# Sur colab
1!pip install pandas fiona shapely pyproj rtree geopandas- 1
- Ces librairies sont utiles pour l’analyse géospatiale (cf. chapitre dédié)

Avec la prolifération de données géolocalisées et l’usage accru de données pour la décision, il est devenu crucial pour les data scientists de savoir faire une carte rapidement. Ce chapitre, complément de celui sur les données spatiales, propose quelques exercices pour apprendre les enjeux de la représentation de données sous forme cartographique avec Python.
La cartographie est l’une des plus anciennes représentations d’informations sous forme graphique. Longtemps cantonnée aux domaines militaires et administratifs ou à la synthèse d’informations pour la navigation, la cartographie est, au moins depuis le XIXe siècle, une des formes privilégiées de représentation de l’information. Il s’agit de l’époque où la carte par aplat de couleur, dite carte choroplèthe, a commencé à devenir une représentation de données géographiques traditionnelle.
D’après Chen et al. (2008), la première représentation de ce type a été proposée par Charles Dupin en 1826 Figure 1.1 pour représenter les niveaux d’instruction sur le territoire français. L’émergence des cartes choroplèthes est en effet indissociable de l’organisation du pouvoir sous forme d’entités politiques supposées unitaires. Par exemple, les cartes du monde représentent souvent des aplats de couleurs à partir des nations, les cartes nationales à partir d’échelons administratifs (régions, départements, communes, mais aussi États ou Länder).
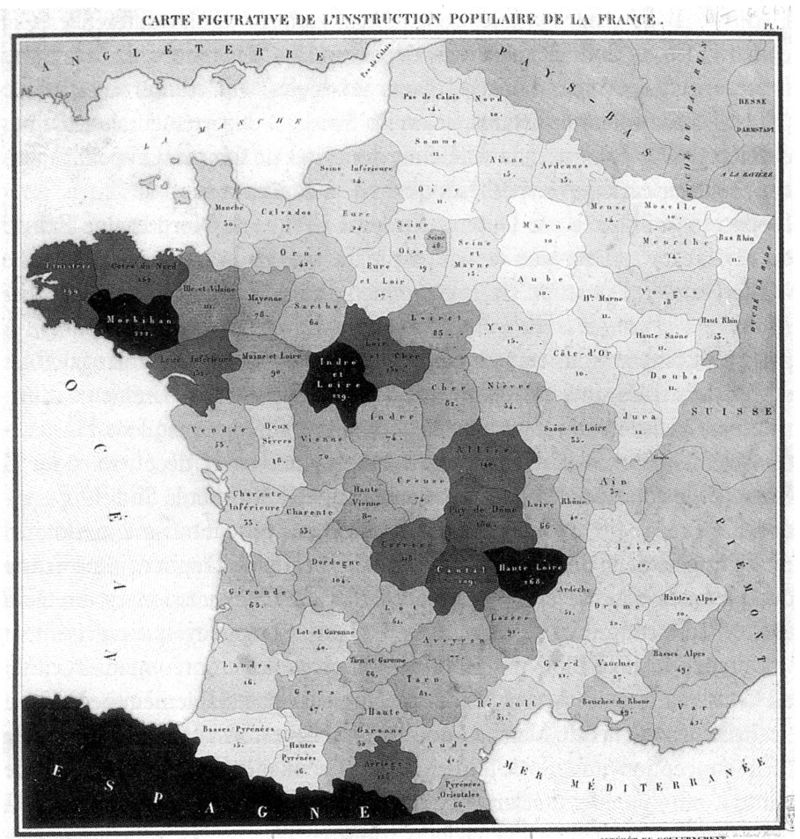
On peut voir l’émergence pendant le XIXe siècle de la carte choroplèthe comme un moment important de la cartographie, un glissement de l’usage militaire vers l’usage politique. Il ne s’agissait plus exclusivement de représenter le territoire physique mais aussi la réalité socioéconomique, dans des bornes administratives connues de tous.
Produire de belles cartes demande du temps mais aussi du bon sens. Comme toute représentation graphique, il est important de réfléchir au message à faire passer et aux moyens appropriés.
La sémiologie cartographique, une discipline scientifique qui s’intéresse aux messages transmis par les cartes, propose certaines règles pour éviter de transmettre des messages faussés, volontairement ou involontairement.
Certaines peuvent être retrouvées à travers des conseils pratiques dans ce guide de sémiologie cartographique de l’Insee. Celles-ci sont reprises dans ce guide.
Cette présentation de Nicolas Lambert revient, à partir de nombreux exemples, sur quelques principes de la dataviz cartographique.
Ce chapitre présentera d’abord quelques fonctionnalités basiques de Geopandas pour la construction de cartes figées. Pour contextualiser l’information présentée, nous utiliserons des contours officiels produits par l’IGN. Nous proposerons ensuite des cartes avec une contextualisation accrue et plusieurs niveaux d’information, ce qui permettra d’illustrer l’intérêt de l’utilisation de librairies réactives, s’appuyant sur JavaScript, comme Folium.
Dans ce chapitre, nous allons utiliser plusieurs jeux de données pour illustrer différents types de cartes :
Avant de pouvoir commencer, il est nécessaire d’installer quelques packages au préalable :
# Sur colab
1!pip install pandas fiona shapely pyproj rtree geopandasNous allons principalement avoir besoin de Pandas et GeoPandas pour ce chapitre.
import pandas as pd
import geopandas as gpdNous allons utiliser cartiflette qui facilite la récupération des fonds de carte administratifs de l’IGN. Ce package est un projet interministériel visant à offrir une interface simple par le biais de Python pour récupérer des découpages officiels de l’IGN.
En premier lieu, nous allons récupérer les limites des départements :
from cartiflette import carti_download
departements = carti_download(
values="France",
crs=4326,
borders="DEPARTEMENT",
vectorfile_format="geojson",
filter_by="FRANCE_ENTIERE_DROM_RAPPROCHES",
source="EXPRESS-COG-CARTO-TERRITOIRE",
year=2022,
)Ces données rapprochent les DROM de la France hexagonale comme c’est expliqué dans l’un des tutoriels de cartiflette et comme l’exercice 1 permettra de le vérifier.
