1 Résumé
- A la fin du semestre, les étudiants rendront un projet informatique par groupe de 2-3 personnes.
- Ce projet dont le sujet est libre devra comporter:
- Une valorisation d’un ou plusieurs jeux de données open data ou collectés par le biais de scraping ou d’API ;
- De la visualisation ;
- De la modélisation.
- Les étudiants sont invités à proposer des sujets qui leur plaisent, à faire valider par le chargé de TD. Celui-ci pourra le refuser, soit parce que le sujet a été trop balisé et ainsi produire une valorisation originale ou intéressante est compliqué, soit parce que le sujet est techniquement complexe à réaliser.
- Les projets issus de compétitions type Kaggle sont interdits.
- Le projet doit utiliser
Gitet être disponible sousGithub(dépôt public) ; - Le projet doit être reproductible sous peine de sanction forte. Cela implique des morceaux de code reproductibles, une description des dépendances et des explications si nécessaire sur la récupération des données ;
- L’utilisation d’assistant de code est possible. Le vibe coding n’est pas autorisé.
Les principales deadline sont les suivantes:
| Etape | Date rendue |
|---|---|
| Date du rendu | XX décembre 2025 23h59 |
| Date des soutenances | XX janvier 2025 |
2 Attentes du projet
Le projet consiste à répondre à une problématique de votre choix à l’aide d’un ou plusieurs jeux de données.
Il vous faudra d’abord définir clairement la question à traiter, en apportant une problématisation et une contextualisation. Nous vous encourageons à choisir un sujet qui vous intéresse personnellement : cela vous aidera à maintenir votre motivation et à impliquer davantage votre lecteur.
Le projet doit articuler trois dimensions complémentaires :
- La récupération de données issue de plusieurs sources et l’exploration de celles-ci
- La visualisation et la communication des résultats
- L’analyse ou la modélisation
Il n’est pas nécessaire de développer toutes les dimensions de manière exhaustive. En revanche, il est attendu que l’une d’entre elles au moins soit approfondie.
Enfin, gardez en tête que l’objectif n’est pas de tout montrer. Un effort de synthèse est attendu, tant à l’écrit qu’à l’oral. Il vous faudra sélectionner les résultats les plus pertinents, les présenter de manière claire et structurée.
2.1 La récupération et le traitement des données
Les données utilisées dans votre projet peuvent provenir de différentes sources : fichiers plats (CSV, parquet), API, scraping, etc. Plus l’effort de collecte est important ou technique (par exemple, croisement de plusieurs sources, automatisation via API, scraping multi-pages…), plus cette partie pourra contribuer à votre évaluation.
À l’inverse, si vous utilisez un jeu de données directement prêt à l’emploi, il vous faudra le compléter ou l’enrichir (recherche de variables supplémentaires, données complémentaires, structuration…) pour que cette étape soit valorisée.
Dans la grande majorité des cas, les données brutes ne seront pas exploitables telles quelles. Vous devrez mettre en place un nettoyage rigoureux : gestion des valeurs manquantes, normalisation des formats, renommage de variables, transformation de types, etc. Cette étape est aussi l’occasion de créer des variables plus lisibles ou informatives.
N’oubliez pas de documenter vos choix : votre chargé de TD ne connaît pas nécessairement la structure de vos données ou les biais potentiels.
ImportantQuelques sources de données sont interdites
Je donne ce cours depuis fin 2020, je bénéficie donc de suffisamment de recul pour pouvoir indiquer qu’il n’est pas souhaitable, sauf si l’objectif est un fiasco, de se lancer dans certains sujets ou de s’appuyer sur certaines sources compte tenu de leur nature et du délai contraint que vous avez pour réaliser vos projets.
Voici les sources qu’il est interdit d’utiliser :
- Les données issues de compétitions Kaggle sont interdites. D’abord parce que ce sont des données sur lesquelles les possibilités de recherche sont généralement limitées: globalement à part tester des algorithmes concurrents sur ce jeu afin d’avoir la meilleure performance possible - ce qui n’est pas le but du projet - on n’a pas grand chose de mieux à faire. Savoir que pour tel ou tel jeu de données tel algorithme est plus performant - sans garantie de validité externe des conclusions - est peu intéressant et vous apprendra peu.
