!pip install numpy pandas spacy transformers scikit-learn langchain_community
AvertissementWarning
Ce chapitre va évoluer prochainement.
Pour essayer les exemples présents dans ce tutoriel :

1 Introduction
Cette page approfondit certains aspects présentés dans la partie introductive. Nous allons avancer dans notre compréhension des enjeux du NLP grâce à la modélisation du langage.
Nous partirons de la conclusion, évoquée à la fin du précédent chapitre, que les approches fréquentistes présentent plusieurs inconvénients : représentation du langage sur des régularités statistiques indépendantes des proximités entre des mots ou phrases, difficulté à prendre en compte le contexte.
L’objectif de ce chapitre est d’évoquer le premier point. Il s’agira d’une introduction au sujet des embeddings, ces représentations du langage qui sont au fondement des modèles de langage actuels utilisés par des outils entrés dans notre quotidien (DeepL, ChatGPT…).
1.1 Données utilisées
Nous allons continuer notre exploration de la littérature avec, à nouveau, les trois auteurs anglophones :
- Edgar Allan Poe, (EAP) ;
- HP Lovecraft (HPL) ;
- Mary Wollstonecraft Shelley (MWS).
Les données sont disponibles sur un CSV mis à disposition sur Github. L’URL pour les récupérer directement est
https://github.com/GU4243-ADS/spring2018-project1-ginnyqg/raw/master/data/spooky.csv.
Pour rentrer dans le sujet des embeddings, nous allons faire de la modélisation du langage en essayant de prédire les auteurs ayant écrit tel ou tel texte. On parle de modèle de langage pour désigner la représentation d’un texte ou d’une langue sous la forme d’une distribution de probabilités de termes (généralement les mots).
NoteSources d’inspiration
Ce chapitre s’inspire de plusieurs ressources disponibles en ligne:
- Un premier notebook sur
Kaggleet un deuxième ; - Un dépôt
Github;
1.2 Packages à installer
Comme dans la partie précédente, il faut télécharger des librairies
spécialiséees pour le NLP, ainsi que certaines de leurs dépendances. Ce TD utilisera plusieurs librairies dont certaines dépendent de PyTorch qui est une librairie volumineuse.
ImportantPyTorch sur le SSPCloud
La prochaine remarque ne concerne que les utilisateurs.trices du SSPCloud.
Les services Python standards sur le SSPCloud (les services vscode-python et jupyter-python) ne proposent pas PyTorch préinstallé. Cette librairie est en effet assez volumineuse (de l’ordre de 600Mo) et nécessite un certain nombre de configurations ad hoc pour fonctionner de manière transparente quelle que soit la configuration logicielle derrière. Pour des raisons de frugalité écologique, cet environnement boosté n’est pas proposé par défaut. Néanmoins, si besoin, un tel environnement où Pytorch est pré à l’emploi est disponible.
Pour cela, il suffit de démarrer un service vscode-pytorch ou jupyter-pytorch. Si vous avez utilisé l’un des boutons disponibles ci-dessus, c’est ce service standardisé qui a automatiquement été mis à disposition pour vous.
Ensuite, comme nous allons utiliser la librairie SpaCy avec un corpus de textes
en Anglais, il convient de télécharger le modèle NLP pour l’Anglais. Pour cela,
on peut se référer à la documentation de SpaCy,
extrêmement bien faite.
!python -m spacy download en_core_web_sm2 Préparation des données
Nous allons à nouveau utiliser le jeu de données spooky :
import pandas as pd
data_url = 'https://github.com/GU4243-ADS/spring2018-project1-ginnyqg/raw/master/data/spooky.csv'
spooky_df = pd.read_csv(data_url)Le jeu de données met ainsi en regard un auteur avec une phrase qu’il a écrite :
spooky_df.head()| id | text | author | |
|---|---|---|---|
| 0 | id26305 | This process, however, afforded me no means of... | EAP |
| 1 | id17569 | It never once occurred to me that the fumbling... | HPL |
| 2 | id11008 | In his left hand was a gold snuff box, from wh... | EAP |
| 3 | id27763 | How lovely is spring As we looked from Windsor... | MWS |
| 4 | id12958 | Finding nothing else, not even gold, the Super... | HPL |
2.1 Preprocessing
Comme nous l’avons évoqué dans le chapitre précédent, la première étape de tout travail sur données textuelles est souvent celle du preprocessing, qui inclut notamment les étapes de tokenization et de nettoyage du texte.
On se contentera ici d’un preprocessing minimaliste : suppression de la ponctuation et des stop words (pour la visualisation et les méthodes de vectorisation basées sur des comptages).
Pour initialiser le processus de nettoyage,
on va utiliser le corpus en_core_web_sm de Spacy
import spacy
nlp = spacy.load('en_core_web_sm')On va utiliser un pipe spacy qui permet d’automatiser, et de paralléliser,
un certain nombre d’opérations. Les pipes sont l’équivalent, en NLP, de
nos pipelines scikit ou des pipes pandas. Il s’agit donc d’un outil
très approprié pour industrialiser un certain nombre d’opérations de
preprocessing :
Preprocessing de la base textuelle
from typing import List
import spacy
def clean_docs(
texts: List[str],
remove_stopwords: bool = False,
n_process: int = 4,
remove_punctuation: bool = True
) -> List[str]:
"""
Cleans a list of text documents by tokenizing, optionally removing stopwords, and optionally removing punctuation.
Parameters:
texts (List[str]): List of text documents to clean.
remove_stopwords (bool): Whether to remove stopwords. Default is False.
n_process (int): Number of processes to use for processing. Default is 4.
remove_punctuation (bool): Whether to remove punctuation. Default is True.
Returns:
List[str]: List of cleaned text documents.
"""
# Load spacy's nlp model
docs = nlp.pipe(
texts,
n_process=n_process,
disable=['parser', 'ner', 'lemmatizer', 'textcat']
)
# Pre-load stopwords for faster checking
stopwords = set(nlp.Defaults.stop_words)
# Process documents
docs_cleaned = (
' '.join(
tok.text.lower().strip()
for tok in doc
if (not remove_punctuation or not tok.is_punct) and
(not remove_stopwords or tok.text.lower() not in stopwords)
)
for doc in docs
)
return list(docs_cleaned)On applique la fonction clean_docs à notre colonne pandas.
Les pandas.Series étant itérables, elles se comportent comme des listes et
fonctionnent ainsi très bien avec notre pipe spacy.
spooky_df['text_clean'] = clean_docs(spooky_df['text'])spooky_df.head()| id | text | author | text_clean | |
|---|---|---|---|---|
| 0 | id26305 | This process, however, afforded me no means of... | EAP | this process however afforded me no means of a... |
| 1 | id17569 | It never once occurred to me that the fumbling... | HPL | it never once occurred to me that the fumbling... |
| 2 | id11008 | In his left hand was a gold snuff box, from wh... | EAP | in his left hand was a gold snuff box from whi... |
| 3 | id27763 | How lovely is spring As we looked from Windsor... | MWS | how lovely is spring as we looked from windsor... |
| 4 | id12958 | Finding nothing else, not even gold, the Super... | HPL | finding nothing else not even gold the superin... |
2.2 Encodage de la variable à prédire
On réalise un simple encodage de la variable à prédire :
il y a trois catégories (auteurs), représentées par des entiers 0, 1 et 2.
Pour cela, on utilise le LabelEncoder de Scikit déjà présenté
dans la partie modélisation. On va utiliser la méthode
fit_transform qui permet, en un tour de main, d’appliquer à la fois
l’entraînement (fit), à savoir la création d’une correspondance entre valeurs
numériques et labels, et l’appliquer (transform) à la même colonne.
On peut vérifier les classes de notre LabelEncoder :
array(['EAP', 'HPL', 'MWS'], dtype=object)2.3 Construction des bases d’entraînement et de test
On met de côté un échantillon de test (20 %) avant toute analyse (même descriptive). Cela permettra d’évaluer nos différents modèles toute à la fin de manière très rigoureuse, puisque ces données n’auront jamais utilisées pendant l’entraînement.
Notre échantillon initial n’est pas équilibré (balanced) : on retrouve plus d’oeuvres de certains auteurs que d’autres. Afin d’obtenir un modèle qui soit évalué au mieux, nous allons donc stratifier notre échantillon de manière à obtenir une répartition similaire d’auteurs dans nos ensembles d’entraînement et de test.
from sklearn.model_selection import train_test_split
y = spooky_df["author"]
X = spooky_df['text_clean']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)Aperçu du premier élément de X_train :
'this process however afforded me no means of ascertaining the dimensions of my dungeon as i might make its circuit and return to the point whence i set out without being aware of the fact so perfectly uniform seemed the wall'3 Vectorisation par l’approche bag of words
La représentation de nos textes sous forme de sac de mot permet de vectoriser notre corpus et ainsi d’avoir une représentation numérique de chaque texte. On peut à partir de là effectuer plusieurs types de tâches de modélisation.
Définissons notre représentation vectorielle par TF-IDF grâce à Scikit:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline
pipeline_tfidf = Pipeline([
('tfidf', TfidfVectorizer(max_features=10000)),
])
pipeline_tfidfPipeline(steps=[('tfidf', TfidfVectorizer(max_features=10000))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Entraînons d’ores et déjà notre modèle à vectoriser le texte à partir de la méthode TF-IDF. Pour le moment il n’est pas encore question de faire de l’évaluation, faisons donc un entraînement sur l’ensemble de notre base et pas seulement sur X_train.
pipeline_tfidf.fit(spooky_df['text_clean'])Pipeline(steps=[('tfidf', TfidfVectorizer(max_features=10000))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Fitted attributes
| Name | Type | Value |
|---|---|---|
| fixed_vocabulary_
fixed_vocabulary_: bool True if a fixed vocabulary of term to indices mapping is provided by the user. |
bool | False |
| idf_
idf_: array of shape (n_features,) The inverse document frequency (IDF) vector; only defined if ``use_idf`` is True. |
ndarray[float64](10000,) | [8.4 ,7.48,9.5 ,...,8.8 ,9.09,9.27] |
| vocabulary_
vocabulary_: dict A mapping of terms to feature indices. |
dict | {'abandon': np.int64(0), 'ab...ed': np.int64(1), 'ab...ng': np.int64(2), 'ab...nt': np.int64(3), ...} |
10000 features
| abandon |
| abandoned |
| abandoning |
| abandonment |
| abaout |
| abbey |
| abdication |
| abdul |
| abernethy |
| abhor |
| abhorred |
| abhorrence |
| abhorrent |
| abilities |
| ability |
| abject |
| able |
| abnormal |
| abnormality |
| abnormally |
| abode |
| abodes |
| about |
| above |
| abroad |
| abrupt |
| abruptly |
| absence |
| absent |
| absolute |
| absolutely |
| absorbed |
| absorbing |
| abstract |
| abstraction |
| absurd |
| absurdity |
| absurdly |
| abundance |
| abundant |
| abundantly |
| abysmal |
| abyss |
| abysses |
| academy |
| accelerated |
| accent |
| accents |
| accept |
| accepted |
| access |
| accident |
| accidental |
| accidentally |
| accidents |
| accommodation |
| accompanied |
| accompany |
| accompanying |
| accomplish |
| accomplished |
| accomplishing |
| accomplishment |
| accomplishments |
| accord |
| accordance |
| accorded |
| according |
| accordingly |
| accost |
| accosted |
| account |
| accounted |
| accounting |
| accounts |
| accumulated |
| accuracy |
| accurate |
| accurately |
| accursed |
| accuse |
| accused |
| accustomed |
| acetylene |
| achieve |
| achieved |
| achievement |
| achievements |
| aching |
| acknowledge |
| acknowledged |
| acquaintance |
| acquaintances |
| acquainted |
| acquire |
| acquired |
| acquirement |
| acquiring |
| acre |
| across |
| act |
| acted |
| acting |
| action |
| actions |
| active |
| activity |
| actor |
| acts |
| actual |
| actually |
| actuated |
| acumen |
| acute |
| adam |
| adaptation |
| adapted |
| adapting |
| add |
| added |
| adding |
| addition |
| additional |
| address |
| addressed |
| addressing |
| adds |
| adduced |
| adept |
| adequate |
| adieu |
| adjacent |
| adjoining |
| adjure |
| adjust |
| adjusted |
| adjusting |
| admeasurement |
| administered |
| administration |
| admirable |
| admiralty |
| admiration |
| admire |
| admired |
| admission |
| admit |
| admitted |
| admitting |
| adopt |
| adopted |
| adoration |
| adore |
| adored |
| adorn |
| adorned |
| adrian |
| advance |
| advanced |
| advances |
| advancing |
| advantage |
| advantages |
| advent |
| adventure |
| adventurer |
| adventures |
| adventurous |
| adversary |
| advertisement |
| advertiser |
| advice |
| advisable |
| advise |
| advised |
| aeons |
| aerial |
| aesthetic |
| aether |
| afar |
| affability |
| affair |
| affairs |
| affect |
| affectation |
| affected |
| affecting |
| affection |
| affectionate |
| affections |
| affidavits |
| affinity |
| afflicted |
| affliction |
| afford |
| afforded |
| affording |
| affords |
| affright |
| afore |
| afraid |
| africa |
| african |
| after |
| afternoon |
| afterward |
| afterwards |
| again |
| against |
| agatha |
| agathos |
| age |
| aged |
| agency |
| agent |
| agents |
| ages |
| aggravated |
| aghast |
| agility |
| agin |
| agitated |
| agitation |
| ago |
| agonies |
| agonized |
| agonizing |
| agony |
| agree |
| agreeable |
| agreed |
| agreement |
| agrippa |
| ah |
| ahead |
| ai |
| aid |
| aided |
| aim |
| aimed |
| ainsworth |
| air |
| aira |
| airs |
| airy |
| ajar |
| akin |
| alarm |
| alarmed |
| alarming |
| alas |
| albany |
| albertus |
| albino |
| alchemy |
| alcove |
| aldebaran |
| ale |
| alert |
| alexander |
| alfred |
| alhazred |
| alien |
| alienage |
| alight |
| alighted |
| alike |
| alive |
| all |
| allay |
| alleviation |
| alley |
| alleys |
| alliance |
| allied |
| allotted |
| allow |
| allowed |
| allowing |
| alloy |
| allude |
| alluded |
| allus |
| allusion |
| almighty |
| almost |
| aloft |
| alone |
| along |
| aloud |
| alpha |
| alphabet |
| alps |
| already |
| also |
| altar |
| alter |
| alteration |
| alterations |
| altered |
| altering |
| alternate |
| alternately |
| alternative |
| although |
| altitude |
| altogether |
| always |
| am |
| amazed |
| amazement |
| amazing |
| ambassador |
| ambition |
| ambitious |
| ambush |
| amendment |
| america |
| american |
| ami |
| amiable |
| amid |
| amidst |
| ammonia |
| among |
| amongst |
| amontillado |
| amount |
| amounted |
| amounting |
| amounts |
| amphitheatre |
| ample |
| amply |
| amulet |
| amuse |
| amused |
| amusement |
| amusements |
| an |
| analogous |
| analogy |
| analyse |
| analysis |
| analytical |
| ancestor |
| ancestors |
| ancestral |
| ancestry |
| anchor |
| ancient |
| and |
| andrée |
| anecdotes |
| anew |
| angel |
| angelic |
| angell |
| angels |
| anger |
| angle |
| angled |
| angles |
| angrily |
| angry |
| anguish |
| animal |
| animals |
| animate |
| animated |
| animating |
| animation |
| animosity |
| ankle |
| ankles |
| ann |
| annals |
| annihilated |
| annihilation |
| anniversary |
| announce |
| announced |
| announcement |
| annoy |
| annoyance |
| annoyed |
| annoying |
| annual |
| anomalous |
| anomaly |
| anon |
| another |
| answer |
| answered |
| answering |
| answers |
| antagonist |
| ante |
| antediluvian |
| antennæ |
| anthropological |
| anticipate |
| anticipated |
| anticipation |
| anticipations |
| antiochus |
| antipodes |
| antiquarian |
| antique |
| antiquities |
| antiquity |
| anxiety |
| anxious |
| anxiously |
| any |
| anybody |
| anyhow |
| anyone |
| anything |
| aout |
| apart |
| apartment |
| apartments |
| apathy |
| ape |
| aperture |
| apes |
| apex |
| appalled |
| appalling |
| apparatus |
| apparel |
| apparent |
| apparently |
| apparition |
| appeal |
| appeals |
| appear |
| appearance |
| appearances |
| appeared |
| appearing |
| appears |
| appellation |
| appertaining |
| appertains |
| appetite |
| applause |
| appleton |
| applicable |
| application |
| applied |
| apply |
| applying |
| appointed |
| appointment |
| appreciable |
| appreciate |
| appreciation |
| apprehended |
| apprehension |
| apprehensions |
| approach |
| approached |
| approaches |
| approaching |
| approbation |
| appropriate |
| appropriated |
| april |
| apt |
| arab |
| arabesque |
| arabian |
| arch |
| archaic |
| archangel |
| arched |
| archer |
| architect |
| architectural |
| architecture |
| archon |
| ardent |
| ardently |
| ardor |
| ardour |
| are |
| area |
| argue |
| argued |
| argument |
| arguments |
| aries |
| aright |
| arise |
| arisen |
| arises |
| arising |
| aristocracy |
| arkham |
| arm |
| armed |
| armies |
| armitage |
| arms |
| army |
| aromatic |
| arose |
| around |
| arouse |
| aroused |
| arousing |
| arrange |
| arranged |
| arrangement |
| arrangements |
| arranging |
| arrant |
| array |
| arrest |
| arrested |
| arrival |
| arrive |
| arrived |
| arrives |
| arriving |
| arrogance |
| arrow |
| arrows |
| art |
| arter |
| arthur |
| article |
| articles |
| articulate |
| artifice |
| artificial |
| artist |
| artists |
| arts |
| as |
| asaph |
| ascend |
| ascendancy |
| ascended |
| ascending |
| ascension |
| ascent |
| ascertain |
| ascertained |
| ascertaining |
| asellius |
| ashamed |
| ashes |
| asia |
| asiatic |
| aside |
| ask |
| asked |
| asking |
| asleep |
| aspect |
| aspirations |
| ass |
| assailed |
| assassin |
| assassins |
| assault |
| assemblage |
| assembled |
| assemblies |
| assembly |
| assent |
| assented |
| assert |
| asserted |
| assertion |
| assertions |
| assign |
| assigned |
| assist |
| assistance |
| assistant |
| assisted |
| assisting |
| associate |
| associated |
| associates |
| association |
| associations |
| assume |
| assumed |
| assuming |
| assumption |
| assurance |
| assure |
| assured |
| assuredly |
| ast |
| astern |
| astonish |
| astonished |
| astonishing |
| astonishment |
| astounded |
| astounding |
| astronomer |
| astronomers |
| astronomical |
| astronomy |
| asylum |
| at |
| atal |
| ate |
| athenians |
| athens |
| atlantic |
| atmosphere |
| atmospheric |
| atomic |
| atrocious |
| atrocity |
| attached |
| attachment |
| attack |
| attacked |
| attacks |
| attain |
| attainable |
| attained |
| attaining |
| attainment |
| attempt |
| attempted |
| attempting |
| attempts |
| attend |
| attendance |
| attendant |
| attendants |
| attended |
| attending |
| attention |
| attentions |
| attentive |
| attentively |
| attic |
| attired |
| attitude |
| attract |
| attracted |
| attraction |
| attractions |
| attractive |
| attribute |
| attributed |
| attributes |
| attributing |
| au |
| auckland |
| audacity |
| audible |
| audience |
| aught |
| augmented |
| august |
| aunt |
| auseil |
| auspices |
| austere |
| author |
| authorities |
| authority |
| authors |
| automaton |
| autumn |
| autumnal |
| avail |
| avalanche |
| avarice |
| ave |
| avenue |
| avenues |
| average |
| averred |
| averse |
| aversion |
| averted |
| avid |
| avidly |
| avoid |
| avoided |
| await |
| awaited |
| awaiting |
| awake |
| awaked |
| awaken |
| awakened |
| awakening |
| awaking |
| aware |
| away |
| awe |
| awed |
| awesome |
| awful |
| awhile |
| awkward |
| awkwardly |
| awoke |
| axe |
| axioms |
| axis |
| ay |
| aye |
| aylesbury |
| azathoth |
| azure |
| babel |
| babes |
| babson |
| back |
| backed |
| background |
| backs |
| backward |
| backwoods |
| bad |
| bade |
| badly |
| baffled |
| bafflement |
| baffling |
| bag |
| baggage |
| bags |
| balance |
| balanced |
| balbutius |
| bald |
| ball |
| ballast |
| balloon |
| balloons |
| balm |
| balmy |
| balustrade |
| ban |
| band |
| bandage |
| bands |
| bane |
| bangus |
| banish |
| banished |
| bank |
| banker |
| bankrupt |
| banks |
| banners |
| banquet |
| bar |
| barbarous |
| bare |
| barely |
| barge |
| bark |
| barked |
| barking |
| barn |
| barometer |
| baron |
| barred |
| barrel |
| barrels |
| barren |
| barrier |
| barriers |
| barrière |
| barry |
| barzai |
| bas |
| basalt |
| base |
| based |
| basement |
| basis |
| basket |
| bat |
| bathed |
| bathroom |
| bats |
| battered |
| batteries |
| battering |
| battery |
| battle |
| battlements |
| bay |
| baying |
| bayonet |
| be |
| beach |
| beacon |
| beam |
| beamed |
| beaming |
| beams |
| bear |
| beard |
| bearded |
| bearing |
| bears |
| beast |
| beasts |
| beat |
| beaten |
| beating |
| beaufort |
| beauteous |
| beauties |
| beautiful |
| beauty |
| beauvais |
| became |
| because |
| beckoned |
| beckoning |
| become |
| becomes |
| becoming |
| bed |
| bedloe |
| beds |
| bedside |
| bedstead |
| bee |
| beech |
| been |
| beetle |
| befall |
| befallen |
| befitting |
| before |
| beg |
| began |
| beggar |
| begged |
| begin |
| beginning |
| begins |
| begone |
| begun |
| behalf |
| behaved |
| behavior |
| beheld |
| behind |
| behold |
| beholder |
| beholding |
| bein |
| being |
| beings |
| beldame |
| belfry |
| belied |
| belief |
| beliefs |
| believe |
| believed |
| believes |
| believing |
| bell |
| belles |
| bells |
| belong |
| belonged |
| belonging |
| beloved |
| below |
| belt |
| ben |
| bench |
| benches |
| bend |
| bendin |
| bending |
| beneath |
| benefactor |
| beneficial |
| benefit |
| benevolence |
| benevolent |
| benign |
| benignity |
| bennett |
| bent |
| bequeathed |
| bequest |
| berenice |
| berlifitzing |
| berries |
| berry |
| beryl |
| beset |
| beside |
| besides |
| besieged |
| besought |
| besprinkled |
| best |
| bestial |
| bestow |
| bestowed |
| bestowing |
| betook |
| betray |
| betrayed |
| betrothed |
| better |
| between |
| betwixt |
| beware |
| bewildered |
| bewildering |
| bewilderment |
| beyond |
| bias |
| bid |
| bidding |
| bids |
| big |
| bigger |
| bill |
| bin |
| bind |
| biological |
| birch |
| bird |
| birds |
| birth |
| birthday |
| bishop |
| bit |
| bite |
| bits |
| bitter |
| bitterest |
| bitterly |
| bitterness |
| bizarre |
| black |
| blackened |
| blacker |
| blackest |
| blackguards |
| blackness |
| blackwood |
| blade |
| blame |
| blanc |
| bland |
| blank |
| blasphemous |
| blasphemy |
| blast |
| blasted |
| blaze |
| blazed |
| blazing |
| bleak |
| bleeding |
| blend |
| blended |
| bless |
| blessed |
| blessing |
| blessings |
| bleu |
| blew |
| blight |
| blind |
| blinded |
| blinding |
| blindly |
| bliss |
| blissful |
| block |
| blocked |
| blocks |
| blood |
| blooded |
| bloodless |
| bloody |
| bloom |
| blooming |
| blossoms |
| blotted |
| blow |
| blowing |
| blows |
| blue |
| blunt |
| blurred |
| blush |
| blushed |
| board |
| boarded |
| boarding |
| boards |
| boast |
| boasted |
| boat |
| boats |
| bob |
| bobby |
| bodies |
| bodily |
| body |
| bog |
| boisterous |
| bold |
| boldly |
| boldness |
| bolt |
| bolted |
| bolton |
| bolts |
| bon |
| bonaparte |
| bondage |
| bonds |
| bone |
| bones |
| bonnet |
| bony |
| book |
| books |
| bookseller |
| boon |
| bordered |
| bordering |
| borders |
| bore |
| born |
| borne |
| borough |
| borrowed |
| bosom |
| bosoms |
| boston |
| both |
| bother |
| bothered |
| bottle |
| bottles |
| bottom |
| bottomed |
| bottoms |
| boughs |
| bought |
| bound |
| boundaries |
| boundary |
| bounded |
| boundless |
| bounds |
| bout |
| bow |
| bowed |
| bower |
| bowing |
| bowl |
| bows |
| box |
| boxes |
| boy |
| boyhood |
| boyish |
| boys |
| brain |
| brainless |
| brains |
| brambles |
| branch |
| branches |
| brandy |
| bransby |
| brass |
| brave |
| breach |
| bread |
| breadth |
| break |
| breakfast |
| breaking |
| breakwater |
| breast |
| breath |
| breathe |
| breathed |
| breathes |
| breathing |
| breathless |
| bred |
| breeches |
| breeding |
| breeze |
| breezes |
| brevet |
| brewster |
| brick |
| bricks |
| brickwork |
| bride |
| briden |
| bridge |
| bridges |
| brief |
| briefly |
| brigadier |
| bright |
| brightened |
| brighter |
| brightest |
| brightly |
| brightness |
| brilliancy |
| brilliant |
| brilliantly |
| brim |
| bring |
| bringing |
| brings |
| brink |
| britain |
| british |
| broad |
| broke |
| broken |
| bronze |
| brooded |
| brooding |
| brook |
| brooks |
| brother |
| brotherly |
| brothers |
| brougham |
| brought |
| brow |
| brown |
| brownish |
| brows |
| bruises |
| brush |
| brushes |
| brutal |
| brute |
| bubbling |
| buckle |
| bud |
| bug |
| bugs |
| build |
| building |
| buildings |
| built |
| bulging |
| bulk |
| bull |
| bullet |
| bumper |
| bunch |
| bundle |
| buoys |
| burden |
| bureau |
| burghers |
| burgomaster |
| burial |
| buried |
| burke |
| burn |
| burned |
| burning |
| burnt |
| burrows |
| burst |
| bursting |
| burthen |
| bury |
| burying |
| bus |
| bushes |
| busied |
| business |
| bustle |
| busy |
| but |
| butcher |
| butchery |
| butterfly |
| buttons |
| buy |
| buying |
| buzz |
| by |
| bye |
| bygone |
| ca |
| cabin |
| cabinet |
| cabins |
| cadence |
| caesar |
| caked |
| calagurris |
| calamities |
| calamity |
| calc |
| calculate |
| calculated |
| calculating |
| calculation |
| calculations |
| calculus |
| california |
| call |
| called |
| calling |
| calls |
| calm |
| calmed |
| calmer |
| calmly |
| calmness |
| came |
| cameleopard |
| camp |
| can |
| canal |
| candidate |
| candle |
| candles |
| cannibal |
| cannon |
| canoe |
| canopy |
| canst |
| canvas |
| canvass |
| cap |
| capable |
| capacities |
| capacity |
| cape |
| capital |
| caprices |
| capt |
| captain |
| captive |
| capture |
| captured |
| car |
| carcass |
| card |
| cards |
| care |
| cared |
| career |
| careful |
| carefully |
| careless |
| carelessly |
| carelessness |
| cares |
| caressed |
| caresses |
| caressing |
| carpentry |
| carpet |
| carpets |
| carriage |
| carriages |
| carried |
| carries |
| carrington |
| carry |
| carrying |
| cart |
| carter |
| carved |
| carven |
| carving |
| carvings |
| case |
| casement |
| casements |
| cases |
| cask |
| casket |
| casks |
| cast |
| casting |
| castle |
| castles |
| castro |
| casual |
| casually |
| cat |
| cataclysmic |
| catacombs |
| catalepsy |
| cataract |
| catastrophe |
| catch |
| catching |
| cathuria |
| cats |
| cattle |
| caught |
| cause |
| caused |
| causes |
| causeway |
| causing |
| caution |
| cautious |
| cautiously |
| cave |
| caved |
| cavern |
| cavernous |
| caverns |
| caves |
| cavities |
| cavity |
| cayley |
| cease |
| ceased |
| ceaseless |
| ceasing |
| ceiling |
| celebrated |
| celephaïs |
| celestial |
| cell |
| cellar |
| cellars |
| cells |
| cemeteries |
| cemetery |
| censer |
| censers |
| censure |
| cent |
| central |
| centre |
| centres |
| cents |
| centuried |
| centuries |
| century |
| ceremonial |
| ceremonies |
| ceremony |
| certain |
| certainly |
| certainty |
| cessation |
| cetera |
| cha |
| chafed |
| chagrin |
| chain |
| chained |
| chains |
| chair |
| chairs |
| chaise |
| chamber |
| chambers |
| chambre |
| chamounix |
| chance |
| chanced |
| chances |
| change |
| changed |
| changeful |
| changes |
| changing |
| channel |
| channels |
| chant |
| chantilly |
| chanting |
| chaos |
| chaotic |
| chapter |
| character |
| characteristic |
| characterized |
| characters |
| charge |
| charged |
| charity |
| charles |
| charleston |
| charm |
| charmion |
| charms |
| charnel |
| charred |
| chart |
| chase |
| chased |
| chasm |
| chateau |
| chattered |
| che |
| cheap |
| cheat |
| check |
| checked |
| cheek |
| cheeks |
| cheer |
| cheerful |
| cheerfully |
| cheerfulness |
| cheering |
| cheese |
| chemical |
| chemicals |
| chemist |
| chemistry |
| cherish |
| cherished |
| cherub |
| chess |
| chest |
| chevalier |
| chicken |
| chief |
| chiefest |
| chiefly |
| child |
| childhood |
| childish |
| childless |
| children |
| chill |
| chilled |
| chilling |
| chilly |
| chimera |
| chimerical |
| chimney |
| chimneys |
| chin |
| china |
| chinese |
| chisel |
| chiselled |
| choice |
| choked |
| choking |
| choose |
| choosing |
| chords |
| chose |
| chosen |
| choynski |
| christian |
| chuckled |
| church |
| churches |
| churchyard |
| churning |
| cipher |
| circle |
| circles |
| circuit |
| circular |
| circulation |
| circumference |
| circumstance |
| circumstances |
| circus |
| citadel |
| cities |
| citizen |
| citizens |
| city |
| civil |
| civilisation |
| civilization |
| civilized |
| clad |
| claim |
| claimed |
| claims |
| clambered |
| clamour |
| clang |
| clapham |
| clapped |
| clara |
| clark |
| clasp |
| clasped |
| clasping |
| class |
| classes |
| classic |
| classical |
| classify |
| clatter |
| claw |
| clawed |
| claws |
| clay |
| clean |
| cleanliness |
| clear |
| cleared |
| clearing |
| clearly |
| clearness |
| clenched |
| clerical |
| clerk |
| clerval |
| clever |
| clew |
| clicking |
| cliff |
| cliffs |
| climate |
| climax |
| climb |
| climbed |