L’exercice 1 vise à s’assurer que nous avons bien récupéré les contours voulus en les représentant simplement. Ceci devrait être le premier réflexe de tout geodata scientist.
plot sur le jeu de données departements pour vérifier l’emprise spatiale. Les coordonnées affichées vous évoquent quelle projection ? Vérifier avec la méthode crs.matplotlib adéquates, représenter une carte avec les contours noirs, le fond blanc et sans axes.La carte des départements, sans modifier aucune option, ressemble à celle-ci :
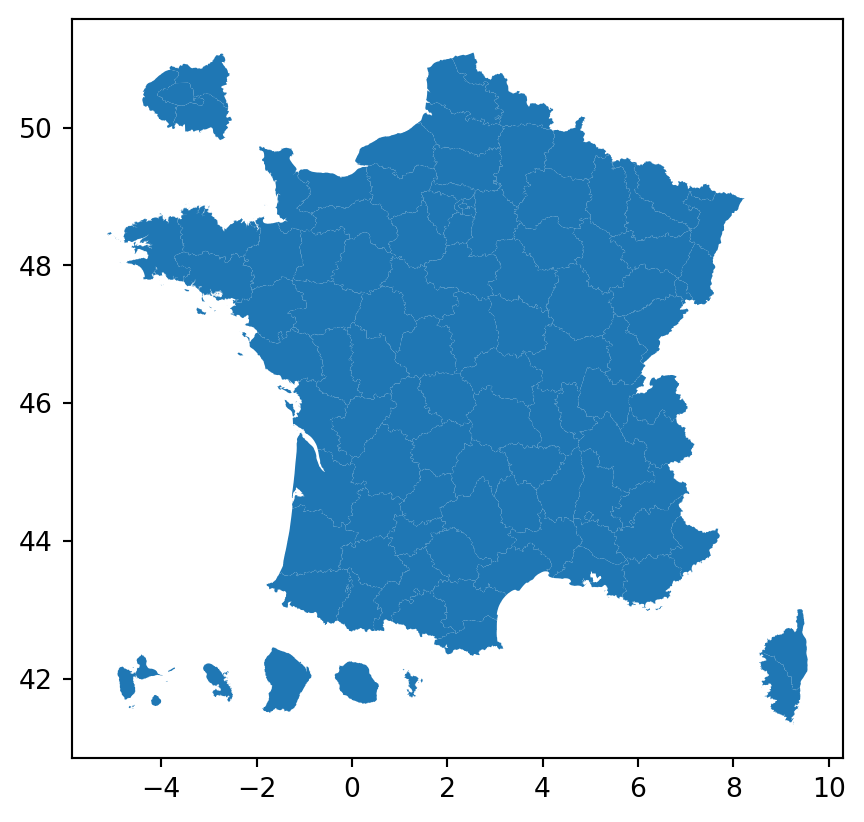
Les coordonnées affichées nous suggèrent du WGS84, ce qu’on peut vérifier avec la méthode crs :
<Geographic 2D CRS: EPSG:4326>
Name: WGS 84
Axis Info [ellipsoidal]:
- Lat[north]: Geodetic latitude (degree)
- Lon[east]: Geodetic longitude (degree)
Area of Use:
- name: World.
- bounds: (-180.0, -90.0, 180.0, 90.0)
Datum: World Geodetic System 1984 ensemble
- Ellipsoid: WGS 84
- Prime Meridian: GreenwichSi on fait la conversion en Lambert 93 (système légal pour l’hexagone), on obtient une emprise différente mais qui est censée être plus véridique pour la métropole (mais pas pour les DROM rapprochés puisque, par exemple, la Guyane est en principe beaucoup plus grande).
Et bien sûr, on retrouve facilement les cartes ratées du chapitre sur GeoPandas, par exemple si on applique une transformation prévue pour l’Amérique du Nord :
departements.to_crs(5070).plot()
Si on fait une carte un petit peu plus esthétique, cela nous donne :
Et la même pour le Finistère :
Ces cartes sont simples et pourtant elles font déjà appel à des connaissances implicites. Elles demandent déjà une connaissance du territoire. Quand nous commencerons à coloriser certains départements, savoir lesquels ont des valeurs extrêmes implique de bien connaître sa géographie française. De même, cela apparaît certes évident, mais rien ne dit dans notre carte du Finistère que ce département est bordé par l’océan. Un lecteur français le verra comme une évidence, mais ce n’est pas forcément le cas d’un lecteur étranger qui, bien sûr, ne connaît pas le détail de notre géographie.
Pour cela, nous avons des parades grâce aux cartes réactives qui permettent :
Pour ceci, nous allons garder uniquement les données correspondant à une réelle emprise spatiale, ce qui exclut notre zoom de l’Île-de-France et les DROM.
On obtient bien l’hexagone :
departements_hexagone.plot()
Pour le prochain exercice, nous allons avoir besoin de quelques variables supplémentaires. En premier lieu, le centre géométrique de la France, qui nous permettra de placer le centre de notre carte.
minx, miny, maxx, maxy = departements_hexagone.total_bounds
center = [(miny + maxy) / 2, (minx + maxx) / 2]Nous allons aussi avoir besoin d’un dictionnaire pour renseigner à Folium des informations sur les paramètres de notre carte.
style_function = lambda x: {
1 'fillColor': 'white',
'color': 'black',
'weight': 1.5,
'fillOpacity': 0.0
}fillOpacity à 0%.
style_function est une fonction anonyme qui sera utilisée dans l’exercice.
Une information qui s’affiche lorsqu’on passe la souris s’appelle un tooltip en langage de développement web.
import folium
tooltip = folium.GeoJsonTooltip(
fields=['LIBELLE_DEPARTEMENT', 'INSEE_DEP', 'POPULATION'],
aliases=['Département:', 'Numéro:', 'Population:'],
localize=True
)Pour le prochain exercice, il faudra utiliser le GeoDataFrame dans la projection Mercator. En effet, Folium attend des données dans cette projection car cette librairie se base sur les fonds de carte de navigation, qui sont adaptés à cette représentation. En principe, on utilise plutôt Folium pour des représentations locales, où la déformation des surfaces induite par la projection Mercator n’est pas problématique.
Pour le prochain exercice, où nous représenterons la France dans son ensemble, nous faisons donc un usage quelque peu détourné de la librairie. Mais la France étant encore assez lointaine du pôle Nord, la déformation reste un prix à payer faible par rapport aux gains de l’interactivité.
center et le niveau zoom_start égal à 5.departements_hexagone et les paramètres style_function et tooltip.Voici la couche de fond de la question 1:
Et une fois mise en forme, cela nous donne la carte:
<folium.features.GeoJson at 0x7f02c9c49010>Lorsqu’on passe sa souris sur la carte ci-dessus, on obtient quelques informations contextuelles. On peut donc jouer sur différents niveaux d’information : un premier coup d’œil permet de se représenter les données dans l’espace, une recherche approfondie permet d’avoir des informations secondaires, utiles à la compréhension, mais pas indispensables.