- Les données issues de l’API Twitter/X sont interdites. Ces données étaient déjà peu intéressantes quand Twitter était très utilisé. Les évolutions de ces dernières années de ce réseau social - polarisation des messages et de sa base d’utilisateur, présence accrue de bots - rendent ce corpus encore plus bruyant. De plus, si pendant des années les vannes étaient ouvertes et de nombreuses ressources en ligne ont proposé d’utiliser ces données, ce n’est plus le cas. Vous n’aurez pas de clé de chercheurs pour l’accès à l’API donc vous aurez du mal à récupérer beaucoup de données.
ImportantFaire un code reproductible quand on fait du webscraping ou utilise des API est une gageure
Comme cela est expliqué dans le chapitre consacré au webscraping, récupérer des données par ce biais est un moyen détourné peu fiable dans la durée car les sites évoluent continuellement ou mettent en oeuvre des solutions pour bloquer les robots aspirant leurs données. Vous n’êtes pas assuré que votre code qui fonctionne aujourd’hui pourra à nouveau tourner demain sans encombre. C’est un problème qui peut également être rencontré avec les API quoique ces dernières sont un moyen plus robuste d’accès aux données. Mais on n’est jamais à l’abri d’une mise à jour de celle-ci.
Une composante essentielle de l’évaluation des projets Python est la reproductibilité, i.e. la possibilité de retrouver les mêmes résultats à partir des mêmes données d’entrée et du même code. Dans la mesure du possible, il faut donc que votre rendu final parte des données brutes utilisées comme source dans votre projet. Si les fichiers de données source sont accessibles via une URL publique par exemple, il est idéal de les importer directement à partir de cette URL au début de votre projet (voir le TP Pandas pour un exemple d’un tel import via Pandas).
Face à l’incertitude de ne pas retrouver demain les mêmes données qu’aujourd’hui, il est nécessaire de pouvoir stocker des données (ou des modèles). Votre dépôt Git n’est pas le lieu adapté pour le stockage de fichiers volumineux. Un projet Python bien construit est modulaire: il sépare le stockage du code (Git), d’éléments de configuration (par exemple des jetons d’API qui ne doivent pas être dans le code) et du stockage des données. Cette séparation conceptuelle entre code et données permet de meilleurs projets.
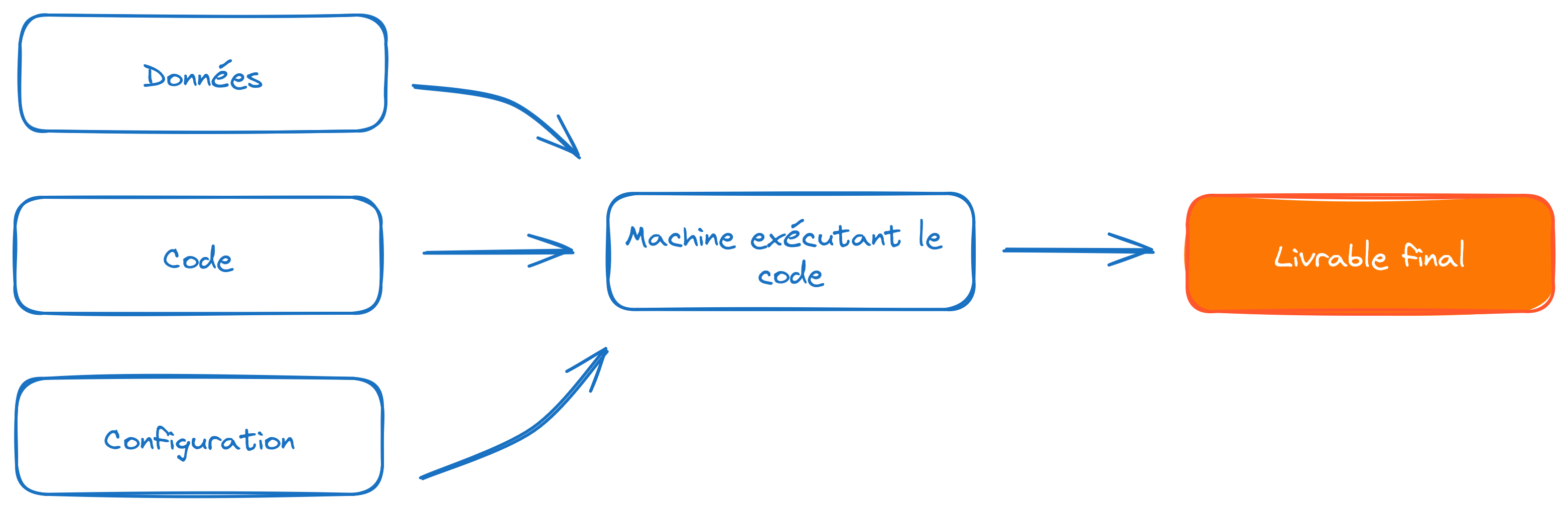
Là où Git est fait pour stocker du code, on utilise des solutions adaptées pour le stockage de fichiers. De nombreuses solutions existent pour ce faire. Sur le SSP Cloud, on propose MinIO, une implémentation open-source du stockage S3. Si vous êtes dans cette situation, vous pouvez consulter ce guide pour partager vos données sur le sspcloud.
