!pip install geopandas openpyxl plotnine plotlyPour essayer les exemples présents dans ce tutoriel :

Le précédent chapitre visait à proposer un premier modèle pour comprendre les comtés où le parti Républicain l’emporte. La variable d’intérêt étant bimodale (victoire ou défaite), on était dans le cadre d’un modèle de classification.
Maintenant, sur les mêmes données, on va proposer un modèle de régression pour expliquer le score du parti Républicain. La variable est donc continue. Nous ignorerons le fait que ses bornes se trouvent entre 0 et 100 et donc qu’il faudrait, pour être rigoureux, transformer l’échelle afin d’avoir des données dans cet intervalle.
L’ensemble de la partie machine learning utilise le même jeu de données, présenté dans l’introduction de cette partie : les données de vote aux élections présidentielles américaines croisées à des variables sociodémographiques. Le code est disponible sur Github.
import requests
url = 'https://raw.githubusercontent.com/linogaliana/python-datascientist/main/content/modelisation/get_data.py'
r = requests.get(url, allow_redirects=True)
open('getdata.py', 'wb').write(r.content)
import getdata
votes = getdata.create_votes_dataframes()Ce chapitre va utiliser plusieurs packages
de modélisation, les principaux étant Scikit et Statsmodels.
Voici une suggestion d’import pour tous ces packages.
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import sklearn.metrics
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd1 Principe général
Le principe général de la régression consiste à trouver une loi \(h_\theta(X)\) telle que
\[ h_\theta(X) = \mathbb{E}_\theta(Y|X) \]
Cette formalisation est extrêmement généraliste et ne se restreint d’ailleurs pas à la régression linéaire.
En économétrie, la régression offre une alternative aux méthodes de maximum de vraisemblance et aux méthodes des moments. La régression est un ensemble très vaste de méthodes, selon la famille de modèles (paramétriques, non paramétriques, etc.) et la structure de modèles.
1.1 La régression linéaire
C’est la manière la plus simple de représenter la loi \(h_\theta(X)\) comme combinaison linéaire de variables \(X\) et de paramètres \(\theta\). Dans ce cas,
\[ \mathbb{E}_\theta(Y|X) = X\beta \]
Cette relation est encore, sous cette formulation, théorique. Il convient de l’estimer à partir des données observées \(y\). La méthode des moindres carrés consiste à minimiser l’erreur quadratique entre la prédiction et les données observées (ce qui explique qu’on puisse voir la régression comme un problème de Machine Learning). En toute généralité, la méthode des moindres carrés consiste à trouver l’ensemble de paramètres \(\theta\) tel que
\[ \theta = \arg \min_{\theta \in \Theta} \mathbb{E}\bigg[ \left( y - h_\theta(X) \right)^2 \bigg] \]
Ce qui, dans le cadre de la régression linéaire, s’exprime de la manière suivante :
\[ \beta = \arg\min \mathbb{E}\bigg[ \left( y - X\beta \right)^2 \bigg] \]
Lorsqu’on amène le modèle théorique (\(\mathbb{E}_\theta(Y|X) = X\beta\)) aux données, on formalise le modèle de la manière suivante :
\[ Y = X\beta + \epsilon \]
Avec une certaine distribution du bruit \(\epsilon\) qui dépend des hypothèses faites. Par exemple, avec des \(\epsilon \sim \mathcal{N}(0,\sigma^2)\) i.i.d., l’estimateur \(\beta\) obtenu est équivalent à celui du Maximum de Vraisemblance dont la théorie asymptotique nous assure l’absence de biais, la variance minimale (borne de Cramer-Rao).
1.1.1 Application
Toujours sous le patronage des héritiers de Siegfried (1913), notre objectif, dans ce chapitre, est d’expliquer et prédire le score des Républicains à partir de quelques variables socioéconomiques. Contrairement au chapitre précédent, où on se focalisait sur un résultat binaire (victoire/défaite des Républicains), cette fois on va chercher à modéliser directement le score des Républicains.
Le prochain exercice vise à illustrer la manière d’effectuer une régression linéaire avec scikit.
Dans ce domaine,
statsmodels est nettement plus complet, ce que montrera l’exercice suivant.