Ces premiers exercices illustraient une situation où on ne désire représenter que les limites des polygones. C’est une carte utile pour rapidement placer son jeu de données dans l’espace, mais cela n’apporte pas d’information supplémentaire. Pour cela, il va être nécessaire d’utiliser les données tabulaires associées à la dimension spatiale.
Pour cette partie, nous allons faire une carte du couvert forestier landais à partir de la BD Forêt produite par l’IGN. L’objectif n’est plus seulement de placer des limites du territoire d’intérêt mais de représenter de l’information sur celui-ci à partir des données présentes dans un GeoDataFrame.
La BD Forêt étant un peu volumineuse dans le format shapefile, nous proposons de la récupérer dans un format plus compressé : le geopackage.
foret = gpd.read_file(
"https://minio.lab.sspcloud.fr/projet-formation/diffusion/r-geographie/landes.gpkg"
)Nous allons aussi créer un masque pour les contours du département:
landes = (
departements
.loc[departements["INSEE_DEP"] == "40"].to_crs(2154)
)Créer une carte du couvert forestier des Landes à partir des données importées précédemment depuis la BD Forêt. Vous pouvez ajouter les limites du département pour contextualiser cette carte.
Cette carte peut être créée via Geopandas et matplotlib ou via plotnine (cf. chapitre précédent).
Comme on peut le voir sur la carte (Figure 3.1), le département des Landes est très forestier. Ceci est logique puisque les deux tiers du département sont couverts, ce qu’on peut vérifier avec le calcul suivant1 :
f"Part du couvert forestier dans les Landes: {float(foret.area.sum()/landes.area.sum()):.0%}"'Part du couvert forestier dans les Landes: 65%'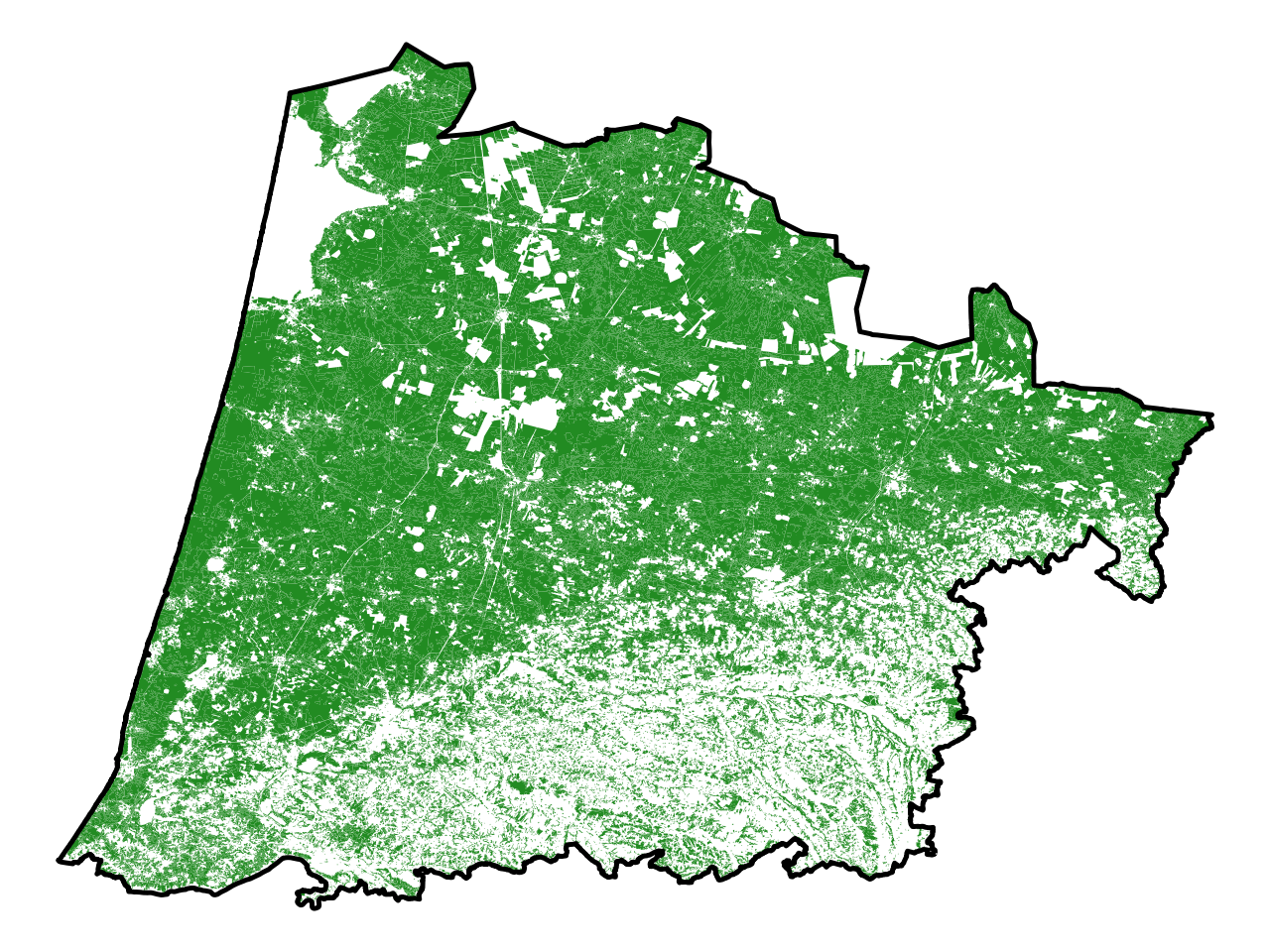
Ici, la carte est assez claire et donne un message relativement lisible. Bien sûr, on ne dispose pas de détails qui pourraient intéresser les curieux (par exemple, quelles localités sont particulièrement couvertes), mais on dispose d’une vision synthétique du phénomène étudié.
L’exercice précédent nous a permis de créer une carte par aplat de couleur. Ceci nous amène naturellement vers la carte choroplèthe, où l’aplat de couleur vise à représenter une information socioéconomique.
Nous allons utiliser les données de population présentes dans les données récupérées par le biais de cartiflette2. Nous allons nous amuser à créer la carte choroplèthe en lui donnant le style vintage des premières cartes de Dupin (1826).
L’objectif de cet exercice va être d’enrichir les informations présentées sur la carte des départements.
Représenter rapidement la carte des départements en colorant en fonction de la variable POPULATION.