| climbing |
| clime |
| cling |
| clinging |
| cloak |
| cloaks |
| clock |
| clocks |
| close |
| closed |
| closely |
| closer |
| closes |
| closest |
| closet |
| closing |
| cloth |
| clothed |
| clothes |
| clothing |
| cloud |
| clouded |
| cloudless |
| clouds |
| cloudy |
| club |
| clue |
| clump |
| clumsily |
| clumsy |
| clung |
| cluster |
| clustered |
| clutched |
| coach |
| coarse |
| coast |
| coat |
| coated |
| coats |
| cobbler |
| cock |
| code |
| coffee |
| coffin |
| coffins |
| cognizance |
| cognizant |
| coherent |
| cohort |
| coincidence |
| coincidences |
| coins |
| cold |
| coldly |
| coldness |
| collapsed |
| collar |
| colleague |
| colleagues |
| collect |
| collected |
| collecting |
| collection |
| college |
| colloquy |
| colonial |
| colonists |
| color |
| colored |
| colors |
| colossal |
| colour |
| coloured |
| colouring |
| colours |
| column |
| columns |
| combat |
| combination |
| combinations |
| combined |
| combining |
| come |
| comes |
| comet |
| comfort |
| comfortable |
| comforter |
| coming |
| command |
| commanded |
| commander |
| commanding |
| commence |
| commenced |
| commencement |
| comment |
| comments |
| commerce |
| commercial |
| commerciel |
| commission |
| commit |
| committed |
| committing |
| common |
| commonest |
| commonly |
| commune |
| communicate |
| communicated |
| communicating |
| communication |
| communications |
| communion |
| communities |
| community |
| compact |
| companies |
| companion |
| companions |
| companionship |
| company |
| comparative |
| comparatively |
| compare |
| compared |
| comparing |
| comparison |
| compartment |
| compass |
| compassion |
| competent |
| competition |
| complacency |
| complain |
| complained |
| complaint |
| complaints |
| complete |
| completed |
| completely |
| completion |
| complex |
| complexion |
| compliance |
| complicated |
| comply |
| compose |
| composed |
| composing |
| composition |
| composure |
| compound |
| comprehend |
| comprehended |
| comprehension |
| comprehensive |
| compressed |
| comrades |
| comte |
| conceal |
| concealed |
| concealing |
| concealment |
| conceit |
| conceivable |
| conceive |
| conceived |
| conceiving |
| concentrated |
| concentration |
| conception |
| conceptions |
| concern |
| concerned |
| concerning |
| concerns |
| conciliating |
| conclude |
| concluded |
| concluding |
| conclusion |
| conclusions |
| conclusive |
| concord |
| concurrence |
| condemned |
| condensation |
| condenser |
| condition |
| conditions |
| conduct |
| conducted |
| cone |
| conference |
| confess |
| confessed |
| confession |
| confide |
| confided |
| confidence |
| confidential |
| confidently |
| confine |
| confined |
| confinement |
| confines |
| confirm |
| confirmation |
| confirmed |
| conflict |
| conflicting |
| conformation |
| confounded |
| confronted |
| confronting |
| confused |
| confusedly |
| confusion |
| congenial |
| congo |
| congratulated |
| congregated |
| congregational |
| conical |
| conjecture |
| conjectured |
| conjectures |
| conjure |
| conjured |
| connect |
| connected |
| connecting |
| connection |
| connexion |
| conquer |
| conquered |
| conquering |
| conqueror |
| conquest |
| conscience |
| conscientiously |
| conscious |
| consciousness |
| consecrated |
| consent |
| consented |
| consequence |
| consequences |
| consequent |
| consequently |
| consider |
| considerable |
| considerably |
| considerate |
| consideration |
| considerations |
| considered |
| considering |
| consigned |
| consisted |
| consistency |
| consistent |
| consists |
| consolation |
| consolations |
| console |
| conspicuous |
| constancy |
| constant |
| constantinople |
| constantly |
| consternation |
| constituted |
| constitution |
| constitutional |
| constrained |
| construct |
| constructed |
| construction |
| consult |
| consulted |
| consume |
| consumed |
| consuming |
| consummate |
| consummated |
| consummation |
| consumption |
| contact |
| contagion |
| contain |
| contained |
| containing |
| contemplate |
| contemplated |
| contemplation |
| contemporaries |
| contempt |
| contemptible |
| contemptuously |
| content |
| contented |
| contention |
| contents |
| contest |
| continent |
| continual |
| continually |
| continuance |
| continue |
| continued |
| continuing |
| continuity |
| continuous |
| contour |
| contracted |
| contradiction |
| contradictions |
| contrary |
| contrast |
| contrasted |
| contribute |
| contributed |
| contributions |
| contrive |
| contrived |
| control |
| convalescence |
| convenience |
| convenient |
| conventional |
| conversation |
| conversations |
| converse |
| conversed |
| converted |
| convex |
| convey |
| conveyed |
| conviction |
| convince |
| convinced |
| convincing |
| convulsed |
| convulsion |
| convulsions |
| convulsive |
| cool |
| coolly |
| copied |
| copies |
| copper |
| copy |
| cord |
| cordial |
| core |
| corey |
| cork |
| corn |
| cornelius |
| corner |
| cornered |
| corners |
| cornices |
| cornwallis |
| corpse |
| corpses |
| correct |
| correspond |
| correspondence |
| correspondent |
| corresponding |
| corridor |
| corridors |
| corroboration |
| corruption |
| cosmic |
| cosmos |
| cost |
| costly |
| costume |
| cot |
| cottage |
| cottagers |
| cottages |
| cotters |
| cotton |
| couch |
| cough |
| could |
| council |
| counsel |
| count |
| counted |
| countenance |
| countenances |
| counter |
| countess |
| counties |
| countless |
| countries |
| country |
| countrymen |
| countryside |
| county |
| couple |
| coupled |
| courage |
| course |
| courses |
| court |
| courteous |
| courtesy |
| courtiers |
| courts |
| courtyard |
| cousin |
| cover |
| covered |
| covering |
| covers |
| covert |
| coward |
| cowardice |
| cowards |
| cowed |
| cows |
| crab |
| cracked |
| crackling |
| cradle |
| cradled |
| crag |
| crags |
| crash |
| crashed |
| crashing |
| craving |
| crawford |
| crawl |
| crawled |
| crawling |
| crazed |
| crazily |
| crazy |
| creaked |
| creaking |
| create |
| created |
| creates |
| creating |
| creation |
| creations |
| creative |
| creator |
| creature |
| creatures |
| credit |
| creditors |
| creeds |
| creek |
| creeping |
| crept |
| crescent |
| crest |
| crevice |
| crew |
| cried |
| cries |
| crime |
| crimes |
| criminal |
| crimson |
| crisis |
| critical |
| criticism |
| croaking |
| croissart |
| crooked |
| cross |
| crossed |
| crossing |
| crouching |
| crow |
| crowd |
| crowded |
| crown |
| crowned |
| crowning |
| crucifix |
| crude |
| cruel |
| cruelly |
| cruelty |
| crumbled |
| crumbling |
| crumpled |
| crush |
| crushed |
| cry |
| cryptic |
| cryptical |
| crystal |
| cthulhu |
| cubits |
| cud |
| cuff |
| cult |
| cultivated |
| cultivation |
| cults |
| culture |
| cum |
| cumberland |
| cunning |
| cup |
| cupalo |
| cupboard |
| cure |
| curiosity |
| curious |
| curiously |
| curled |
| curling |
| current |
| currents |
| curse |
| cursed |
| cursing |
| cursory |
| curtain |
| curtained |
| curtains |
| curtis |
| curve |
| curves |
| curving |
| custom |
| customary |
| customs |
| cut |
| cuts |
| cutting |
| cuttings |
| cyclopean |
| cylinder |
| cylindrical |
| cypress |
| czanek |
| dabbled |
| daddy |
| daemon |
| daemoniac |
| daemons |
| dagon |
| daily |
| damn |
| damnable |
| damnably |
| damned |
| damp |
| dampness |
| dance |
| danced |
| dancers |
| dancing |
| dandy |
| danger |
| dangerous |
| dangerously |
| dangers |
| dangling |
| dank |
| dante |
| daown |
| dare |
| dared |
| dares |
| daring |
| dark |
| darkened |
| darkest |
| darkly |
| darkness |
| darling |
| darted |
| dash |
| dashed |
| dashing |
| dat |
| data |
| date |
| dated |
| dating |
| daughter |
| daughters |
| david |
| davis |
| davy |
| dawn |
| dawned |
| day |
| daybreak |
| daylight |
| days |
| dazed |
| dazzled |
| dazzling |
| de |
| dead |
| deadly |
| deaf |
| deafening |
| deal |
| dealing |
| dean |
| dear |
| dearer |
| dearest |
| death |
| deaths |
| debate |
| debauch |
| debris |
| debt |
| debts |
| decadent |
| decay |
| decayed |
| decaying |
| decease |
| deceased |
| deceit |
| deceive |
| deceived |
| december |
| decent |
| decide |
| decided |
| decidedly |
| decipher |
| decision |
| decisive |
| deck |
| declare |
| declared |
| declares |
| declaring |
| decline |
| declined |
| declivity |
| decomposition |
| decorated |
| decorum |
| decrease |
| decreased |
| decree |
| decreed |
| decrees |
| decrepit |
| decrepitude |
| dedicated |
| deduced |
| deductions |
| dee |
| deed |
| deeds |
| deem |
| deemed |
| deep |
| deepened |
| deepening |
| deeper |
| deepest |
| deeply |
| deer |
| defaulter |
| defeat |
| defect |
| defective |
| defects |
| defence |
| defenceless |
| defend |
| defended |
| defiance |
| deficiency |
| deficient |
| defied |
| define |
| defined |
| definite |
| definitely |
| deformed |
| deformity |
| degenerate |
| degradation |
| degraded |
| degree |
| degrees |
| deity |
| delay |
| delayed |
| deliberate |
| deliberately |
| deliberateness |
| deliberation |
| delicacy |
| delicate |
| delicately |
| delicious |
| delight |
| delighted |
| delightful |
| delights |
| delirious |
| delirium |
| deliver |
| deliverance |
| delivered |
| deliverer |
| deluc |
| deluged |
| delusion |
| demand |
| demanded |
| demands |
| demeanor |
| demeanour |
| demon |
| demoniacal |
| demons |
| demonstrate |
| demonstrated |
| demonstration |
| demonstrations |
| den |
| denial |
| denied |
| denizens |
| dense |
| denser |
| density |
| deny |
| denys |
| depart |
| departed |
| departure |
| depend |
| depended |
| dependent |
| depends |
| depict |
| depicted |
| deposes |
| deposit |
| deposited |
| deposition |
| deposits |
| depressed |
| depression |
| deprive |
| deprived |
| depth |
| depths |
| deputy |
| der |
| derelict |
| derive |
| derived |
| des |
| desart |
| descend |
| descendant |
| descendants |
| descended |
| descending |
| descends |
| descent |
| describe |
| described |
| describes |
| description |
| descriptions |
| desert |
| deserted |
| desertion |
| deserts |
| deserve |
| deserved |
| design |
| designated |
| designed |
| designs |
| desire |
| desired |
| desires |
| desirous |
| desk |
| desolate |
| desolation |
| despair |
| despairing |
| desperado |
| desperate |
| desperately |
| desperation |
| despised |
| despite |
| despondency |
| despotism |
| desrochers |
| destination |
| destined |
| destinies |
| destiny |
| destitute |
| destroy |
| destroyed |
| destroyer |
| destroying |
| destruction |
| destructive |
| detail |
| detailed |
| details |
| detain |
| detained |
| detect |
| detected |
| detecting |
| deterioration |
| determination |
| determine |
| determined |
| determining |
| detestable |
| developed |
| developing |
| development |
| deviate |
| device |
| devices |
| devil |
| devilish |
| devils |
| devoid |
| devote |
| devoted |
| devoting |
| devotion |
| devour |
| devoured |
| devouring |
| dew |
| dews |
| dexter |
| dexterity |
| di |
| diabolic |
| diabolism |
| diadem |
| dial |
| dialect |
| diameter |
| diamond |
| diana |
| diary |
| did |
| diddle |
| diddler |
| didst |
| die |
| died |
| dies |
| diet |
| dieu |
| differ |
| differed |
| difference |
| different |
| difficult |
| difficulties |
| difficulty |
| diffused |
| dig |
| digging |
| dignified |
| dignity |
| dilapidated |
| dilemma |
| diligence |
| dim |
| dimension |
| dimensional |
| dimensions |
| diminish |
| diminished |
| diminishing |
| diminution |
| diminutive |
| dimly |
| dimmed |
| dingy |
| dining |
| dinner |
| dint |
| diotima |
| dire |
| direct |
| directed |
| directing |
| direction |
| directions |
| directly |
| dirge |
| dirt |
| dirty |
| dis |
| disagreeable |
| disappear |
| disappearance |
| disappeared |
| disappearing |
| disappointed |
| disappointment |
| disarrangement |
| disaster |
| disasters |
| disastrous |
| disbelief |
| discarded |
| discern |
| discerned |
| discernible |
| discharge |
| discharged |
| disciple |
| discipline |
| disclose |
| disclosed |
| disclosing |
| discomfort |
| discord |
| discordant |
| discourse |
| discoursed |
| discover |
| discovered |
| discoveries |
| discovering |
| discovery |
| discuss |
| discussed |
| discussing |
| discussion |
| disdain |
| disdained |
| disdainfully |
| disease |
| diseased |
| disengaged |
| disgrace |
| disguise |
| disgust |
| disgusted |
| disgusting |
| dish |
| dishevelled |
| disjointed |
| disk |
| dislike |
| disliked |
| dismal |
| dismay |
| dismiss |
| dismissed |
| disorder |
| disordered |
| dispel |
| dispelled |
| disperse |
| displaced |
| display |
| displayed |
| displaying |
| displays |
| disposal |
| disposed |
| disposition |
| dispositions |
| dispute |
| disputed |
| disquiet |
| disquieting |
| disquietude |
| dissecting |
| dissimilar |
| dissipate |
| dissipated |
| dissipation |
| dissolute |
| dissolution |
| dissolved |
| distance |
| distant |
| distaste |
| distempered |
| distinct |
| distinction |
| distinctive |
| distinctly |
| distinctness |
| distinguish |
| distinguished |
| distorted |
| distortion |
| distracted |
| distress |
| distressed |
| distressing |
| district |
| districts |
| disturb |
| disturbance |
| disturbances |
| disturbed |
| disturbing |
| diverted |
| diverting |
| divest |
| divested |
| divide |
| divided |
| divine |
| divinity |
| division |
| divisions |
| dizzily |
| dizziness |
| dizzy |
| do |
| doctor |
| doctors |
| doctrines |
| document |
| does |
| dog |
| dogged |
| dogs |
| doin |
| doing |
| doings |
| dollar |
| dollars |
| dolphins |
| domain |
| dombrowski |
| dome |
| domes |
| domestic |
| dominion |
| dominions |
| don |
| done |
| doo |
| doodle |
| doom |
| doomed |
| door |
| doors |
| doorway |
| doorways |
| dormant |
| dose |
| double |
| doubled |
| doubly |
| doubt |
| doubted |
| doubtful |
| doubtless |
| doubts |
| dow |
| down |
| downcast |
| downward |
| dozen |
| dr |
| drab |
| drag |
| dragged |
| dragging |
| dragon |
| drama |
| dramatic |
| drank |
| draperies |
| drapery |
| draught |
| draw |
| drawer |
| drawers |
| drawing |
| drawn |
| dread |
| dreaded |
| dreadful |
| dreadfully |
| dreading |
| dream |
| dreamed |
| dreamer |
| dreaming |
| dreams |
| dreamy |
| drear |
| dreary |
| dress |
| dressed |
| dressing |
| drew |
| dried |
| drift |
| drifted |
| drifting |
| drink |
| drinking |
| dripping |
| drive |
| driven |
| driver |
| driving |
| droll |
| drone |
| dronk |
| droop |
| drooping |
| drop |
| dropped |
| dropping |
| drops |
| dross |
| drove |
| drowned |
| drowsiness |
| drowsy |
| drug |
| drugs |
| drum |
| drumming |
| drums |
| drunk |
| drunkard |
| drunken |
| dry |
| drômes |
| du |
| dub |
| dubble |
| dubious |
| duc |
| duchess |
| duck |
| due |
| dug |
| duke |
| dull |
| duly |
| dumas |
| dumb |
| dun |
| dungeon |
| dunkeld |
| dunwich |
| dupe |
| dupin |
| duration |
| during |
| dusk |
| dusky |
| dust |
| dusty |
| dutch |
| dutee |
| duties |
| duty |
| dwell |
| dwellers |
| dwelling |
| dwellings |
| dwelt |
| dwindled |
| dxn |
| dying |
| each |
| eager |
| eagerly |
| eagerness |
| eagle |
| ear |
| earl |
| earldom |
| earlier |
| earliest |
| early |
| earned |
| earnest |
| earnestly |
| earnestness |
| ears |
| earth |
| earthly |
| earthquake |
| ease |
| easier |
| easily |
| east |
| eastern |
| eastward |
| easy |
| eat |
| eaten |
| eating |
| eaves |
| ebony |
| eccentric |
| eccentricities |
| eccentricity |
| echo |
| echoed |
| echoes |
| eclipse |
| eclipsed |
| ecstasies |
| ecstasy |
| ecstatic |
| eddies |
| edge |
| edges |
| edifice |
| edifices |
| edinburgh |
| edition |
| editor |
| editorial |
| educated |
| education |
| eerie |
| ef |
| effaced |
| effect |
| effected |
| effects |
| effectual |
| effectually |
| effort |
| efforts |
| effulgence |
| effusion |
| egress |
| egypt |
| egyptian |
| eh |
| eight |
| eighteen |
| eighteenth |
| eighth |
| eighty |
| either |
| ejaculated |
| el |
| elaborate |
| elapsed |
| elastic |
| elasticity |
| elbow |
| elbows |
| elder |
| elderly |
| eldest |
| eldritch |
| election |
| electric |
| electrical |
| electricity |
| elegance |
| element |
| elements |
| eleonora |
| elephant |
| elephants |
| elevate |
| elevated |
| elevating |
| elevation |
| eleven |
| elicited |
| elinor |
| eliot |
| elixir |
| elizabeth |
| ellison |
| elm |
| elms |
| elopement |
| eloquence |
| eloquent |
| else |
| elsewhere |
| eluded |
| elwood |
| elysian |
| em |
| emaciated |
| embalming |
| embankment |
| embark |
| embarked |
| embarrassed |
| embarrassment |
| embellishments |
| embers |
| embittered |
| embodiment |
| embrace |
| embraced |
| embroidered |
| emendation |
| emerald |
| emerged |
| emerging |
| emigration |
| eminence |
| eminent |
| eminently |
| emitted |
| emitting |
| emma |
| emotion |
| emotions |
| emperor |
| emperors |
| emphasis |
| empire |
| employ |
| employed |
| employing |
| employment |
| emptied |
| empty |
| en |
| enable |
| enabled |
| enamored |
| encampment |
| enchain |
| enchained |
| enchanted |
| enchanting |
| enchantment |
| encircled |
| enclosed |
| enclosure |
| encompassed |
| encounter |
| encountered |
| encountering |
| encourage |
| encouraged |
| encrease |
| encreased |
| encreasing |
| encroachments |
| encrusted |
| end |
| endeared |
| endeavor |
| endeavored |
| endeavoring |
| endeavors |
| endeavour |
| endeavoured |
| endeavouring |
| endeavours |
| ended |
| ending |
| endless |
| endlessly |
| endowed |
| endowments |
| ends |
| endued |
| endurance |
| endure |
| endured |
| enduring |
| enemies |
| enemy |
| energetic |
| energies |
| energy |
| engage |
| engaged |
| engagement |
| engaging |
| engendered |
| engine |
| england |
| english |
| englishman |
| englishmen |
| engrossing |
| engulfed |
| enhanced |
| enigma |
| enjoy |
| enjoyed |
| enjoying |
| enjoyment |
| enjoyments |
| enkindled |
| enlarged |
| enlightened |
| ennui |
| enormous |
| enough |
| enquiries |
| enraged |
| enraptured |
| enshrined |
| enshrouded |
| ensue |
| ensued |
| ensuing |
| ensure |
| entangled |
| enter |
| entered |
| entering |
| enterprise |
| enters |
| entertain |
| entertained |
| enthroned |
| enthusiasm |
| enthusiastic |
| enthusiastically |
| entire |
| entirely |
| entities |
| entitled |
| entity |
| entombed |
| entrance |
| entranced |
| entreat |
| entreated |
| entreaties |
| entreaty |
| entry |
| enunciation |
| enveloped |
| envied |
| environment |
| environs |
| envy |
| epidaphne |
| epidemic |
| epiphanes |
| episode |
| epoch |
| equal |
| equality |
| equalled |
| equally |
| equals |
| equivocal |
| er |
| era |
| erased |
| ere |
| erect |
| erected |
| eric |
| erich |
| ernest |
| error |
| errors |
| erudition |
| escape |
| escaped |
| escapes |
| escaping |
| espanaye |
| especial |
| especially |
| espied |
| esq |
| essay |
| essence |
| essential |
| essentially |
| est |
| establish |
| established |
| establishing |
| establishment |
| estate |
| estates |
| esteem |
| estimate |
| estimated |
| estimation |
| et |
| etc |
| eternal |
| eternally |
| eternity |
| ethelred |
| ether |
| ethereal |
| etienne |
| etoile |
| eton |
| eugenie |
| europe |
| european |
| eustache |
| evadne |
| evanescent |
| eve |
| evelyn |
| even |
| evening |
| evenings |
| event |
| eventful |
| events |
| eventually |
| ever |
| everard |
| everlasting |
| evermore |
| every |
| everybody |
| everyday |
| everyone |
| everything |
| everywhere |
| evidence |
| evident |
| evidently |
| evil |
| evilly |
| evils |
| evinced |
| ex |
| exact |
| exacted |
| exactitude |
| exactly |
| exaggerated |
| exaggeration |
| exaltation |
| exalted |
| exalting |
| examination |
| examine |
| examined |
| examiner |
| examining |
| example |
| exasperated |
| excavated |
| excavation |
| exceed |
| exceeded |
| exceeding |
| exceedingly |
| excellence |
| excellencies |
| excellent |
| except |
| exception |
| exceptions |
| excess |
| excesses |
| excessive |
| excessively |
| exchange |
| exchanged |
| excitable |
| excite |
| excited |
| excitement |
| exciting |
| exclaimed |
| exclamations |
| excluded |
| excursion |
| excursions |
| excuse |
| excuses |
| executed |
| execution |
| exempt |
| exercise |
| exercised |
| exert |
| exerted |
| exertion |
| exertions |
| exhalation |
| exhalations |
| exhausted |
| exhaustion |
| exhaustive |
| exhibit |
| exhibited |
| exhibiter |
| exhibiting |
| exhibition |
| exile |
| exist |
| existed |
| existence |
| existing |
| exists |
| exotic |
| expanded |
| expanse |
| expect |
| expectancy |
| expectation |
| expectations |
| expected |
| expecting |
| expedient |
| expedition |
| expeditions |
| expense |
| expensive |
| experience |
| experienced |
| experiences |
| experiment |
| experimental |
| experiments |
| expert |
| expiration |
| expire |
| expired |
| explain |
| explained |
| explanation |
| explanations |
| explicit |
| exploits |
| explorations |
| explore |
| explorer |
| explosion |
| expose |
| exposed |
| exposure |
| express |
| expressed |
| expresses |
| expressing |
| expression |
| expressions |
| expressive |
| exquisite |
| exquisitely |
| extasy |
| extend |
| extended |
| extending |
| extends |
| extension |
| extensive |
| extent |
| exterior |
| external |
| extinct |
| extinction |
| extinguish |
| extinguished |
| extra |
| extract |
| extraction |
| extracts |
| extraordinary |
| extravagance |
| extravagances |
| extravagant |
| extreme |
| extremely |
| extremes |
| extremity |
| exultation |
| eye |
| eyed |
| eyeing |
| eyelids |
| eyes |
| fable |
| fabric |
| fabulous |
| facade |
| face |
| faced |
| faces |
| facial |
| facility |
| fact |
| factory |
| facts |
| faculties |
| faculty |
| fade |
| faded |
| fading |
| faery |
| fail |
| failed |
| failing |
| fails |
| failure |
| failures |
| faint |
| fainted |
| fainter |
| fainting |
| faintly |
| fair |
| fairest |
| fairly |
| fairy |
| faith |
| faithful |
| fall |
| fallen |
| falling |
| falls |
| false |
| falsehood |
| falter |
| faltered |
| faltering |
| fame |
| familiar |
| familiarity |
| families |
| family |
| famine |
| famous |
| fanatic |
| fancied |
| fancies |
| fanciful |
| fancy |
| fancying |
| fanged |
| fangs |
| fantasia |
| fantastic |
| fantastically |
| faound |
| far |
| fare |
| farewell |
| farm |
| farmhouse |
| farther |
| farthest |
| fascinated |
| fascinating |
| fascination |
| fashion |
| fashionable |
| fashioned |
| fast |
| fasten |
| fastened |
| fastenings |
| faster |
| fastidious |
| fat |
| fatal |
| fatality |
| fate |
| fated |
| fateful |
| father |
| fathers |
| fathom |
| fathoms |
| fatigue |
| fatigued |
| fault |
| favor |
| favorite |
| favour |
| favourable |
| favoured |
| favourite |
| favourites |
| fear |
| feared |
| fearful |
| fearfully |
| fearing |
| fearless |
| fearlessly |
| fears |
| fearsome |
| feast |
| feat |
| feather |
| feathered |
| feats |
| feature |
| features |
| february |
| fed |
| federal |
| feeble |
| feebly |
| feed |
| feel |
| feeling |
| feelings |
| feels |
| feet |
| felicity |
| felix |
| fell |
| feller |
| fellow |
| fellows |
| felon |
| felt |
| female |
| females |
| feminine |
| fence |
| fenner |
| fer |
| ferocity |
| ferry |
| fertile |
| fervent |
| fervid |
| fervour |
| festival |
| festivity |
| fetters |
| fever |
| fevered |
| feverish |
| few |
| fewer |
| fhtagn |
| fibres |
| fiction |
| fictitious |
| fidelity |
| field |
| fields |
| fiend |
| fiendish |
| fiendishly |
| fierce |
| fiery |
| fifteen |
| fifteenth |
| fifth |
| fifty |
| fight |
| fighting |
| figure |
| figured |
| figures |
| filed |
| filial |
| fill |
| filled |
| filling |
| fills |
| filthy |
| final |
| finally |
| find |
| finder |
| finding |
| finds |
| fine |
| finer |
| finest |
| finger |
| fingers |
| finished |
| fire |
| fired |
| fireplace |
| fires |
| firing |
| firm |
| firmament |
| firmly |
| firmness |
| first |
| fish |
| fishermen |
| fishing |
| fishy |
| fissure |
| fit |
| fitfully |
| fitness |
| fits |
| fitted |
| fitting |
| five |
| fix |
| fixed |
| fixing |
| flag |
| flags |
| flame |
| flames |
| flaming |
| flapped |
| flapping |
| flaring |
| flash |
| flashed |
| flashes |
| flashing |
| flashlight |
| flat |
| flatter |
| fled |
| flee |
| fleeting |
| flesh |
| flew |
| flexible |
| flickering |
| flies |
| flight |
| flights |
| flimsy |
| flitted |
| float |
| floated |
| floating |
| flock |
| flocks |
| flood |
| floor |
| floors |
| flopping |
| floundering |
| flour |
| flourish |
| flourished |
| flow |
| flowed |
| flower |
| flowers |
| flowery |
| flowing |
| flows |
| fluid |
| flung |
| flush |
| flushed |
| flute |
| flutes |
| fly |
| flying |
| foam |
| foaming |
| focus |
| foe |
| foetid |
| foetor |
| fog |
| fold |
| folded |
| folding |
| folds |
| foliage |
| folk |
| folklore |
| folks |
| follies |
| follow |
| followed |
| followers |
| following |
| follows |
| folly |
| fond |
| fondness |
| food |
| fool |
| foolish |
| fools |
| foot |
| footman |
| footstep |
| footsteps |
| footstool |
| for |
| forbade |
| forbear |
| forbid |
| forbidden |
| forbidding |
| force |
| forced |
| forces |
| forcibly |
| forcing |
| fore |
| forefathers |
| forehead |
| foreign |
| foreigner |
| foreigners |
| foreman |
| foremost |
| foreseen |
| forest |
| forests |
| foretold |
| forever |
| forget |
| forgetfulness |
| forgetting |
| forgive |
| forgiveness |
| forgot |
| forgotten |
| form |
| formal |
| formation |
| formed |
| former |
| formerly |
| formidable |
| forming |
| formless |
| forms |
| formula |
| formulae |
| fort |
| forth |
| forthwith |
| fortitude |
| fortnight |
| fortunate |
| fortunately |
| fortunato |
| fortune |
| fortunes |
| forty |
| forward |
| fought |
| foul |
| found |
| foundation |
| foundations |
| founded |
| fountain |
| fountains |
| four |
| fourteen |
| fourteenth |
| fourth |
| fox |
| fraction |
| fragile |
| fragment |
| fragments |
| fragrance |
| fragrant |
| frail |
| frame |
| framed |
| france |
| francs |
| frank |
| frankenstein |
| frankly |
| frankness |
| frantic |
| frantically |
| freak |
| fred |
| frederick |
| free |
| freedom |
| freely |
| french |
| frenchman |
| frenzy |
| frequency |
| frequent |
| frequented |
| frequently |
| fresh |
| freshness |
| friday |
| friend |
| friendless |
| friendly |
| friends |
| friendship |
| fright |
| frightened |
| frightful |
| frigid |
| fringed |
| frivolous |
| fro |
| frock |
| frog |
| frogs |
| froissart |
| from |
| front |
| frost |
| frosty |
| frown |
| frozen |
| fruit |
| fruiterer |
| fruitless |
| fruits |
| frye |
| fudge |
| fuel |
| fugitive |
| fulfil |
| fulfilled |
| fulfilling |
| fulfilment |
| full |
| fullest |
| fully |
| fulness |
| fum |
| fumbled |
| fumbling |
| fumes |
| functions |
| funeral |
| funereal |
| fungi |
| fungous |
| fungus |
| funnel |
| funny |
| fur |
| furious |
| furiously |
| furled |
| furnish |
| furnished |
| furniture |
| furry |
| furs |
| further |
| furtherance |
| furtive |
| furtively |
| furtiveness |
| fury |
| fust |
| futile |
| futility |
| future |
| futurity |
| gable |
| gables |
| gad |
| gaiety |
| gain |
| gained |
| gaining |
| gait |
| gale |
| gales |
| gall |
| gallant |
| gallery |
| galley |
| galleys |
| gallons |
| galpin |
| galvanic |
| gambrel |
| game |
| gang |
| gaping |
| garb |
| garden |
| gardening |
| gardens |
| garment |
| garments |
| garret |
| garrison |
| garters |
| gas |
| gasped |
| gasping |
| gasps |
| gate |
| gates |
| gateway |
| gather |
| gathered |
| gathering |
| gaudy |
| gaunt |
| gave |
| gawd |
| gay |
| gaze |
| gazed |
| gazette |
| gazing |
| gelatinous |
| gem |
| gems |
| gendarme |
| genealogical |
| general |
| generally |
| generation |
| generations |
| generosity |
| generous |
| geneva |
| genial |
| genius |
| gentle |
| gentleman |
| gentlemen |
| gentleness |
| gentler |
| gentlest |
| gently |
| genuine |
| geological |
| geometrical |
| george |
| georgian |
| german |
| germany |
| gesture |
| gestures |
| get |
| gets |
| getting |
| ghastly |
| ghost |
| ghostly |
| ghoulish |
| ghouls |
| giant |
| gibbering |
| gibbous |
| giddy |
| gift |
| gifted |
| gifts |
| gigantic |
| gilded |
| gilman |
| girl |
| girls |
| git |
| gits |
| give |
| given |
| giver |
| gives |
| giving |
| glad |
| glades |
| gladly |
| glance |
| glanced |
| glances |
| glancing |
| glare |
| glared |
| glaring |
| glass |
| glasses |
| glassy |
| glazed |
| gleam |
