18:57:48 | Lino Galiana | Fix boxes now that it is better supported by jupyter (#628) |
| 91431fa2 | 2025-06-09 17:08:00 | Lino Galiana | Improve homepage hero banner (#612) |
| 5f08b572 | 2024-08-29 10:33:57 | Lino Galiana | Traduction de l’introduction (#551) |
| f8b04136 | 2024-08-28 15:15:04 | Lino Galiana | Révision complète de la partie introductive (#549) |
| c9f9f8a7 | 2024-04-24 15:09:35 | Lino Galiana | Dark mode and CSS improvements (#494) |
| d75641d7 | 2024-04-22 18:59:01 | Lino Galiana | Editorialisation des chapitres de manipulation de données (#491) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 4cd44f35 | 2023-12-11 17:37:50 | Antoine Palazzolo | Relecture NLP (#474) |
| 1f23de28 | 2023-12-01 17:25:36 | Lino Galiana | Stockage des images sur S3 (#466) |
| 652009df | 2023-10-09 13:56:34 | Lino Galiana | Finalise le cleaning (#430) |
| a7711832 | 2023-10-09 11:27:45 | Antoine Palazzolo | Relecture TD2 par Antoine (#418) |
| 154f09e4 | 2023-09-26 14:59:11 | Antoine Palazzolo | Des typos corrigées par Antoine (#411) |
| 6f206430 | 2023-09-25 14:33:20 | Lino Galiana | Correction lien mort cours ENSAE |
| 6dee48d4 | 2023-08-31 11:47:07 | linogaliana | Démarche scientifique |
| fb186dd1 | 2023-08-31 08:42:58 | linogaliana | Ajoute avis CADA |
| 9a4e2267 | 2023-08-28 17:11:52 | Lino Galiana | Action to check URL still exist (#399) |
| 80823022 | 2023-08-25 17:48:36 | Lino Galiana | Mise à jour des scripts de construction des notebooks (#395) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| 2dbf8533 | 2023-07-05 11:21:40 | Lino Galiana | Add nice featured images (#368) |
| b2d48237 | 2022-09-21 17:36:29 | Lino Galiana | Relec KA 21/09 (#273) |
| bacb5a01 | 2022-07-04 19:05:20 | Lino Galiana | Enrichir la partie elastic (#241) |
| 22d4b5ac | 2022-06-30 12:40:41 | Lino Galiana | Corrige la typo pour la ref (#245) |
| 5123634a | 2022-06-30 11:24:49 | Lino Galiana | Amélioration de la première partie (#244) |
| 12965bac | 2022-05-25 15:53:27 | Lino Galiana | :launch: Bascule vers quarto (#226) |
| 2f7b52d9 | 2021-07-20 17:37:03 | Lino Galiana | Improve notebooks automatic creation (#120) |
| aeb39950 | 2021-07-06 11:11:03 | avouacr | Relecture et ajouts sur anaconda + jupyter (#116) |
Notes de bas de page
The French public statistical service consists of Insee and the 16 ministerial statistical services (SSM). These are the departments of ministries responsible for the production and dissemination of public service data. Unlike other departments to which the SSMs are attached, they are not solely focused on supporting public action operationally but primarily on providing quantitative elements useful for public debate and public action.↩︎
In the project submission guidelines (Evaluation section), we recommend avoiding monolithic notebooks and offer some solutions for this.↩︎
Reinhart and Rogoff’s article, “Growth in a Time of Debt”, relied on a manually constructed Excel file. A PhD student discovered errors in it and noted that when official figures were substituted, the results no longer had the same degree of validity.↩︎
It is assumed here that the erroneous message is transmitted without intention to deceive. Manifest manipulation is an even more serious problem.↩︎
It is assumed here that the erroneous message is transmitted without intention to deceive. Manifest manipulation is an even more serious problem.↩︎
Citation
BibTeX
@book{galiana2025,
author = {Galiana, Lino},
title = {Python pour la data science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {fr}
}
Veuillez citer ce travail comme suit :
Galiana, Lino. 2025. Python pour la data science. https://doi.org/10.5281/zenodo.8229676.