Cette carte présente plusieurs problèmes :
Les prochaines questions visent à améliorer ceci progressivement.
Refaire cette carte dans la projection Lambert 93.
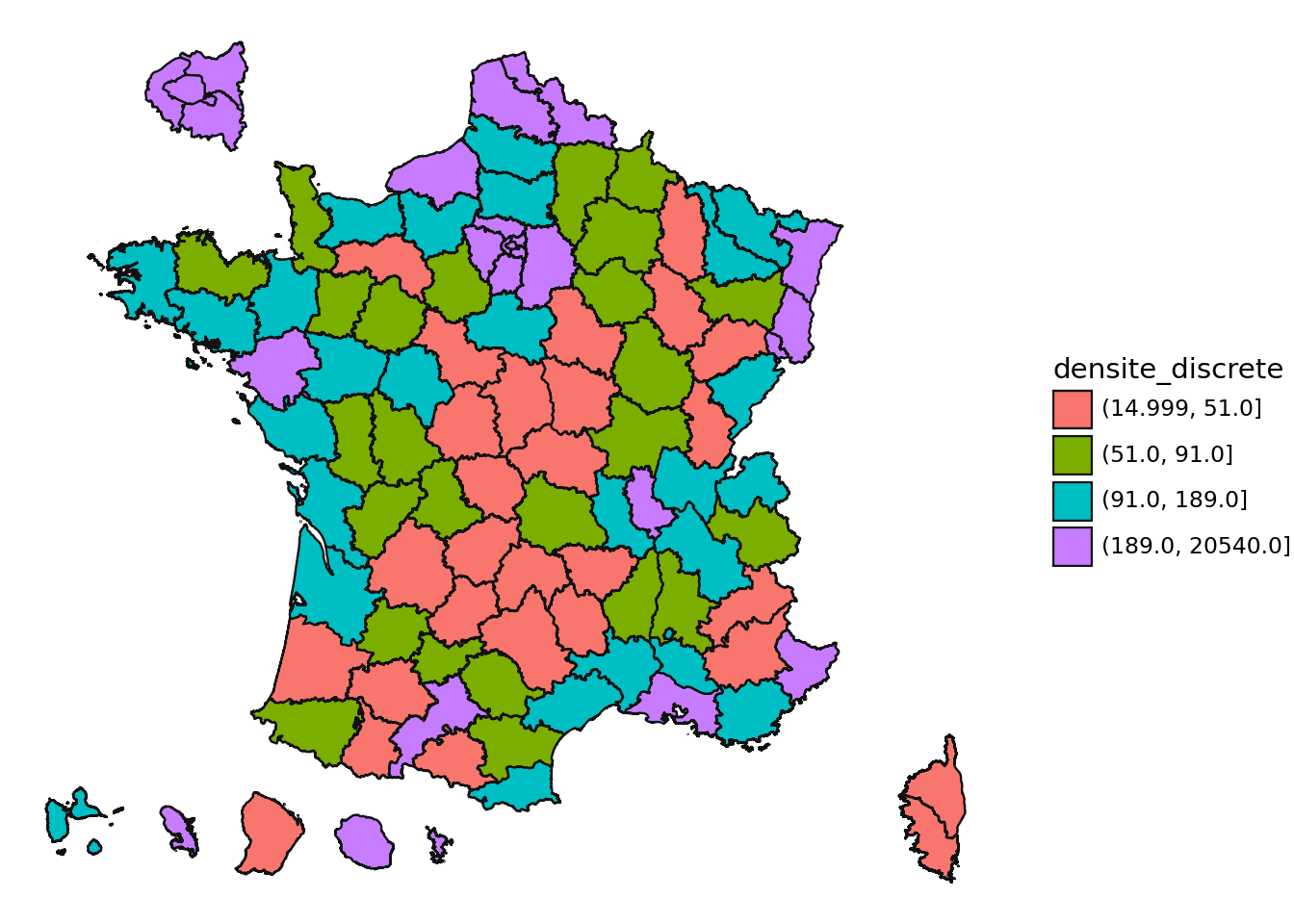
Discrétiser la variable POPULATION en utilisant 4 classes par le biais d’une discrétisation par quantile. Refaire la carte.
Diviser votre population par la taille de chaque département (en km²) en créant une variable à partir de .area.div(1e6)3.
Choisir une palette de couleur vintage type échelle de gris.
La première question donne une carte ayant cet aspect :
Elle est déjà améliorée par l’utilisation d’une projection adaptée pour le territoire, le Lambert 93 (question 2) :
La carte ci-dessous, après discrétisation (question 3), donne déjà une représentation plus véridique des inégalités de population. On remarque que la diagonale du vide commence à se dessiner, ce qui est logique pour une carte de population.
Cependant, l’un des problèmes des choroplèthes est qu’elles donnent un poids exagéré aux grands espaces. Ceci avait été particulièrement mis en avant dans le cas des cartes électorales avec le visuel “Land doesn’t vote, people do” (version élections européennes de 2024).
Sans pouvoir totalement s’abstraire de ce problème — pour cela, il faudrait changer de type de représentation graphique, par exemple avec des ronds proportionnels — on peut déjà réduire l’effet de la surface sur notre variable d’intérêt en représentant la densité (population au km² plutôt que la population).