| gleamed |
| gleaming |
| glee |
| glen |
| glendinning |
| glide |
| glided |
| glimpse |
| glimpsed |
| glimpses |
| glistened |
| glistening |
| glittered |
| glittering |
| globe |
| gloom |
| gloomy |
| glories |
| glorious |
| glory |
| glossy |
| gloves |
| glow |
| glowed |
| glowing |
| gnarled |
| gnashed |
| gnawing |
| go |
| goal |
| goat |
| goatish |
| god |
| goddess |
| godfrey |
| godlike |
| gods |
| goes |
| goin |
| going |
| gold |
| golden |
| goldsmith |
| gondola |
| gone |
| good |
| goodness |
| goods |
| goole |
| goosetherumfoodle |
| gorge |
| gorgeous |
| gossip |
| got |
| gothic |
| gott |
| govern |
| government |
| grace |
| graceful |
| gracefully |
| graces |
| gradation |
| grade |
| gradual |
| gradually |
| grand |
| grandeur |
| grandfather |
| grandmother |
| grandmothers |
| grandson |
| granite |
| grant |
| granted |
| granting |
| grasp |
| grasped |
| grass |
| grassy |
| grateful |
| gratification |
| gratified |
| gratify |
| grating |
| gratitude |
| grave |
| gravel |
| gravely |
| graven |
| graves |
| graveyard |
| graveyards |
| gravity |
| gray |
| great |
| greater |
| greatest |
| greatly |
| greatness |
| grecian |
| greece |
| greedily |
| greek |
| greeks |
| green |
| greenish |
| greenwich |
| greeted |
| grew |
| grey |
| grief |
| grieve |
| grieved |
| grim |
| grin |
| grinning |
| grisly |
| groan |
| groaned |
| groans |
| grocery |
| grope |
| groped |
| groping |
| gross |
| grossly |
| grotesque |
| grotesquely |
| grotesqueness |
| grotto |
| ground |
| grounds |
| group |
| groups |
| grove |
| grovelling |
| groves |
| grow |
| growing |
| grown |
| grows |
| growth |
| gruesome |
| gruesomely |
| gruff |
| guard |
| guarded |
| guardian |
| guardians |
| guardianship |
| guess |
| guessed |
| guesses |
| guessing |
| guest |
| guests |
| guidance |
| guide |
| guided |
| guides |
| guilt |
| guiltless |
| guilty |
| guinea |
| guise |
| guitar |
| gulf |
| gulfs |
| gulph |
| gum |
| gush |
| gushed |
| gust |
| guttural |
| gx |
| ha |
| habit |
| habitation |
| habitations |
| habited |
| habits |
| habitual |
| habitually |
| had |
| haff |
| haggard |
| hail |
| hailed |
| hair |
| haired |
| hairs |
| hairy |
| half |
| hall |
| hallowe |
| halls |
| hallucination |
| hallway |
| halo |
| halsey |
| halting |
| hamlet |
| hammer |
| hand |
| handed |
| handkerchief |
| handkerchiefs |
| handle |
| handled |
| hands |
| handsome |
| hang |
| hanged |
| hanging |
| hangings |
| hangman |
| hangs |
| hannah |
| hans |
| haouse |
| haow |
| hapless |
| happen |
| happened |
| happening |
| happens |
| happier |
| happily |
| happiness |
| happy |
| harangue |
| harassed |
| harbour |
| hard |
| harder |
| hardly |
| hardship |
| hardships |
| hardy |
| harm |
| harmless |
| harmony |
| harp |
| harris |
| harrowing |
| harsh |
| harshness |
| harvest |
| has |
| hast |
| haste |
| hasten |
| hastened |
| hastening |
| hastily |
| hasty |
| hat |
| hate |
| hated |
| hateful |
| hath |
| hatheg |
| hatred |
| hats |
| haughty |
| haunt |
| haunted |
| haunting |
| haunts |
| have |
| haven |
| having |
| havoc |
| hawk |
| hazy |
| he |
| head |
| headed |
| headless |
| headlong |
| headquarters |
| heads |
| health |
| healthy |
| heap |
| heaped |
| heaps |
| hear |
| heard |
| hearers |
| hearing |
| heart |
| hearted |
| hearth |
| hearths |
| heartless |
| hearts |
| hearty |
| heat |
| heated |
| heath |
| heave |
| heaved |
| heaven |
| heavenly |
| heavens |
| heavier |
| heavily |
| heaving |
| heavy |
| hectic |
| heed |
| heeded |
| heels |
| heerd |
| hees |
| heh |
| height |
| heighten |
| heightened |
| heights |
| heir |
| heirs |
| held |
| hell |
| hellish |
| help |
| helped |
| helping |
| helpless |
| helseggen |
| hem |
| hemisphere |
| hemmed |
| hen |
| hence |
| henceforward |
| henry |
| henson |
| her |
| herbert |
| herd |
| here |
| hereafter |
| hereditary |
| herein |
| heretofore |
| hereupon |
| heritage |
| hermann |
| hermit |
| hero |
| heroes |
| heroic |
| heroism |
| hers |
| herself |
| hesitate |
| hesitated |
| hesitation |
| heterogeneous |
| hev |
| hewn |
| hey |
| hi |
| hid |
| hidden |
| hide |
| hideous |
| hideously |
| hideousness |
| hiding |
| hieroglyphics |
| high |
| higher |
| highest |
| highly |
| highway |
| hilarity |
| hill |
| hillock |
| hills |
| hillside |
| him |
| himself |
| hind |
| hinges |
| hint |
| hinted |
| hints |
| hippodrome |
| hired |
| his |
| hissing |
| historic |
| historical |
| histories |
| history |
| hit |
| hither |
| hitherto |
| ho |
| hoarse |
| hoary |
| hog |
| hogshead |
| hold |
| holding |
| holds |
| hole |
| holes |
| holland |
| hollow |
| holt |
| holy |
| homage |
| home |
| homer |
| homes |
| homeward |
| honest |
| honor |
| honour |
| honourable |
| honours |
| hoop |
| hope |
| hoped |
| hopeless |
| hopelessly |
| hopelessness |
| hopes |
| hoping |
| horde |
| hordes |
| horizon |
| horizontal |
| horn |
| horned |
| horns |
| horrible |
| horribly |
| horrid |
| horrified |
| horror |
| horrors |
| horse |
| horseback |
| horses |
| hospital |
| hospitals |
| host |
| hostile |
| hostility |
| hot |
| hotel |
| hound |
| hour |
| hourly |
| hours |
| house |
| household |
| houses |
| hovel |
| hover |
| hovered |
| hovering |
| how |
| however |
| howl |
| howled |
| howling |
| howlings |
| hu |
| hue |
| hues |
| huge |
| hugh |
| hull |
| hum |
| human |
| humanity |
| humble |
| humdrum |
| humid |
| humility |
| humming |
| humor |
| humour |
| hundred |
| hundreds |
| hundredth |
| hung |
| hungary |
| hunger |
| hungry |
| hunted |
| hunter |
| hunting |
| hurled |
| hurricane |
| hurried |
| hurriedly |
| hurries |
| hurry |
| hurrying |
| hurt |
| husband |
| husbands |
| hush |
| hushed |
| hut |
| hybrid |
| hyde |
| hymn |
| hymns |
| hypothesis |
| hysterical |
| ib |
| ibid |
| ibidus |
| ice |
| icy |
| idea |
| ideal |
| ideas |
| identical |
| identification |
| identified |
| identify |
| identity |
| idiosyncrasy |
| idiotic |
| idle |
| idleness |
| idly |
| idol |
| idols |
| idris |
| if |
| ignorance |
| ignorant |
| il |
| ilarnek |
| ill |
| illimitable |
| illness |
| illnesses |
| ills |
| illuminated |
| illumined |
| illusion |
| illusions |
| illustrated |
| illustrious |
| image |
| imaged |
| imagery |
| images |
| imaginary |
| imagination |
| imaginations |
| imaginative |
| imagine |
| imagined |
| imagining |
| imaginings |
| imbibed |
| imbued |
| imitate |
| imitation |
| immature |
| immeasurable |
| immeasurably |
| immediate |
| immediately |
| immemorial |
| immense |
| immersed |
| immortal |
| immortality |
| immutable |
| impart |
| impassioned |
| impatience |
| impatient |
| impatiently |
| impeded |
| impediment |
| impediments |
| impelled |
| impels |
| impending |
| impenetrable |
| imperatively |
| imperceptible |
| imperceptibly |
| imperfect |
| imperial |
| imperious |
| imperiously |
| impersonal |
| impertinence |
| impertinent |
| impetuosity |
| impetuous |
| impetuously |
| impious |
| implements |
| implicated |
| implications |
| implicit |
| implicitly |
| implied |
| imply |
| import |
| importance |
| important |
| imposed |
| imposing |
| impossibility |
| impossible |
| impotent |
| impracticable |
| impress |
| impressed |
| impression |
| impressions |
| impressive |
| imprisoned |
| imprisonment |
| improbable |
| improve |
| improved |
| improvement |
| improvements |
| imprudence |
| impulse |
| impulses |
| impunity |
| in |
| inability |
| inaccessible |
| inaction |
| inadequate |
| inanimate |
| incalculable |
| incantation |
| incantations |
| incapable |
| incarnate |
| incense |
| incessantly |
| inch |
| inches |
| incident |
| incidents |
| incinerator |
| inclemency |
| inclination |
| inclinations |
| inclined |
| include |
| included |
| includes |
| including |
| incoherent |
| income |
| incomprehensible |
| inconceivable |
| incongruities |
| inconsiderable |
| inconstant |
| inconvenience |
| inconvenient |
| increase |
| increased |
| increases |
| increasing |
| increasingly |
| incredible |
| incredibly |
| incumbent |
| incurred |
| indebted |
| indecent |
| indeed |
| indefinable |
| indefinite |
| indefinitely |
| independence |
| independent |
| indescribable |
| indeterminate |
| india |
| indian |
| indians |
| indicate |
| indicated |
| indicating |
| indication |
| indications |
| indifference |
| indifferent |
| indignant |
| indignation |
| indispensable |
| indistinct |
| indistinctly |
| individual |
| individuals |
| induce |
| induced |
| indulge |
| indulged |
| indulgence |
| industry |
| ineffable |
| ineffectual |
| inevitable |
| inevitably |
| inexhaustible |
| inexperience |
| inexplicable |
| inexplicably |
| inexpressible |
| inexpressibly |
| inextricably |
| infallible |
| infamy |
| infancy |
| infant |
| infected |
| infection |
| inference |
| inferior |
| inferred |
| infested |
| infinite |
| infinitely |
| infinity |
| infirm |
| infirmity |
| inflamed |
| inflation |
| inflexible |
| inflict |
| inflicted |
| influence |
| influenced |
| influences |
| inform |
| information |
| informed |
| informs |
| ingenious |
| ingenuity |
| ingolstadt |
| ingratitude |
| ingress |
| inhabit |
| inhabitant |
| inhabitants |
| inhabited |
| inheritance |
| inherited |
| inhuman |
| inimitable |
| injected |
| injunction |
| injured |
| injuries |
| injury |
| injustice |
| ink |
| inky |
| inland |
| inmate |
| inmost |
| inn |
| inner |
| innermost |
| innocence |
| innocent |
| innsmouth |
| innumerable |
| inorganic |
| inquire |
| inquired |
| inquiries |
| inquiring |
| inquiry |
| inquisition |
| inquisitive |
| inroads |
| insane |
| insanity |
| insatiate |
| inscribed |
| inscription |
| insect |
| insects |
| insensibility |
| insensible |
| insert |
| inserted |
| inside |
| insidious |
| insight |
| insinuate |
| insist |
| insisted |
| insistent |
| insisting |
| insists |
| inspecting |
| inspection |
| inspector |
| inspiration |
| inspire |
| inspired |
| instance |
| instances |
| instant |
| instantaneous |
| instantaneously |
| instantly |
| instead |
| instigated |
| instinct |
| instinctive |
| instinctively |
| institute |
| instituted |
| institution |
| institutions |
| instruct |
| instructed |
| instruction |
| instructions |
| instrument |
| instruments |
| insufferable |
| insufficient |
| insulated |
| insult |
| insulted |
| insurance |
| insurmountable |
| intact |
| intangible |
| integrity |
| intellect |
| intellectual |
| intelligence |
| intelligent |
| intelligible |
| intend |
| intended |
| intense |
| intensely |
| intensified |
| intensity |
| intent |
| intention |
| intentions |
| intently |
| interchange |
| intercourse |
| interest |
| interested |
| interesting |
| interests |
| interfere |
| interference |
| interior |
| interment |
| interments |
| interminable |
| intermingled |
| internal |
| interposed |
| interpret |
| interpretation |
| interred |
| interrupt |
| interrupted |
| interruption |
| interspersed |
| interval |
| intervals |
| intervene |
| intervened |
| intervening |
| intervention |
| interview |
| intimacy |
| intimate |
| intimated |
| into |
| intolerable |
| intolerably |
| intonation |
| intoxicating |
| intoxication |
| intricate |
| intrigues |
| introduce |
| introduced |
| introducing |
| introduction |
| intrude |
| intruder |
| intrusion |
| intuition |
| invaded |
| invaders |
| invalid |
| invariably |
| invented |
| invention |
| invested |
| investigation |
| investigations |
| investigators |
| invincible |
| invisible |
| invited |
| involuntarily |
| involuntary |
| involve |
| involved |
| involving |
| inward |
| ionic |
| ipswich |
| iranon |
| ireland |
| iridescent |
| irish |
| irksome |
| iron |
| irony |
| irregular |
| irregularity |
| irrelevant |
| irreparable |
| irresistible |
| is |
| ish |
| island |
| islanders |
| islands |
| isle |
| islet |
| isolated |
| isolation |
| issue |
| issued |
| issuing |
| it |
| italian |
| italy |
| item |
| items |
| its |
| itself |
| ivied |
| ivory |
| ivy |
| iz |
| iä |
| jacket |
| jade |
| jan |
| january |
| jarring |
| java |
| jaw |
| jaws |
| je |
| jealous |
| jealousy |
| jelly |
| jenkin |
| jermyn |
| jest |
| jetty |
| jewellery |
| jewels |
| joe |
| johansen |
| john |
| johnson |
| join |
| joined |
| joint |
| joints |
| joke |
| journal |
| journey |
| journied |
| joy |
| joyeuse |
| joyful |
| joyous |
| joys |
| juan |
| judge |
| judged |
| judges |
| judgment |
| july |
| jumble |
| jump |
| jumped |
| junction |
| juncture |
| june |
| jung |
| jungle |
| jup |
| jupiter |
| jura |
| just |
| justice |
| justified |
| justine |
| justly |
| jxhn |
| kadath |
| kadatheron |
| kaleidoscopic |
| kalends |
| kalos |
| kanakys |
| kate |
| keel |
| keen |
| keener |
| keenest |
| keep |
| keeper |
| keepers |
| keeping |
| keeps |
| keer |
| keg |
| kempelen |
| kept |
| key |
| keys |
| keziah |
| kick |
| kickapoo |
| kicked |
| kid |
| kidd |
| kilderry |
| kill |
| killed |
| killing |
| kilt |
| kin |
| kind |
| kinder |
| kindled |
| kindly |
| kindness |
| kinds |
| king |
| kingdom |
| kings |
| kingsport |
| kinship |
| kirwin |
| kishan |
| kiss |
| kissam |
| kissed |
| kitchen |
| kitten |
| kittens |
| kla |
| klenze |
| knee |
| knees |
| knelt |
| knew |
| knife |
| knit |
| knobs |
| knock |
| knocked |
| knocker |
| knocking |
| knot |
| know |
| knowed |
| knowing |
| knowledge |
| known |
| knows |
| knxw |
| krempe |
| kuranes |
| la |
| labor |
| laboratory |
| laboring |
| laborious |
| labors |
| labour |
| laboured |
| labourers |
| labours |
| labyrinth |
| labyrinths |
| lace |
| lacey |
| lack |
| lacked |
| lacking |
| ladder |
| ladders |
| laden |
| ladies |
| lady |
| lafayette |
| lafitte |
| laid |
| lain |
| lair |
| lake |
| lakes |
| lalande |
| lament |
| lamented |
| lamp |
| lamps |
| land |
| landed |
| landing |
| landlady |
| landlord |
| lands |
| landscape |
| lane |
| lanes |
| language |
| languages |
| languid |
| languidly |
| languor |
| lantern |
| lanterns |
| lap |
| lapping |
| lapse |
| lapsed |
| large |
| largely |
| larger |
| largest |
| lashes |
| last |
| lasted |
| lasting |
| lastly |
| latch |
| late |
| lately |
| latent |
| later |
| lateral |
| latest |
| latin |
| latitude |
| latter |
| lattice |
| laudable |
| laugh |
| laughed |
| laughing |
| laughter |
| lavinia |
| lavished |
| law |
| lawless |
| lawn |
| lawrence |
| laws |
| lay |
| laying |
| le |
| lead |
| leaden |
| leader |
| leaders |
| leading |
| leads |
| leaf |
| league |
| leagues |
| lean |
| leaned |
| leaning |
| leap |
| leaped |
| leaping |
| leapt |
| learn |
| learned |
| learning |
| learnt |
| lease |
| least |
| leather |
| leave |
| leaves |
| leaving |
| led |
| lee |
| leeds |
| leered |
| leering |
| leetle |
| lef |
| left |
| leg |
| legend |
| legends |
| leghorn |
| legion |
| legions |
| legitimate |
| legrand |
| legrasse |
| legs |
| leisure |
| length |
| lenses |
| lent |
| les |
| less |
| lessened |
| lesser |
| lesson |
| lessons |
| lest |
| let |
| lethal |
| letter |
| lettered |
| letters |
| letting |
| lettres |
| level |
| levels |
| liable |
| liberal |
| liberty |
| libo |
| library |
| license |
| lid |
| lids |
| lie |
| lies |
| lieutenant |
| life |
| lifeless |
| lifetime |
| lift |
| lifted |
| ligeia |
| light |
| lighted |
| lighten |
| lightened |
| lighter |
| lighting |
| lightly |
| lightness |
| lightning |
| lightnings |
| lights |
| like |
| liked |
| likely |
| likeness |
| likewise |
| lilies |
| lily |
| limb |
| limbs |
| limit |
| limited |
| limitless |
| limits |
| line |
| lineaments |
| lined |
| linen |
| liner |
| lines |
| linger |
| lingered |
| lingering |
| link |
| linkage |
| linked |
| links |
| lion |
| lionel |
| lions |
| lip |
| lips |
| liquid |
| liquor |
| list |
| listen |
| listened |
| listener |
| listeners |
| listening |
| listless |
| lit |
| literal |
| literally |
| literary |
| literature |
| litten |
| little |
| live |
| lived |
| lively |
| lives |
| livid |
| living |
| lizard |
| ll |
| lo |
| load |
| loaded |
| loaf |
| loathed |
| loathing |
| loathsome |
| lobby |
| local |
| locality |
| location |
| loch |
| lock |
| locked |
| locks |
| lodge |
| lodged |
| lodgers |
| lofoden |
| loft |
| lofty |
| logic |
| logical |
| logs |
| lollipop |
| lomar |
| london |
| lone |
| lonely |
| long |
| longed |
| longer |
| longest |
| longing |
| look |
| looked |
| looking |
| looks |
| loomed |
| loops |
| loose |
| loosened |
| lord |
| lords |
| lore |
| lose |
| loser |
| loses |
| losing |
| loss |
| losses |
| lost |
| lot |
| lotos |
| lots |
| loud |
| louder |
| loudly |
| louis |
| loungers |
| love |
| loved |
| loveliest |
| loveliness |
| lovely |
| lover |
| lovers |
| loves |
| loving |
| low |
| lower |
| lowered |
| lowest |
| lowly |
| lozenge |
| luck |
| luckily |
| lulled |
| lulling |
| luminosity |
| luminous |
| lunacy |
| lunar |
| lunatic |
| lunatics |
| lunch |
| lungs |
| lurid |
| lurked |
| lurking |
| lustre |
| lutes |
| luther |
| luxuriance |
| luxuriant |
| luxuries |
| luxurious |
| luxury |
| lyeh |
| lying |
| ma |
| macedonia |
| machine |
| machinery |
| machines |
| mad |
| madam |
| madame |
| maddening |
| made |
| madeline |
| mademoiselle |
| madhouse |
| madly |
| madman |
| madmen |
| madness |
| maelzel |
| magazine |
| magic |
| magical |
| magician |
| magistrate |
| magnet |
| magnetic |
| magnificence |
| magnificent |
| magnitude |
| magnus |
| maid |
| maiden |
| maillard |
| main |
| mainly |
| maintain |
| maintained |
| maintaining |
| maintains |
| majestic |
| majesty |
| major |
| majority |
| make |
| maker |
| makes |
| making |
| malady |
| male |
| malevolence |
| malice |
| malign |
| malignancy |
| malignant |
| malignity |
| malodorous |
| man |
| manage |
| managed |
| mangled |
| manhood |
| mania |
| maniac |
| manifest |
| manifestation |
| manifestations |
| manifested |
| manifold |
| mankind |
| manly |
| manner |
| manners |
| manoeuvre |
| manor |
| mansion |
| mansions |
| mantel |
| manton |
| manuscript |
| manuscripts |
| manuxet |
| many |
| map |
| maple |
| maps |
| marble |
| march |
| marched |
| marchesa |
| mare |
| margaret |
| margin |
| marie |
| marine |
| mariner |
| mark |
| marked |
| market |
| marks |
| marriage |
| married |
| marrow |
| marry |
| marsh |
| marshes |
| marshy |
| martense |
| martenses |
| martha |
| marvel |
| marvelled |
| marvellous |
| marvellously |
| marvels |
| mary |
| mask |
| mason |
| masonry |
| masquerade |
| mass |
| massa |
| massacre |
| masse |
| masses |
| massive |
| massy |
| mast |
| master |
| mastered |
| masters |
| masts |
| match |
| matchless |
| mate |
| material |
| materially |
| materials |
| maternal |
| mathematical |
| mathematician |
| mathematics |
| mather |
| mathilda |
| matt |
| matted |
| matter |
| matters |
| matured |
| maturity |
| may |
| maybe |
| mazes |
| mazurewicz |
| me |
| meadow |
| meadows |
| meal |
| mean |
| meaning |
| meaningless |
| means |
| meant |
| meantime |
| meanwhile |
| measure |
| measured |
| measures |
| meat |
| mebbe |
| mechanical |
| mechanism |
| medical |
| medicine |
| meditate |
| meditation |
| meditations |
| mediterranean |
| medium |
| meerschaum |
| meet |
| meeting |
| meetings |
| meets |
| mein |
| melancholy |
| melodious |
| melody |
| melted |
| mem |
| member |
| members |
| memorable |
| memories |
| memory |
| men |
| menace |
| menaced |
| menacing |
| menes |
| menial |
| mental |
| mentally |
| mention |
| mentioned |
| mentioning |
| mentoni |
| merchant |
| merchants |
| merciful |
| merciless |
| mercy |
| mere |
| merely |
| merest |
| merge |
| merged |
| merit |
| merits |
| merriment |
| merrival |
| merry |
| mesmeric |
| message |
| messages |
| messenger |
| messengers |
| messrs |
| met |
| metal |
| metallic |
| metaphysical |
| metaphysics |
| methinks |
| method |
| methodical |
| methods |
| methought |
| metropolis |
| metzengerstein |
| mexican |
| michel |
| microscope |
| mid |
| middle |
| midnight |
| midst |
| midway |
| mien |
| might |
| mightier |
| mighty |
| mignaud |
| mild |
| mildew |
| mildewed |
| mile |
| miles |
| military |
| milk |
| milky |
| mill |
| mille |
| million |
| millions |
| mills |
| minarets |
| mind |
| minded |
| minds |
| mine |
| mineral |
| mingle |
| mingled |
| mingling |
| miniature |
| minister |
| ministers |
| minor |
| minute |
| minutely |
| minuteness |
| minutes |
| minutest |
| miracle |
| miracles |
| miraculous |
| miranda |
| mirror |
| mirrors |
| mirth |
| mis |
| miscellaneous |
| mischief |
| miserable |
| miserably |
| miseries |
| misery |
| misfortune |
| misfortunes |
| miskatonic |
| misled |
| miss |
| missed |
| missing |
| mist |
| mistake |
| mistaken |
| mistakes |
| mistress |
| mists |
| misty |
| mixed |
| mixture |
| mnar |
| moan |
| moaning |
| mob |
| mock |
| mocked |
| mockery |
| mocking |
| mockingly |
| mode |
| model |
| moderate |
| moderately |
| modern |
| modes |
| modest |
| modesty |
| modification |
| modifications |
| modified |
| modify |
| modulated |
| moissart |
| moist |
| moisture |
| mole |
| moment |
| momentarily |
| momentary |
| momently |
| momentous |
| moments |
| mon |
| monarch |
| monday |
| money |
| moneypenny |
| mongrels |
| monkey |
| monolith |
| monoliths |
| monotonous |
| monotonously |
| monotony |
| monsieur |
| monster |
| monsters |
| monstrosities |
| monstrosity |
| monstrous |
| mont |
| month |
| monthly |
| months |
| monument |
| mood |
| moods |
| moody |
| moon |
| moonlight |
| moonlit |
| moor |
| moral |
| morals |
| morass |
| morbid |
| morbidity |
| morbidly |
| more |
| moreland |
| morella |
| moreover |
| morgan |
| morgue |
| moritz |
| mornin |
| morning |
| morrow |
| mortal |
| mortality |
| mortals |
| mortification |
| mos |
| moskoe |
| moss |
| mossy |
| most |
| mostly |
| mother |
| mothers |
| motion |
| motioned |
| motionless |
| motions |
| motive |
| motives |
| motley |
| motor |
| mould |
| moulded |
| moulding |
| mouldy |
| mound |
| mounds |
| mount |
| mountain |
| mountainous |
| mountains |
| mounted |
| mounting |
| mourn |
| mourners |
| mournful |
| mournfully |
| mourning |
| mouth |
| mouths |
| move |
| moved |
| movement |
| movements |
| moves |
| moving |
| mr |
| mrs |
| ms |
| much |
| mud |
| muddy |
| muffled |
| multiform |
| multiplied |
| multiply |
| multitude |
| multitudinous |
| mumbled |
| munroe |
| murder |
| murdered |
| murderer |
| murderers |
| murderous |
| murders |
| murky |
| murmur |
| murmured |
| murmuring |
| murmurs |
| mus |
| muscles |
| muscular |
| muse |
| museum |
| music |
| musical |
| musician |
| musides |
| musing |
| musingly |
| muskets |
| muslin |
| must |
| muster |
| mustiness |
| musty |
| mute |
| mutiny |
| mutter |
| muttered |
| muttering |
| mutual |
| muñoz |
| mwanu |
| my |
| mynheer |
| myriad |
| myself |
| mysteries |
| mysterious |
| mystery |
| mystic |
| mystical |
| mystification |
| myth |
| myths |
| müller |
| nail |
| nails |
| naked |
| name |
| named |
| nameless |
| names |
| namesake |
| naow |
| naples |
| napoleon |
| nargai |
| narrated |
| narration |
| narrative |
| narrow |
| narrowly |
| nassau |
| nasty |
| nation |
| national |
| nations |
| native |
| natives |
| natural |
| naturally |
| nature |
| natures |
| naught |
| nauseous |
| naval |
| navigators |
| nay |
| ncey |
| nd |
| ne |
| near |
| nearby |
| nearer |
| nearest |
| nearly |
| neat |
| neatly |
| nebulous |
| necessarily |
| necessary |
| necessity |
| neck |
| necks |
| necronomicon |
| need |
| needed |
| needle |
| needless |
| needs |
| negative |
| neglect |
| neglected |
| negro |
| negroes |
| neighbor |
| neighborhood |
| neighboring |
| neighbors |
| neighbour |
| neighbourhood |
| neighbouring |
| neighbours |
| neither |
| nerve |
| nerves |
| nervous |
| nervously |
| nest |
| nestling |
| net |
| nether |
| never |
| nevertheless |
| new |
| newburyport |
| newcomer |
| newer |
| newly |
| news |
| newspaper |
| newspapers |
| next |
| nice |
| niche |
| niece |
| nigh |
| night |
| nighted |
| nightingale |
| nightly |
| nightmare |
| nightmares |
| nights |
| nine |
| nineteenth |
| ninety |
| ninth |
| nithra |
| nitre |
| nitrogen |
| nitrous |
| no |
| nobility |
| noble |
| nobleman |
| nobles |
| noblest |
| nobody |
| nocturnal |
| nod |
| nodded |
| noise |
| noises |
| noisome |
| noisy |
| nom |
| non |
| nonchalance |
| nondescript |
| none |
| nook |
| noon |
| noonday |
| nopolis |
| nor |
| normal |
| north |
| northeast |
| northerly |
| northern |
| northward |
| northwest |
| norwegian |
| nose |
| noses |
| nosology |
| nostrils |
| not |
| notable |
| note |
| noted |
| notes |
| nothin |
| nothing |
| nothingness |
| notice |
| noticeable |
| noticed |
| notices |
| noticing |
| notion |
| notions |
| notoriety |
| notorious |
| notwithstanding |
| nought |
| nourished |
| novel |
| novelty |
| november |
| now |
| nowhere |
| noxious |
| nt |
| nucleus |
| number |
| numbered |
| numbers |
| numerous |
| nurse |
| nursed |
| nurses |
| nursling |
| nurtured |
| nuts |
| nx |
| nyarlathotep |
| nyl |
| oak |
| oaken |
| oaks |
| oar |
| oars |
| oarsmen |
| oath |
| oaths |
| ob |
| obed |
| obedience |
| obedient |
| obey |
| obeyed |
| obeying |
| object |
| objection |
| objective |
| objects |
| obligation |
| obliged |
| obliterated |
| oblivion |
| oblong |
| obscure |
| obscured |
| obscurely |
| obscurity |
| observable |
| observation |
| observations |
| observe |
| observed |
| observer |
| observing |
| obstacle |
| obstacles |
| obstinacy |
| obstinate |
| obstruction |
| obtain |
| obtained |
| obtaining |
| obtuse |
| obvious |
| obviously |
| occasion |
| occasional |
| occasionally |
| occasioned |
| occasions |
| occupant |
| occupation |
| occupations |
| occupied |
| occupy |
| occupying |
| occur |
| occurred |
| occurrence |
| occurrences |
| occurring |
| occurs |
| ocean |
| october |
| odd |
| oddities |
| oddly |
| odious |
| odor |
| odorous |
| odour |
| odours |
| of |
| off |
| offence |
| offended |
| offensive |
| offer |
| offered |
| offering |
| offers |
| office |
| officer |
| officers |
| offices |
| offspring |
| often |
| oftener |
| oh |
| oil |
| oinos |
| ol |
| old |
| olden |
| older |
| oldest |
| olive |
| olney |
| omelette |
| omen |
| ominous |
| omnipotent |
| on |
| once |
| onct |
| one |
| ones |
| only |
| onward |
| onwards |
| oonai |
| ooth |
| ooze |
| open |
| opened |
| opening |
| openly |
| opens |
| opera |
| operated |
| operating |
| operation |
| operations |
| opiate |
| opinion |
| opinions |
| opium |
| oppodeldoc |
| opponent |
| opportunities |
| opportunity |
| oppose |
| opposed |
| opposing |
| opposite |
| opposition |
| oppressed |
| oppression |
| oppressive |
| oppressor |
| or |
| orange |
| orb |
| orbit |
| orbs |
| order |
| ordered |
| orders |
| ordinarily |
| ordinary |
| organ |
| organic |
| organised |
| organism |
| organization |
| organs |
| oriental |
| origin |
| original |
| originally |
| orion |
| ornament |
| ornamented |
| ornaments |
| ornate |
| orne |
| orphan |
| osborn |
| osborne |
| other |
| others |
| otherwise |
| ottoman |
| ought |
| our |
| ourang |
| ours |
| ourselves |
| out |
| outang |
| outcast |
| outer |
| outfit |
| outline |
| outlines |
| outrage |
| outside |
| outspread |
| outstretched |
| outward |
| outwardly |
| oval |
| oven |
| over |
| overboard |
| overcame |
| overcoat |
| overcome |
| overflowing |
| overgrown |
| overhanging |
| overhead |
| overheard |
| overhung |
| overlooked |
| overlooking |
| overpowered |
| overshadowed |
| oversight |
| overspread |
| overthrow |
| overwhelmed |
| overwhelming |
| owe |
| owed |
| owing |
| owl |
| own |
| owned |
| owner |
| owners |
| oxford |
| oxygen |
| pa |
| pace |
| paced |
| paces |
| pacific |
| pacing |
| packed |
| packet |
| page |
| pages |
| paid |
| pain |
| paine |
| painful |
| painfully |
| pains |
| paint |
| painted |
| painter |
| painting |
| paintings |
| pair |
| palace |
| palaces |
| palazzo |
| pale |
| pall |
| pallid |
| pallor |
| palm |
| palpable |
| palpably |
| paltry |
| pamphlet |
| pan |
| pandemonium |
| paned |
| panelling |
| panes |
| pang |
| pangs |
| panic |
| panorama |
| panted |
| panting |
| papa |
| paper |
| papers |
| papyrus |
| par |
| paracelsus |
| paradise |
| paradox |
| paragraph |
| paragraphs |
| parallel |
| paralysed |
| paralysis |
| paramount |
| parchment |
| pardon |
| pardoned |
| pardons |
| parent |