L’intérêt principal de faire
des régressions avec scikit est de pouvoir comparer les résultats d’une régression linéaire
avec d’autres modèles de régression dans une perspective de sélection du meilleur modèle prédictif.
AstuceExercice 1a : Régression linéaire avec scikit
- A partir de quelques variables, par exemple, ‘Unemployment_rate_2019’, ‘Median_Household_Income_2021’, ‘Percent of adults with less than a high school diploma, 2018-22’, “Percent of adults with a bachelor’s degree or higher, 2018-22”, expliquer la variable
per_gopà l’aide d’un échantillon d’entraînementX_trainconstitué au préalable.
⚠️ Utiliser la variable Median_Household_Income_2021
en log sinon son échelle risque d’écraser tout effet.
Afficher les valeurs des coefficients, constante comprise
Evaluer la pertinence du modèle avec le \(R^2\) et la qualité du fit avec le MSE.
Représenter un nuage de points des valeurs observées et des erreurs de prédiction. Observez-vous un problème de spécification ?
À la question 4, on peut voir que la répartition des erreurs n’est clairement pas aléatoire en fonction de \(X\).
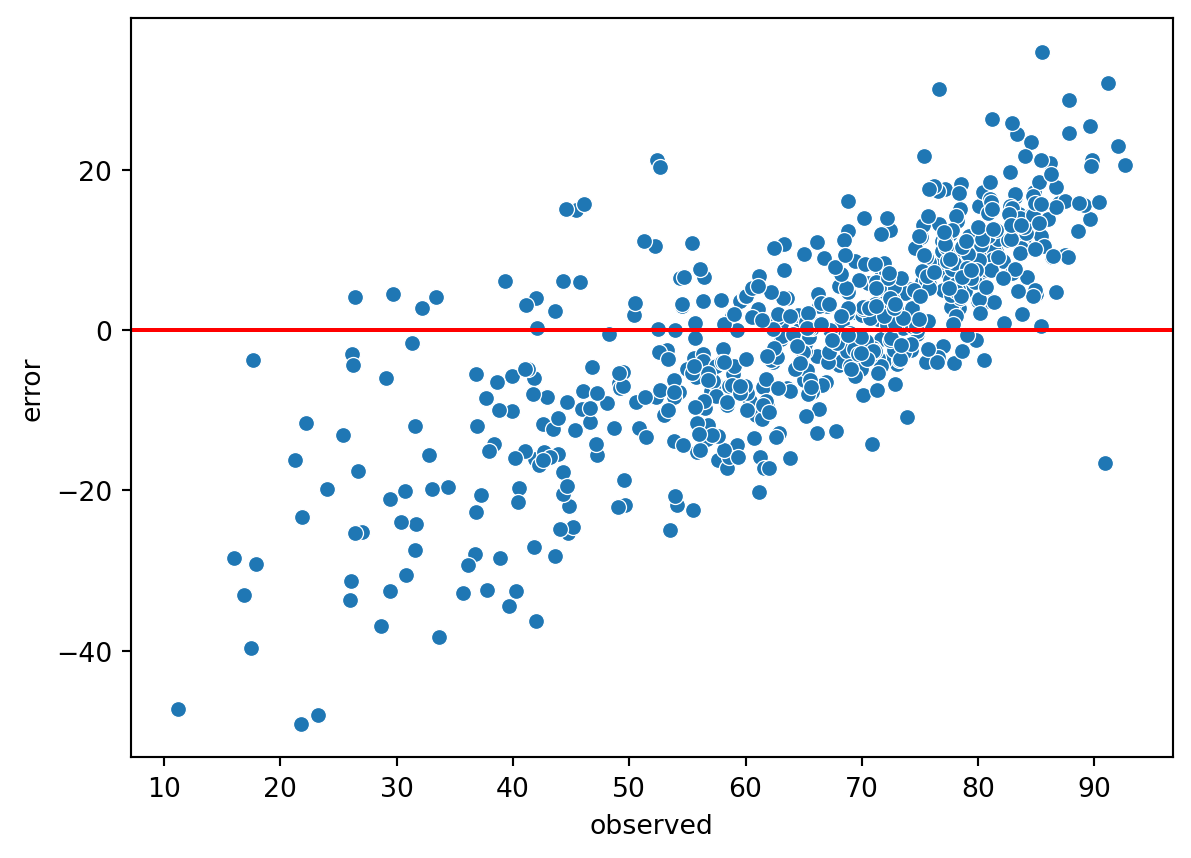
Le modèle souffre donc d’un problème de spécification, il faudra par la suite faire un travail sur les variables sélectionnées. Avant cela, on peut refaire cet exercice avec le package statsmodels.