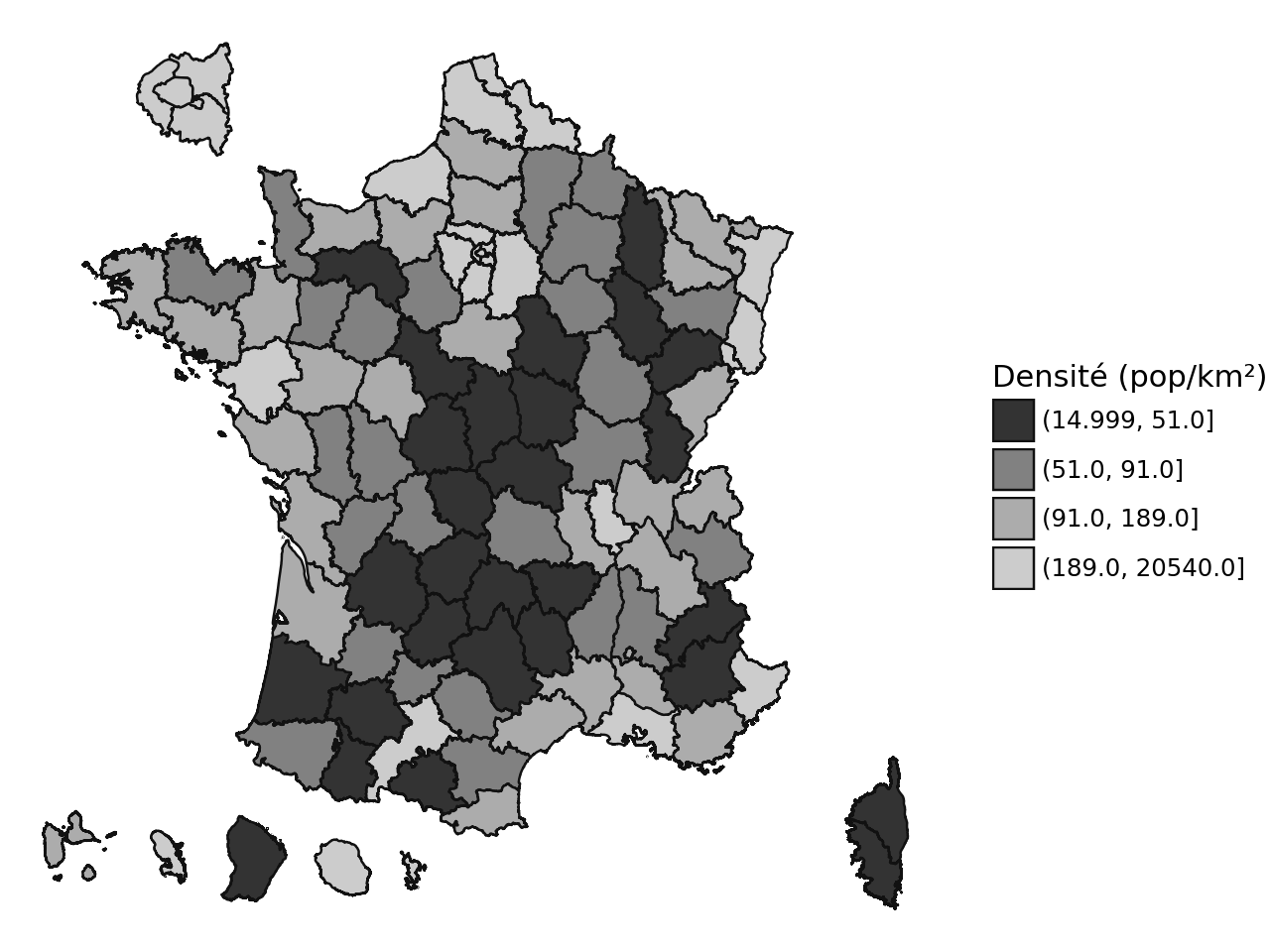
On obtient donc la carte suivante lorsqu’on représente la densité plutôt que la population totale :
Cela nous donne déjà une image plus véridique de la distribution de la population sur le territoire français. Néanmoins, la palette de couleur desigual utilisée par défaut n’aide pas trop à saisir les nuances. Avec une palette de couleur en nuancier, qui tient compte de l’aspect ordinal de nos données, on obtient une carte plus lisible (question 5) :
C’est déjà mieux. Néanmoins, pour avoir une meilleure carte, il faudrait choisir une discrétisation plus adéquate. C’est un travail itératif important, qui mobilise plusieurs domaines de compétences : statistique, sociologie ou économie selon le type d’information représentée, informatique, etc. Bref, la palette normale de compétences d’un data scientist.
Jusqu’à présent, nous avons travaillé sur des données où, en soi, représenter des frontières administratives suffisait pour contextualiser. Penchons-nous maintenant sur le cas où avoir un fonds de carte contextuel va devenir crucial : les cartes infracommunales.
Pour cela, nous allons représenter la localisation des stations Vélib’. Celles-ci sont disponibles en open data sur le site de la Mairie de Paris.
La localisation des stations de Vélib est disponible sur le portail open data de la ville de Paris sous la forme d’un fichier GeoJSON:
import geopandas as gpd
velib_data = "https://opendata.paris.fr/explore/dataset/velib-emplacement-des-stations/download/?format=geojson&timezone=Europe/Berlin&lang=fr"
stations = gpd.read_file(velib_data)
stations.head(2)| capacity | stationcode | coordonnees_geo | name | geometry | |
|---|---|---|---|---|---|
| 0 | 26 | 6032 | [48.852575112948415, 2.331552766263485] | Sabot - Rennes | POINT (2.33155 48.85258) |
| 1 | 22 | 15107 | [48.833468517426, 2.2858720645308] | Palais des Sports | POINT (2.28587 48.83347) |
Les limites administratives de la zone d’intérêt seront également utiles à l’analyse des données. Voici un code pour les récupérer.