| parents |
| paris |
| parisian |
| park |
| parks |
| parliament |
| parlor |
| part |
| parte |
| parted |
| parti |
| partial |
| partiality |
| partially |
| participate |
| particle |
| particles |
| particular |
| particularly |
| particulars |
| parties |
| parting |
| partition |
| partitions |
| partizans |
| partly |
| partner |
| partook |
| parts |
| party |
| pas |
| pass |
| passage |
| passages |
| passageway |
| passed |
| passengers |
| passes |
| passing |
| passion |
| passionate |
| passionately |
| passions |
| passive |
| past |
| pastor |
| patches |
| paternal |
| path |
| pathetic |
| pathless |
| paths |
| pathway |
| patience |
| patient |
| patiently |
| patients |
| patriotic |
| patron |
| pattering |
| pattern |
| patterns |
| paul |
| pause |
| paused |
| pausing |
| paved |
| pavement |
| pavée |
| paw |
| paws |
| pay |
| paying |
| payment |
| pe |
| peace |
| peaceful |
| peak |
| peaked |
| peaks |
| peal |
| pearl |
| peasant |
| peasantry |
| peasants |
| pebbles |
| peck |
| peculiar |
| peculiarities |
| peculiarity |
| peculiarly |
| pecuniary |
| peep |
| peer |
| peered |
| peering |
| peers |
| peg |
| pen |
| pencil |
| pendulous |
| pendulum |
| penetrate |
| penetrated |
| penetrating |
| penned |
| penny |
| penury |
| people |
| peopled |
| per |
| perceive |
| perceived |
| perceiving |
| perceptible |
| perceptibly |
| perception |
| perceptions |
| perched |
| perdita |
| perfect |
| perfection |
| perfectly |
| perform |
| performance |
| performed |
| performers |
| performing |
| perfume |
| perfumed |
| perfumery |
| perhaps |
| peril |
| perilous |
| perilously |
| period |
| periodical |
| periodically |
| periods |
| perish |
| perished |
| permanent |
| permanently |
| permeates |
| permission |
| permit |
| permits |
| permitted |
| permitting |
| perpendicular |
| perpendicularly |
| perpetual |
| perpetually |
| perplexed |
| perplexing |
| perseverance |
| persia |
| persist |
| persisted |
| persistent |
| person |
| personage |
| personal |
| personally |
| persons |
| perspective |
| perspiration |
| persuade |
| persuaded |
| persuading |
| persuasion |
| perth |
| pertinaciously |
| pertinacity |
| perturbed |
| perusal |
| perused |
| pervaded |
| pervades |
| pervading |
| perverse |
| perverseness |
| perversion |
| perversity |
| pest |
| pestilence |
| pestilential |
| pet |
| peter |
| petticoat |
| petticoats |
| petty |
| pfaall |
| phantasm |
| phantasmal |
| phantasms |
| phantasy |
| phantom |
| phases |
| phenomena |
| phenomenon |
| philadelphia |
| philosopher |
| philosophers |
| philosophic |
| philosophical |
| philosophy |
| phosphorescence |
| phosphorescent |
| photograph |
| phrase |
| phraseology |
| phrases |
| physical |
| physically |
| physician |
| physicians |
| physics |
| physiognomy |
| physique |
| piano |
| pick |
| picked |
| picking |
| pickman |
| pictorial |
| picture |
| pictured |
| pictures |
| picturesque |
| piece |
| pieces |
| pierced |
| piercing |
| pierre |
| pig |
| pigs |
| pile |
| piled |
| piles |
| pilgrimage |
| pillar |
| pillared |
| pillars |
| pillow |
| pilot |
| pinch |
| pine |
| pines |
| pinions |
| pink |
| pinnacle |
| pinnacles |
| pious |
| piously |
| pipe |
| pipes |
| piping |
| piquant |
| pirate |
| pirouette |
| pistol |
| pistols |
| pit |
| pitch |
| pitched |
| pitcher |
| pitchy |
| pitiable |
| pitied |
| pitiful |
| pitiless |
| pits |
| pity |
| place |
| placed |
| places |
| placid |
| placing |
| plague |
| plain |
| plainly |
| plains |
| plan |
| plane |
| planet |
| planets |
| plank |
| planks |
| planned |
| plans |
| plant |
| planted |
| plants |
| plaster |
| plate |
| plateau |
| platform |
| plausible |
| play |
| played |
| player |
| players |
| playful |
| playing |
| playmate |
| plays |
| plaything |
| pleasant |
| pleasantly |
| please |
| pleased |
| pleasing |
| pleasurable |
| pleasure |
| pleasures |
| pledge |
| plentiful |
| plenty |
| plot |
| plum |
| plumes |
| plunge |
| plunged |
| plunging |
| pluto |
| pnakotic |
| pockets |
| poem |
| poems |
| poet |
| poetic |
| poetical |
| poetry |
| poets |
| poignant |
| poignantly |
| point |
| pointed |
| pointing |
| points |
| poison |
| poisoned |
| poisonous |
| pole |
| poles |
| police |
| policemen |
| policy |
| polished |
| political |
| politics |
| polyhedron |
| pomp |
| pompelo |
| pompey |
| pompous |
| pon |
| pond |
| ponder |
| pondered |
| pondering |
| ponderous |
| poodle |
| pool |
| poor |
| pope |
| populace |
| popular |
| popularity |
| population |
| populous |
| pored |
| poring |
| port |
| portable |
| portal |
| portentous |
| portion |
| portions |
| portrait |
| ports |
| portuguese |
| pose |
| position |
| positions |
| positive |
| positively |
| possess |
| possessed |
| possesses |
| possession |
| possessions |
| possessor |
| possibilities |
| possibility |
| possible |
| possibly |
| post |
| posterity |
| posts |
| posture |
| pot |
| potency |
| potent |
| pots |
| potter |
| pounds |
| pour |
| poured |
| pouring |
| poverty |
| powder |
| power |
| powerful |
| powers |
| practical |
| practice |
| practised |
| prairie |
| praise |
| praised |
| praises |
| pratt |
| pray |
| prayed |
| prayer |
| prayers |
| praying |
| pre |
| precaution |
| precautions |
| preceded |
| preceding |
| precincts |
| precious |
| precipice |
| precipices |
| precipitate |
| precipitated |
| precipitous |
| precise |
| precisely |
| precision |
| preconceived |
| predecessors |
| predicament |
| predominant |
| prefect |
| prefer |
| preferred |
| pregnant |
| prehistoric |
| prejudice |
| prejudices |
| preliminary |
| premature |
| premises |
| preparation |
| preparations |
| prepare |
| prepared |
| preparing |
| preposterous |
| presburg |
| presence |
| present |
| presented |
| presentiment |
| presenting |
| presently |
| presents |
| preservation |
| preserve |
| preserved |
| preserving |
| president |
| press |
| pressed |
| pressing |
| pressure |
| presumably |
| presume |
| presumption |
| presumptuous |
| pretence |
| pretend |
| pretended |
| pretensions |
| preternatural |
| pretty |
| prevailed |
| prevalence |
| prevalent |
| prevent |
| prevented |
| preventing |
| prevention |
| previous |
| previously |
| prey |
| preyed |
| price |
| pride |
| priest |
| priests |
| primal |
| primary |
| prime |
| primitive |
| prince |
| princely |
| princes |
| princess |
| principal |
| principally |
| principle |
| principles |
| printed |
| prints |
| prior |
| priori |
| prison |
| prisoner |
| prisoners |
| pristine |
| privacy |
| private |
| privilege |
| prize |
| prized |
| probabilities |
| probability |
| probable |
| probably |
| problem |
| proboscis |
| proceed |
| proceeded |
| proceeding |
| proceedings |
| proceeds |
| process |
| processes |
| procession |
| proconsul |
| procure |
| procured |
| prodigies |
| prodigious |
| produce |
| produced |
| producing |
| productions |
| professed |
| profession |
| professional |
| professor |
| professors |
| profit |
| profound |
| profoundly |
| profundity |
| profuse |
| profusion |
| prognostications |
| progress |
| progression |
| progressive |
| project |
| projected |
| projecting |
| projects |
| prolong |
| prolonged |
| promenade |
| prominent |
| promise |
| promised |
| promises |
| prompted |
| prone |
| pronounce |
| pronounced |
| pronouncing |
| proof |
| propeller |
| propelling |
| propensities |
| propensity |
| proper |
| properly |
| properties |
| property |
| prophecy |
| prophet |
| proportion |
| proportioned |
| proportions |
| proposals |
| propose |
| proposed |
| proposition |
| propped |
| proprietor |
| propriety |
| prosaic |
| prose |
| prospect |
| prospects |
| prosperity |
| prosperous |
| prostrate |
| prosy |
| protect |
| protected |
| protection |
| protector |
| protectorate |
| protectors |
| protectorship |
| protracted |
| protruded |
| protruding |
| protuberance |
| proud |
| proudly |
| prove |
| proved |
| proves |
| provide |
| provided |
| providence |
| province |
| provinces |
| provision |
| provisions |
| provoked |
| proximity |
| prudence |
| prudent |
| prussian |
| psyche |
| psychology |
| public |
| publication |
| publicly |
| published |
| puff |
| puffed |
| puffy |
| pull |
| pulled |
| pulling |
| pulpit |
| pulse |
| pump |
| puncheon |
| pundit |
| pungent |
| punish |
| punished |
| punishment |
| pupil |
| pupils |
| puppy |
| purchase |
| pure |
| purely |
| puritan |
| purity |
| purple |
| purpose |
| purposes |
| purse |
| pursuance |
| pursue |
| pursued |
| pursuer |
| pursuers |
| pursuing |
| pursuit |
| pursuits |
| push |
| pushed |
| pushing |
| put |
| puts |
| putting |
| puzzled |
| puzzling |
| pyramid |
| quaint |
| qualities |
| quality |
| quantity |
| quarrel |
| quarter |
| quarters |
| quasi |
| que |
| queen |
| queer |
| queerest |
| queerly |
| quenched |
| query |
| quest |
| question |
| questioned |
| questioning |
| questions |
| qui |
| quick |
| quicker |
| quickly |
| quiet |
| quietly |
| quit |
| quite |
| quitted |
| quitting |
| quivered |
| quivering |
| quote |
| quoted |
| rabbit |
| rabbits |
| rabble |
| race |
| rack |
| racked |
| radiance |
| radiant |
| radical |
| radically |
| rag |
| rage |
| raged |
| ragged |
| raging |
| rags |
| railed |
| railing |
| rails |
| railway |
| rain |
| rainbow |
| rains |
| rainy |
| raise |
| raised |
| raising |
| ram |
| ramble |
| rambled |
| rambles |
| rambling |
| ramparts |
| ran |
| randolph |
| random |
| rang |
| range |
| rank |
| ranks |
| rant |
| raound |
| rapid |
| rapidity |
| rapidly |
| raps |
| rapture |
| rapturous |
| rare |
| rarely |
| rarest |
| rash |
| rashness |
| rat |
| rate |
| rather |
| ratio |
| rational |
| rats |
| rattle |
| rattled |
| rattling |
| ravages |
| raved |
| raven |
| ravine |
| ravines |
| raving |
| ravings |
| raw |
| ray |
| raymond |
| rays |
| razor |
| re |
| reach |
| reached |
| reaches |
| reaching |
| reaction |
| read |
| reader |
| readers |
| readily |
| readiness |
| reading |
| ready |
| real |
| realise |
| realised |
| realities |
| reality |
| realized |
| really |
| realm |
| realms |
| reanimated |
| reanimation |
| reap |
| rear |
| reared |
| reason |
| reasonable |
| reasoned |
| reasoner |
| reasoning |
| reasons |
| reassured |
| recall |
| recalled |
| recalling |
| recalls |
| receded |
| receding |
| receipt |
| receive |
| received |
| receiving |
| recent |
| reception |
| recess |
| recesses |
| reckless |
| reckoning |
| recognise |
| recognised |
| recognising |
| recognition |
| recognize |
| recognized |
| recognizing |
| recollect |
| recollected |
| recollection |
| recollections |
| recommended |
| reconcile |
| record |
| recorded |
| records |
| recourse |
| recover |
| recovered |
| recovering |
| recovery |
| rectangular |
| recur |
| recurred |
| red |
| redeem |
| redolent |
| redoubled |
| reduced |
| reef |
| reeking |
| reel |
| reeled |
| reeling |
| refer |
| reference |
| references |
| referred |
| referring |
| refined |
| refinement |
| refinery |
| reflect |
| reflected |
| reflecting |
| reflection |
| reflections |
| refrain |
| refreshed |
| refuge |
| refusal |
| refuse |
| refused |
| refusing |
| regained |
| regal |
| regard |
| regarded |
| regarding |
| regardless |
| regards |
| regiment |
| region |
| regions |
| regret |
| regrets |
| regretted |
| regular |
| regularity |
| regularly |
| regulated |
| reid |
| reign |
| reigned |
| reigning |
| reigns |
| reins |
| reject |
| rejected |
| rejoice |
| rejoiced |
| relapse |
| relate |
| related |
| relates |
| relating |
| relation |
| relations |
| relationship |
| relative |
| relatives |
| relaxed |
| release |
| released |
| relentless |
| relics |
| relied |
| relief |
| relieve |
| relieved |
| relieving |
| religion |
| religious |
| relish |
| reluctance |
| reluctant |
| rely |
| remain |
| remainder |
| remained |
| remaining |
| remains |
| remark |
| remarkable |
| remarkably |
| remarked |
| remarks |
| remedies |
| remedy |
| remember |
| remembered |
| remembering |
| remembrance |
| remind |
| reminded |
| remnant |
| remnants |
| remorse |
| remote |
| remoteness |
| remotest |
| removal |
| remove |
| removed |
| removing |
| rend |
| render |
| rendered |
| rendering |
| renders |
| rending |
| renew |
| renewal |
| renewed |
| renewing |
| renounce |
| renown |
| rent |
| rented |
| repair |
| repaired |
| repay |
| repeat |
| repeated |
| repeatedly |
| repeating |
| repellent |
| repentance |
| repetition |
| repetitions |
| repined |
| replaced |
| replete |
| replied |
| replies |
| reply |
| report |
| reported |
| reporters |
| reports |
| repose |
| reposed |
| represent |
| represented |
| reproach |
| reproached |
| reproaches |
| republic |
| republican |
| repugnance |
| repulsed |
| repulsion |
| repulsive |
| reputation |
| reputed |
| request |
| requested |
| require |
| required |
| requires |
| requisite |
| rescue |
| rescued |
| research |
| researches |
| resemblance |
| resemble |
| resembled |
| resembles |
| resembling |
| resentment |
| reserve |
| reserved |
| reside |
| resided |
| residence |
| resident |
| residing |
| resignation |
| resigned |
| resist |
| resistance |
| resisted |
| resolutely |
| resolution |
| resolve |
| resolved |
| resolving |
| resort |
| resorted |
| resounded |
| resource |
| resources |
| respect |
| respectable |
| respected |
| respectfully |
| respecting |
| respective |
| respects |
| respiration |
| respite |
| response |
| responses |
| responsible |
| rest |
| rested |
| resting |
| restless |
| restlessly |
| restlessness |
| restoration |
| restore |
| restored |
| restoring |
| restrain |
| restrained |
| restraint |
| rests |
| result |
| resulted |
| resulting |
| results |
| resume |
| resumed |
| resurrection |
| retain |
| retained |
| retaining |
| retire |
| retired |
| retirement |
| retiring |
| retreat |
| retreated |
| retreating |
| return |
| returned |
| returning |
| reveal |
| revealed |
| revealing |
| revel |
| revelation |
| revelled |
| revellers |
| revelry |
| revels |
| revenge |
| reverberated |
| reverence |
| reverie |
| reveries |
| reverse |
| reversed |
| revert |
| reverted |
| review |
| revive |
| revived |
| revolution |
| revolutions |
| revolved |
| revolver |
| reward |
| rewarded |
| rhine |
| rhoby |
| rhode |
| rhythm |
| rhythmical |
| ribbon |
| ribbons |
| ribs |
| ricci |
| rice |
| rich |
| richer |
| riches |
| richest |
| richly |
| richmond |
| rickety |
| rid |
| ridden |
| riddle |
| ride |
| rider |
| rides |
| ridge |
| ridicule |
| ridiculous |
| ridiculously |
| riding |
| rife |
| rift |
| right |
| rightly |
| rights |
| rigid |
| rigidity |
| rigidly |
| rigorous |
| rigorously |
| rim |
| ring |
| ringing |
| ringlets |
| rings |
| riot |
| riots |
| ripples |
| rise |
| risen |
| rises |
| rising |
| risk |
| rite |
| rites |
| ritual |
| ritzner |
| rival |
| river |
| rivers |
| riveted |
| road |
| roads |
| roadway |
| roamed |
| roaming |
| roar |
| roared |
| roaring |
| roarings |
| rob |
| robber |
| robe |
| robed |
| robert |
| robes |
| rock |
| rocked |
| rocks |
| rocky |
| rod |
| rode |
| rodosto |
| rogêt |
| roll |
| rolled |
| rolling |
| roman |
| romance |
| romantic |
| rome |
| romero |
| romnod |
| roof |
| roofed |
| roofs |
| room |
| rooms |
| rooted |
| roots |
| rope |
| ropes |
| rose |
| roseate |
| roses |
| rotted |
| rotten |
| rotterdam |
| rotting |
| rough |
| roughly |
| roule |
| roulet |
| roulets |
| round |
| rounded |
| rouse |
| roused |
| route |
| routine |
| row |
| rowdy |
| rowena |
| rowley |
| rows |
| royal |
| royalty |
| rub |
| rubbed |
| rubbing |
| rubbish |
| ruby |
| rud |
| rudder |
| rude |
| rudely |
| rudeness |
| rudimental |
| rue |
| ruffians |
| rugged |
| ruin |
| ruined |
| ruinous |
| ruins |
| rule |
| ruled |
| ruler |
| rules |
| rum |
| rumbling |
| rumblings |
| rumgudgeon |
| rumors |
| rumour |
| rumoured |
| rumours |
| run |
| running |
| runs |
| rural |
| rush |
| rushed |
| rushes |
| rushing |
| russia |
| rusted |
| rustic |
| rustling |
| rusty |
| ryland |
| sabbat |
| sabbath |
| sable |
| sacred |
| sacrifice |
| sacrificed |
| sacrifices |
| sad |
| saddle |
| sadly |
| sadness |
| safe |
| safely |
| safer |
| safety |
| safie |
| sagacious |
| sagacity |
| sagging |
| said |
| sail |
| sailed |
| sailing |
| sailor |
| sailors |
| sails |
| saint |
| saintly |
| sake |
| salem |
| sallies |
| sally |
| salt |
| saluted |
| salvation |
| same |
| sand |
| sands |
| sandy |
| sane |
| sang |
| sanguine |
| sanity |
| sank |
| saound |
| sardonic |
| sarnath |
| sartain |
| sarten |
| sash |
| sat |
| satan |
| sate |
| satellite |
| satiated |
| satin |
| satisfaction |
| satisfactory |
| satisfied |
| satisfy |
| satisfying |
| saturday |
| satyr |
| savage |
| save |
| saved |
| saving |
| saw |
| sawyer |
| saxon |
| say |
| saying |
| says |
| scale |
| scales |
| scaly |
| scanned |
| scant |
| scanty |
| scarabæus |
| scarce |
| scarcely |
| scare |
| scared |
| scarlet |
| scattered |
| scene |
| scenery |
| scenes |
| scent |
| scented |
| scheme |
| schemes |
| scholar |
| school |
| schoolboy |
| schools |
| science |
| sciences |
| scientific |
| scientist |
| scope |
| score |
| scorn |
| scotch |
| scotland |
| scoundrel |
| scourge |
| scrambled |
| scrap |
| scraps |
| scratching |
| scream |
| screamed |
| screaming |
| screams |
| screen |
| screw |
| screwed |
| scribonius |
| scruple |
| scruples |
| scrupulous |
| scrutinized |
| scrutinizing |
| scrutiny |
| sculptor |
| sculpture |
| sculptured |
| sculptures |
| scythe |
| se |
| sea |
| seal |
| sealed |
| seaman |
| seamen |
| search |
| searched |
| searchers |
| searching |
| searchlight |
| seared |
| seas |
| season |
| seasons |
| seat |
| seated |
| seats |
| seaward |
| seaweed |
| sech |
| secluded |
| seclusion |
| second |
| secondary |
| secondly |
| seconds |
| secrecy |
| secret |
| secretary |
| secretly |
| secrets |
| section |
| secure |
| secured |
| securely |
| securing |
| security |
| see |
| seed |
| seeing |
| seek |
| seeking |
| seeks |
| seem |
| seemed |
| seeming |
| seemingly |
| seems |
| seen |
| sees |
| seething |
| sefton |
| seine |
| seize |
| seized |
| seizing |
| seizure |
| seldom |
| selected |
| self |
| selfish |
| selfishness |
| sell |
| selle |
| semblance |
| semi |
| send |
| sending |
| sensation |
| sensations |
| sense |
| senseless |
| senses |
| sensibility |
| sensible |
| sensibly |
| sensitive |
| sensitiveness |
| sensual |
| sent |
| sentence |
| sentences |
| sentience |
| sentiment |
| sentiments |
| sentinel |
| separate |
| separated |
| separation |
| september |
| sepulchral |
| sepulchre |
| serene |
| series |
| serious |
| seriously |
| seriousness |
| serpent |
| servant |
| servants |
| serve |
| served |
| service |
| services |
| set |
| seth |
| sets |
| setting |
| settle |
| settled |
| settlement |
| seven |
| seventeen |
| seventeenth |
| seventh |
| seventy |
| several |
| severe |
| severity |
| sex |
| shabby |
| shade |
| shaded |
| shades |
| shadow |
| shadowed |
| shadows |
| shadowy |
| shady |
| shaft |
| shake |
| shaken |
| shakespeare |
| shaking |
| shaky |
| shall |
| shallow |
| shalt |
| shambling |
| shame |
| shape |
| shaped |
| shapeless |
| shapes |
| share |
| shared |
| sharp |
| sharpened |
| sharply |
| shattered |
| shaven |
| she |
| shed |
| sheds |
| sheehan |
| sheep |
| sheer |
| sheet |
| sheets |
| shelf |
| shell |
| shells |
| shelter |
| sheltered |
| shelves |
| shepherd |
| shew |
| shewed |
| shewing |
| shewn |
| shield |
| shielded |
| shift |
| shifting |
| shine |
| shines |
| shingles |
| shining |
| ship |
| ships |
| shirt |
| shiver |
| shivered |
| shivering |
| shock |
| shocked |
| shocking |
| shockingly |
| shoes |
| shone |
| shook |
| shoot |
| shop |
| shops |
| shore |
| shoreless |
| shores |
| short |
| shorter |
| shortly |
| shot |
| shots |
| should |
| shoulder |
| shoulders |
| shout |
| shouted |
| shouting |
| shouts |
| show |
| showed |
| shower |
| shown |
| shrank |
| shreds |
| shriek |
| shrieked |
| shrieking |
| shrieks |
| shrill |
| shrine |
| shrines |
| shrink |
| shrivelled |
| shroud |
| shrouded |
| shrouds |
| shrub |
| shrubberies |
| shrubbery |
| shrunk |
| shudder |
| shuddered |
| shuddering |
| shudderingly |
| shun |
| shunned |
| shut |
| shutter |
| shuttered |
| shutters |
| shutting |
| si |
| sibyl |
| sic |
| sick |
| sickened |
| sickening |
| sickly |
| sickness |
| side |
| sides |
| sidewalk |
| siege |
| sigh |
| sighed |
| sighs |
| sight |
| sighted |
| sightless |
| sights |
| sign |
| signal |
| signature |
| signed |
| significance |
| significant |
| signora |
| signs |
| silence |
| silent |
| silently |
| silk |
| silken |
| silly |
| silva |
| silver |
| similar |
| similarity |
| simile |
| similes |
| simple |
| simplest |
| simpleton |
| simplicity |
| simply |
| simpson |
| simultaneously |
| sin |
| since |
| sincere |
| sincerely |
| sincerity |
| sing |
| singer |
| singing |
| single |
| singly |
| singular |
| singularity |
| singularly |
| sinister |
| sink |
| sinking |
| sinks |
| sir |
| sister |
| sisters |
| sit |
| site |
| sits |
| sitting |
| situated |
| situation |
| situations |
| six |
| sixteen |
| sixth |
| sixty |
| size |
| skeleton |
| skeletons |
| sketch |
| skies |
| skill |
| skin |
| skull |
| sky |
| slab |
| slabs |
| slack |
| slacken |
| slain |
| slang |
| slant |
| slanting |
| slate |
| slater |
| slaughter |
| slave |
| slavery |
| slaves |
| sledge |
| sleep |
| sleeper |
| sleepers |
| sleeping |
| sleeps |
| sleepy |
| sleeve |
| sleeves |
| slender |
| slept |
| slid |
| slide |
| sliding |
| slight |
| slightest |
| slightly |
| slime |
| slimy |
| slip |
| slipped |
| slippery |
| slipping |
| slope |
| sloped |
| slopes |
| slow |
| slowly |
| slumber |
| slumbering |
| slumbers |
| slums |
| sly |
| smack |
| small |
| smaller |
| smallest |
| smell |
| smelled |
| smelling |
| smelt |
| smile |
| smiled |
| smiles |
| smiling |
| smith |
| smitherton |
| smoke |
| smoking |
| smooth |
| smoothed |
| snake |
| snapped |
| snatched |
| snatches |
| snob |
| snobbs |
| snow |
| snows |
| snowy |
| snuff |
| so |
| sob |
| sobbed |
| sobbing |
| sober |
| sobs |
| social |
| society |
| sockets |
| sod |
| sofa |
| soft |
| soften |
| softened |
| softer |
| softly |
| softness |
| soil |
| sojourn |
| solace |
| solar |
| sold |
| soldier |
| soldiers |
| sole |
| soleil |
| solely |
| solemn |
| solemnity |
| solemnly |
| solicitude |
| solid |
| solitary |
| solitude |
| solitudes |
| solomon |
| solution |
| solutions |
| solved |
| solving |
| sombre |
| some |
| somebody |
| somehow |
| someone |
| somethin |
| something |
| sometimes |
| somewhat |
| somewhere |
| somthing |
| son |
| sona |
| song |
| songs |
| sonorous |
| sons |
| soon |
| sooner |
| sooth |
| soothe |
| soothed |
| soothing |
| sorcier |
| sordid |
| sore |
| sorrow |
| sorrowful |
| sorrowing |
| sorrows |
| sorry |
| sort |
| sorts |
| sothoth |
| sought |
| soul |
| souls |
| sound |
| sounded |
| sounding |
| soundly |
| sounds |
| source |
| sources |
| south |
| southeast |
| southern |
| southward |
| southwards |
| sovereign |
| sovereignty |
| space |
| spaces |
| spacious |
| spade |
| spades |
| spain |
| spanish |
| spanned |
| spare |
| spared |
| spark |
| sparkled |
| sparkling |
| sparse |
| spasm |
| spasmodic |
| spattering |
| speak |
| speaker |
| speaking |
| speaks |
| special |
| specialist |
| species |
| specimen |
| specimens |
| speckled |
| spectacle |
| spectacled |
| spectacles |
| spectator |
| spectators |
| spectral |
| spectre |
| speculating |
| speculation |
| speculations |
| sped |
| speech |
| speeches |
| speechless |
| speed |
| speedily |
| speedy |
| spell |
| spells |
| spend |
| spent |
| sphere |
| spheres |
| spices |
| spiky |
| spinning |
| spiral |
| spires |
| spirit |
| spirited |
| spirits |
| spiritual |
| spirituality |
| spite |
| splash |
| splendid |
| splendor |
| splendour |
| splintered |
| split |
| spoiled |
| spoke |
| spoken |
| sport |
| spot |
| spots |
| spotted |
| sprang |
| sprawled |
| spray |
| sprayer |
| spread |
| spreading |
| spring |
| springing |
| springs |
| sprung |
| spurn |
| spurned |
| sputter |
| spy |
| squalid |
| squalor |
| square |
| squares |
| squat |
| squatted |
| squatter |
| squatters |
| squint |
| squire |
| st |
| stable |
| stables |
| stage |
| stages |
| staggered |
| staggering |
| stained |
| staircase |
| staircases |
| stairs |
| stale |
| stalked |
| stalking |
| stall |
| stamboul |
| stamp |
| stamping |
| stand |
| standard |
| standing |
| stands |
| stanzas |
| star |
| starboard |
| stare |
| stared |
| staring |
| stark |
| starry |
| stars |
| start |
| started |
| starting |
| startled |
| startling |
| starvation |
| state |
| stated |
| stately |
| statement |
| states |
| station |
| stationary |
| statue |
| statues |
| stature |
| stay |
| stayed |
| stead |
| steadied |
| steadily |
| steady |
| steal |
| stealthily |
| stealthy |
| steam |
| steed |
| steel |
| steep |
| steeped |
| steeple |
| steeples |
| steeply |
| steered |
| stench |
| step |
| stephen |
| stepped |
| steps |
| stern |
| stick |
| stickiness |
| stiff |
| stifled |
| stifling |
| still |
| stillness |
| sting |
| stings |
| stir |
| stirred |
| stirring |
| stock |
| stole |
| stolen |
| stomach |
| stone |
| stones |
| stony |
| stood |
| stooped |
| stooping |
| stop |
| stopped |
| stopping |
| storage |
| store |
| stores |
| stories |
| storm |
| storms |
| stormy |
| story |
| stout |
| stragglers |
| straggling |
| straight |
| strain |
| strained |
| straining |
| strains |
| strait |
| strange |
| strangely |
| strangeness |
| stranger |
| strangers |
| straw |
| stray |
| strayed |
| stream |
| streamed |
| streaming |
| streams |
| street |
| streets |
| strength |
| strengthened |
| stress |
| stretch |
| stretched |
| strew |
| strewed |
| stricken |
| strict |
| strictly |
| strike |
| strikes |
| striking |
| string |
| strings |
| strip |
| strips |
| strive |
| striving |
| strode |
| stroke |
| strokes |
| strolled |
| strong |
| stronger |
| strongest |
| strongly |
| strove |
| struck |
| structure |
| struggle |
| struggled |
| struggles |
| struggling |
| ström |
| stuck |
| studded |
| student |
| students |
| studied |
| studies |
| studio |
| study |
| studying |
| stuff |
| stuffed |
| stumble |
| stumbled |
| stumbling |
| stung |
| stunned |
| stupefied |
| stupendous |
| stupid |
| stupidity |
| stupified |
| stupor |
| sturdy |
| sty |
| style |
| styles |
| subconscious |
| subdue |
| subdued |
| subject |
| subjected |
| subjects |
| subjoined |
| sublime |
| submission |
| submit |
| submitted |
| subsequent |
| subsequently |
| subside |
| subsided |
| substance |
| substantial |
| subterranean |
| subtle |
| subtlety |
| subtly |
| suburbs |
| subway |
| succeed |
| succeeded |
| succeeding |
| success |
| successful |
| successfully |
| succession |
| successive |
| succour |
| succumbed |
| such |
| sucked |
| sudden |
| suddenly |
| suddenness |
| suffer |
| suffered |
| sufferer |
| suffering |
| sufferings |
| suffers |
| suffice |
| sufficed |
| sufficient |
| sufficiently |
| suffocation |
| suggest |
| suggested |
| suggestion |
| suggestions |
| suggestive |
| suicide |
| suit |
| suitable |
| suite |
| sullen |
| sullenly |
| sum |
| summer |
| summit |
| summits |
| summoned |
| summons |
| sumptuous |
| sums |
| sun |
| sunbeam |
| sunday |
| sundays |
| sung |
| sunk |
| sunken |
| sunlight |
| sunny |
| sunrise |
| suns |
| sunset |
| sunshine |
| superb |
| superficial |
| superfluous |
| superhuman |
| superintendent |
| superior |
| superiority |
| supernal |
| supernatural |
| superstition |
| superstitions |
| superstitious |
| supervened |
| supper |
| supplied |
| supply |
| support |
| supported |
| supporting |
| suppose |
| supposed |
| supposing |
| supposition |
| suppress |
| suppressed |
| supremacy |
| supreme |
| supremely |
| surcingle |
| sure |
| surely |
| surf |
| surface |
| surfaces |
| surgeon |
| surging |
| surmount |
| surmounted |
| surmounting |
| surpassed |
| surpassing |
| surprise |
| surprised |
| surprising |
| surprisingly |
| surrender |
| surround |
| surrounded |
| surrounding |
| surroundings |
| survey |
| surveyed |
| survive |
| survived |
| surviving |
| survivor |
| survivors |
| susceptibility |
| susceptible |
| suspect |
| suspected |
| suspecting |