AstuceExercice 1b : Régression linéaire avec statsmodels
Cet exercice vise à illustrer la manière d’effectuer une régression linéaire avec statsmodels qui offre des fonctionnalités plus proches de celles de R, et moins orientées Machine Learning.
L’objectif est toujours d’expliquer le score des Républicains en fonction de quelques variables.
- A partir de quelques variables, par exemple, ‘Unemployment_rate_2019’, ‘Median_Household_Income_2021’, ‘Percent of adults with less than a high school diploma, 2018-22’, “Percent of adults with a bachelor’s degree or higher, 2018-22”, expliquer la variable
per_gop. ⚠️ utiliser la variableMedian_Household_Income_2021enlogsinon son échelle risque d’écraser tout effet. - Afficher un tableau de régression.
- Evaluer la pertinence du modèle avec le R^2.
- Utiliser l’API
formulapour régresser le score des républicains en fonction de la variableUnemployment_rate_2021, deUnemployment_rate_2019au carré et du log deMedian_Household_Income_2021.
R2: 0.43016652968844415
AstuceTip
Pour sortir une belle table pour un rapport sous \(\LaTeX\), il est possible d’utiliser
la méthode Summary.as_latex. Pour un rapport HTML, on utilisera Summary.as_html
NoteNote
Les utilisateurs de R retrouveront des éléments très familiers avec statsmodels,
notamment la possibilité d’utiliser une formule pour définir une régression.
La philosophie de statsmodels est similaire à celle qui a influé sur la construction
des packages stats et MASS de R: offrir une librairie généraliste, proposant
une large gamme de modèles.
Néanmoins, statsmodels bénéficie de sa jeunesse
par rapport aux packages R. Depuis les années 1990, les packages R visant
à proposer des fonctionalités manquantes dans stats et MASS se sont
multipliés alors que statsmodels, enfant des années 2010, n’a eu qu’à
proposer un cadre général (les generalized estimating equations) pour
englober ces modèles.
1.2 La régression logistique
Nous avons appliqué notre régression linéaire sur une variable d’outcome continue.
Comment faire avec une distribution binaire ?
Dans ce cas, \(\mathbb{E}_{\theta} (Y|X) = \mathbb{P}_{\theta} (Y = 1|X)\).
La régression logistique peut être vue comme un modèle linéaire en probabilité :
\[ \text{logit}\bigg(\mathbb{E}_{\theta}(Y|X)\bigg) = \text{logit}\bigg(\mathbb{P}_{\theta}(Y = 1|X)\bigg) = X\beta \]
La fonction \(\text{logit}\) est \(]0,1[ \to \mathbb{R}: p \mapsto \log(\frac{p}{1-p})\).
Elle permet ainsi de transformer une probabilité dans \(\mathbb{R}\). Sa fonction réciproque est la sigmoïde (\(\frac{1}{1 + e^{-x}}\)), objet central du Deep Learning.
Il convient de noter que les probabilités ne sont pas observées, c’est l’outcome binaire (0/1) qui l’est. Cela amène à voir la régression logistique de deux manières différentes :
- En économétrie, on s’intéresse au modèle latent qui détermine le choix de l’outcome. Par exemple, si on observe les choix de participer ou non au marché du travail, on va modéliser les facteurs déterminant ce choix ;
- En Machine Learning, le modèle latent n’est nécessaire que pour classifier dans la bonne catégorie les observations.
L’estimation des paramètres \(\beta\) peut se faire par maximum de vraisemblance ou par régression, les deux solutions sont équivalentes sous certaines hypothèses.
NoteNote
Par défaut, scikit applique une régularisation pour pénaliser les modèles
peu parcimonieux (comportement différent
de celui de statsmodels). Ce comportement par défaut est à garder à l’esprit
si l’objectif n’est pas de faire de la prédiction.