from cartiflette import carti_download
# 1. Fonds communaux
contours_villes_arrt = carti_download(
values = ["75", "92", "93", "94"],
crs = 4326,
borders="COMMUNE_ARRONDISSEMENT",
filter_by="DEPARTEMENT",
source="EXPRESS-COG-CARTO-TERRITOIRE",
year=2022)
# 2. Départements
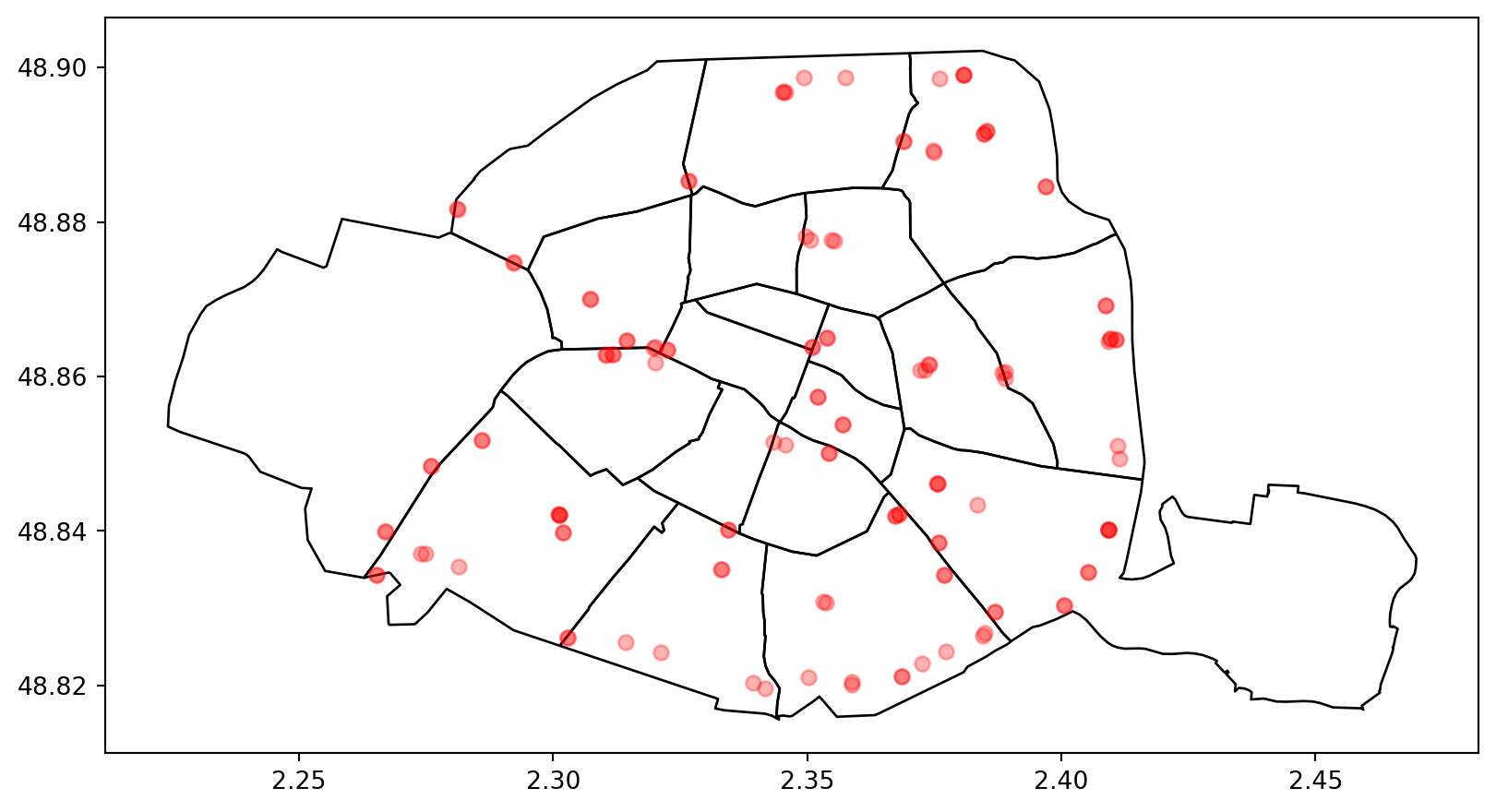
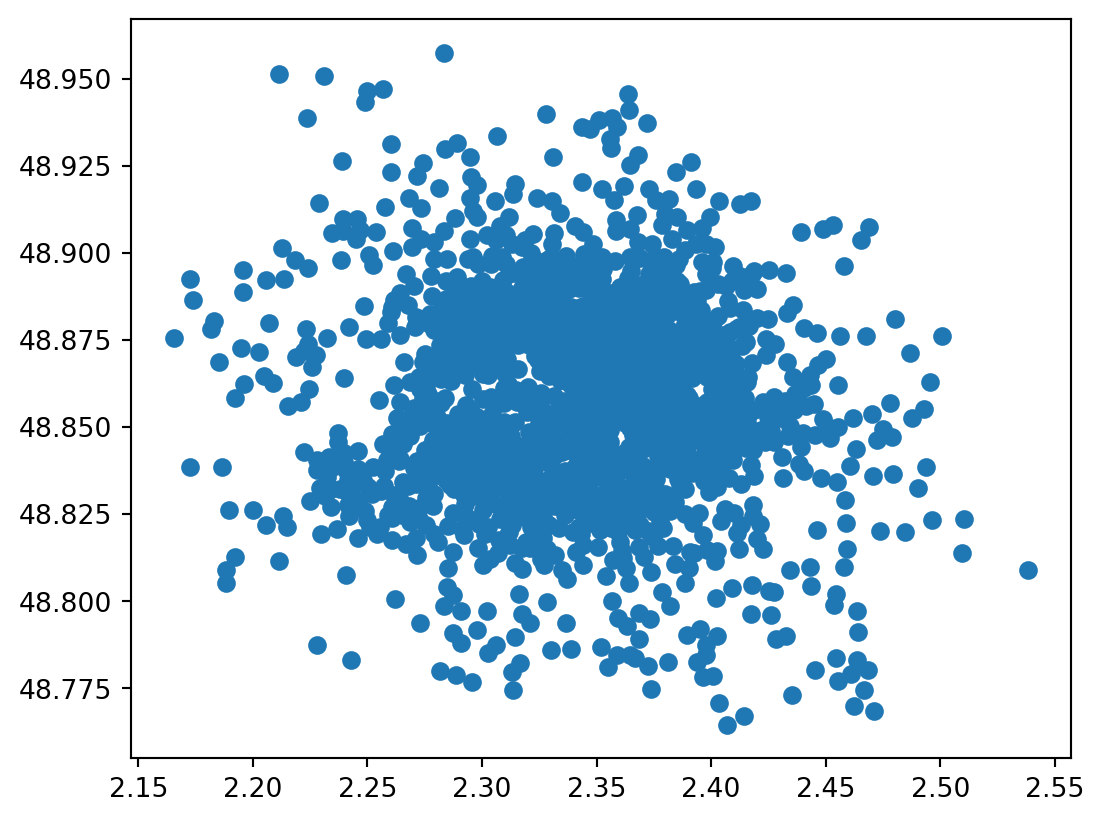
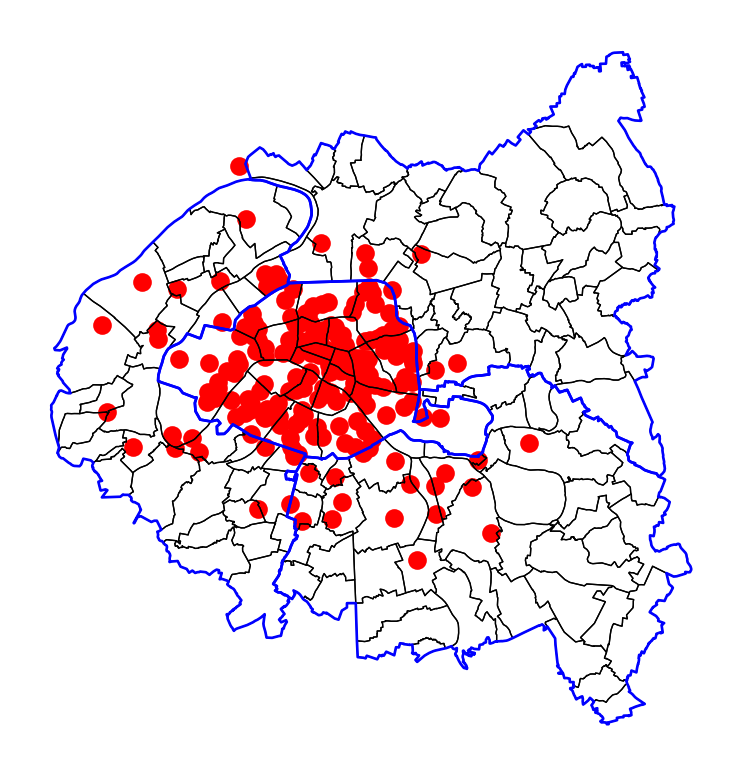
departements = contours_villes_arrt.dissolve("INSEE_DEP")plot. Êtes-vous en mesure de déterminer où elles se trouvent ?MarkerCluster de Folium pour créer une carte interactive.Si on représente directement les stations avec la méthode plot, on manque de contexte :
Il est même impossible de savoir si on se trouve réellement dans Paris. On peut essayer d’associer nos données aux découpages administratifs pour vérifier que nous sommes bien dans la région parisienne.