| suspended |
| suspense |
| suspicion |
| suspicions |
| suspicious |
| sustain |
| sustained |
| sustaining |
| suthin |
| swallowed |
| swamp |
| swarming |
| swarthy |
| swath |
| sway |
| swaying |
| swear |
| sweep |
| sweeping |
| sweeps |
| sweet |
| sweeter |
| sweetest |
| sweetness |
| swell |
| swelled |
| swelling |
| swells |
| swept |
| swift |
| swiftly |
| swiftness |
| swim |
| swimming |
| swinging |
| switch |
| switzerland |
| swollen |
| swoon |
| swooned |
| sword |
| swore |
| sworn |
| swung |
| sx |
| sydney |
| syllable |
| syllabled |
| syllables |
| symbol |
| sympathetic |
| sympathies |
| sympathize |
| sympathized |
| sympathizing |
| sympathy |
| symptom |
| symptoms |
| syria |
| system |
| systematic |
| systems |
| ta |
| table |
| tables |
| tablet |
| tail |
| tailor |
| tails |
| taint |
| tainted |
| take |
| taken |
| takes |
| taking |
| talbot |
| tale |
| talent |
| talents |
| tales |
| talk |
| talked |
| talking |
| talks |
| tall |
| talons |
| tame |
| tamed |
| tameless |
| tangible |
| taown |
| tapestries |
| tapestry |
| tar |
| taran |
| tardy |
| tarn |
| tarnished |
| tarpaulin |
| tarry |
| task |
| taste |
| tasteful |
| tastes |
| tattered |
| taught |
| taunt |
| te |
| tea |
| teach |
| teacher |
| tear |
| tearful |
| tearing |
| tears |
| tedious |
| teeming |
| teeth |
| tegea |
| telephone |
| telescope |
| telescopes |
| tell |
| tellin |
| telling |
| tells |
| teloth |
| temper |
| temperament |
| tempest |
| tempestuous |
| temple |
| temples |
| templeton |
| temporary |
| tempted |
| ten |
| tenant |
| tenanted |
| tenants |
| tend |
| tended |
| tendency |
| tender |
| tenderest |
| tenderly |
| tenderness |
| tenebrous |
| tenement |
| tenor |
| tense |
| tension |
| tentacles |
| tenth |
| tenths |
| tents |
| tenuity |
| ter |
| term |
| termed |
| terminated |
| terminating |
| termination |
| terms |
| terrace |
| terraces |
| terrestrial |
| terrible |
| terribly |
| terrific |
| terrified |
| terrifying |
| territory |
| terror |
| terrors |
| test |
| tested |
| testimony |
| text |
| texture |
| th |
| thames |
| than |
| thank |
| thanked |
| thanks |
| thar |
| that |
| the |
| theatre |
| theatres |
| thee |
| their |
| theirs |
| them |
| theme |
| themselves |
| then |
| thence |
| thenceforward |
| theories |
| theory |
| there |
| thereafter |
| thereby |
| therefore |
| therefrom |
| therein |
| these |
| thet |
| they |
| thick |
| thickened |
| thicker |
| thicket |
| thickly |
| thief |
| thin |
| thine |
| thing |
| things |
| thingum |
| think |
| thinking |
| thinks |
| thinned |
| thinner |
| third |
| thirst |
| thirteen |
| thirty |
| this |
| thither |
| tho |
| thomas |
| thorn |
| thorns |
| thorough |
| thoroughfare |
| thoroughly |
| those |
| thou |
| though |
| thought |
| thoughtful |
| thoughtless |
| thoughts |
| thousand |
| thousands |
| thraa |
| thrace |
| thread |
| threaded |
| threat |
| threatened |
| threatening |
| threats |
| three |
| threshold |
| threw |
| thrice |
| thrill |
| thrilled |
| thrilling |
| thrillingly |
| throat |
| throats |
| throes |
| throne |
| throng |
| thronged |
| thronging |
| through |
| throughout |
| throw |
| throwing |
| thrown |
| throws |
| thrust |
| thrusting |
| thumb |
| thunder |
| thunderbolt |
| thunders |
| thunderstorm |
| thunderstorms |
| thursday |
| thus |
| thy |
| tiara |
| ticking |
| tide |
| tides |
| tidings |
| tie |
| tied |
| tier |
| ties |
| tiger |
| tight |
| tightly |
| tiles |
| till |
| tillinghast |
| tilton |
| timber |
| timbers |
| time |
| times |
| timid |
| timidity |
| tin |
| tinge |
| tinged |
| tint |
| tinted |
| tints |
| tiny |
| tired |
| tis |
| tissue |
| tissues |
| titan |
| titanic |
| title |
| titles |
| tittering |
| to |
| tobacco |
| tobey |
| today |
| together |
| toil |
| toiled |
| toils |
| token |
| tokens |
| told |
| tolerable |
| tolerably |
| tom |
| tomb |
| tombs |
| tomorrow |
| tone |
| tones |
| tongue |
| tongues |
| tonight |
| tons |
| too |
| took |
| tools |
| top |
| topic |
| topics |
| topmost |
| tops |
| torch |
| torches |
| tore |
| torment |
| tormented |
| tormenting |
| tormentor |
| torments |
| torn |
| torpor |
| torrent |
| torrents |
| torture |
| tortured |
| tortures |
| tossed |
| total |
| totally |
| tottered |
| tottering |
| tottle |
| touch |
| touched |
| touching |
| tour |
| toward |
| towards |
| tower |
| towered |
| towering |
| towers |
| town |
| towns |
| townsfolk |
| trace |
| traced |
| traces |
| tracing |
| track |
| tracks |
| trade |
| traded |
| trader |
| tradition |
| traditions |
| tragedies |
| tragedy |
| tragic |
| trail |
| train |
| trained |
| training |
| trait |
| traits |
| tramp |
| trampled |
| trance |
| tranquil |
| tranquillity |
| tranquilly |
| transacted |
| transcend |
| transcendant |
| transfer |
| transformed |
| transient |
| transitory |
| translated |
| translation |
| transmit |
| transom |
| transparent |
| transport |
| transported |
| trap |
| trash |
| travel |
| travelled |
| traveller |
| travellers |
| travelling |
| travels |
| traversed |
| treacherous |
| tread |
| treason |
| treasure |
| treasures |
| treat |
| treated |
| treatise |
| treatment |
| tree |
| trees |
| tremble |
| trembled |
| trembling |
| tremendous |
| tremor |
| tremulous |
| trepidation |
| tresses |
| trever |
| trial |
| triangular |
| tribe |
| tribes |
| trick |
| tried |
| trifle |
| trifles |
| trifling |
| trim |
| trio |
| trip |
| triple |
| trips |
| triumph |
| triumphant |
| triumphantly |
| triumphed |
| trivial |
| trod |
| trodden |
| troop |
| troops |
| trot |
| trouble |
| troubled |
| truce |
| true |
| truest |
| truly |
| trunk |
| trunks |
| trust |
| trusted |
| trusting |
| truth |
| truths |
| try |
| trying |
| tub |
| tube |
| tuesday |
| tulip |
| tumbled |
| tumult |
| tumultuous |
| tunic |
| tunnel |
| turbid |
| turbulent |
| turf |
| turk |
| turkey |
| turkish |
| turks |
| turn |
| turned |
| turning |
| turns |
| turret |
| turrets |
| twas |
| twelve |
| twentieth |
| twenty |
| twice |
| twilight |
| twin |
| twinkled |
| twisted |
| twitching |
| two |
| tx |
| tyché |
| type |
| typical |
| tyranny |
| tyrant |
| tête |
| ud |
| ugh |
| ugliness |
| ugly |
| ulswater |
| ulthar |
| ultimate |
| ultimately |
| un |
| una |
| unable |
| unaccountable |
| unaccountably |
| unaccustomed |
| unaided |
| unaltered |
| unattended |
| unavoidable |
| unaware |
| unbearable |
| unbecoming |
| unbelievable |
| unbidden |
| unbounded |
| unbroken |
| unburied |
| uncannily |
| uncanny |
| unceasing |
| unceasingly |
| uncertain |
| uncertainty |
| unchecked |
| uncle |
| unclosed |
| uncomfortable |
| uncomfortably |
| uncommon |
| uncomplaining |
| unconnected |
| unconscious |
| unconsciously |
| uncontrollable |
| uncouth |
| uncovered |
| und |
| undecayed |
| under |
| underbrush |
| underduk |
| undergo |
| undergoing |
| undergone |
| underground |
| understand |
| understanding |
| understood |
| undertake |
| undertaker |
| undertaking |
| undertook |
| underwood |
| undiscovered |
| undisturbed |
| undivided |
| undoubtedly |
| undue |
| undulations |
| unearthed |
| unearthly |
| uneasily |
| uneasiness |
| uneasy |
| uneducated |
| unendurable |
| unequal |
| unequivocal |
| unexampled |
| unexpected |
| unexpectedly |
| unexplored |
| unfamiliar |
| unfastened |
| unfathomable |
| unfathomed |
| unfinished |
| unfit |
| unfold |
| unfolded |
| unfortunate |
| unfortunately |
| unfrequently |
| ungovernable |
| ungrateful |
| unguided |
| unhallowed |
| unhappiness |
| unhappy |
| unhealthy |
| unheard |
| unhinged |
| unholy |
| uniform |
| unimaginable |
| unimagined |
| unimpeded |
| unintelligible |
| uninterrupted |
| union |
| unique |
| unison |
| unite |
| united |
| universal |
| universe |
| university |
| unjust |
| unjustly |
| unkempt |
| unkindness |
| unknown |
| unless |
| unlighted |
| unlike |
| unlimited |
| unlock |
| unlocked |
| unmeaning |
| unmentionable |
| unmingled |
| unmistakable |
| unmistakably |
| unmoved |
| unnamable |
| unnatural |
| unnaturally |
| unnecessary |
| unnerved |
| unnoticed |
| unobserved |
| unparalleled |
| unparticled |
| unpaved |
| unpeopled |
| unperceived |
| unpleasant |
| unpleasing |
| unprecedented |
| unprotected |
| unquestionably |
| unquiet |
| unreal |
| unreasonable |
| unremitting |
| unrest |
| unrestrained |
| unsatisfactory |
| unseen |
| unspeakable |
| unsuccessful |
| unthinkable |
| until |
| untill |
| untimely |
| unto |
| untold |
| untouched |
| untoward |
| unused |
| unusual |
| unusually |
| unutterable |
| unvarying |
| unveiled |
| unvisited |
| unwearied |
| unwelcome |
| unwholesome |
| unwieldy |
| unwilling |
| unwittingly |
| unwonted |
| unworthy |
| up |
| uplifted |
| upon |
| upper |
| upright |
| uproar |
| upstairs |
| upward |
| upwards |
| urge |
| urged |
| urgent |
| urging |
| urn |
| us |
| use |
| used |
| useful |
| useless |
| uses |
| usher |
| using |
| usual |
| usually |
| utility |
| utmost |
| utter |
| utterance |
| uttered |
| utterly |
| uttermost |
| vacancy |
| vacant |
| vacillating |
| vacillation |
| vacuum |
| vagabond |
| vagaries |
| vague |
| vaguely |
| vain |
| vainly |
| valdemar |
| vale |
| valence |
| valet |
| valiant |
| valise |
| valley |
| valleys |
| valor |
| valuable |
| value |
| valued |
| valve |
| van |
| vanes |
| vanish |
| vanished |
| vanity |
| vanquished |
| vapor |
| vapour |
| vapours |
| variable |
| variance |
| variation |
| variations |
| varied |
| varieties |
| variety |
| various |
| varying |
| vase |
| vast |
| vastly |
| vastness |
| vat |
| vault |
| vaulted |
| vaults |
| ve |
| veal |
| veered |
| vegetable |
| vegetation |
| vehemence |
| vehicle |
| veil |
| veiled |
| veils |
| veined |
| veins |
| vell |
| velocity |
| velvet |
| venerable |
| veneration |
| vengeance |
| venice |
| venom |
| venomous |
| vent |
| venture |
| ventured |
| venus |
| ver |
| verbatim |
| verdant |
| verdure |
| verge |
| veritable |
| verney |
| verse |
| verses |
| version |
| very |
| vessel |
| vessels |
| vestibule |
| vestige |
| vex |
| vexation |
| vexed |
| vibration |
| vibrations |
| vice |
| vicinity |
| vicious |
| victim |
| victims |
| victor |
| victory |
| vienna |
| view |
| viewed |
| viewless |
| views |
| vigil |
| vigilance |
| vigilant |
| vigor |
| vigorous |
| vigorously |
| vigour |
| vile |
| village |
| villagers |
| villages |
| villain |
| villains |
| vine |
| vines |
| viol |
| violated |
| violence |
| violent |
| violently |
| violet |
| violets |
| virgin |
| virginia |
| virtu |
| virtually |
| virtue |
| virtues |
| virtuous |
| virulence |
| visage |
| visaged |
| viscous |
| visible |
| visibly |
| vision |
| visionary |
| visions |
| visit |
| visitation |
| visited |
| visiter |
| visiting |
| visitor |
| visitors |
| visits |
| vista |
| vistas |
| visual |
| vital |
| vitality |
| vivacity |
| vivid |
| vividly |
| vividness |
| viz |
| vocal |
| voice |
| voiceless |
| voices |
| void |
| voissart |
| volcanic |
| volition |
| volume |
| volumes |
| voluntarily |
| voluntary |
| voluptuous |
| von |
| vondervotteimittiss |
| voodoo |
| vor |
| vortex |
| vortices |
| vow |
| vowed |
| vows |
| voyage |
| voyager |
| voyages |
| vulgar |
| vulture |
| wa |
| wade |
| wafted |
| wager |
| wagon |
| wailing |
| waist |
| wait |
| waited |
| waiting |
| wake |
| waked |
| waker |
| waking |
| wal |
| walakea |
| waldman |
| walk |
| walked |
| walking |
| walks |
| wall |
| walled |
| walls |
| walter |
| walton |
| wan |
| wand |
| wander |
| wandered |
| wanderer |
| wanderers |
| wandering |
| wanderings |
| waned |
| waning |
| want |
| wanted |
| wanting |
| wants |
| war |
| ward |
| warehouse |
| warehouses |
| warlike |
| warm |
| warmed |
| warmest |
| warmly |
| warmth |
| warned |
| warning |
| warrant |
| warranted |
| warren |
| warrior |
| wars |
| was |
| washed |
| washington |
| waste |
| wasted |
| wasting |
| watch |
| watched |
| watches |
| watchful |
| watching |
| watchman |
| water |
| waterfalls |
| waterfront |
| waters |
| watery |
| wave |
| waved |
| waves |
| waving |
| wax |
| waxed |
| way |
| ways |
| we |
| weak |
| weakened |
| weaker |
| weakness |
| wealth |
| wealthy |
| weapon |
| weapons |
| wear |
| wearied |
| weariness |
| wearing |
| wears |
| weary |
| weather |
| web |
| webb |
| wedded |
| wedding |
| wednesday |
| weed |
| weeds |
| weedy |
| week |
| weeks |
| weep |
| weeping |
| weigh |
| weighed |
| weighing |
| weight |
| weird |
| weirdly |
| welcome |
| welcomed |
| welfare |
| well |
| welled |
| went |
| wept |
| were |
| wert |
| west |
| western |
| westminster |
| westward |
| wet |
| whale |
| whang |
| whar |
| wharf |
| wharves |
| what |
| whateley |
| whateleys |
| whatever |
| whatsoever |
| wheel |
| wheeler |
| wheels |
| when |
| whence |
| whenever |
| where |
| whereabouts |
| whereby |
| wherefore |
| wherein |
| whereon |
| whereupon |
| wherever |
| whether |
| which |
| while |
| whilst |
| whim |
| whims |
| whimsical |
| whine |
| whining |
| whip |
| whippoorwills |
| whirl |
| whirled |
| whirling |
| whirlpool |
| whirlwind |
| whirring |
| whiskers |
| whiskey |
| whisper |
| whispered |
| whispering |
| whispers |
| whist |
| whistled |
| white |
| whiteness |
| whither |
| whitish |
| who |
| whoever |
| whole |
| wholesome |
| wholly |
| whom |
| whose |
| why |
| wicked |
| wickedness |
| wicker |
| wid |
| wide |
| widely |
| widened |
| wider |
| widest |
| widow |
| widowed |
| width |
| wife |
| wig |
| wilbur |
| wilcox |
| wild |
| wilder |
| wilderness |
| wildest |
| wildly |
| wildness |
| will |
| william |
| williams |
| willing |
| willingly |
| willow |
| wilson |
| wilt |
| win |
| wind |
| windenough |
| winding |
| windings |
| window |
| windows |
| winds |
| windsor |
| wine |
| wing |
| winged |
| wings |
| winking |
| winning |
| wins |
| winter |
| wipe |
| wiped |
| wire |
| wires |
| wisdom |
| wise |
| wisely |
| wiser |
| wisest |
| wish |
| wished |
| wishes |
| wishing |
| wit |
| witch |
| witchcraft |
| witches |
| with |
| withdraw |
| withdrawn |
| withdrew |
| withered |
| withering |
| withheld |
| within |
| without |
| withstand |
| witness |
| witnessed |
| witnesses |
| wits |
| wives |
| wizard |
| wo |
| woe |
| woes |
| woke |
| wolf |
| wolves |
| woman |
| women |
| won |
| wonder |
| wondered |
| wonderful |
| wonderfully |
| wondering |
| wonders |
| wondrous |
| wood |
| wooded |
| wooden |
| woodland |
| woods |
| woodville |
| wool |
| word |
| words |
| wore |
| work |
| worked |
| working |
| workings |
| workmanship |
| workmen |
| works |
| world |
| worldly |
| worlds |
| worm |
| worms |
| wormy |
| worn |
| worried |
| worry |
| worse |
| worship |
| worshipped |
| worshippers |
| worst |
| worth |
| worthless |
| worthy |
| would |
| wound |
| wounded |
| wounds |
| woven |
| wrapped |
| wrapper |
| wrapt |
| wrath |
| wreath |
| wreathed |
| wreaths |
| wreck |
| wreckage |
| wrecked |
| wretch |
| wretched |
| wretchedness |
| wretches |
| wriggle |
| wrinkled |
| wrist |
| wrists |
| write |
| writer |
| writers |
| writes |
| writhe |
| writhed |
| writhing |
| writing |
| writings |
| written |
| wrong |
| wronged |
| wrote |
| wrought |
| wyatt |
| xf |
| xld |
| ya |
| yacht |
| yard |
| yards |
| yawned |
| yawning |
| ye |
| year |
| yearned |
| years |
| yell |
| yellow |
| yellowed |
| yellowish |
| yells |
| yer |
| yes |
| yesterday |
| yet |
| yew |
| yield |
| yielded |
| yielding |
| yog |
| yon |
| yonder |
| york |
| yorkshire |
| you |
| young |
| younger |
| youngest |
| your |
| yours |
| yourself |
| yourselves |
| youth |
| youthful |
| youths |
| yxu |
| yxur |
| zadok |
| zaire |
| zann |
| zeal |
| zee |
| zenith |
| zenobia |
| zest |
| zit |
3.1 Trouver le texte le plus similaire
En premier lieu, on peut chercher le texte le plus proche, au sens de TF-IDF, d’une phrase donnée. Prenons cet exemple:
text = "He was afraid by Frankenstein monster"Comment retrouver le texte le plus proche de celui-ci ? Il faudrait transformer notre texte dans cette même représentation vectorielle et rapprocher ensuite celui-ci des autres textes représentés sous cette même forme.
Cela revient à effectuer une tâche de recherche d’information, cas d’usage classique du NLP, mis en oeuvre par exemple par les moteurs de recherche. Le terme Frankenstein étant assez discrminant, nous devrions, grâce à TF-IDF, retrouver des similarités entre notre texte et d’autres textes écrits par Mary Shelley.
Une métrique régulièrement utilisée pour comparer des vecteurs est la similarité cosinus. Il s’agit d’ailleurs d’une mesure centrale dans l’approche moderne du NLP. Celle-ci a plus de sens avec des vecteurs dense, que nous verrons prochainement, qu’avec des vecteurs comportant beaucoup de 0 comme le sont les vecteurs sparse des mesures bag-of-words. Néanmoins c’est déjà un exercice intéressant pour comprendre la similarité entre deux vecteurs.
Si chaque dimension d’un vecteur correspond à une direction, l’idée derrière la similarité cosinus est de mesurer l’angle entre deux vecteurs. L’angle sera réduit si les vecteurs sont proches.
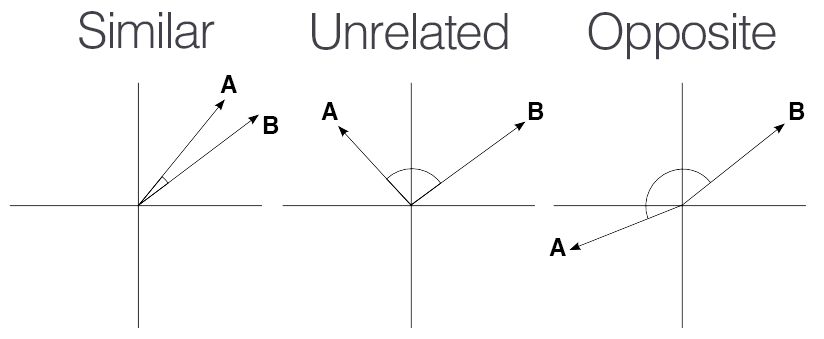
3.1.1 Avec Scikit-Learn
AstuceExercice 1: recherche de similarité avec TF-IDF
Utiliser la méthode
transformpour vectoriser tout notre corpus d’entraînement.En supposant que votre jeu d’entraînement vectorisé s’appelle
X_train_tfidf, vous pouvez le transformer en DataFrame avec la commande suivante:
X_train_tfidf = pd.DataFrame(
X_train_tfidf.todense(), columns=pipeline_tfidf.get_feature_names_out()
)- Utiliser la méthode
cosine_similaritydeScikitpour calculer la similarité cosinus entre notre texte vectorisé et l’ensemble du corpus d’entraînement grâce au code suivant:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarities = cosine_similarity(
X_train_tfidf,
pipeline_tfidf.transform([text])
).flatten()
top_4_indices = np.argsort(cosine_similarities)[-4:][::-1] # Tri décroissant
top_4_similarities = cosine_similarities[top_4_indices]- Retrouver les documents concernés. Êtes-vous satisfait du résultat ? Comprenez-vous ce qu’il s’est passé ?
A l’issue de l’exercice, les 4 textes les plus similaires sont:
| text | author | score | |
|---|---|---|---|
| 8181 | Listen to me, Frankenstein. | MWS | 0.402964 |
| 8606 | He was gazing at me gaspingly and fascinatedly... | HPL | 0.330177 |
| 14550 | The light is dimmer and the gods are afraid. . . | HPL | 0.314670 |
| 11366 | I screamed aloud that I was not afraid; that I... | HPL | 0.311235 |
3.1.2 Avec Langchain
Cette approche de calcul de similarité textuelle est assez laborieuse avec Scikit. Avec le développement continu d’applications Python utilisant des modèles de langage, un écosystème très complet s’est développé pour pouvoir faire ces tâches en quelques lignes de code avec Python.
Parmi les outils les plus précieux, nous trouvons Langchain, un écosystème Python haut-niveau permettant de construire des chaînes de production utilisant des données textuelles.
Nous allons ici procéder en 2 étapes:
- Créer un retriever, c’est-à-dire vectoriser avec TF-IDF notre corpus (les textes de nos trois auteurs) et les stocker sous forme de base de données vectorielle.
- Vectoriser à la volée notre texte de recherche (l’objet
textcréé précédemment) et rechercher sa contrepartie la plus proche dans la base de données vectorielle.
La vectorisation de notre corpus se fait très simplement grâce à Langchain
puisque le TfidfVectorizer de Scikit est encapsulé dans un module ad hoc de Langchain
from langchain_community.retrievers import TFIDFRetriever
from langchain_community.document_loaders import DataFrameLoader
loader = DataFrameLoader(spooky_df, page_content_column="text_clean")
retriever = TFIDFRetriever.from_documents(
loader.load()
)/tmp/ipykernel_8765/3052793950.py:1: DeprecationWarning: `langchain-community` is being sunset and is no longer actively maintained. See https://github.com/langchain-ai/langchain-community/issues/674 for details and migration guidance toward standalone integration packages.
from langchain_community.retrievers import TFIDFRetrieverCet objet retriever est un point d’entrée sur notre corpus. Langchain présente l’intérêt de fournir plusieurs points d’entrées standardisés, forts utiles dans les projets de NLP puisqu’il suffit de changer les vectoriseurs en entrée sans avoir à changer leur usage en fin de chaîne.
La méthode invoke permet de rechercher les vecteurs les plus similaires à notre texte de recherche:
retriever.invoke(text)[Document(metadata={'id': 'id12587', 'text': 'Listen to me, Frankenstein.', 'author': 'MWS', 'author_encoded': 2}, page_content='listen to me frankenstein'),
Document(metadata={'id': 'id09284', 'text': 'I screamed aloud that I was not afraid; that I never could be afraid; and others screamed with me for solace.', 'author': 'HPL', 'author_encoded': 1}, page_content='i screamed aloud that i was not afraid that i never could be afraid and others screamed with me for solace'),
Document(metadata={'id': 'id09797', 'text': 'It seemed to be a sort of monster, or symbol representing a monster, of a form which only a diseased fancy could conceive.', 'author': 'HPL', 'author_encoded': 1}, page_content='it seemed to be a sort of monster or symbol representing a monster of a form which only a diseased fancy could conceive'),
Document(metadata={'id': 'id10816', 'text': 'And, as I have implied, it was not of the dead man himself that I became afraid.', 'author': 'HPL', 'author_encoded': 1}, page_content='and as i have implied it was not of the dead man himself that i became afraid')]La sortie est un objet Langchain, ce qui n’est pas pratique pour nous dans notre situation. On se ramène à un DataFrame:
documents = []
for best_echoes in retriever.invoke(text):
documents += [{**best_echoes.metadata, **{"text_clean": best_echoes.page_content}}]
documents = pd.DataFrame(documents)On peut ajouter à ce DataFrame la colonne de score:
On retrouve bien les mêmes documents:
| id | text | author | author_encoded | text_clean | score | |
|---|---|---|---|---|---|---|
| 0 | id12587 | Listen to me, Frankenstein. | MWS | 2 | listen to me frankenstein | 0.402964 |
| 1 | id09284 | I screamed aloud that I was not afraid; that I... | HPL | 1 | i screamed aloud that i was not afraid that i ... | 0.311235 |
| 2 | id09797 | It seemed to be a sort of monster, or symbol r... | HPL | 1 | it seemed to be a sort of monster or symbol re... | 0.295587 |
| 3 | id10816 | And, as I have implied, it was not of the dead... | HPL | 1 | and as i have implied it was not of the dead m... | 0.261818 |
NoteLa métrique BM25
BM25 est un modèle de récupération d’informations basé sur la pertinence probabiliste, au même titre que TF-IDF. BM25 est souvent utilisée dans les moteurs de recherche pour classer les documents par rapport à une requête.
BM25 repose sur une combinaison de la fréquence des termes (TF), la fréquence inverse des documents (IDF), et une normalisation basée sur la longueur des documents. Autrement dit, il s’agit de tenir compte d’améliorer TF-IDF tout en normalisant les mesures en fonction de la taille des strings afin de ne pas surpondérer les grands documents.
BM25 est donc particulièrement performant dans des environnements où les documents varient en longueur et en contenu. C’est pour cette raison que des moteurs de recherche comme Elasticsearch en ont fait une pierre angulaire du mécanisme de recherche.
Pourquoi ne sont-ils pas tous pertinents ? On peut anticiper plusieurs raisons à cela.
La première hypothèse vient du fait qu’on entraîne notre vectoriseur sur un corpus biaisé. Certes Frankestein est un terme rare mais il est beaucoup plus fréquent dans notre corpus que dans la langue anglaise. L’inverse document frequency est donc biaisée en défaveur de ce terme: son apparition devrait être un signe beaucoup plus fort que le texte recherché correspond à Mary Shelley. Si cela peut améliorer un peu la pertinence des résultats renvoyés, ce n’est néanmoins pas là que le bât blesse.
L’approche fréquentiste suppose que les termes sont aussi dissemblables les uns que les autres. Une phrase où apparaît le terme “créature” ne bénéficiera pas d’un score positif si on recherche “monstre”. De plus, là encore, nous avons pris notre corpus comme un sac où les mots sont indépendants: on n’a pas plus de chance de tirer “Frankenstein” après “docteur”. Ces limites vont nous amener vers le sujet des embeddings. Néanmoins, si l’approche fréquentiste est un peu old school, elle n’est néanmoins pas inutile et représente souvent une “tough to beat baseline”. Dans les domaines de l’extraction d’information avec des textes courts, où chaque terme est porteur d’un signal fort, cette approche est souvent judicieuse.
3.2 Trouver l’auteur le plus proche: une introduction au classifieur naif Bayes
Avant d’explorer les embeddings, nous pouvons essayer d’avoir un cas d’usage un petit peu différent dans notre cadre probabiliste. Supposons qu’on désire maintenant faire de la prédiction d’auteur. Si l’intuition précédente est vraie - certains mots sont plus probables dans les textes de certains auteurs - cela veut dire qu’on peut entraîner un algorithme de classification automatique à prédire un auteur à partir d’un texte.
La méthode la plus naturelle pour se lancer dans cette approche est d’utiliser le classifieur naif de Bayes. Ce dernier est parfaitement adapté à l’approche fréquentiste que nous avons adoptée jusqu’à présent puisqu’il exploite les probabilités d’occurrence de mots par auteur.
Le classifieur naif de Bayes consiste à appliquer une règle de décision, à savoir sélectionner la classe la plus probable sachant la structure observée du document, c’est-à-dire les mots apparaissant dans celui-ci.
Autrement dit, on sélectionne la classe \(\widehat{c}\) qui est la plus probable, sachant les termes dans le document \(d\).
\[ \widehat{c} = \arg \max_{c \in \mathcal{C}} \mathbb{P}(c|d) = \arg \max_{c \in \mathcal{C}} \frac{ \mathbb{P}(d|c)\mathbb{P}(c)}{\mathbb{P}(d)} \tag{3.1}\]
Comme ceci est classique en estimation bayésienne, on peut se passer de certains termes constants, à savoir \(\mathbb{P}(d)\). La définition de la classe estimée peut ainsi être reformulée de cette manière:
\[ \widehat{c} = \arg \max_{c \in \mathcal{C}} \mathbb{P}(d|c)\mathbb{P}(c) \tag{3.2}\]
L’hypothèse du sac de mot intervient à ce niveau. Un document \(d\) est une collection de mots \(w_i\) dont l’ordre n’a pas d’intérêt. Autrement dit, on peut se contenter de faire un modèle sur les mots, sans faire intervenir des probabilités conditionnelles sur l’ordre d’occurrence. La seconde hypothèse forte est l’hypothèse naive à laquelle la méthode doit son nom: la probabilité de tirer un mot ne dépend que de la catégorie \(c\) d’appartenance du document. Autrement dit, on peut considérer qu’un document est une suite de tirage indépendants de mots dont la probabilité ne dépend que de l’auteur.
Comme cela est expliqué dans la boite dédiée, en faisant ces hypothèses, on peut réécrire ce classifieur sous la forme
\[ \widehat{c} = \arg \max_{c \in \mathcal{C}} \mathbb{P}(c)\prod_{w \in \mathcal{W}}{\mathbb{P}(w|c)} \]
avec \(\mathcal{W}\) l’ensemble des mots dans le corpus (notre vocabulaire).
Empiriquement, nous sommes dans une tâche d’apprentissage supervisé où le label est la classe du document et les features sont nos mots vectorisés. Empiriquement, les probabilités sont estimées à partir du dénombrement des mots dans le corpus et des types de documents dans le corpus.
Il est bien-sûr possible de calculer toutes ces grandeurs à la main mais Scikit permet d’implémenter un estimateur naif de Bayes après avoir vectorisé son corpus comme le montre le prochain exercice. Cela peut néanmoins poser un problème pratique: en principe, le corpus de test ne doit pas comporter de nouveaux mots car ces “nouvelles” dimensions n’étaient pas présentes dans le corpus d’entraînement. En pratique, la solution la plus simple est souvent celle choisie: ces mots sont ignorés.
AstuceExercice 2: le classifieur naif de Bayes
- En repartant de l’exemple précédent, définir un pipeline qui vectorise chaque document (utiliser
CountVectorizerplutôt queTFIDFVectorizer) et effectue une prédiction grâce à un modèle naif de Bayes. - Entraîner ce modèle, faire une prédiction sur le jeu de test.
- Evaluer la performance de votre modèle
- Faire une prédiction sur la phrase que nous avons utilisée tout à l’heure dans la variable
text. Obtenez-vous ce qui était attendu ? - Regarder les probabilités obtenues (méthode
predict_proba).