2.2 L’analyse descriptive et la représentation graphique
La présence de statistiques descriptives est indispensable dans le projet. De la description de la base aux premières grandes tendances des données, cette partie permet d’avoir une vision globale des données : le lien avec la problématique, comment elle permet d’y répondre, quels sont les premiers éléments de réponse… Chaque résultat doit être interprété : pas la peine de faire un describe et de ne pas le commenter.
En termes de représentation graphique, plusieurs niveaux sont envisageables, selon le degré d’approfondissement de cette partie. La base d’une bonne visualisation est de trouver le type de graphique adéquat pour ce que vous voulez montrer et de le rendre visible : une légende qui a du sens, des axes avec des noms etc.
Encore une fois, il faudra commenter votre graphique: qu’est ce qu’il montre, en quoi cela valide / contredit votre argumentaire ?
Note 2.1: Les applications réactives
Dans le cadre de ce cours, nous présentons plusieurs librairies graphiques permettant de créer des visualisations de données interactives, notamment Plotly ou Leaflet. Pour aller plus loin, vous pouvez désirer créer des applications encapsulant plusieurs graphiques construits automatiquement
en fonction de choix de l’utilisateur sur une interface graphique.
Tout d’abord, ce n’est pas un prérequis pour ce cours. Le cours de 3e année “Mise en production de projets de data science”
que Romain Avouac et moi donnons à l’ENSAE vous permettra de mettre en oeuvre ceci, qui fait appel à des concepts plus avancés qu’une introduction à Python pour la science des données.
C’est néanmoins un plus qui est apprécié et si vous désirez aller dans cette voie, il est recommandé de bien choisir son écosystème. Il vaut mieux mettre en oeuvre des frameworks web modernes comme
Streamlit que des clients lourds comme tkinter qui rendent le code difficilement reproductible
car adhérant à une configuration logicielle. Pour en savoir plus, se reporter
à l’introduction de la partie visualisation.
Si vous faites une application réactive, vous n’êtes pas obligé de rédiger un notebook.
Cependant, faites en sorte que votre application propose une page présentant votre démarche
afin de faire comprendre à votre lecteur la problématique et les solutions mises en oeuvre.
Cette application doit être reproductible sur le SSPCloud par le biais, par exemple,
d’un streamlit run. Il est donc vivement recommandé de développer celle-ci sur le SSPCloud
où la reproductibilité est maximale.
2.3 La modélisation
Vient ensuite la phase de modélisation : un modèle peut être le bienvenu quand des statistiques descriptives ne suffisent pas à apporter une solution complète à votre problématique ou pour compléter / renforcer l’analyse descriptive. Le modèle importe peu (régression linéaire, random forest ou autre) : il doit être approprié (répondre à votre problématique) et justifié. Vous pouvez aussi confronter plusieurs modèles qui n’ont pas la même vocation : par exemple une CAH pour catégoriser et créer des nouvelles variables / faire des groupes puis une régression. Même si le projet n’est pas celui du cours de stats, il faut que la démarche soit scientifique et que les résultats soient interprétés.
3 Format du rendu
Sur le format du rendu, vous devrez :
- Écrire un rapport sous forme de notebook (quelques exceptions à cette règle peuvent exister, par exemple si vous développer une appli
Streamlitcomme expliqué dans la Note 2.1) ou deQuarto Markdown. Soyez vigilant avec le contrôle de version (Important 3.1) - Avoir un projet
Githubavec le rapport. Les données utilisées doivent être accessibles également, dans le dépôt, sur internet ou sur l’espace de stockage duSSPCloud(voir tutoriel S3). - Les dépôts
Githuboù seul un upload du projet a été réalisé seront pénalisés. A l’inverse, les dépôts dans lequels le contrôle de version et le travail collaboratif ont été activement pratiqués (commitsfréquents,pull requests, ..) seront valorisés. - Le code contenu dans le rapport devra être un maximum propre (pas de copier coller de cellule, préférez des fonctions)
Important 3.1: Git et les notebooks
Faites attention au contrôle de version avec les notebooks, cela ne fait pas toujours bon ménage.