La première étape est de récupérer les découpages des arrondissements parisiens et des communes limitrophes, ce qui se fait facilement avec cartiflette :
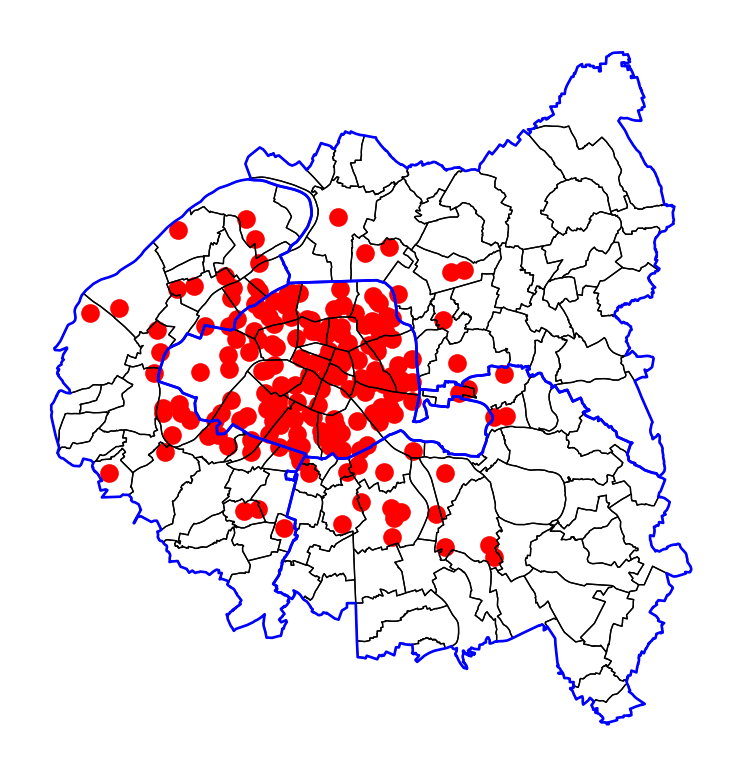
Si maintenant on utilise le masque des limites administratives pour contextualiser les données, on est rassuré sur la nature de celles-ci ; on se trouve bien dans l’agglomération parisienne.
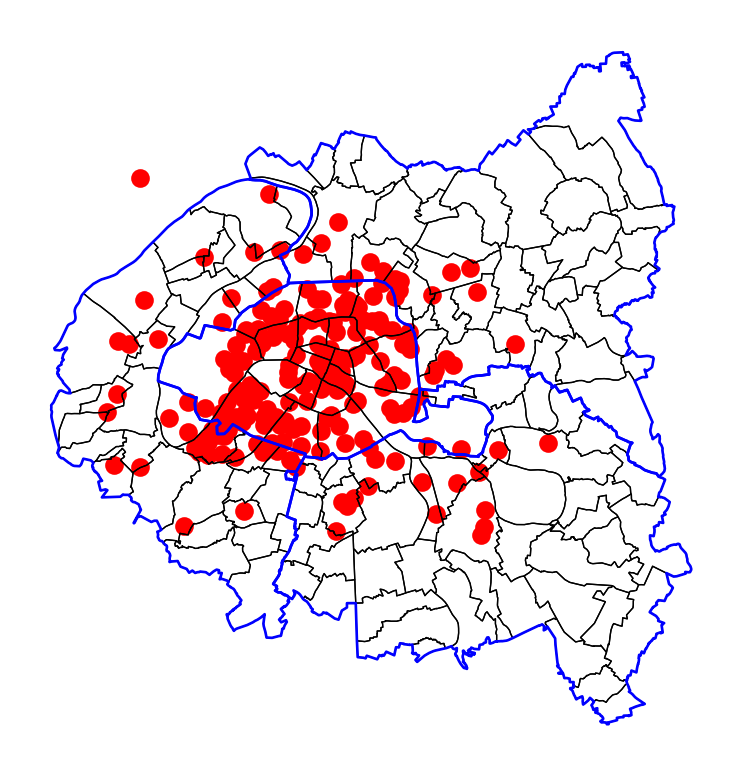
Les Parisiens reconnaîtront facilement leur bourgade car ils connaissent bien l’organisation de l’espace de cette agglomération. Cependant, pour des lecteurs ne connaissant pas celle-ci, cette carte sera de peu de secours. L’idéal est plutôt d’utiliser le fonds de carte contextuel de Folium pour cela.
Afin de ne pas surcharger la carte, il est utile d’utiliser la dimension réactive de Folium en laissant l’utilisateur.trice naviguer dans la carte et afficher un volume d’information adapté à la fenêtre visible. Pour cela, Folium embarque une fonctionnalité MarkerCluster très pratique.