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
pipeline = Pipeline([
('vectorizer', CountVectorizer()),
('classifier', MultinomialNB())
])
# Train the pipeline on the training data
pipeline.fit(X_train, y_train)Pipeline(steps=[('vectorizer', CountVectorizer()),
('classifier', MultinomialNB())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Fitted attributes
| Name | Type | Value |
|---|---|---|
| classes_
classes_: ndarray of shape (n_classes,) The classes labels. Only exist if the last step of the pipeline is a classifier. |
ndarray[<U3](3,) | ['EAP','HPL','MWS'] |
Parameters
Fitted attributes
| Name | Type | Value |
|---|---|---|
| fixed_vocabulary_
fixed_vocabulary_: bool True if a fixed vocabulary of term to indices mapping is provided by the user. |
bool | False |
| vocabulary_
vocabulary_: dict A mapping of terms to feature indices. |
dict | {'ab': 0, 'aback': 1, 'abaft': 2, 'abandon': 3, ...} |
22902 features
| ab |
| aback |
| abaft |
| abandon |
| abandoned |
| abandoning |
| abandonment |
| abaout |
| abased |
| abasement |
| abashed |
| abashment |
| abate |
| abatement |
| abating |
| abbey |
| abbreviation |
| abbé |
| abdicated |
| abdication |
| abdications |
| abdomen |
| abdul |
| abernethy |
| aberrancy |
| aberrant |
| aberration |
| aberrations |
| abeyance |
| abhor |
| abhorred |
| abhorrence |
| abhorrent |
| abigail |
| abijah |
| abilities |
| ability |
| abject |
| abjure |
| ablaze |
| able |
| ably |
| abnormal |
| abnormalities |
| abnormality |
| abnormally |
| aboard |
| abode |
| abodes |
| abolished |
| abominable |
| abomination |
| abominations |
| aboriginal |
| abortion |
| abortions |
| abortive |
| abounds |
| about |
| above |
| abra |
| abreast |
| abroad |
| abrupt |
| abruptly |
| abruptness |
| absence |
| absences |
| absent |
| absolute |
| absolutely |
| absolved |
| absorb |
| absorbed |
| absorbing |
| absorbingly |
| absorption |
| abstain |
| abstemious |
| abstract |
| abstracted |
| abstraction |
| abstractions |
| abstractly |
| abstruse |
| abstruseness |
| absurd |
| absurdities |
| absurdity |
| absurdly |
| absurdness |
| absurdum |
| abundance |
| abundant |
| abundantly |
| abuse |
| abused |
| abuses |
| abutted |
| abutting |
| abxut |
| abysmal |
| abysms |
| abyss |
| abysses |
| academy |
| accaount |
| accede |
| accelerated |
| accelerating |
| acceleration |
| accent |
| accents |
| accentuation |
| accept |
| acceptance |
| acceptation |
| accepted |
| accepting |
| access |
| accessible |
| accession |
| accessory |
| accident |
| accidental |
| accidentally |
| accidents |
| acclaimed |
| acclamation |
| acclamations |
| acclivity |
| accommodate |
| accommodated |
| accommodation |
| accompanied |
| accompanies |
| accompaniment |
| accompany |
| accompanying |
| accomplice |
| accomplish |
| accomplished |
| accomplishing |
| accomplishment |
| accomplishments |
| accord |
| accordance |
| accorded |
| according |
| accordingly |
| accorto |
| accost |
| accosted |
| account |
| accounted |
| accounting |
| accounts |
| accoutred |
| accoutrements |
| accredited |
| accrue |
| accrued |
| accumulate |
| accumulated |
| accumulating |
| accumulation |
| accumulations |
| accumulative |
| accuracy |
| accurate |
| accurately |
| accursed |
| accusation |
| accusations |
| accuse |
| accused |
| accusers |
| accuses |
| accusing |
| accustomed |
| acetylene |
| ached |
| acheron |
| acherontic |
| achieve |
| achieved |
| achievement |
| achievements |
| achilles |
| aching |
| acid |
| acknowledge |
| acknowledged |
| acknowledgement |
| acknowledges |
| acknowledging |
| acknowledgment |
| acme |
| acolyte |
| acorns |
| acoustic |
| acquaint |
| acquaintance |
| acquaintances |
| acquainted |
| acquainting |
| acquiesce |
| acquiesced |
| acquiescence |
| acquire |
| acquired |
| acquirement |
| acquirements |
| acquires |
| acquiring |
| acquisition |
| acquisitions |
| acquit |
| acquittal |
| acquitted |
| acre |
| acrid |
| acrimony |
| across |
| acrost |
| act |
| acted |
| acting |
| action |
| actions |
| active |
| actively |
| activity |
| actor |
| actors |
| acts |
| actual |
| actuality |
| actually |
| actuated |
| actuates |
| acumen |
| acute |
| acutely |
| acuteness |
| ad |
| adage |
| adam |
| adamantine |
| adams |
| adapt |
| adaptation |
| adapted |
| adapting |
| adaption |
| add |
| added |
| adder |
| adders |
| addicted |
| adding |
| addison |
| addition |
| additional |
| address |
| addressed |
| addresses |
| addressing |
| adds |
| adduce |
| adduced |
| adelaide |
| ademptum |
| adept |
| adequate |
| adequately |
| adhere |
| adhered |
| adherence |
| adhesion |
| adieu |
| adjacent |
| adjective |
| adjoining |
| adjurations |
| adjure |
| adjust |
| adjusted |
| adjusting |
| adjustment |
| adjustments |
| admeasurement |
| administered |
| administration |
| admirable |
| admirably |
| admiral |
| admiralty |
| admiration |
| admire |
| admired |
| admirer |
| admirers |
| admires |
| admiring |
| admission |
| admit |
| admits |
| admittance |
| admitted |
| admitting |
| admonisher |
| admonishing |
| admonition |
| admonitions |
| ado |
| adolescence |
| adolphe |
| adonis |
| adopt |
| adopted |
| adopting |
| adoration |
| adore |
| adored |
| adores |
| adoring |
| adorn |
| adorned |
| adornment |
| adorns |
| adrian |
| adriatic |
| adrift |
| adroitness |
| adult |
| adulthood |
| advance |
| advanced |
| advancement |
| advances |
| advancing |
| advantage |
| advantageous |
| advantages |
| advent |
| adventitious |
| adventure |
| adventurer |
| adventurers |
| adventures |
| adventuring |
| adventurous |
| adversaries |
| adversary |
| adverse |
| adversities |
| adversity |
| advert |
| adverted |
| adverting |
| advertise |
| advertisement |
| advertisements |
| advertiser |
| advertising |
| advice |
| advices |
| advisability |
| advisable |
| advise |
| adviseable |
| advised |
| advising |
| advocate |
| advocated |
| advoue |
| aegidus |
| aegis |
| aeolus |
| aeon |
| aeons |
| aera |
| aerial |
| aeris |
| aeronauts |
| aerostation |
| aesculapius |
| aesthetes |
| aesthetic |
| aether |
| afar |
| afeard |
| afeared |
| affability |
| affable |
| affair |
| affairs |
| affect |
| affectation |
| affected |
| affectedly |
| affecting |
| affection |
| affectionate |
| affectionately |
| affectionateness |
| affections |
| affidavits |
| affiliations |
| affinity |
| affirm |
| affirmation |
| affirmative |
| affixed |
| afflatus |
| afflict |
| afflicted |
| affliction |
| afflictions |
| affluence |
| afford |
| afforded |
| affording |
| affords |
| affrays |
| affright |
| affrightedly |
| affronted |
| afloat |
| afoot |
| afore |
| aforesaid |
| afraid |
| afrasiab |
| afresh |
| africa |
| african |
| afriky |
| after |
| aftermath |
| afternoon |
| afternoons |
| afterward |
| afterwards |
| afur |
| ag |
| again |
| against |
| agatha |
| agathos |
| age |
| aged |
| agencies |
| agency |
| agent |
| agents |
| ages |
| aggrandisement |
| aggrandizement |
| aggravated |
| aggravation |
| aggregate |
| aggregated |
| aggression |
| aggressive |
| aghast |
| agile |
| agility |
| agin |
| agir |
| agitated |
| agitates |
| agitating |
| agitation |
| agitations |
| aglow |
| ago |
| agog |
| agonies |
| agonized |
| agonizing |
| agony |
| agora |
| agraffas |
| agree |
| agreeable |
| agreed |
| agreeing |
| agreement |
| agressi |
| agricultural |
| agriculture |
| agrippa |
| ague |
| ah |
| ahead |
| ahem |
| ai |
| aid |
| aided |
| aidenn |
| aides |
| aiding |
| aigrette |
| aiguilles |
| ailments |
| aim |
| aimed |
| aiming |
| aimless |
| aimlessly |
| aims |
| ainsworth |
| aiolos |
| air |
| aira |
| airs |
| airship |
| airy |
| aisles |
| ajar |
| akariel |
| akin |
| aklo |
| akurion |
| alabaster |
| alacrity |
| alarm |
| alarmed |
| alarming |
| alarmingly |
| alarummed |
| alas |
| alba |
| albano |
| albans |
| albany |
| albatross |
| albeit |
| albert |
| albertus |
| albinism |
| albino |
| alchemical |
| alchemists |
| alchemy |
| alcmaeon |
| alcohol |
| alcove |
| alcoves |
| aldebaran |
| alderney |
| ale |
| alert |
| alertly |
| alertness |
| ales |
| alex |
| alexander |
| alfieri |
| alfred |
| algebraical |
| algebraists |
| algol |
| alhazred |
| alice |
| alien |
| alienage |
| alienated |
| alienation |
| alienists |
| alight |
| alighted |
| alike |
| alimentiveness |
| aliquantulum |
| alit |
| aliterque |
| alive |
| all |
| allah |
| allan |
| allaow |
| allaowed |
| allay |
| allayed |
| allaying |
| allbreath |
| alleged |
| allegiance |
| alleging |
| allegorical |
| allegorically |
| allegories |
| allegory |
| allen |
| alleviate |
| alleviating |
| alleviation |
| alleviations |
| alley |
| alleys |
| alliance |
| alliances |
| allied |
| allies |
| alligator |
| allotted |
| allow |
| allowance |
| allowed |
| allowing |
| alloy |
| allude |
| alluded |
| alludes |
| alluding |
| allure |
| allured |
| allurement |
| allurements |
| alluring |
| allus |
| allusion |
| allusions |
| ally |
| alma |
| almaviva |
| almighty |
| almost |
| alms |
| aloe |
| aloft |
| alone |
| along |
| alongside |
| aloof |
| alos |
| aloud |
| alow |
| alp |
| alpha |
| alphabet |
| alpheus |
| alpine |
| alps |
| already |
| alsatian |
| also |
| altair |
| altar |
| altars |
| alter |
| alteration |
| alterations |
| altercation |
| altered |
| altering |
| alternate |
| alternately |
| alternations |
| alternative |
| alternatives |
| alters |
| although |
| altitude |
| altitudes |
| altogether |
| always |
| am |
| amalthea |
| amassed |
| amateur |
| amativeness |
| amazed |
| amazement |
| amazing |
| amazingly |
| ambaaren |
| ambassador |
| amber |
| ambiguities |
| ambiguity |
| ambiguous |
| ambition |
| ambitious |
| ambois |
| ambrosial |
| ambush |
| amendment |
| amenity |
| america |
| american |
| americana |
| americans |
| ami |
| amiability |
| amiable |
| amicable |
| amicably |
| amicae |
| amid |
| amidst |
| amiss |
| amity |
| ammonia |
| among |
| amongst |
| amontillado |
| amor |
| amorphous |
| amount |
| amounted |
| amounting |
| amounts |
| amour |
| amphibians |
| amphitheatre |
| amphitheatres |
| ample |
| amplitudine |
| amply |
| amriccan |
| amulet |
| amus |
| amuse |
| amused |
| amusement |
| amusements |
| amusing |
| amèrement |
| an |
| ana |
| anacreon |
| anacreontic |
| anadem |
| anaemia |
| anaemic |
| analogical |
| analogies |
| analogous |
| analogy |
| analyse |
| analysed |
| analysing |
| analysis |
| analyst |
| analytic |
| analytical |
| analyze |
| analyzed |
| analyzing |
| anan |
| anarchy |
| anastasia |
| anatomical |
| anatomize |
| anaxagoras |
| ancestor |
| ancestors |
| ancestral |
| ancestry |
| anchises |
| anchor |
| anchorage |
| anchored |
| ancient |
| ancients |
| ancona |
| and |
| andava |
| anderson |
| andes |
| andree |
| andrew |
| andrews |
| andromache |
| andrée |
| anear |
| anecdote |
| anecdotes |
| anemonae |
| anemone |
| anew |
| anfongsgrunde |
| angarola |
| angel |
| angelic |
| angelica |
| angell |
| angelo |
| angels |
| anger |
| angered |
| angle |
| angled |
| angler |
| angles |
| anglican |
| anglo |
| anglois |
| angrily |
| angry |
| anguish |
| angular |
| anician |
| anicius |
| animadversion |
| animadversions |
| animal |
| animals |
| animate |
| animated |
| animating |
| animation |
| animator |
| animosity |
| ankle |
| ankles |
| ann |
| annals |
| annihilate |
| annihilated |
| annihilating |
| annihilation |
| anniversary |
| announce |
| announced |
| announcement |
| announcing |
| annoy |
| annoyance |
| annoyed |
| annoying |
| annoys |
| annual |
| annul |
| annæus |
| anomalies |
| anomalous |
| anomalousness |
| anomaly |
| anon |
| anonymous |
| another |
| answer |
| answered |
| answering |
| answers |
| antagonise |
| antagonist |
| antagonistical |
| antares |
| ante |
| antediluvian |
| antennæ |
| anthill |
| anthony |
| anthropoid |
| anthropological |
| anthropologist |
| anthropologists |
| anthropomorphic |
| anti |
| anticipate |
| anticipated |
| anticipation |
| anticipations |
| anticlimactic |
| antics |
| antidote |
| antient |
| antin |
| antioch |
| antiochus |
| antiparos |
| antipater |
| antipathy |
| antipodes |
| antiquarian |
| antiquarians |
| antiquated |
| antique |
| antiquities |
| antiquity |
| antiquum |
| antlered |
| antoines |
| antoninus |
| ants |
| anxieties |
| anxiety |
| anxious |
| anxiously |
| any |
| anybody |
| anyhaow |
| anyhow |
| anyone |
| anything |
| anyw |
| anywhere |
| anzique |
| anziques |
| aoede |
| aout |
| aoutdoors |
| aoutside |
| apart |
| apartment |
| apartments |
| apathy |
| ape |
| aperture |
| apertures |
| apes |
| apex |
| aphelion |
| aphrodite |
| apicius |
| apocryphal |
| apollo |
| apollonius |
| apologetic |
| apologies |
| apologised |
| apologize |
| apology |
| apophysis |
| apoplexy |
| apostacy |
| apothecary |
| apotheosis |
| apout |
| appalled |
| appalling |
| appallingly |
| appals |
| apparatus |
| apparel |
| apparelled |
| apparent |
| apparently |
| apparition |
| apparitions |
| appeal |
| appealed |
| appealing |
| appeals |
| appear |
| appearance |
| appearances |
| appeared |
| appearing |
| appears |
| appeasing |
| appellation |
| appellations |
| appended |
| appertain |
| appertaining |
| appertains |
| appetite |
| appetites |
| applauded |
| applaudingly |
| applause |
| apple |
| apples |
| appleton |
| appletonians |
| appliances |
| applicable |
| application |
| applicationem |
| applied |
| applies |
| apply |
| applying |
| appoint |
| appointed |
| appointment |
| apportioning |
| appreciable |
| appreciate |
| appreciated |
| appreciation |
| apprehend |
| apprehended |
| apprehension |
| apprehensions |
| apprehensive |
| apprehensively |
| apprehensiveness |
| apprentices |
| apprenticeship |
| apprised |
| approach |
| approached |
| approaches |
| approaching |
| approbation |
| approbatory |
| appropriate |
| appropriated |
| approval |
| approved |
| approximately |
| approximations |
| april |
| apt |
| aqua |
| aquatic |
| aqueous |
| aquiline |
| arab |
| arabella |
| arabesque |
| arabesques |
| arabia |
| arabian |
| arabic |
| arabiscus |
| arago |
| aran |
| araoun |
| araound |
| arbitrary |
| arbours |
| arc |
| arcaded |
| arcades |
| arcadia |
| arcadian |
| arcadians |
| arcana |
| arch |
| archaeological |
| archaeologists |
| archaeology |
| archaic |
| archaism |
| archangel |
| archangels |
| arched |
| archer |
| arches |
| archimedean |
| archipelago |
| architect |
| architects |
| architectural |
| architecture |
| archives |
| archon |
| archons |
| archway |
| archways |
| archytas |
| arctic |
| arcturus |
| ardent |
| ardently |
| ardois |
| ardor |
| ardour |
| ardours |
| arduous |
| are |
| area |
| areas |
| argo |
| argosies |
| argostino |
| argue |
| argued |
| argues |
| argument |
| argumentative |
| arguments |
| argumentum |
| argyropylo |
| aria |
| arianus |
| aricina |
| arid |
| aries |
| aright |
| ariosto |
| arise |
| arisen |
| arises |
| arising |
| aristocracy |
| aristocratical |
| aristocrats |
| aristotelian |
| arithmetic |
| arithmetical |
| arkham |
| arly |
| arm |
| armada |
| armands |
| armed |
| armenian |
| armies |
| armington |
| armitage |
| armlets |
| armorial |
| armory |
| armour |
| arms |
| army |
| arnheim |
| aromatic |
| arose |
| around |
| arount |
| arouse |
| aroused |
| arousing |
| arpino |
| arrang |
| arrange |
| arranged |
| arrangement |
| arrangements |
| arranges |
| arranging |
| arrant |
| array |
| arraying |
| arrest |
| arrested |
| arrests |
| arrises |
| arrival |
| arrivals |
| arrive |
| arrived |
| arrives |
| arriving |
| arrogance |
| arrogant |
| arrogate |
| arrogated |
| arrondees |
| arrow |
| arrows |
| arrowy |
| art |
| artemis |
| arter |
| arteries |
| artful |
| arth |
| arthur |
| article |
| articles |
| articulate |
| articulation |
| articulations |
| articulo |
| artifice |
| artifices |
| artificial |
| artificiality |
| artificially |
| artillery |
| artisan |
| artist |
| artistic |
| artistical |
| artistically |
| artists |
| artless |
| artlessness |
| arts |
| arve |
| arveiron |
| aryan |
| as |
| asaph |
| asbestic |
| asbury |
| ascend |
| ascendancy |
| ascended |
| ascending |
| ascension |
| ascensions |
| ascent |
| ascertain |
| ascertained |
| ascertaining |
| ascribe |
| ascribed |
| asellius |
| ashamed |
| ashen |
| ashes |
| ashimah |
| ashore |
| ashton |
| ashtophet |
| ashtoreth |
| ashy |
| asia |
| asiatic |
| asiatics |
| aside |
| ask |
| asked |
| asking |
| asks |
| asleep |
| aspect |
| aspects |
| asperation |
| asperities |
| asperity |
| asphodel |
| asphodels |
| asphytic |
| aspic |
| aspirant |
| aspirants |
| aspiration |
| aspirations |
| aspire |
| aspired |
| aspires |
| aspiring |
| ass |
| assailants |
| assailed |
| assassin |
| assassinated |
| assassination |
| assassins |
| assault |
| assaulted |
| assaulting |
| assemblage |
| assemblages |
| assemble |
| assembled |
| assemblies |
| assembly |
| assent |
| assented |
| assert |
| asserted |
| asserting |
| assertion |
| assertions |
| asserts |
| asses |
| asseverations |
| assiduity |
| assiduous |
| assiduousness |
| assign |
| assignable |
| assigned |
| assist |
| assistance |
| assistant |
| assistants |
| assisted |
| assisting |
| assists |
| assizes |
| associate |
| associated |
| associates |
| association |
| associations |
| assoilzie |
| assorted |
| assume |
| assumed |
| assumes |
| assuming |
| assumption |
| assumptions |
| assurance |
| assurances |
| assure |
| assured |
| assuredly |
| assurement |
| assures |
| assuring |
| ast |
| astarte |
| astern |
| asteroids |
| asthma |
| astonish |
| astonished |
| astonishing |
| astonishingly |
| astonishment |
| astoreth |
| astound |
| astounded |
| astounding |
| astoundingly |
| astride |
| astrologer |
| astrologers |
| astronomer |
| astronomers |
| astronomical |
| astronomy |
| astute |
| astuteness |
| asunder |
| asylum |
| asymmetrical |
| at |
| atal |
| atalantic |
| atavism |
| ate |
| athenian |
| athenians |
| athens |
| athib |
| athok |
| athos |
| athwart |
| atlantic |
| atlantis |
| atmosphere |
| atmospheric |
| atom |
| atomic |
| atoms |
| atoned |
| atop |
| atrocious |
| atrocities |
| atrocity |
| atrophied |
| atrée |
| attach |
| attached |
| attaching |
| attachment |
| attachés |
| attack |
| attacked |
| attacker |
| attacking |
| attacks |
| attain |
| attainable |
| attained |
| attaining |
| attainment |
| attainments |
| attains |
| attempt |
| attempted |
| attempting |
| attempts |
| attend |
| attendance |
| attendant |
| attendants |
| attended |
| attending |
| attends |
| attention |
| attentions |
| attentive |
| attentively |
| attenuated |
| attest |
| attested |
| attic |
| attica |
| attics |
| atticus |
| attire |
| attired |
| attitude |
| attorney |
| attract |
| attracted |
| attracting |
| attraction |
| attractions |
| attractive |
| attracts |
| attributable |
| attribute |
| attributed |
| attributes |
| attributing |
| attuned |
| atween |
| au |
| auckland |
| audacities |
| audacity |
| audible |
| audibly |
| audience |
| audiences |
| audient |
| auditor |
| auditors |
| auditory |
| aug |
| aught |
| augment |
| augmented |
| augmenting |
| augury |
| august |
| augustan |
| auguste |
| augustus |
| aunt |
| auoir |
| aural |
| aurelius |
| aureole |
| auriclas |
| auriculas |
| auriferous |
| aurora |
| auseil |
| auspices |
| auspiciously |
| aussi |
| austere |
| austin |
| austria |
| austrian |
| authentic |
| authenticated |
| authenticity |
| authentick |
| author |
| authorities |
| authority |
| authors |
| authorship |
| autobiography |
| autocrats |
| autograph |
| automata |
| automatic |
| automatically |
| automatics |
| automatism |
| automaton |
| automobile |
| autos |
| autres |
| autumn |
| autumnal |
| avail |
| availability |
| available |
| availed |
| availing |
| avalanche |
| avarice |
| avaricious |
| avaunt |
| ave |
| avenge |
| avenger |
| avenue |
| avenues |
| aver |
| average |
| averills |
| averni |
| averred |
| averring |
| averse |
| aversion |
| avert |
| averted |
| avid |
| avidity |
| avidly |
| avisson |
| avitus |
| avoid |
| avoidable |
| avoided |
| avoiding |
| avoirdupois |
| avowedly |
| await |
| awaited |
| awaiting |
| awaits |
| awake |
| awaked |
| awaken |
| awakened |
| awakeners |
| awakening |
| awakens |
| awaking |
| aware |
| away |
| awe |
| awed |
| awesome |
| awesomely |
| awestruck |
| awful |
| awhile |
| awkward |
| awkwardly |
| awkwardness |
| awoke |
| awry |
| axe |
| axiomatic |
| axioms |
| axis |
| ay |
| aye |
| aylesbury |
| azathoth |
| azazel |
| azrael |
| azure |
| aërial |
| aërially |
| aëroplane |
| babble |
| babbled |
| babcock |
| babe |
| babel |
| babes |
| babies |
| baboon |
| baboons |
| babson |
| baby |
| babylon |
| babylonian |
| babylonish |
| bacchanalia |
| bacchanalian |
| bacchanalibus |
| bacchanals |
| bachelor |
| back |
| backed |
| background |
| backgrounds |
| backs |
| backward |
| backwards |
| backwaters |
| backwoods |
| bacon |
| baconian |
| bad |
| bade |
| badly |
| baffle |
| baffled |
| bafflement |
| baffles |
| baffling |
| bag |
| baggage |
| baggy |
| bagpipes |
| bags |
| bah |
| baiae |
| bail |
| baissée |
| baked |
| baker |
| bakery |
| baking |
| balance |
| balanced |
| balancing |
| balbutius |
| balconies |
| bald |
| balderdash |
| baldly |
| baleful |
| balefully |
| bales |
| balkin |
| ball |
| ballad |
| ballast |
| ballasted |
| ballet |
| balloon |
| balloons |
| ballots |
| balls |
| ballylough |
| balm |
| balmy |
| balustrade |
| balustraded |
| bamboozled |
| ban |
| banana |
| band |
| bandage |
| bandaged |
| bandages |
| banded |
| bands |
| bane |
| bangus |
| banish |
| banished |
| banishment |
| bank |
| banker |
| bankers |
| bankrupt |
| banks |
| banner |
| banners |
| banof |
| banquet |
| banqueting |
| banter |
| baound |
| baptism |
| baptismal |
| baptist |
| baptiste |
| bar |
| barac |
| barb |
| barbarian |
| barbarians |
| barbaric |
| barbarism |
| barbarity |
| barbarous |
| barbarously |
| barber |
| barca |
| barclay |
| bard |
| bare |
| bared |
| barefoot |
| bareheaded |
| barely |
| barest |
| bargain |
| bargaining |
| barge |
| bargeman |
| bargemen |
| bark |
| barked |
| barkentine |
| barkin |
| barking |
| barkings |
| barks |
| barlow |
| barn |
| barnabas |
| barnacles |
| barnard |
| barometer |
| barometers |
| baron |
| baronet |
| barons |
| barred |
| barrel |
| barrels |
| barren |
| barrenness |
| barricade |
| barricaded |
| barricades |
| barricading |
| barrier |
| barriers |
| barring |
| barrière |
| barroom |
| barroques |
| barry |
| bars |
| bartender |
| bartholinus |
| bartholomew |
| barzai |
| bas |
| basalt |
| base |
| based |
| baseless |
| basement |
| bases |
| basest |
| bashful |
| bashfulness |
| basic |
| basically |
| basis |
| basked |
| basket |
| bass |
| bassianus |
| basso |
| bat |
| batavia |
| bates |
| bath |
| bathe |
| bathed |
| bathing |
| bathroom |
| baths |
| batrachian |
| bats |
| battalions |
| batten |
| batter |
| battered |
| batteries |
| battering |
| battery |
| battle |
| battled |
| battlefield |
| battlement |
| battlements |
| battles |
| battleship |
| battling |
| baulked |
| bawled |
| bawling |
| bay |
| bayed |
| baying |
| bayonet |
| be |
| beach |
| beaches |
| beacon |
| beacons |
| beaded |
| beads |
| beak |
| beam |
| beamed |
| beaming |
| beams |
| beant |
| bear |
| bearable |
| beard |
| bearded |
| beardless |
| bearer |
| bearers |
| bearin |
| bearing |
| bearings |
| bears |
| beast |
| beasts |
| beat |
| beaten |
| beati |
| beatified |
| beatin |
| beating |
| beatings |
| beatitude |
| beau |
| beauclerk |
| beaufort |
| beauteous |
| beauties |
| beautiful |
| beautifully |
| beauty |
| beauvais |
| beaver |
| beavers |
| became |
| because |
| beckon |
| beckoned |
| beckoning |
| beckons |
| become |
| becomes |
| becoming |
| becomingly |
| bed |
| bedchamber |
| bedclothes |
| bedecked |
| bedewed |
| bedizzened |
| bedlo |
| bedloe |
| bedraggled |
| beds |
| bedside |
| bedstead |
| bee |
| beech |
| beef |
| beefsteak |
| beelzebub |
| been |
| beer |
| bees |
| beetle |
| beetling |
| befall |
| befallen |
| befell |
| befitted |
| befitting |
| before |
| befouled |
| befriended |
| befriends |
| beg |
| began |
| beggar |
| beggary |
| begged |
| begging |
| begin |
| beginnin |
| beginning |
| begins |
| begirt |
| begone |
| begotten |
| begs |
| beguile |
| beguiled |
| begun |
| behalf |
| behave |
| behaved |
| behaving |
| behavior |
| behaviour |
| beheld |
| behemoth |
| behind |
| behold |
| beholder |
| beholding |
| beholds |
| bein |
| being |
| beings |
| bel |
| belated |
| belay |
| belching |
| beldame |
| belfast |
| belfries |
| belfry |
| belgian |
| belial |
| belied |
| belief |
| beliefs |
| believe |
| believed |
| believes |
| believing |
| belisarius |
| bell |
| belles |
| bellini |
| bellissima |
| bellowing |
| bellowings |
| bellows |
| bells |
| belong |
| belonged |
| belonging |
| belongs |
| beloved |
| below |
| belphegor |
| belrive |
| belt |
| belted |
| belts |
| ben |
| benares |
| bench |
| benches |
| bend |
| bendin |
| bending |
| bendis |
| bends |
| beneath |
| benefactor |
| benefactors |
| beneficence |
| beneficent |
| beneficial |
| benefit |
| benefited |
| benefits |
| benevolence |
| benevolent |
| benevolently |
| bengalee |
| benighted |
| benign |
| benignant |
| benignity |
| benijah |
| benjamin |
| bennett |
| bent |
| bentham |
| bentinck |
| bentley |
| bepuffed |
| bequeath |
| bequeathed |
| bequest |
| berating |
| bereavement |
| berenice |
| berenices |
| berkeley |
| berkshire |
| berlifitzing |
| berlin |
| berries |
| berry |
| berth |
| berths |
| beryl |
| beseamed |
| beseech |
| beset |
| beside |
| besides |
| besieged |
| besiegers |
| besieging |
| besmeared |
| besotted |
| besought |
| bespeak |
| bespeaks |
| bespoke |
| besprinkled |
| bess |
| bessop |
| best |
| bestial |
| bestiality |
| bestir |
| bestow |
| bestowed |
| bestowing |
| bestows |
| bestrode |
| bet |
| betake |
| betaken |
| bethlehem |
| bethought |
| bethumbed |
| betide |
| betokened |
| betook |
| betray |
| betrayal |
| betrayed |
| betrayer |
| betraying |
| betrays |
| betrothed |
| better |
| between |
| betwixt |
| beverage |
| bewailed |
| beware |
| bewilder |
| bewildered |
| bewildering |
| bewilderingly |
| bewilderment |
| bewitched |
| bewitching |
| bewitchingly |
| beyond |
| beyont |
| beëlzebub |
| bi |
| bias |
| biassed |
| bible |
| bibliographical |
| bibliotheca |
| bickering |
| bicknell |
| bicycle |
| bid |
| bidden |
| bidding |
| bids |
| bienseance |
| bienville |
| bier |
| big |
| bigger |
| bignonia |
| bigoted |
| bilge |
| bill |
| billets |
| billiards |
| billowed |
| billows |
| bills |
| bin |
| binary |
| bind |
| binder |
| binding |
| binds |
| binoculars |
| biochemical |
| biography |
| biological |
| biologically |
| birch |
| bird |
| birds |
| biron |
| birth |
| birthday |
| birthplace |
| bisected |
| bishop |
| bishopgate |
| bishops |
| bismuth |
| bison |
| bit |
| bite |
| biting |
| bits |
| bitten |
| bitter |
| bitterest |
| bitterly |
| bitterness |
| bitumen |
| bivalve |
| bivouac |
| bixby |
| bizarre |
| bizarrerie |
| blab |
| black |
| blacken |
| blackened |
| blackening |
| blacker |
| blackest |
| blackguard |
| blackguards |
| blacking |
| blackly |
| blackness |
| blacksmith |
| blackwood |
| bladder |
| bladders |
| blade |
| blades |
| blame |
| blamed |
| blameless |
| blaming |
| blanc |
| bland |
| blandot |
| blank |
| blanket |
| blankets |
| blankly |
| blankness |
| blanks |
| blaspheme |
| blasphemies |
| blasphemous |
| blasphemy |
| blast |
| blasted |
| blasting |
| blasts |
| blaze |
| blazed |
| blazing |
| blazingly |
| bleached |
| bleak |
| bleakness |
| bleatin |
| bleating |
| bleeding |
| blemish |
| blemished |
| blenching |
| blend |
| blended |
| bless |
| blessed |
| blessing |
| blessings |
| bleu |
| bleus |
| blew |
| blieve |
| blight |
| blighted |
| blighting |
| blights |
| blind |
| blinded |
| blinding |
| blindly |
| blindness |
| blink |
| blinked |
| blinking |
| bliss |
| blissful |
| blissfully |
| blitzen |
| bloated |
| block |
| blockading |
| blocked |
| blocks |
| blond |
| blood |
| blooded |
| bloodless |
| bloodshed |
| bloodthirstiness |
| bloodthirsty |
| bloody |
| bloom |
| bloomed |
| blooming |
| blossom |
| blossoming |
| blossoms |
| blot |
| blots |
| blotted |
| blotting |
| blouse |
| blow |
| blowed |
| blowing |
| blown |
| blows |
| bluddennuff |
| blue |
| blueberry |
| blueness |
| bluff |
| bluish |
| blunder |
| blunderbuss |
| blunderbuzzard |
| blundering |
| blunt |
| blunting |
| bluntly |
| blur |
| blurred |
| blush |
| blushed |
| blushing |
| bluster |
| bnazic |
| boar |
| board |
| boarded |
| boarder |
| boarders |
| boarding |
| boards |
| boast |
| boasted |
| boat |
| boatman |
| boats |
| boatswain |
| bob |
| bobbing |
| bobby |
| bobolink |
| boccaccio |
| boded |
| bodies |
| bodiless |
| bodily |
| boding |
| body |
| boethius |
| bog |
| bogs |
| bohm |
| boiled |
| boiling |
| boils |
| bois |
| boisterous |
| boisterously |
| bold |
| bolder |
| boldly |
| boldness |
| bolstered |
| bolt |
| bolted |
| bolter |
| bolting |
| bolton |
| bolts |
| bombardment |
| bombastes |
| bombay |
| bombshell |
| bon |
| bona |
| bonaparte |
| bond |
| bondage |
| bonds |
| bone |
| boned |
| bones |
| bonfire |
| bonfires |
| bonne |
| bonnet |
| bonneted |
| bonnot |
| bony |
| book |
| booked |
| books |
| bookseller |
| bookshelves |
| boom |
| booming |
| booms |
| boon |
| boons |
| boosed |
| boot |
| booted |
| bootleg |
| boots |
| booty |
| booze |
| border |
| bordered |
| bordering |
| borders |
| bore |
| borealis |
| bored |
| boredom |
| borghese |
| boring |
| born |
| borne |
| borneo |
| bornese |
| borough |
| borrow |
| borrowed |
| borrows |
| bosom |
| bosoms |
| bossieux |
| bossuet |
| boston |
| boswell |
| bosworth |
| bot |
| botanical |
| both |
| bother |
| bothered |
| bottle |
| bottles |
| bottom |
| bottomed |
| bottomless |
| bottoms |
| bouche |
| boudoir |
| bouffon |
| bough |
| boughs |
| bought |
| bouleversement |
| boullard |
| boulogne |
| bound |
| boundaries |
| boundary |
| bounded |
| bounding |
| boundless |
| boundlessly |
| bounds |
| bounteous |
| bounty |
| bouquets |
| bourdon |
| bourne |
| bout |
| bouts |
| bovine |
| bow |
| bowed |
| bowels |
| bowen |
| bower |
| bowers |
| bowing |
| bowl |
| bows |
| box |
| boxed |
| boxes |
| boxing |
| boy |
| boyhood |
| boyish |
| boys |
| boz |
| bozzy |
| braced |
| bracelet |
| braces |
| bracing |
| brackets |
| braggadocio |
| braided |
| brain |
| brainless |
| brains |
| brake |
| brambles |
| branch |
| branches |
| brand |
| branded |
| brandished |
| brandy |
| bransby |
| bras |
| brass |
| brat |
| brava |
| bravado |
| brave |
| bravely |
| bravery |
| bravest |
| bravo |
| brawl |
| brawling |
| brawls |
| brawny |
| braying |
| breach |
| breaches |
| bread |
| breadth |
| break |
| breakers |
| breakfast |
| breaking |
| breakless |
| breaks |
| breakwater |
| breast |
| breastplate |
| breasts |
| breath |
| breathe |
| breathed |
| breathes |
| breathin |
| breathing |
| breathings |
| breathless |
| breathlessly |
| bred |
| breeches |
| breed |
| breedin |
| breeding |
| breeds |
| breeng |
| breeze |
| breezes |
| breezy |
| bremen |
| brethren |
| breton |
| brevet |
| brewer |
| brewing |
| brewster |
| bribe |
| brick |
| bricks |
| brickwork |
| bridal |
| bride |
| briden |
| bridge |
| bridged |
| bridges |
| bridled |
| brief |
| briefest |
| briefly |
| brier |
| briers |
| brig |
| brigadier |
| bright |
| brightened |
| brighter |
| brightest |
| brightholme |
| brightholmes |
| brightly |
| brightness |
| brilliance |
| brilliancy |
| brilliant |
| brilliantly |
| brim |
| brimful |
| brimmed |
| brimming |
| brine |
| bring |
| bringhurst |
| bringin |
| bringing |
| brings |
| brink |
| brisk |
| brisker |
| briskly |
| bristled |
| bristles |
| bristly |