Comme expliqué dans le chapitre sur Git, lorsque vous travaillez sur le même fichier en même temps vous pouvez vous retrouver avec un conflit de version lorsque vous résolvez les différences dans vos dépôts.
Dans les notebooks cela peut se traduire par de multiples conflits de version car deux notebooks en apparence similaires peuvent contenir beaucoup d’éléments différents dans les fichiers bruts (un JSON assez complexe, embarquant notamment des id d’exécution de cellules changeant systématiquement). Un merge mal géré peut rendre un notebook invalide.
Il est recommandé de ne pas travailler sur un même notebook sur une même branche en même temps. Cela fait donc beaucoup de conditions pour arriver à un conflit de version mais dans le rush inhérent à tout projet cela peut vite arriver. Outre la coordination, nous pouvons vous conseiller de déporter une partie du code dans des fichiers .py importés sous forme de module par le notebook. De toute manière, c’est une bonne pratique de ne pas accumuler de trop longues instructions de code dans un notebook car cela freine la lisibilité et l’intelligibilité de celui-ci.
ImportantPolitique concernant l’IA générative
L’utilisation d’IA génératives assistantes de code est devenue commune dans le domaine de la data science. Elles peuvent servir à transcire une idée en code, à défricher les packages ou fonctions les plus appropriées pour une tâche donnée ou encore à documenter du code.
Utilisées avec discernement, ces IA peuvent améliorer la qualité de votre travail. Leur usage est donc autorisé dans ce projet, et apprendre à les utiliser efficacement fait partie des compétences que vous devrez développer dans le cadre de votre scolarité.
Cependant, cet outil ne doit pas être détourné en pensant qu’il fera tout à votre place. Il y a deux raisons à cela :
- Sans instructions claires (prompts de qualité), le code généré sera souvent médiocre… et votre note aussi.
- Si vous vous contentez de copier sans comprendre, vous n’apprendrez rien ce qui vous pénalisera à long terme dans la suite de votre formation.
Coder c’est aussi réfléchir à son problème, faire un aller/retour avec un jeu de données, affiner sa problématique et ses conclusions en mesurant les limites des données. Ce n’est pas juste coder une application en faisant du vibe coding (pratique que d’ailleurs j’interdis parce que là vous n’apprendrez vraiment rien).
Tout usage abusif des IA génératives, c’est-à-dire sans effort apparent de reprise de celui-ci, sera sanctionné.
4 Barème approximatif
| Catégorie | Points |
|---|---|
| Données (collecte et nettoyage) | 4 |
| Analyse descriptive | 4 |
| Modélisation | 2 |
| Démarche scientifique et reproductibilité du projet | 4 |
| Format du code (code propre et github) | 2 |
| Soutenance | 4 |
Lors de l’évaluation, une attention particulière sera donnée à la reproductibilité de votre projet. Chaque étape (récupération et traitement des données, analyses descriptives, modélisation) doit pouvoir être reproduite à partir du notebook final.
Le test à réaliser : faire tourner toutes les cellules de votre notebook et ne pas avoir d’erreur est une condition sine qua non pour avoir la moyenne.
5 Projets passés faits par les étudiants 😍
Aucun article correspondant
Informations additionnelles
NoteEnvironnement Python
Ce site a été construit automatiquement par le biais d’une action Github utilisant le logiciel de publication reproductible Quarto
L’environnement utilisé pour obtenir les résultats est reproductible par le biais d’uv. Le fichier pyproject.toml utilisé pour construire cet environnement est disponible sur le dépôt linogaliana/python-datascientist
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
Pour utiliser exactement le même environnement (version de Python et packages), se reporter à la documentation d’uv.