NoteNote
By default, scikit applies regularization to penalize non-parsimonious models (a behavior different from that of statsmodels). This default behavior should be kept in mind if the objective is not prediction.
AstuceExercice 2a : Régression logistique avec scikit
Avec scikit, en utilisant échantillons d’apprentissage et d’estimation :
- Evaluer l’effet des variables déjà utilisées sur la probabilité des Républicains de gagner. Affichez la valeur des coefficients.
- Déduire une matrice de confusion et une mesure de qualité du modèle.
- Supprimer la régularisation grâce au paramètre
penalty. Quel effet sur les paramètres estimés ?
AstuceExercice 2b : Régression logistique avec statmodels
En utilisant échantillons d’apprentissage et d’estimation :
- Evaluer l’effet des variables déjà utilisées sur la probabilité des Républicains de gagner.
- Faire un test de ratio de vraisemblance concernant l’inclusion de la variable de (log)-revenu.
La p-value du test de maximum de ratio de vraisemblance étant proche de 1, cela signifie que la variable log revenu ajoute, presque à coup sûr, de l’information au modèle.
AstuceTip
La statistique du test est : \[ LR = -2\log\bigg(\frac{\mathcal{L}_{\theta}}{\mathcal{L}_{\theta_0}}\bigg) = -2(\mathcal{l}_{\theta} - \mathcal{l}_{\theta_0}) \]
2 Pour aller plus loin
Ce chapitre n’évoque les enjeux de la régression que de manière très introductive. Pour compléter ceci, il est recommandé d’aller plus loin en fonction de vos centres d’intérêt et de vos besoins.
Dans le domaine du machine learning, les principales voies d’approfondissement sont les suivantes:
- Les modèles de régression alternatifs comme les forêts aléatoires.
- Les méthodes de boosting et bagging pour découvrir la manière dont plusieurs modèles peuvent être entraînés de manière conjointe et leur prédiction sélectionnée selon un principe démocratique pour converger vers une meilleure décision qu’un modèle simple.
- Les enjeux liés à l’explicabilité des modèles, un champ de recherche très actif, pour mieux comprendre les critères de décision des modèles.
Dans le domaine de l’économétrie, les principales voies d’approfondissement sont les suivantes:
- Les modèles linéaires généralisés pour découvrir la régression avec des hypothèses plus générales que celles que nous avons posées jusqu’à présent ;
- Les tests d’hypothèses pour aller plus loin sur ces questions que notre test de ratio de vraisemblance.
Références
Informations additionnelles
NoteEnvironnement Python
Ce site a été construit automatiquement par le biais d’une action Github utilisant le logiciel de publication reproductible Quarto
L’environnement utilisé pour obtenir les résultats est reproductible par le biais d’uv. Le fichier pyproject.toml utilisé pour construire cet environnement est disponible sur le dépôt linogaliana/python-datascientist
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
Pour utiliser exactement le même environnement (version de Python et packages), se reporter à la documentation d’uv.