| bristol |
| britain |
| britannia |
| british |
| britons |
| broach |
| broached |
| broad |
| broadcloth |
| broader |
| broadest |
| broadway |
| brobdignag |
| brobdignagians |
| brocade |
| brochures |
| broglio |
| broils |
| broke |
| broken |
| bronze |
| brood |
| brooded |
| brooding |
| brook |
| brooks |
| brother |
| brotherhood |
| brotherly |
| brothers |
| brougham |
| brought |
| brow |
| browed |
| brown |
| browne |
| brownish |
| brownson |
| brownstone |
| brows |
| browsing |
| bruise |
| bruised |
| bruises |
| bruited |
| brun |
| bruna |
| brung |
| brunswick |
| brush |
| brushed |
| brushes |
| brushing |
| brusquerie |
| brutal |
| brutality |
| brute |
| brutish |
| brutus |
| bry |
| bryant |
| brève |
| bubastis |
| bubble |
| bubbled |
| bubbles |
| bubbling |
| bucket |
| buckholm |
| buckingham |
| buckle |
| buckled |
| bucks |
| buckskin |
| bud |
| budding |
| buds |
| buffeted |
| buffon |
| buffoon |
| buffooneries |
| buffoons |
| bug |
| bugaboo |
| bugbears |
| bugs |
| build |
| builded |
| builders |
| buildin |
| building |
| buildings |
| built |
| bulge |
| bulged |
| bulgin |
| bulging |
| bulk |
| bulkhead |
| bulky |
| bull |
| bullet |
| bulletin |
| bulls |
| bulwarks |
| bulwer |
| bump |
| bumper |
| bumpkin |
| bunch |
| bundle |
| bungalow |
| bungled |
| bunk |
| bunkhouse |
| bunsen |
| buoy |
| buoyant |
| buoyantly |
| buoyed |
| buoys |
| buppy |
| burden |
| burdens |
| bureau |
| buren |
| burgesses |
| burghers |
| burgomaster |
| burial |
| burials |
| buried |
| buries |
| burke |
| burn |
| burned |
| burner |
| burney |
| burning |
| burnished |
| burns |
| burnt |
| burr |
| burrow |
| burrowers |
| burrows |
| burst |
| bursting |
| bursts |
| burthen |
| burthened |
| burthening |
| burthensome |
| bury |
| burying |
| bus |
| bush |
| bushes |
| bushiness |
| bushy |
| busied |
| busier |
| busies |
| busily |
| business |
| buskin |
| bussy |
| bust |
| bustle |
| bustled |
| busts |
| busy |
| busying |
| but |
| butcher |
| butcheries |
| butchery |
| butefulle |
| butler |
| butt |
| butter |
| buttercup |
| butterflies |
| butterfly |
| button |
| buttoned |
| buttons |
| buttresses |
| buy |
| buyers |
| buying |
| buzrael |
| buzz |
| buzzards |
| bxg |
| bxw |
| bxwl |
| by |
| bye |
| bygone |
| byron |
| bystanders |
| byway |
| byzantine |
| bête |
| bêtenoir |
| ca |
| cab |
| cabal |
| cabalistic |
| cabalistical |
| cabbage |
| cabbaged |
| cabbages |
| cabin |
| cabinet |
| cabins |
| cable |
| cabling |
| caboose |
| cabriolet |
| cachinnation |
| cacophony |
| cactus |
| cadaverous |
| cadaverousness |
| cadence |
| cadet |
| caesar |
| cafeteria |
| cafeterias |
| caff |
| café |
| cage |
| cahoone |
| cain |
| caius |
| cajoled |
| caked |
| cakes |
| calagurris |
| calais |
| calamities |
| calamitous |
| calamity |
| calc |
| calculate |
| calculated |
| calculating |
| calculation |
| calculations |
| calculus |
| calcutta |
| calderon |
| calendar |
| calendars |
| calf |
| california |
| caligula |
| call |
| callao |
| called |
| callers |
| callin |
| calling |
| callous |
| calloused |
| callousness |
| calls |
| calm |
| calmed |
| calmer |
| calmest |
| calming |
| calmly |
| calmness |
| caloric |
| calvary |
| calves |
| cambric |
| cambridge |
| came |
| camel |
| cameleopard |
| cameleopards |
| camels |
| camera |
| camillus |
| camorin |
| camp |
| campaign |
| campaigning |
| campanella |
| campanian |
| camped |
| campfires |
| camphor |
| campi |
| camps |
| campus |
| camus |
| can |
| canaan |
| canadian |
| canal |
| canaries |
| cancale |
| cancel |
| cancelled |
| candelabra |
| candelabrum |
| candid |
| candidate |
| candidates |
| candle |
| candlelight |
| candlemas |
| candles |
| candlestick |
| candlesticks |
| candor |
| candour |
| candy |
| cane |
| canine |
| canisters |
| cannibal |
| cannibals |
| cannon |
| canoe |
| canonchet |
| canopy |
| canst |
| canteen |
| canteens |
| canto |
| canvas |
| canvass |
| canvasser |
| canyon |
| caoutchouc |
| caows |
| cap |
| capabilities |
| capability |
| capable |
| capacious |
| capacities |
| capacity |
| caparisoned |
| cape |
| capella |
| capered |
| capers |
| capital |
| capitals |
| capitol |
| capitulate |
| capitulated |
| capon |
| cappadocia |
| capped |
| caprice |
| caprices |
| capricious |
| capricornutti |
| caps |
| capsize |
| capt |
| captain |
| captains |
| captious |
| captivating |
| captive |
| captivity |
| captors |
| capture |
| captured |
| capuletti |
| caput |
| capwell |
| car |
| caracols |
| caravaggio |
| caravan |
| caravans |
| carboy |
| carboys |
| carbuncle |
| carcase |
| carcass |
| carcasses |
| card |
| cardboard |
| carded |
| cards |
| care |
| cared |
| career |
| careered |
| careering |
| careful |
| carefully |
| careless |
| carelessly |
| carelessness |
| cares |
| caress |
| caressed |
| caresses |
| caressing |
| careworn |
| cargo |
| cargoes |
| caricature |
| caricatures |
| carnage |
| carne |
| carnival |
| carnivorous |
| carolina |
| carolines |
| carousal |
| carousals |
| carpaccio |
| carpentry |
| carpet |
| carpeted |
| carpets |
| carriage |
| carriages |
| carried |
| carrier |
| carries |
| carrington |
| carry |
| carryin |
| carrying |
| cart |
| carted |
| cartel |
| carter |
| cartes |
| carthaginian |
| cartilaginous |
| carting |
| cartoonist |
| carts |
| carve |
| carved |
| carven |
| carvers |
| carvin |
| carving |
| carvings |
| case |
| casement |
| casements |
| cases |
| cash |
| cashmere |
| cask |
| casket |
| casks |
| caspian |
| cassiopeia |
| cast |
| castes |
| casting |
| castle |
| castles |
| castor |
| castors |
| castro |
| casts |
| casual |
| casually |
| casualness |
| casualties |
| casualty |
| cat |
| cataclysm |
| cataclysmic |
| catacomb |
| catacombs |
| catalani |
| catalepsy |
| cataleptic |
| cataleptical |
| catalogue |
| catalpa |
| catalpas |
| catapult |
| cataract |
| cataracts |
| catastrophe |
| catch |
| catching |
| catechise |
| catechism |
| categories |
| category |
| caterwauled |
| caterwauling |
| cathedral |
| catholic |
| cathuria |
| cats |
| catskill |
| catskills |
| cattle |
| caucasian |
| caude |
| caught |
| cauldron |
| cauliflowers |
| causation |
| cause |
| caused |
| causeless |
| causes |
| causeway |
| causing |
| caustic |
| caution |
| cautioned |
| cautious |
| cautiously |
| cautiousness |
| cavalcade |
| cavalier |
| cavalry |
| cave |
| caved |
| cavern |
| cavernous |
| caverns |
| caves |
| cavil |
| cavin |
| caving |
| cavities |
| cavity |
| cawed |
| cawing |
| cayley |
| cc |
| ce |
| cease |
| ceased |
| ceaseless |
| ceaselessly |
| ceases |
| ceasing |
| cecila |
| ceiled |
| ceiling |
| ceilings |
| celebrants |
| celebrate |
| celebrated |
| celebrating |
| celebration |
| celebrity |
| celephaïs |
| celerity |
| celestial |
| cell |
| cellar |
| cellars |
| cells |
| cellular |
| celt |
| celtiberian |
| cement |
| cemented |
| cemeteries |
| cemetery |
| cenotaphs |
| censer |
| censers |
| censure |
| censured |
| censures |
| cent |
| center |
| centipede |
| central |
| centre |
| centred |
| centres |
| centrifugal |
| centripetal |
| cents |
| centumcellae |
| centuried |
| centuries |
| centuriones |
| century |
| cepheus |
| cerebral |
| cerements |
| ceremonial |
| ceremonies |
| ceremoniously |
| ceremony |
| ceres |
| certain |
| certainly |
| certainty |
| certificates |
| certum |
| cerulean |
| cervantes |
| cessation |
| cessations |
| cet |
| cetacean |
| cetera |
| cette |
| cf |
| cha |
| chad |
| chafed |
| chagrin |
| chagrined |
| chain |
| chained |
| chains |
| chair |
| chairman |
| chairs |
| chaise |
| chalcedony |
| chaldee |
| chalk |
| chalking |
| challenge |
| chamber |
| chambers |
| chambertin |
| chambre |
| chamier |
| chamois |
| chamounix |
| champagne |
| champion |
| chan |
| chance |
| chanced |
| chances |
| chandelier |
| change |
| changed |
| changeful |
| changeless |
| changes |
| changeth |
| changing |
| channel |
| channels |
| channing |
| chant |
| chanted |
| chantilly |
| chanting |
| chants |
| chaos |
| chaotic |
| chap |
| chapeau |
| chaplet |
| chapman |
| chapter |
| chapters |
| character |
| characterised |
| characteristic |
| characteristically |
| characteristics |
| characterization |
| characterize |
| characterized |
| characterizes |
| characters |
| charactery |
| charcoal |
| charge |
| charged |
| charger |
| chargers |
| charges |
| charging |
| charioted |
| chariots |
| charitable |
| charities |
| charity |
| charlatanerie |
| charlemagne |
| charles |
| charleston |
| charlottesville |
| charm |
| charming |
| charmion |
| charms |
| charnel |
| charred |
| chart |
| charter |
| chartreuse |
| charts |
| chase |
| chased |
| chasm |
| chasms |
| chassez |
| chastened |
| chastity |
| chat |
| chateau |
| chateaubriand |
| chatted |
| chatter |
| chattered |
| chattering |
| chauncey |
| chaussée |
| che |
| cheap |
| cheat |
| cheats |
| check |
| checked |
| checking |
| cheek |
| cheeked |
| cheeks |
| cheer |
| cheered |
| cheerful |
| cheerfully |
| cheerfulness |
| cheerily |
| cheering |
| cheerless |
| cheers |
| cheese |
| chemical |
| chemically |
| chemicals |
| chemin |
| chemist |
| chemistry |
| chemists |
| chequered |
| cher |
| cherish |
| cherished |
| cherishing |
| cherry |
| cherub |
| chess |
| chessboard |
| chessmen |
| chest |
| chesterfield |
| chestnut |
| chestnuts |
| chests |
| chevalier |
| chewed |
| chez |
| chi |
| chian |
| chicago |
| chichester |
| chicken |
| chickens |
| chided |
| chief |
| chiefest |
| chiefly |
| chiefs |
| chien |
| child |
| childe |
| childhood |
| childish |
| childishly |
| childishness |
| childless |
| children |
| chill |
| chilled |
| chilliness |
| chilling |
| chills |
| chilly |
| chimaeras |
| chimbly |
| chime |
| chimed |
| chimera |
| chimeras |
| chimerical |
| chimes |
| chiming |
| chimney |
| chimneys |
| chimpanzees |
| chin |
| china |
| chinamen |
| chinese |
| chink |
| chinks |
| chinless |
| chinlessness |
| chinned |
| chip |
| chiponchipino |
| chipped |
| chippendale |
| chiromancy |
| chirp |
| chirurgical |
| chisel |
| chiseled |
| chiselled |
| chiselling |
| chisels |
| chittering |
| chivalrous |
| chivalry |
| chloride |
| cho |
| choaked |
| choaking |
| choctaw |
| choctaws |
| choice |
| choicest |
| choke |
| choked |
| choking |
| choler |
| choose |
| chooses |
| choosing |
| chopped |
| chopping |
| choppy |
| chops |
| chord |
| chords |
| choristers |
| chorum |
| chorus |
| chose |
| chosen |
| choynski |
| chris |
| christchurch |
| christendom |
| christened |
| christi |
| christian |
| christiana |
| christianity |
| christians |
| christmas |
| christopher |
| chronic |
| chronicle |
| chronicler |
| chrysalis |
| chrysolite |
| chuckle |
| chuckled |
| chuckling |
| church |
| churches |
| churchly |
| churchyard |
| churchyards |
| churn |
| churning |
| chymist |
| château |
| cicale |
| cicero |
| ciceronian |
| cimabue |
| cimabué |
| cincinnatus |
| cinctured |
| cinema |
| cinna |
| cinnamon |
| cipher |
| ciphers |
| circle |
| circled |
| circles |
| circuit |
| circuitous |
| circuitously |
| circular |
| circulated |
| circulates |
| circulation |
| circulatory |
| circumambient |
| circumference |
| circumgyratory |
| circumjacent |
| circumlocution |
| circumscribing |
| circumstance |
| circumstanced |
| circumstances |
| circumstantial |
| circus |
| citadel |
| citation |
| citations |
| cities |
| citing |
| citizen |
| citizens |
| city |
| civic |
| civil |
| civilian |
| civilisation |
| civilised |
| civilities |
| civility |
| civilization |
| civilize |
| civilized |
| clad |
| claim |
| claimant |
| claimed |
| claims |
| clambered |
| clamminess |
| clammy |
| clamor |
| clamored |
| clamorer |
| clamorously |
| clamour |
| clams |
| clandestinely |
| clang |
| clangor |
| clangorous |
| clangour |
| clanking |
| clannish |
| clapboarded |
| clapham |
| clapped |
| clara |
| clare |
| clark |
| clashed |
| clashes |
| clasp |
| clasped |
| clasping |
| clasps |
| class |
| classes |
| classic |
| classical |
| classically |
| classified |
| classify |
| classifying |
| clatter |
| clattered |
| clattering |
| claude |
| claudianus |
| claudius |
| claw |
| clawed |
| clawing |
| claws |
| clay |
| clean |
| cleaned |
| cleanest |
| cleaning |
| cleanliness |
| cleanly |
| clear |
| cleared |
| clearer |
| clearest |
| clearing |
| clearly |
| clearness |
| cleavage |
| cleaves |
| cleaving |
| cleft |
| cleis |
| clematis |
| clemency |
| clenched |
| cleomenes |
| clergyman |
| clergymen |
| clerical |
| clerically |
| clerics |
| clerk |
| clerval |
| cleveland |
| clever |
| cleverly |
| cleverness |
| clew |
| clicking |
| clientele |
| cliff |
| cliffs |
| cliffside |
| climate |
| climax |
| climb |
| climbed |
| climber |
| climbing |
| climbs |
| clime |
| climes |
| clinched |
| cling |
| clinging |
| clings |
| clinic |
| clipt |
| cloak |
| cloaked |
| cloaks |
| cloathing |
| clock |
| clocks |
| clod |
| clogged |
| cloister |
| clombe |
| clos |
| close |
| closed |
| closely |
| closeness |
| closer |
| closes |
| closest |
| closet |
| closets |
| closing |
| clost |
| cloth |
| clothe |
| clothed |
| clothes |
| clothing |
| clotted |
| cloud |
| clouded |
| cloudiness |
| clouding |
| cloudless |
| clouds |
| cloudy |
| clout |
| cloven |
| clown |
| club |
| clubs |
| clue |
| clues |
| clump |
| clumps |
| clumsily |
| clumsy |
| clung |
| cluster |
| clustered |
| clustering |
| clusters |
| clutch |
| clutched |
| clutches |
| clutching |
| co |
| coach |
| coaches |
| coadjutor |
| coadjutors |
| coal |
| coalescence |
| coals |
| coarse |
| coarser |
| coarsest |
| coast |
| coastmen |
| coat |
| coated |
| coating |
| coats |
| cobbled |
| cobbler |
| cobblestones |
| cobwebbed |
| cobwebs |
| cock |
| cocking |
| cocoa |
| cod |
| code |
| coelius |
| coffee |
| coffer |
| coffin |
| coffins |
| cognizance |
| cognizant |
| cognomen |
| cognoscenti |
| coherence |
| coherent |
| cohort |
| coil |
| coiled |
| coin |
| coinage |
| coincidence |
| coincidences |
| coincident |
| coins |
| coke |
| col |
| cold |
| colder |
| coldest |
| coldly |
| coldness |
| coleridge |
| collapsed |
| collapsing |
| collar |
| collate |
| collated |
| collateral |
| collation |
| colleague |
| colleagues |
| collect |
| collected |
| collecting |
| collection |
| collectively |
| collector |
| colledge |
| college |
| colleges |
| collegians |
| collegiate |
| collegiates |
| collide |
| collie |
| collins |
| collision |
| collocation |
| collocations |
| colloquial |
| colloquies |
| colloquy |
| collusion |
| cologne |
| colonel |
| colonial |
| colonies |
| colonists |
| colonization |
| colony |
| color |
| colored |
| colors |
| colossal |
| colour |
| colouration |
| coloured |
| colouring |
| colourless |
| colours |
| columbiad |
| column |
| columnar |
| columned |
| columns |
| coma |
| comatose |
| combat |
| combated |
| combating |
| combativeness |
| combats |
| combattendo |
| combed |
| combination |
| combinations |
| combine |
| combined |
| combing |
| combining |
| combustible |
| combustibles |
| combustion |
| come |
| comeagain |
| comedy |
| comely |
| comer |
| comers |
| comes |
| comest |
| comet |
| cometary |
| cometh |
| comets |
| comfort |
| comfortable |
| comfortably |
| comforted |
| comforter |
| comforters |
| comforting |
| comfortless |
| comin |
| coming |
| comings |
| command |
| commanded |
| commander |
| commandery |
| commanding |
| commands |
| commemorate |
| commemorates |
| commence |
| commenced |
| commencement |
| commences |
| commencing |
| commendable |
| commendation |
| commended |
| commensurate |
| comment |
| commentaries |
| commentary |
| commented |
| commenting |
| comments |
| commerce |
| commercial |
| commerciel |
| commingled |
| commingling |
| commiseration |
| commission |
| commit |
| committed |
| committee |
| committing |
| commodious |
| commodities |
| commodity |
| commodus |
| common |
| commonalty |
| commoner |
| commonest |
| commonly |
| commonplace |
| commotion |
| communal |
| commune |
| communed |
| communicate |
| communicated |
| communicates |
| communicating |
| communication |
| communications |
| communicative |
| communion |
| communities |
| community |
| compact |
| companies |
| companion |
| companioned |
| companionless |
| companions |
| companionship |
| companionway |
| company |
| compar |
| comparable |
| comparative |
| comparatively |
| compare |
| compared |
| comparing |
| comparison |
| compartment |
| compartments |
| compass |
| compasses |
| compassion |
| compassionated |
| compassioning |
| compassless |
| compeers |
| compel |
| compelled |
| compels |
| compendious |
| compendium |
| compensate |
| compensated |
| compensation |
| competent |
| competing |
| competition |
| compiled |
| compiler |
| complacency |
| complacently |
| complain |
| complained |
| complaining |
| complaint |
| complaints |
| compleated |
| complement |
| complete |
| completed |
| completely |
| completeness |
| completes |
| completest |
| completing |
| completion |
| complex |
| complexion |
| complexions |
| complexity |
| compliance |
| complicated |
| complication |
| complied |
| compliment |
| complimented |
| compliments |
| comply |
| complying |
| compose |
| composed |
| composes |
| composing |
| composite |
| composition |
| compositions |
| composure |
| compound |
| comprehend |
| comprehended |
| comprehensible |
| comprehension |
| comprehensive |
| compressed |
| compressing |
| comprised |
| comprising |
| compromise |
| comptoir |
| compulsory |
| compute |
| computed |
| comrades |
| comte |
| con |
| conan |
| concatenation |
| concave |
| concavity |
| conceal |
| concealed |
| concealedly |
| concealing |
| concealment |
| concealments |
| conceals |
| concede |
| conceit |
| conceited |
| conceivable |
| conceivably |
| conceive |
| conceived |
| conceiver |
| conceiving |
| concentrate |
| concentrated |
| concentration |
| concentrative |
| concentric |
| conception |
| conceptions |
| concern |
| concerned |
| concerning |
| concerns |
| concert |
| concerto |
| concession |
| conches |
| concierge |
| conciliate |
| conciliating |
| conciliatory |
| concision |
| conclaves |
| conclude |
| concluded |
| concludes |
| concluding |
| conclusion |
| conclusions |
| conclusive |
| concocted |
| concocting |
| concoctions |
| concomitants |
| concord |
| concordant |
| concourse |
| concrete |
| concur |
| concurred |
| concurrence |
| concussion |
| condemn |
| condemnation |
| condemned |
| condemns |
| condensation |
| condense |
| condensed |
| condenser |
| condensing |
| condescended |
| condition |
| conditionally |
| conditioned |
| conditions |
| condolence |
| condor |
| condorcet |
| conduce |
| conduct |
| conducted |
| conducting |
| conductors |
| conduit |
| cone |
| confectioner |
| confederacy |
| confer |
| conference |
| confering |
| conferred |
| confess |
| confessed |
| confessedly |
| confession |
| confessions |
| confessor |
| confide |
| confided |
| confidence |
| confident |
| confidential |
| confidently |
| confiding |
| confine |
| confined |
| confinement |
| confines |
| confirm |
| confirmation |
| confirmed |
| confirming |
| confiscated |
| conflagration |
| conflict |
| conflicted |
| conflicting |
| confluence |
| conformation |
| conforming |
| conformity |
| confound |
| confounded |
| confounds |
| confront |
| confronted |
| confronting |
| confronts |
| confuse |
| confused |
| confusedly |
| confusion |
| confutation |
| confute |
| confuted |
| congeal |
| congealed |
| congealing |
| congenial |
| congeniality |
| congeries |
| conglomeration |
| congo |
| congolese |
| congratulate |
| congratulated |
| congratulatory |
| congregate |
| congregated |
| congregating |
| congregation |
| congregational |
| congregationalists |
| congress |
| conic |
| conical |
| conjecture |
| conjectured |
| conjectures |
| conjoined |
| conjointly |
| conjugal |
| conjunction |
| conjurations |
| conjure |
| conjured |
| conjuror |
| connect |
| connected |
| connecticut |
| connecting |
| connection |
| connections |
| conned |
| connexion |
| connexions |
| conning |
| connings |
| connivance |
| connoisseur |
| conquer |
| conquered |
| conquering |
| conqueror |
| conquers |
| conquest |
| conquests |
| conscience |
| conscientious |
| conscientiously |
| conscious |
| consciously |
| consciousness |
| consecrated |
| consecutive |
| consent |
| consented |
| consenting |
| consequence |
| consequences |
| consequent |
| consequently |
| conservatism |
| conservative |
| considdeble |
| consider |
| considerable |
| considerably |
| considerate |
| considerateness |
| consideration |
| considerations |
| considered |
| considering |
| considers |
| consigned |
| consigning |
| consisted |
| consistency |
| consistent |
| consisting |
| consists |
| consolation |
| consolations |
| consolatory |
| console |
| consoled |
| consoler |
| consoles |
| consoling |
| consolotary |
| consonance |
| consonant |
| consort |
| consorted |
| conspicuous |
| conspired |
| constance |
| constancy |
| constant |
| constantine |
| constantinople |
| constantly |
| constellation |
| constellations |
| consternation |
| constitute |
| constituted |
| constitutes |
| constitution |
| constitutional |
| constitutionally |
| constrained |
| constraint |
| constriction |
| construct |
| constructed |
| constructing |
| construction |
| constructionem |
| constructive |
| constructs |
| construe |
| construed |
| consubstantialism |
| consul |
| consular |
| consulship |
| consult |
| consultation |
| consultations |
| consulted |
| consulting |
| consults |
| consultum |
| consume |
| consumed |
| consuming |
| consummate |
| consummated |
| consummation |
| consumption |
| contact |
| contacts |
| contagion |
| contagious |
| contain |
| contained |
| containers |
| containing |
| contains |
| contemn |
| contemns |
| contemplate |
| contemplated |
| contemplation |
| contemplations |
| contemplative |
| contemporaries |
| contempt |
| contemptible |
| contemptuous |
| contemptuously |
| contend |
| contended |
| contending |
| content |
| contented |
| contentedly |
| contention |
| contentions |
| contentiousness |
| contentment |
| contents |
| contes |
| contest |
| contested |
| contesting |
| contests |
| context |
| contiguous |
| continent |
| continental |
| continents |
| contingencies |
| continual |
| continually |
| continuance |
| continuation |
| continue |
| continued |
| continues |
| continuing |
| continuity |
| continuous |
| continuously |
| continuum |
| contorted |
| contortions |
| contour |
| contours |
| contract |
| contracted |
| contraction |
| contradict |
| contradicted |
| contradiction |
| contradictions |
| contradictories |
| contradictory |
| contradistinction |
| contrary |
| contrast |
| contrasted |
| contrasting |
| contrasts |
| contre |
| contree |
| contribute |
| contributed |
| contributes |
| contributing |
| contribution |
| contributions |
| contributors |
| contrivance |
| contrivances |
| contrive |
| contrived |
| contriver |
| contriving |
| control |
| controlling |
| controul |
| controversial |
| controversy |
| controvert |
| contumely |
| contusion |
| contusions |
| conundrums |
| convalescence |
| convenience |
| conveniences |
| convenient |
| conveniently |
| convention |
| conventional |
| conventionalities |
| converging |
| convers |
| conversant |
| conversation |
| conversational |
| conversations |
| converse |
| conversed |
| converses |
| conversible |
| conversing |
| convert |
| converted |
| convertible |
| convex |
| convexity |
| convey |
| conveyance |
| conveyed |
| conveying |
| conveys |
| convict |
| convicted |
| conviction |
| convince |
| convinced |
| convinces |
| convincing |
| convincingness |
| convivial |
| conviviality |
| convocation |
| convolute |
| convolutions |
| convoy |
| convulsed |
| convulsion |
| convulsions |
| convulsive |
| convulsively |
| cooing |
| cook |
| cooked |
| cookery |
| cool |
| cooled |
| cooling |
| coolly |
| coolness |
| cools |
| coop |
| cooperation |
| cope |
| copied |
| copies |
| copious |
| copp |
| copper |
| coppered |
| coppice |
| copses |
| copy |
| copying |
| copyist |
| coquet |
| coquetry |
| coquetted |
| coquettish |
| coral |
| cord |
| cordage |
| cordial |
| cordiality |
| cordially |
| core |
| corey |
| corinnos |
| corinth |
| corinthian |
| cork |
| corn |
| cornelius |
| corner |
| cornered |
| corners |
| cornfields |
| cornices |
| corns |
| cornwallis |
| corollaries |
| corona |
| coronal |
| coroner |
| coronet |
| corporation |
| corporations |
| corps |
| corpse |
| corpses |
| corpulence |
| corpulent |
| correct |
| corrected |
| correcting |
| correction |
| correctly |
| correggio |
| correlate |
| correlating |
| correlation |
| correspond |
| corresponded |
| correspondence |
| correspondent |
| correspondents |
| corresponding |
| corridor |
| corridors |
| corroborate |
| corroborated |
| corroborates |
| corroboration |
| corroborative |
| corroded |
| corrosion |
| corrugated |
| corrupitur |
| corrupted |
| corruption |
| cortege |
| corty |
| coruscations |
| cosmic |
| cosmos |
| cost |
| costly |
| costume |
| costumes |
| cot |
| cotch |
| cotopaxi |
| cottage |
| cottager |
| cottagers |
| cottages |
| cotters |
| cottle |
| cotton |
| couch |
| couches |
| cough |
| could |
| couldst |
| council |
| councils |
| counsel |
| counsellor |
| counsels |
| count |
| counted |
| countenance |
| countenanced |
| countenances |
| counter |
| counteracted |
| counterbalance |
| counterbalances |
| counterfeit |
| counterfeiting |
| counterfeits |
| counterpart |
| counterparts |
| counters |
| countess |
| counties |
| counting |
| countless |
| countries |
| country |
| countryman |
| countrymen |
| countryside |
| counts |
| county |
| coup |
| coupar |
| couple |
| coupled |
| courage |
| courageous |
| courier |
| course |
| coursed |
| coursers |
| courses |
| court |
| courted |
| courteous |
| courtesies |
| courtesy |
| courtier |
| courtiers |
| courtly |
| courts |
| courtyard |
| courtyards |
| cousin |
| cousins |
| cove |
| cover |
| covered |
| covering |
| covers |
| covert |
| coverts |
| covet |
| coveted |
| cow |
| coward |
| cowardice |
| cowards |
| cowed |
| cower |
| cowered |
| cowering |
| cowper |
| cows |
| coyly |
| coyote |
| coördinated |
| crab |
| crack |
| cracked |
| crackers |
| cracking |
| crackings |
| crackle |
| crackling |
| cracks |
| cradle |
| cradled |
| cradling |
| craft |
| craftily |
| craftsmanship |
| crafty |
| crag |
| craggy |
| crags |
| crammed |
| cramped |
| crane |
| cranium |
| crank |
| craowd |
| crash |
| crashed |
| crashing |
| crass |
| cravat |
| craved |
| craving |
| crawford |
| crawl |
| crawled |
| crawlin |
| crawling |
| crawls |
| crayons |
| crazed |
| crazily |
| crazy |
| creak |
| creaked |
| creakin |
| creaking |
| creakings |
| creased |
| creases |
| create |
| created |
| creaters |
| creates |
| creating |
| creation |
| creations |
| creative |
| creator |
| creature |
| creatures |
| crebillon |
| credence |
| credentials |
| credible |
| credit |
| credited |
| creditors |
| credulous |
| creed |
| creeds |
| creek |
| creeks |
| creep |
| creeping |
| crenulate |
| crept |
| crescendoes |
| crescent |
| crest |
| crevice |
| crevices |
| crew |
| crews |
| cricket |
| crickets |
| cried |
| cries |
| crime |
| crimes |
| criminal |
| criminality |
| criminate |
| crimson |
| crinkly |
| crippling |
| crisis |
| crisp |
| criterion |
| critic |
| critical |
| criticise |
| criticism |
| criticisms |
| critick |
| critter |
| critters |
| croak |
| croaked |
| croaking |
| croakings |
| croesus |
| croissart |
| cromwell |
| crone |
| crook |
| crooked |
| crookes |
| crooned |
| crop |
| cropped |
| cross |
| crossbones |
| crossed |
| crosses |
| crossing |
| crossings |
| crotala |
| crotchet |
| crouch |
| crouched |
| crouching |
| crow |
| crowd |
| crowded |
| crowding |
| crowds |
| crown |
| crowned |
| crowning |
| crows |
| crucial |
| crucible |
| crucibles |
| crucifix |
| crucifixes |
| crude |
| crudeness |
| crudest |
| crudities |
| cruel |
| cruelly |
| cruelties |
| cruelty |
| cruises |
| crumble |
| crumbled |
| crumbling |
| crumpled |
| crusader |
| crush |
| crushed |
| crushing |
| crusted |
| crxwing |
| cry |
| crying |
| crypt |
| cryptic |
| cryptical |
| cryptograms |
| cryptograph |
| cryptographic |
| cryptographist |
| crypts |
| crystal |
| crystalline |
| crystallise |
| crystallised |
| crébillon |
| cthulhu |
| cub |
| cube |
| cubic |
| cubical |
| cubism |
| cubits |
| cubs |
| cuckoo |
| cud |
| cudgel |
| cue |
| cuff |
| cuffing |
| cuffs |
| cui |
| culled |
| culley |
| culminate |
| culminating |
| culmination |
| cult |
| cultivate |
| cultivated |
| cultivating |
| cultivation |
| cults |
| cultural |
| culture |
| cum |
| cumaean |
| cumberland |
| cumbrous |
| cumulative |
| cunning |
| cunningly |
| cup |
| cupalo |
| cupboard |
| cupboards |
| cupidity |
| cupola |
| cupolas |
| cups |
| cur |
| curas |
| curator |
| curb |
| curbed |
| curdle |
| curdles |
| cure |
| cured |
| cureless |
| curio |
| curiosities |
| curiosity |
| curious |
| curiously |
| curled |
| curling |
| curls |
| curly |
| curmudgeon |
| currency |
| current |
| currents |
| currycomb |
| curse |
| cursed |
| curses |
| cursing |
| cursory |
| curt |
| curtail |
| curtain |
| curtained |
| curtains |
| curtis |
| curvature |
| curve |
| curved |
| curves |
| curvets |
| curvetted |
| curving |
| cushion |
| cushioned |
| cushions |
| cusps |
| custody |
| custom |
| customarily |
| customary |
| customer |
| customers |
| customs |
| cut |
| cutlasses |
| cuts |
| cutter |
| cutting |
| cuttings |
| cuttlefish |
| cxck |
| cxme |
| cxncxrd |
| cxw |
| cxxl |
| cyclamen |
| cycle |
| cycles |
| cyclopean |
| cyclops |
| cydathria |
| cygnus |
| cylinder |
| cylindrical |
| cynical |
| cynicism |
| cynosure |
| cypher |
| cypress |
| cypresses |
| czanek |
| cælius |
| céder |
| cöincident |
| dabble |
| dabbled |
| dabbler |
| dabbling |
| dacia |
| daddy |
| daddyship |
| daedalus |
| daemon |
| daemoniac |
| daemoniacal |
| daemonolatreia |
| daemonologist |
| daemons |
| dagger |
| dagon |
| daily |
| daintiness |
| dainty |
| dais |
| daisies |
| daisy |
| dale |
| dalliance |
| dallying |
| damage |
| damaged |
| damages |
| damascus |
| dame |
| dames |
| dammed |
| damn |
| damnable |
| damnably |
| damnation |
| damned |
| damning |
| damp |
| damply |
| dampness |
| damps |
| damsel |
| damsels |
| dan |
| dance |
| danced |
| dancer |
| dancers |
| dances |
| dancing |
| dandy |
| danger |
| dangerous |
| dangerously |
| dangers |
| dangle |
| dangled |
| dangling |
| daniel |
| dank |
| dante |
| danvers |
| daown |
| daphnis |
| dare |
| dared |
| dares |
| daring |
| dark |
| darkened |
| darkening |
| darker |
| darkest |
| darkling |
| darkly |
| darkness |
| darksome |
| darling |
| darlings |
| darry |
| dart |
| darted |
| darters |
| darting |
| dash |
| dashed |
| dashing |
| dast |
| dastard |
| dat |
| data |
| datchet |
| date |
| dated |
| dates |
| dating |
| daubed |
| daughter |
| daughters |
| dauntless |
| david |
| davidson |
| davis |
| davy |
| dawn |
| dawned |
| dawns |
| day |
| daybreak |
| daylight |
| days |
| daytime |
| daze |
| dazed |
| dazedly |
| dazedness |
| dazzle |
| dazzled |
| dazzles |
| dazzling |
| de |
| dead |
| deaden |
| deadliest |
| deadly |
| deaf |
| deafen |
| deafened |
| deafening |
| deafeningly |
| deafness |
| deal |
| dealer |
| dealing |
| dealings |
| dealt |
| dean |
| dear |
| dearer |
| dearest |
| dearly |
| dearth |
| death |
| deathful |
| deathless |
| deathlike |
| deathly |
| deaths |
| debar |
| debarred |
| debased |
| debasement |
| debatable |
| debate |
| debated |
| debates |
| debauch |
| debaucheries |
| debbil |
| debbils |
| debilitated |
| debility |
| debris |
| debt |
| debtor |
| debts |
| decade |
| decadence |
| decadent |