On peut ainsi produire la carte désirée de cette manière :
Ce site a été construit automatiquement par le biais d’une action Github utilisant le logiciel de publication reproductible Quarto
L’environnement utilisé pour obtenir les résultats est reproductible par le biais d’uv. Le fichier pyproject.toml utilisé pour construire cet environnement est disponible sur le dépôt linogaliana/python-datascientist
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
Pour utiliser exactement le même environnement (version de Python et packages), se reporter à la documentation d’uv.
| SHA | Date | Author | Description |
|---|---|---|---|
| f250c24f | 2025-12-13 19:15:02 | Lino Galiana | Un essai d’histogramme en légende (#661) |
| c3d51646 | 2025-08-12 17:28:51 | Lino Galiana | Ajoute un résumé au début de chaque chapitre (première partie) (#634) |
| 94648290 | 2025-07-22 18:57:48 | Lino Galiana | Fix boxes now that it is better supported by jupyter (#628) |
| 91431fa2 | 2025-06-09 17:08:00 | Lino Galiana | Improve homepage hero banner (#612) |
| 26226eea | 2025-01-31 17:54:48 | lgaliana | Chapitre cartographie en anglais |
| cbe6459f | 2024-11-12 07:24:15 | lgaliana | Revoir quelques abstracts |
| 886389c4 | 2024-10-21 08:59:14 | lgaliana | rappel mercator folium |
| 9cf2bde5 | 2024-10-18 15:49:47 | lgaliana | Reconstruction complète du chapitre de cartographie |
| d2422572 | 2024-08-22 18:51:51 | Lino Galiana | At this point, notebooks should now all be functional ! (#547) |
| 06d003a1 | 2024-04-23 10:09:22 | Lino Galiana | Continue la restructuration des sous-parties (#492) |
| 8c316d0a | 2024-04-05 19:00:59 | Lino Galiana | Fix cartiflette deprecated snippets (#487) |
| ce33d5dc | 2024-01-16 15:47:22 | Lino Galiana | Adapte les exemples de code de cartiflette (#482) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 3fba6124 | 2023-12-17 18:16:42 | Lino Galiana | Remove some badges from python (#476) |
| 4cd44f35 | 2023-12-11 17:37:50 | Antoine Palazzolo | Relecture NLP (#474) |
| 1f23de28 | 2023-12-01 17:25:36 | Lino Galiana | Stockage des images sur S3 (#466) |
| b68369d4 | 2023-11-18 18:21:13 | Lino Galiana | Reprise du chapitre sur la classification (#455) |
| 09654c71 | 2023-11-14 15:16:44 | Antoine Palazzolo | Suggestions Git & Visualisation (#449) |
| 889a71ba | 2023-11-10 11:40:51 | Antoine Palazzolo | Modification TP 3 (#443) |
| ad654c5f | 2023-10-10 14:23:05 | linogaliana | CQuick fix gzip csv |
| 1c646606 | 2023-10-04 15:52:52 | Lino Galiana | Quick fix remove contextily (#420) |
| 154f09e4 | 2023-09-26 14:59:11 | Antoine Palazzolo | Des typos corrigées par Antoine (#411) |
| c7f8c941 | 2023-09-01 09:27:43 | Lino Galiana | Ajoute un champ citation (#403) |
| 17a238f2 | 2023-08-30 15:06:18 | Lino Galiana | Nouvelles données compteurs (#402) |
| 0035b743 | 2023-08-29 14:51:26 | Lino Galiana | Temporary fix for cartography pipeline (#401) |
| a8f90c2f | 2023-08-28 09:26:12 | Lino Galiana | Update featured paths (#396) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| 78ea2cbd | 2023-07-20 20:27:31 | Lino Galiana | Change titles levels (#381) |
| 8df7cb22 | 2023-07-20 17:16:03 | linogaliana | Change link |
| f0c583c0 | 2023-07-07 14:12:22 | Lino Galiana | Images viz (#371) |
| f21a24d3 | 2023-07-02 10:58:15 | Lino Galiana | Pipeline Quarto & Pages 🚀 (#365) |
| 38693f62 | 2023-04-19 17:22:36 | Lino Galiana | Rebuild visualisation part (#357) |
| 32486330 | 2023-02-18 13:11:52 | Lino Galiana | Shortcode rawhtml (#354) |
| b0abd027 | 2022-12-12 07:57:22 | Lino Galiana | Fix cartiflette in additional exercise (#334) |
| e56f6fd5 | 2022-12-03 17:00:55 | Lino Galiana | Corrige typos exo compteurs (#329) |
| f10815b5 | 2022-08-25 16:00:03 | Lino Galiana | Notebooks should now look more beautiful (#260) |
| 494a85ae | 2022-08-05 14:49:56 | Lino Galiana | Images featured ✨ (#252) |
| d201e3cd | 2022-08-03 15:50:34 | Lino Galiana | Pimp la homepage ✨ (#249) |
| 5698e303 | 2022-06-03 18:28:37 | Lino Galiana | Finalise widget (#232) |
| 7b9f27be | 2022-06-03 17:05:15 | Lino Galiana | Essaie régler les problèmes widgets JS (#231) |
| 12965bac | 2022-05-25 15:53:27 | Lino Galiana | :launch: Bascule vers quarto (#226) |
| 9c71d6e7 | 2022-03-08 10:34:26 | Lino Galiana | Plus d’éléments sur S3 (#218) |
| 66a52761 | 2021-11-23 16:13:20 | Lino Galiana | Relecture partie visualisation (#181) |
| 2a8809fb | 2021-10-27 12:05:34 | Lino Galiana | Simplification des hooks pour gagner en flexibilité et clarté (#166) |
| 2f4d3905 | 2021-09-02 15:12:29 | Lino Galiana | Utilise un shortcode github (#131) |
| 2e4d5862 | 2021-09-02 12:03:39 | Lino Galiana | Simplify badges generation (#130) |
| 4cdb759c | 2021-05-12 10:37:23 | Lino Galiana | :sparkles: :star2: Nouveau thème hugo :snake: :fire: (#105) |
| 7f9f97bc | 2021-04-30 21:44:04 | Lino Galiana | 🐳 + 🐍 New workflow (docker 🐳) and new dataset for modelization (2020 🇺🇸 elections) (#99) |
| 29242152 | 2020-10-08 13:35:18 | Lino Galiana | modif slug cartographie |
| 64776878 | 2020-10-08 13:31:00 | Lino Galiana | Visualisation cartographique (#68) |
Ce calcul est possible car les deux bases sont en projection Lambert 93 pour lequel les opérations géométriques (dont les calculs de surface) sont autorisés.↩︎
Stricto sensu, il faudrait vérifier que ces colonnes correspondent bien aux populations légales définies par l’Insee. Cette variable est fournie nativement par l’IGN dans ses fonds de carte. Nous laissons les lecteurs intéressés faire ce travail, qui permet de réviser les compétences Pandas.↩︎
Le Lambert 93 donne une aire en mètres carrés. Pour la transformer en km², il faut faire div(1e6).↩︎
@book{galiana2025,
author = {Galiana, Lino},
title = {Python pour la data science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {fr}
}