NoteHistorique du fichier
| SHA | Date | Author | Description |
|---|---|---|---|
| d56f6e9e | 2025-11-25 08:30:59 | lgaliana | Un petit coup de neuf sur les consignes et corrections pandas related |
| 94648290 | 2025-07-22 18:57:48 | Lino Galiana | Fix boxes now that it is better supported by jupyter (#628) |
| 91431fa2 | 2025-06-09 17:08:00 | Lino Galiana | Improve homepage hero banner (#612) |
| 48dccf14 | 2025-01-14 21:45:34 | lgaliana | Fix bug in modeling section |
| d4f89590 | 2024-12-20 14:36:20 | lgaliana | format fstring R2 |
| 8c8ca4c0 | 2024-12-20 10:45:00 | lgaliana | Traduction du chapitre clustering |
| a5ecaedc | 2024-12-20 09:36:42 | Lino Galiana | Traduction du chapitre modélisation (#582) |
| ff0820bc | 2024-11-27 15:10:39 | lgaliana | Mise en forme chapitre régression |
| 06d003a1 | 2024-04-23 10:09:22 | Lino Galiana | Continue la restructuration des sous-parties (#492) |
| 8c316d0a | 2024-04-05 19:00:59 | Lino Galiana | Fix cartiflette deprecated snippets (#487) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 7d12af8b | 2023-12-05 10:30:08 | linogaliana | Modularise la partie import pour l’avoir partout |
| 417fb669 | 2023-12-04 18:49:21 | Lino Galiana | Corrections partie ML (#468) |
| a06a2689 | 2023-11-23 18:23:28 | Antoine Palazzolo | 2ème relectures chapitres ML (#457) |
| 889a71ba | 2023-11-10 11:40:51 | Antoine Palazzolo | Modification TP 3 (#443) |
| 154f09e4 | 2023-09-26 14:59:11 | Antoine Palazzolo | Des typos corrigées par Antoine (#411) |
| 9a4e2267 | 2023-08-28 17:11:52 | Lino Galiana | Action to check URL still exist (#399) |
| a8f90c2f | 2023-08-28 09:26:12 | Lino Galiana | Update featured paths (#396) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| 78ea2cbd | 2023-07-20 20:27:31 | Lino Galiana | Change titles levels (#381) |
| 29ff3f58 | 2023-07-07 14:17:53 | linogaliana | description everywhere |
| f21a24d3 | 2023-07-02 10:58:15 | Lino Galiana | Pipeline Quarto & Pages 🚀 (#365) |
| 58c71287 | 2023-06-11 21:32:03 | Lino Galiana | change na subset (#362) |
| 2ed4aa78 | 2022-11-07 15:57:31 | Lino Galiana | Reprise 2e partie ML + Règle problème mathjax (#319) |
| f10815b5 | 2022-08-25 16:00:03 | Lino Galiana | Notebooks should now look more beautiful (#260) |
| 494a85ae | 2022-08-05 14:49:56 | Lino Galiana | Images featured ✨ (#252) |
| d201e3cd | 2022-08-03 15:50:34 | Lino Galiana | Pimp la homepage ✨ (#249) |
| 12965bac | 2022-05-25 15:53:27 | Lino Galiana | :launch: Bascule vers quarto (#226) |
| 9c71d6e7 | 2022-03-08 10:34:26 | Lino Galiana | Plus d’éléments sur S3 (#218) |
| c3bf4d42 | 2021-12-06 19:43:26 | Lino Galiana | Finalise debug partie ML (#190) |
| fb14d406 | 2021-12-06 17:00:52 | Lino Galiana | Modifie l’import du script (#187) |
| 37ecfa3c | 2021-12-06 14:48:05 | Lino Galiana | Essaye nom différent (#186) |
| 5d0a5e38 | 2021-12-04 07:41:43 | Lino Galiana | MAJ URL script recup data (#184) |
| 5c104904 | 2021-12-03 17:44:08 | Lino Galiana | Relec (antuki?) partie modelisation (#183) |
| 2a8809fb | 2021-10-27 12:05:34 | Lino Galiana | Simplification des hooks pour gagner en flexibilité et clarté (#166) |
| 2e4d5862 | 2021-09-02 12:03:39 | Lino Galiana | Simplify badges generation (#130) |
| 4cdb759c | 2021-05-12 10:37:23 | Lino Galiana | :sparkles: :star2: Nouveau thème hugo :snake: :fire: (#105) |
| 7f9f97bc | 2021-04-30 21:44:04 | Lino Galiana | 🐳 + 🐍 New workflow (docker 🐳) and new dataset for modelization (2020 🇺🇸 elections) (#99) |
| 59eadf58 | 2020-11-12 16:41:46 | Lino Galiana | Correction des typos partie ML (#81) |
| 347f50f3 | 2020-11-12 15:08:18 | Lino Galiana | Suite de la partie machine learning (#78) |
| 671f75a4 | 2020-10-21 15:15:24 | Lino Galiana | Introduction au Machine Learning (#72) |
Les références
Siegfried, André. 1913. Tableau politique de la France de l’ouest sous la troisième république: 102 cartes et croquis, 1 carte hors texte. A. Colin.
Citation
BibTeX
@book{galiana2025,
author = {Galiana, Lino},
title = {Python pour la data science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {fr}
}
Veuillez citer ce travail comme suit :
Galiana, Lino. 2025. Python pour la data science. https://doi.org/10.5281/zenodo.8229676.