NoteHistorique du fichier
| SHA | Date | Author | Description |
|---|---|---|---|
| 56ad5bc8 | 2026-07-14 21:57:39 | Lino Galiana | Données filosofi plus à jour pour le chapitre Pandas (#699) |
| 4c90fe40 | 2025-12-09 09:33:49 | lgaliana | change link S3 tutorial |
| b3a43b8b | 2025-08-25 14:45:28 | lgaliana | retire instuctions .md |
| 3d593afb | 2025-08-25 15:38:21 | Lino Galiana | Politique autour de la genAI (#648) |
| edf92f1b | 2025-08-20 12:41:26 | Lino Galiana | Improve notebook construction pipeline & landing page (#637) |
| 99ab48b0 | 2025-07-25 18:50:15 | Lino Galiana | Utilisation des callout classiques pour les box notes and co (#629) |
| ab0eb6e9 | 2024-12-27 17:29:43 | lgaliana | relative path image |
| 88890345 | 2024-12-27 14:38:09 | lgaliana | Sur la récupération de données |
| 618c24a7 | 2024-12-26 15:46:05 | lgaliana | Plus de projets d’alumni |
| c1853b92 | 2024-11-20 15:09:19 | Lino Galiana | Reprise eval + reprise S3 (#576) |
| 4ddbdc80 | 2024-10-30 10:31:07 | lbaudin | Update evaluation.qmd (#572) |
| e0fa908a | 2024-10-12 13:50:16 | lgaliana | Mise en forme exogit |
| c326488c | 2024-10-10 14:31:57 | Romain Avouac | Various fixes (#565) |
| d02515b4 | 2024-04-27 21:32:25 | Lino Galiana | Eléments sur les applis & évaluation (#495) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 1f23de28 | 2023-12-01 17:25:36 | Lino Galiana | Stockage des images sur S3 (#466) |
| c8123220 | 2023-11-29 10:13:21 | lbaudin | Dates d’évaluation (#462) |
| 889a71ba | 2023-11-10 11:40:51 | Antoine Palazzolo | Modification TP 3 (#443) |
| 3276558f | 2023-10-17 11:09:45 | Romain Avouac | more example projects (#436) |
| 154f09e4 | 2023-09-26 14:59:11 | Antoine Palazzolo | Des typos corrigées par Antoine (#411) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| 30823c40 | 2023-08-24 14:30:55 | Lino Galiana | Liens morts navbar (#392) |
| 202e7dc0 | 2023-08-11 15:52:52 | linogaliana | Order execution |
| 5d4874a8 | 2023-08-11 15:09:33 | Lino Galiana | Pimp les introductions des trois premières parties (#387) |
| 25adfdce | 2022-09-22 16:20:12 | Lino Galiana | Slides version 2022 (#275) |
| b2d48237 | 2022-09-21 17:36:29 | Lino Galiana | Relec KA 21/09 (#273) |
| 2360ff7b | 2022-08-02 16:29:57 | Lino Galiana | Test wowchemy update (#247) |
| 3e919f9f | 2022-03-28 10:00:49 | jblaval | Ajoute projet élève (#224) |
| dece5e48 | 2022-03-21 10:10:39 | Mélissa Tamine | Ajoute projet élèves (#222) |
| 06016669 | 2022-03-21 10:05:12 | Idrissa KONKOBO | Ajoute projet élève (#221) |
| 9c71d6e7 | 2022-03-08 10:34:26 | Lino Galiana | Plus d’éléments sur S3 (#218) |
| 6cc6d81f | 2021-12-31 09:40:17 | Lino Galiana | Lien pour avoir des notebooks propres |
| 81ce124d | 2021-09-20 15:36:05 | Romain Avouac | Quelques éléments sur la reproductibilité (#148) |
| bf5ebc5f | 2021-09-01 14:41:17 | Lino Galiana | Fix problem import pynsee (#128) |
| 4cdb759c | 2021-05-12 10:37:23 | Lino Galiana | :sparkles: :star2: Nouveau thème hugo :snake: :fire: (#105) |
| 8781c833 | 2021-03-05 15:32:43 | romanegajdos | Projet GPS vélo (#96) |
| acfb0100 | 2021-03-03 18:50:32 | Lino Galiana | Intégration d’un endroit où lister les projets des élèves (#95) |
| 72092d73 | 2020-11-10 17:43:52 | Lino Galiana | Ajout dates rendu |
| b47e1ae4 | 2020-11-09 14:58:18 | Lino Galiana | Section sur l’intégration continue (#77) |
| e644cc70 | 2020-10-21 15:48:12 | Lino Galiana | Actualise la partie évaluation (#73) |
| 4677769b | 2020-09-15 18:19:24 | Lino Galiana | Nettoyage des coquilles pour premiers TP (#37) |
| 913047d3 | 2020-09-08 14:44:41 | Lino Galiana | Harmonisation des niveaux de titre (#17) |
Citation
BibTeX
@book{galiana2025,
author = {Galiana, Lino},
title = {Python pour la data science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {fr}
}
Veuillez citer ce travail comme suit :
Galiana, Lino. 2025. Python pour la data science. https://doi.org/10.5281/zenodo.8229676.