| decadents |
| decades |
| decanter |
| decapitated |
| decay |
| decayed |
| decaying |
| decease |
| deceased |
| deceit |
| deceitful |
| deceive |
| deceived |
| deceiving |
| december |
| decency |
| decent |
| decently |
| deception |
| deceptive |
| decide |
| decided |
| decidedly |
| decides |
| deciding |
| decipher |
| deciphered |
| decipherer |
| deciphering |
| decision |
| decisions |
| decisive |
| decisively |
| decius |
| deck |
| decked |
| decks |
| declaiming |
| declamatory |
| declaration |
| declare |
| declared |
| declares |
| declaring |
| declin |
| decline |
| declined |
| declines |
| declining |
| declivity |
| decollavimus |
| decomposed |
| decomposition |
| decora |
| decorated |
| decoration |
| decorations |
| decorist |
| decorum |
| decrease |
| decreased |
| decreases |
| decreasing |
| decree |
| decreed |
| decrees |
| decrepid |
| decrepit |
| decrepitude |
| decry |
| decypher |
| decyphering |
| dedicate |
| dedicated |
| dedication |
| deduce |
| deduced |
| deduces |
| deducing |
| deductions |
| dee |
| deed |
| deeds |
| deem |
| deemed |
| deep |
| deepen |
| deepened |
| deepening |
| deeper |
| deepest |
| deeply |
| deeps |
| deer |
| deestrick |
| defaced |
| default |
| defaulter |
| defeat |
| defeated |
| defect |
| defective |
| defects |
| defence |
| defenceless |
| defences |
| defend |
| defended |
| defenders |
| defensive |
| defer |
| deference |
| deferred |
| deferring |
| defiance |
| deficiencies |
| deficiency |
| deficient |
| defied |
| defile |
| defiles |
| define |
| defined |
| definite |
| definitely |
| definiteness |
| definition |
| definitions |
| definitive |
| definitiveness |
| deflect |
| deformed |
| deformities |
| deformity |
| defray |
| deftness |
| defy |
| defying |
| degeneracy |
| degenerate |
| degenerated |
| degenerating |
| degeneration |
| degradation |
| degraded |
| degradedly |
| degrading |
| degree |
| degrees |
| dei |
| deification |
| deified |
| deign |
| deigned |
| deity |
| dejected |
| dejection |
| delay |
| delayed |
| delaying |
| delegation |
| deliberate |
| deliberately |
| deliberateness |
| deliberation |
| deliberations |
| delicacy |
| delicate |
| delicately |
| delicious |
| deliciously |
| delight |
| delighted |
| delightedly |
| delightful |
| delightfully |
| delighting |
| delights |
| delineation |
| delineations |
| delirious |
| deliriously |
| delirium |
| deliver |
| deliverance |
| delivered |
| deliverer |
| deliverers |
| delivering |
| delivers |
| delivery |
| delly |
| deloraine |
| delphinus |
| delphis |
| deluc |
| delude |
| deluge |
| deluged |
| delusion |
| delusions |
| delusive |
| delved |
| delvers |
| delving |
| delvings |
| dem |
| demand |
| demanded |
| demanding |
| demands |
| demeanor |
| demeanour |
| demented |
| dementedly |
| demesne |
| demesnes |
| demeter |
| demijohns |
| demise |
| demnition |
| democracy |
| democratic |
| democrats |
| democritus |
| demolished |
| demon |
| demoniac |
| demoniacal |
| demons |
| demonstrable |
| demonstrably |
| demonstrate |
| demonstrated |
| demonstrates |
| demonstration |
| demonstrations |
| demoralise |
| demosthenes |
| demure |
| demurely |
| demureness |
| den |
| deneb |
| denial |
| denied |
| denies |
| denis |
| denizen |
| denizens |
| denn |
| denominate |
| denominated |
| denomination |
| denote |
| denoted |
| denouement |
| denouncement |
| dens |
| dense |
| densely |
| denser |
| density |
| denunciations |
| deny |
| denying |
| denys |
| deodamnatus |
| depart |
| departed |
| departing |
| department |
| departs |
| departure |
| depend |
| dependable |
| dependance |
| depended |
| dependence |
| dependent |
| depends |
| depict |
| depicted |
| depicts |
| deplorable |
| deplored |
| depopulated |
| deposed |
| deposes |
| deposit |
| deposited |
| depositing |
| deposition |
| depositions |
| depository |
| deposits |
| depot |
| depraved |
| depravity |
| deprecate |
| deprecated |
| deprecates |
| deprecating |
| deprecation |
| depreciate |
| depreciations |
| depressed |
| depressing |
| depression |
| depressions |
| deprivation |
| deprive |
| deprived |
| deprives |
| depth |
| depths |
| deputed |
| deputies |
| deputy |
| der |
| derby |
| derelict |
| dereliction |
| derelictions |
| deride |
| derided |
| derision |
| derisive |
| derivation |
| derivationibus |
| derivative |
| derive |
| derived |
| derives |
| des |
| desart |
| desarved |
| desarving |
| descant |
| descanted |
| descend |
| descendant |
| descendants |
| descended |
| descending |
| descends |
| descensus |
| descent |
| descents |
| describable |
| describe |
| described |
| describes |
| describing |
| description |
| descriptions |
| descriptive |
| descry |
| dese |
| desecrating |
| desert |
| deserted |
| deserting |
| desertion |
| deserts |
| deserve |
| deserved |
| deserves |
| deserving |
| desideratum |
| desiderius |
| design |
| designated |
| designates |
| designations |
| designed |
| designer |
| designs |
| desire |
| desired |
| desires |
| desiring |
| desirous |
| desist |
| desk |
| desks |
| desolate |
| desolated |
| desolating |
| desolation |
| desp |
| despair |
| despaired |
| despairing |
| despairingly |
| despatch |
| despatched |
| despatching |
| despera |
| desperado |
| desperadoes |
| desperate |
| desperately |
| desperation |
| despicable |
| despise |
| despised |
| despises |
| despising |
| despite |
| despoiled |
| despoiling |
| despond |
| despondence |
| despondency |
| despondent |
| desponding |
| despot |
| despotic |
| despotism |
| desrochers |
| dessein |
| dessert |
| destination |
| destinations |
| destined |
| destinies |
| destiny |
| destitute |
| destroy |
| destroyed |
| destroyer |
| destroyers |
| destroying |
| destroys |
| destruction |
| destructive |
| desultory |
| detach |
| detached |
| detaching |
| detachment |
| detachments |
| detail |
| detailed |
| detailing |
| details |
| detain |
| detained |
| detainers |
| detect |
| detected |
| detecting |
| detection |
| detective |
| detectives |
| deter |
| deteriorate |
| deterioration |
| determinate |
| determination |
| determine |
| determined |
| determinedly |
| determining |
| deterred |
| deters |
| detest |
| detestable |
| detested |
| dethroned |
| detoured |
| detours |
| detracts |
| detrimental |
| deux |
| devastated |
| devastating |
| devastatingly |
| devastation |
| develop |
| developed |
| developing |
| development |
| developments |
| deviate |
| deviates |
| deviations |
| device |
| devices |
| devil |
| devilish |
| devils |
| deviltry |
| devious |
| devise |
| devised |
| devises |
| devising |
| devoid |
| devolved |
| devolving |
| devote |
| devoted |
| devotee |
| devoting |
| devotion |
| devotions |
| devour |
| devoured |
| devouring |
| devours |
| devout |
| devoutest |
| devoutly |
| dew |
| dews |
| dewy |
| dexter |
| dexterity |
| dextrous |
| dey |
| dho |
| di |
| diable |
| diabolic |
| diabolical |
| diabolism |
| diabolist |
| diadem |
| diagnosed |
| diagnosis |
| diagonally |
| diagrams |
| dial |
| dialect |
| dialects |
| dials |
| diameter |
| diamond |
| diamonds |
| dian |
| diana |
| diary |
| diatribe |
| diavolo |
| dicebant |
| dick |
| dickey |
| dictate |
| dictated |
| dictates |
| diction |
| dictionary |
| did |
| diddle |
| diddled |
| diddler |
| diddles |
| diddling |
| didst |
| die |
| died |
| diemen |
| dieppe |
| dies |
| diet |
| dieu |
| differ |
| differed |
| difference |
| differences |
| different |
| differential |
| differentiate |
| differently |
| differing |
| differs |
| difficult |
| difficulties |
| difficulty |
| diffidence |
| diffident |
| diffuse |
| diffused |
| diffusing |
| diffusion |
| diffusive |
| dig |
| digest |
| digested |
| digged |
| digging |
| digitalis |
| digits |
| digne |
| dignified |
| dignitary |
| dignity |
| digressed |
| dilapidated |
| dilapidation |
| dilate |
| dilated |
| dilation |
| dilatoriness |
| dilatory |
| dilemma |
| diligence |
| diligent |
| diligently |
| diluted |
| dim |
| dimension |
| dimensional |
| dimensioned |
| dimensions |
| diminish |
| diminished |
| diminishing |
| diminution |
| diminutive |
| dimly |
| dimmed |
| dimmer |
| dimming |
| dimness |
| dimpled |
| dimples |
| din |
| dined |
| dinginess |
| dingle |
| dingy |
| dining |
| dinned |
| dinner |
| dint |
| diodorus |
| diogenes |
| dios |
| diotima |
| diplomacy |
| diplomatist |
| dipped |
| dipping |
| dips |
| dipt |
| dire |
| direct |
| directed |
| directing |
| direction |
| directions |
| directly |
| directness |
| directors |
| direful |
| direst |
| dirge |
| dirges |
| dirt |
| dirteen |
| dirtiest |
| dirty |
| dis |
| disabuse |
| disadvantage |
| disadvantages |
| disagree |
| disagreeable |
| disagreeably |
| disagreed |
| disappear |
| disappearance |
| disappearances |
| disappeared |
| disappearing |
| disappears |
| disappoint |
| disappointed |
| disappointedly |
| disappointment |
| disappointments |
| disapprobation |
| disapproval |
| disarranged |
| disarrangement |
| disarray |
| disaster |
| disasters |
| disastrous |
| disastrously |
| disavow |
| disbanded |
| disbelief |
| disburses |
| disburthen |
| discard |
| discarded |
| discern |
| discerned |
| discernible |
| discerning |
| discernment |
| discharge |
| discharged |
| discharges |
| discharging |
| disciple |
| disciples |
| discipline |
| disciplined |
| disclaim |
| disclose |
| disclosed |
| disclosing |
| disclosure |
| discoloration |
| discolored |
| discolouration |
| discoloured |
| discomfited |
| discomfort |
| disconcert |
| disconcerted |
| disconcerting |
| disconnected |
| disconsolate |
| discontent |
| discontented |
| discontinuance |
| discord |
| discordant |
| discordantly |
| discounted |
| discourage |
| discouraged |
| discouraging |
| discourse |
| discoursed |
| discourses |
| discoursing |
| discover |
| discoverable |
| discovered |
| discoveries |
| discovering |
| discovery |
| discreditable |
| discrepancies |
| discrepancy |
| discretion |
| discrimination |
| discriminative |
| discs |
| discursive |
| discuss |
| discussed |
| discussing |
| discussion |
| discussions |
| disdain |
| disdained |
| disdainful |
| disdainfully |
| disdaining |
| disease |
| diseased |
| diseases |
| disembodied |
| disencumbered |
| disenfranchised |
| disengage |
| disengaged |
| disengagement |
| disentangled |
| disentangles |
| disfigured |
| disfigures |
| disgrace |
| disgraced |
| disgraceful |
| disgracefully |
| disgracing |
| disguise |
| disguised |
| disgust |
| disgusted |
| disgustful |
| disgusting |
| dish |
| disheartened |
| dishes |
| dishevelled |
| dishonour |
| dishonoured |
| disillusion |
| disinclination |
| disinclined |
| disingenuous |
| disintegrated |
| disintegrating |
| disintegration |
| disinter |
| disinterested |
| disinterestedness |
| disinterment |
| disinterred |
| disinterring |
| disjoined |
| disjointed |
| disjointedly |
| disk |
| dislike |
| disliked |
| dislikes |
| disliking |
| dislodged |
| dislodging |
| dismal |
| dismally |
| dismantled |
| dismay |
| dismembered |
| dismiss |
| dismissal |
| dismissed |
| dismisses |
| dismissing |
| dismount |
| disobedience |
| disobey |
| disobeyed |
| disorder |
| disordered |
| disorderly |
| disorders |
| disorganisation |
| disorganization |
| disorganized |
| disowned |
| disparagement |
| dispatched |
| dispatches |
| dispel |
| dispelief |
| dispelled |
| dispelling |
| dispense |
| dispensed |
| dispersal |
| disperse |
| dispersed |
| dispirited |
| displace |
| displaced |
| displacing |
| display |
| displayed |
| displaying |
| displays |
| displease |
| displeased |
| displeases |
| displeasure |
| disporting |
| disposal |
| dispose |
| disposed |
| disposing |
| disposition |
| dispositions |
| disproportion |
| disproportionately |
| disprove |
| disproved |
| dispute |
| disputed |
| disputes |
| disputing |
| disquiet |
| disquieted |
| disquieting |
| disquietingly |
| disquietude |
| disquisition |
| disquisitions |
| disregarded |
| disregardful |
| disregarding |
| disrepairs |
| disreputable |
| disrepute |
| disruption |
| disruptions |
| dissatisfaction |
| dissect |
| dissecting |
| dissemble |
| dissensions |
| dissentient |
| disservice |
| dissimilar |
| dissimilarity |
| dissipate |
| dissipated |
| dissipates |
| dissipation |
| dissociate |
| dissociated |
| dissoluble |
| dissolute |
| dissolution |
| dissolve |
| dissolved |
| dissonance |
| dissonant |
| dissuade |
| dissuaded |
| distance |
| distances |
| distant |
| distaste |
| distasteful |
| distemper |
| distempered |
| distended |
| distending |
| distention |
| distinct |
| distinction |
| distinctions |
| distinctive |
| distinctly |
| distinctness |
| distinguish |
| distinguishable |
| distinguished |
| distinguishing |
| distingué |
| distorted |
| distorting |
| distortion |
| distortions |
| distract |
| distracted |
| distractingly |
| distraction |
| distress |
| distressed |
| distresses |
| distressing |
| distributed |
| distributing |
| distribution |
| district |
| districts |
| distrust |
| distrustful |
| disturb |
| disturbance |
| disturbances |
| disturbed |
| disturbing |
| disturbingly |
| disturbs |
| disunion |
| disused |
| dithyrambics |
| ditty |
| diurnal |
| dive |
| dived |
| diverging |
| diverse |
| diversified |
| diversions |
| diversity |
| divert |
| diverted |
| diverting |
| divest |
| divested |
| divesting |
| divide |
| divided |
| divides |
| dividing |
| divine |
| divined |
| divinely |
| divinest |
| diving |
| divining |
| divinity |
| division |
| divisions |
| divorce |
| divorced |
| divulge |
| divulged |
| dizzily |
| dizziness |
| dizzy |
| do |
| dobson |
| doch |
| docile |
| docility |
| docks |
| doctair |
| doctor |
| doctors |
| doctrine |
| doctrines |
| document |
| documents |
| dodge |
| dodona |
| doe |
| does |
| doff |
| doffed |
| dog |
| dogged |
| doggedly |
| doggrel |
| dogless |
| dogma |
| dogmatic |
| dogmatism |
| dogs |
| doin |
| doing |
| doings |
| dole |
| doleful |
| doll |
| dollar |
| dollars |
| dolphins |
| dolt |
| domain |
| domains |
| dombrowski |
| domdaniel |
| dome |
| domed |
| domes |
| domestic |
| domesticate |
| domesticated |
| domicile |
| dominance |
| dominantly |
| dominate |
| dominating |
| domination |
| dominic |
| dominion |
| dominions |
| domino |
| don |
| donations |
| done |
| donjon |
| donkey |
| donkeys |
| donna |
| donner |
| donning |
| donovan |
| doo |
| doodle |
| doodling |
| doom |
| doomed |
| dooms |
| dooo |
| dooooooh |
| door |
| doorbell |
| doors |
| doorstep |
| doorsteps |
| doorway |
| doorways |
| dope |
| doric |
| dories |
| dormant |
| dormer |
| dormitories |
| dory |
| doré |
| dose |
| doses |
| dost |
| dotage |
| doted |
| doth |
| doting |
| dots |
| double |
| doubled |
| doubles |
| doublet |
| doubly |
| doubt |
| doubted |
| doubtful |
| doubting |
| doubtless |
| doubts |
| doughty |
| douglas |
| doux |
| dove |
| dover |
| dovetailed |
| dow |
| down |
| downcast |
| downfall |
| downright |
| downs |
| downstairs |
| downtown |
| downward |
| downwards |
| doyle |
| doze |
| dozen |
| dozens |
| dozing |
| dr |
| drab |
| draconian |
| draft |
| drag |
| dragged |
| dragging |
| draggled |
| dragon |
| drain |
| drainage |
| drained |
| dram |
| drama |
| dramatic |
| dramatically |
| dramatis |
| drams |
| drank |
| draownded |
| draped |
| draper |
| draperied |
| draperies |
| drapery |
| drastic |
| draught |
| draughts |
| draughtsman |
| drave |
| draw |
| drawback |
| drawer |
| drawers |
| drawing |
| drawings |
| drawlingly |
| drawn |
| draws |
| dread |
| dreaded |
| dreadful |
| dreadfully |
| dreading |
| dreadless |
| dreads |
| dream |
| dreamable |
| dreamed |
| dreamer |
| dreamers |
| dreamily |
| dreaming |
| dreamings |
| dreamless |
| dreams |
| dreamt |
| dreamy |
| drear |
| dreary |
| drenched |
| drenching |
| dresden |
| dress |
| dressed |
| dresser |
| dressers |
| dresses |
| dressing |
| drest |
| drew |
| dried |
| drift |
| drifted |
| drifting |
| drifts |
| drilled |
| drills |
| drink |
| drinking |
| drinks |
| drip |
| dripping |
| drive |
| drivel |
| driven |
| driver |
| drivers |
| drives |
| drivest |
| drivin |
| driving |
| drizzle |
| drizzling |
| drole |
| droll |
| drolleries |
| drollery |
| drollest |
| dromedary |
| drone |
| dronk |
| droop |
| drooped |
| drooping |
| droopingly |
| droops |
| drop |
| dropped |
| droppin |
| dropping |
| drops |
| dropsical |
| dropsy |
| dropt |
| dross |
| drought |
| droughts |
| drove |
| drown |
| drowned |
| drowning |
| drowsily |
| drowsiness |
| drowsing |
| drowsy |
| drs |
| drudge |
| drudgery |
| drug |
| druggists |
| drugs |
| druid |
| druidic |
| druidical |
| drum |
| drummers |
| drumming |
| drummummupp |
| drums |
| drunk |
| drunkard |
| drunken |
| drury |
| druv |
| drxwn |
| dry |
| dryads |
| dryly |
| dryness |
| drômes |
| du |
| dub |
| dubble |
| dubious |
| dublin |
| dubourg |
| duc |
| ducal |
| duchess |
| duck |
| ducks |
| ducrow |
| dudgeon |
| due |
| duelli |
| duelling |
| duellist |
| duello |
| dug |
| dugouts |
| duk |
| duke |
| dull |
| dullard |
| dulled |
| duller |
| dulling |
| dulls |
| dully |
| dulness |
| duly |
| dumas |
| dumb |
| dumbarton |
| dumbfounded |
| dump |
| dumpy |
| dun |
| dunces |
| dunder |
| dunedin |
| dungeon |
| dungeons |
| dunkeld |
| dunwich |
| dunôt |
| dupe |
| duped |
| dupin |
| duplicate |
| duplicated |
| duplication |
| duplications |
| duquel |
| durability |
| durable |
| duration |
| durch |
| dure |
| durfee |
| during |
| durned |
| durst |
| dusk |
| dusky |
| dust |
| dusty |
| dutch |
| dutchman |
| dutee |
| duties |
| dutiful |
| duty |
| duval |
| duvillard |
| dvelf |
| dwarf |
| dwarfed |
| dwell |
| dwelled |
| dweller |
| dwellers |
| dwelling |
| dwellings |
| dwells |
| dwelt |
| dwindled |
| dx |
| dxg |
| dxll |
| dxn |
| dyed |
| dyin |
| dying |
| dynamically |
| dynamics |
| dynamite |
| dynasty |
| dyspeptic |
| dæmonic |
| déshabillé |
| each |
| eager |
| eagerly |
| eagerness |
| eagle |
| eagles |
| ear |
| eared |
| earl |
| earldom |
| earldoms |
| earlier |
| earliest |
| earls |
| early |
| earn |
| earned |
| earnest |
| earnestly |
| earnestness |
| earning |
| earns |
| earrings |
| ears |
| earth |
| earthen |
| earthern |
| earthiness |
| earthly |
| earthquake |
| earthquakes |
| earthy |
| ease |
| easel |
| easier |
| easily |
| east |
| easter |
| eastern |
| eastward |
| easy |
| eat |
| eaten |
| eater |
| eating |
| eats |
| eave |
| eaved |
| eaves |
| eb |
| ebb |
| ebbed |
| ebber |
| ebenezer |
| eberry |
| ebery |
| ebn |
| ebon |
| ebony |
| ecarte |
| eccentric |
| eccentricities |
| eccentricity |
| eccentrick |
| ecclesiae |
| eccossois |
| echo |
| echoed |
| echoes |
| echoing |
| eclipse |
| eclipsed |
| ecliptic |
| economics |
| economy |
| ecstacies |
| ecstasies |
| ecstasy |
| ecstatic |
| eddied |
| eddies |
| eddying |
| eder |
| edgar |
| edge |
| edged |
| edges |
| edgeways |
| edging |
| edifice |
| edifices |
| edina |
| edinburgh |
| edit |
| edited |
| edition |
| editor |
| editorial |
| editorials |
| editors |
| edmund |
| edouard |
| educate |
| educated |
| educating |
| education |
| educations |
| educe |
| educed |
| edw |
| edward |
| edwin |
| ee |
| eend |
| eerie |
| eerily |
| eeth |
| ef |
| efface |
| effaced |
| effacing |
| effect |
| effected |
| effecting |
| effective |
| effects |
| effectual |
| effectually |
| effeminate |
| efficacy |
| efficiency |
| efficient |
| effluence |
| effluvia |
| effort |
| efforts |
| effrontery |
| effudit |
| effulgence |
| effulgent |
| effusion |
| egeberg |
| egg |
| egged |
| egham |
| eglantine |
| egotism |
| egree |
| egregious |
| egress |
| egypt |
| egyptian |
| eh |
| ehye |
| eibon |
| eidolon |
| eight |
| eighteen |
| eighteenth |
| eighth |
| eighths |
| eighty |
| eikon |
| einstein |
| eiros |
| either |
| ejaculated |
| ejaculation |
| ejaculations |
| ejected |
| el |
| elaborate |
| elaborated |
| elaborately |
| elah |
| elam |
| elapse |
| elapsed |
| elapses |
| elapsing |
| elastic |
| elasticity |
| elation |
| elbow |
| elbowed |
| elbows |
| eld |
| elder |
| elderly |
| elders |
| eldest |
| eldritch |
| eleanor |
| eleatic |
| eleazar |
| elect |
| elected |
| election |
| elections |
| elector |
| electric |
| electrical |
| electrically |
| electricity |
| electro |
| electronic |
| electrons |
| elegance |
| elegant |
| element |
| elemental |
| elementary |
| elements |
| elenchi |
| eleonora |
| elephant |
| elephants |
| elevate |
| elevated |
| elevates |
| elevating |
| elevation |
| elevations |
| eleven |
| eleventh |
| elfin |
| elicit |
| elicited |
| eliciting |
| eligible |
| elihu |
| elinor |
| eliot |
| elipse |
| elixir |
| eliza |
| elizabeth |
| elizabethtown |
| elizy |
| ellent |
| ellery |
| elliot |
| ellipse |
| ellipsoid |
| ellis |
| ellison |
| elm |
| elmer |
| elms |
| eloi |
| eloped |
| elopement |
| eloquence |
| eloquent |
| else |
| elses |
| elsewhere |
| elucidation |
| elude |
| eluded |
| eludes |
| eluding |
| elusive |
| elwood |
| elysian |
| elysium |
| em |
| emaciated |
| emaciation |
| emanate |
| emanated |
| emanating |
| emanation |
| emanations |
| embalmed |
| embalming |
| embankment |
| embark |
| embarked |
| embarks |
| embarrass |
| embarrassed |
| embarrassing |
| embarrassment |
| embattled |
| embellish |
| embellished |
| embellishment |
| embellishments |
| ember |
| embers |
| embittered |
| emblazoned |
| emblem |
| embodied |
| embodiment |
| embodiments |
| embody |
| embolden |
| embosomed |
| embossed |
| embowered |
| embrace |
| embraced |
| embraces |
| embracing |
| embrasure |
| embroidered |
| embroidery |
| embrowned |
| embryo |
| emendation |
| emerald |
| emerge |
| emerged |
| emergence |
| emergency |
| emerging |
| emeritus |
| emigrant |
| emigrants |
| emigrate |
| emigration |
| eminence |
| eminent |
| eminently |
| emissaries |
| emissary |
| emit |
| emitted |
| emitting |
| emma |
| emolument |
| emotion |
| emotional |
| emotions |
| emperor |
| emperors |
| emphasis |
| emphasised |
| emphasizing |
| emphatic |
| emphatically |
| empire |
| empires |
| employ |
| employed |
| employers |
| employing |
| employment |
| employments |
| employs |
| empress |
| emptied |
| emptiness |
| empty |
| emptying |
| empyrean |
| emulation |
| en |
| enable |
| enabled |
| enables |
| enacted |
| enactments |
| enamel |
| enamelled |
| enamored |
| encaged |
| encamped |
| encampment |
| encased |
| enchain |
| enchained |
| enchanted |
| enchanter |
| enchanting |
| enchantingly |
| enchantment |
| enchantments |
| encircle |
| encircled |
| encircling |
| encke |
| enclos |
| enclose |
| enclosed |
| enclosing |
| enclosure |
| encoffined |
| encomium |
| encomiums |
| encompass |
| encompassed |
| encompassing |
| encore |
| encored |
| encounter |
| encountered |
| encountering |
| encourage |
| encouraged |
| encouragement |
| encouraging |
| encrease |
| encreased |
| encreasing |
| encroach |
| encroached |
| encroaching |
| encroachments |
| encrusted |
| encumbered |
| encumbrance |
| end |
| endangered |
| endangers |
| endeared |
| endearing |
| endeavor |
| endeavored |
| endeavoring |
| endeavors |
| endeavour |
| endeavoured |
| endeavouring |
| endeavours |
| ended |
| ending |
| endless |
| endlessly |
| endorsed |
| endorsement |
| endow |
| endowed |
| endowing |
| endowment |
| endowments |
| ends |
| endued |
| enduing |
| endurance |
| endure |
| endured |
| endures |
| endureth |
| enduring |
| enemies |
| enemy |
| energetic |
| energetically |
| energies |
| energy |
| enfeeble |
| enfeebled |
| enforce |
| enforcing |
| enfranchised |
| engage |
| engaged |
| engagement |
| engages |
| engaging |
| engendered |
| engine |
| engineers |
| engines |
| engirdle |
| engirdled |
| england |
| englefield |
| english |
| englishman |
| englishmen |
| engrafted |
| engraven |
| engraving |
| engravings |
| engroses |
| engross |
| engrossed |
| engrossing |
| engulfed |
| engulfs |
| enhance |
| enhanced |
| enigma |
| enigmas |
| enigmatical |
| enjoined |
| enjoy |
| enjoyed |
| enjoying |
| enjoyment |
| enjoyments |
| enjoys |
| enkindle |
| enkindled |
| enkindling |
| enlarge |
| enlarged |
| enlargement |
| enlighten |
| enlightened |
| enlightening |
| enlightenment |
| enlist |
| enlisting |
| enlistment |
| enlivened |
| enmeshed |
| enmity |
| ennobled |
| ennobles |
| ennobling |
| ennui |
| enoch |
| enormity |
| enormous |
| enormously |
| enough |
| enquire |
| enquired |
| enquirer |
| enquires |
| enquiries |
| enquiring |
| enquiringly |
| enquiry |
| enraged |
| enraptured |
| enrooted |
| ensanguined |
| ensconced |
| enshadowed |
| enshadowing |
| enshrine |
| enshrined |
| enshrouded |
| enslave |
| enslaved |
| ensnaring |
| ensue |
| ensued |
| ensuing |
| ensure |
| ensured |
| entablature |
| entailed |
| entangle |
| entangled |
| entanglement |
| entangling |
| enter |
| entered |
| entereth |
| entering |
| enterprise |
| enterprize |
| enterred |
| enters |
| entertain |
| entertained |
| entertaining |
| entertainment |
| enthralled |
| enthralment |
| enthroned |
| enthusiasm |
| enthusiasms |
| enthusiast |
| enthusiastic |
| enthusiastically |
| enthusiasts |
| enticement |
| enticements |
| entire |
| entirely |
| entities |
| entitled |
| entity |
| entombed |
| entombment |
| entomological |
| entourage |
| entrance |
| entranced |
| entrancing |
| entrap |
| entrapment |
| entrapped |
| entre |
| entreat |
| entreated |
| entreaties |
| entreating |
| entreaty |
| entric |
| entrust |
| entrusted |
| entrusting |
| entry |
| entwined |
| enuff |
| enumerated |
| enunciated |
| enunciation |
| envelop |
| enveloped |
| envelopes |
| envelops |
| envenomed |
| envied |
| environed |
| environment |
| environmental |
| environs |
| envisage |
| envy |
| enwoven |
| enwrapt |
| enwritten |
| eo |
| ephemera |
| ephemeral |
| epictetus |
| epicurus |
| epidaphne |
| epidemic |
| epidendrum |
| epigoniad |
| epigram |
| epigrams |
| epilepsis |
| epileptic |
| epilogue |
| epimanes |
| epiphanes |
| episode |
| epistles |
| epitaphs |
| epithet |
| epithets |
| epoch |
| epochs |
| equable |
| equal |
| equality |
| equalize |
| equalizing |
| equalled |
| equally |
| equals |
| equanimity |
| equation |
| equations |
| equator |
| equatorial |
| equerries |
| equinoctial |
| equipment |
| equipped |
| equitable |
| equitably |
| equivalent |
| equivocal |
| er |
| era |
| eradicate |
| eradicated |
| eradicating |
| eras |
| erase |
| erased |
| ere |
| erebus |
| erect |
| erected |
| erecting |
| erectly |
| eres |
| eric |
| erich |
| ermengarde |
| ermined |
| ernest |
| eros |
| errand |
| erratic |
| erring |
| erringly |
| erroneous |
| erroneously |
| error |
| errors |
| errs |
| erry |
| erudite |
| erudition |
| eruptions |
| escape |
| escaped |
| escapes |
| escaping |
| eschew |
| eschewed |
| escondida |
| escort |
| escorted |
| escritoire |
| escutcheons |
| esdras |
| ese |
| esoteric |
| espanaye |
| especial |
| especially |
| espied |
| esprit |
| espritism |
| esq |
| esquimau |
| esquimaux |
| essay |
| essayed |
| essence |
| essential |
| essentially |
| esset |
| essex |
| est |
| establish |
| established |
| establishes |
| establishing |
| establishment |
| estate |
| estates |
| esteban |
| esteem |
| esteemed |
| estimate |
| estimated |
| estimating |
| estimation |
| estrange |
| estranged |
| estuary |
| et |
| etait |
| etc |
| eternal |
| eternally |
| eternals |
| eternities |
| eternity |
| ethelred |
| ether |
| ethereal |
| etherial |
| ethical |
| ethics |
| ethnological |
| ethnologist |
| ethnology |
| etienne |
| etiquette |
| etoile |
| eton |
| etonians |
| etruria |
| etruscan |
| ettrick |
| euclidean |
| eugenie |
| eulogies |
| eulogy |
| eumenides |
| euphonious |
| europe |
| european |
| eusebius |
| eustache |
| evade |
| evadne |
| evanescent |
| evaporating |
| evaporation |
| evasive |
| eve |
| evelyn |
| even |
| evening |
| evenings |
| evenly |
| event |
| eventful |
| events |
| eventual |
| eventualities |
| eventually |
| ever |
| everard |
| everbody |
| evergreen |
| evergreens |
| everlasting |
| everlastingly |
| evermore |
| everteeming |
| every |
| everybody |
| everyday |
| everyone |
| everything |
| everywhere |
| eves |
| evian |
| evicted |
| evidence |
| evidences |
| evident |
| evidently |
| evil |
| evilly |
| evils |
| evinced |
| evinces |
| evincing |
| evive |
| evoke |
| evoked |
| evokes |
| evoking |
| evolution |
| evolutionary |
| evolutions |
| evolving |
| ex |
| exact |
| exacted |
| exactions |
| exactitude |
| exactly |
| exagerating |
| exaggerated |
| exaggerating |
| exaggeration |
| exalt |
| exaltation |
| exalted |
| exalting |
| examination |
| examinations |
| examine |
| examined |
| examiner |
| examines |
| examining |
| example |
| examples |
| exasperate |
| exasperated |
| excavated |
| excavation |
| excavations |
| excavators |
| exceed |
| exceeded |
| exceeding |
| exceedingly |
| exceeds |
| excel |
| excelled |
| excellence |
| excellences |
| excellencies |
| excellency |
| excellent |
| excelling |
| excentric |
| excep |
| except |
| excepted |
| excepting |
| exception |
| exceptional |
| exceptionally |
| exceptions |
| excess |
| excesses |
| excessive |
| excessively |
| exchange |
| exchanged |
| exchanging |
| excitability |
| excitable |
| excitation |
| excite |
| excited |
| excitedly |
| excitement |
| excitements |
| excites |
| exciting |
| exclaim |
| exclaimed |
| exclaiming |
| exclaims |
| exclamation |
| exclamations |
| excluded |
| excluding |
| exclusion |
| exclusive |
| exclusively |
| excommunication |
| excoriated |
| excrescence |
| exculpate |
| exculpated |
| excursion |
| excursions |
| excusable |
| excuse |
| excuses |
| execrable |
| execrate |
| execration |
| execute |
| executed |
| executing |
| execution |
| executor |
| exemplification |
| exemplified |
| exemplify |
| exemplifying |
| exempt |
| exemption |
| exercise |
| exercised |
| exercises |
| exergues |
| exert |
| exerted |
| exerting |
| exertion |
| exertions |
| exeter |
| exhalation |
| exhalations |
| exhaling |
| exhaust |
| exhausted |
| exhausting |
| exhaustion |
| exhaustive |
| exhaustless |
| exhibit |
| exhibited |
| exhibiter |
| exhibiting |
| exhibition |
| exhibitions |
| exhilarated |
| exhilarating |
| exhilaration |
| exhortation |
| exhortations |
| exhorted |
| exhorting |
| exhumation |
| exhume |
| exhumed |
| exigencies |
| exigent |
| exile |
| exiled |
| exiles |
| exist |
| existed |
| existence |
| existences |
| existent |
| existing |
| exists |
| exit |
| exonerated |
| exorbitant |
| exotic |
| expanded |
| expanding |
| expanse |
| expanses |
| expansion |
| expansive |
| expatiate |
| expatiating |
| expect |
| expectancy |
| expectant |
| expectation |
| expectations |
| expected |
| expecting |
| expedient |
| expedients |
| expedition |
| expeditions |
| expeditious |
| expelled |
| expending |
| expenditure |
| expense |
| expenses |
| expensive |
| experience |
| experienced |
| experiences |
| experiment |
| experimental |
| experimentalist |
| experimentally |
| experimenters |
| experimenting |
| experiments |
| expert |
| experts |
| expiate |
| expiration |
| expire |
| expired |
| explain |
| explained |
| explaining |
| explains |
| explanation |
| explanations |
| explanatory |
| explicable |
| explicit |
| explicitly |
| expliquer |
| exploded |
| exploding |
| exploit |
| exploits |
| exploration |
| explorations |
| exploraturi |
| explore |
| explored |
| explorer |
| explorers |
| exploring |
| explosion |
| exporting |
| exports |
| expose |
| exposed |
| exposing |
| expostulate |
| expostulated |
| expostulation |
| exposure |
| express |
| expressed |
| expresses |
| expressing |
| expression |
| expressionless |
| expressions |
| expressive |
| expressiveness |
| exquisite |
| exquisitely |
| exquisites |
| extactic |
| extant |
| extasy |
| extend |
| extended |
| extending |
| extends |
| extension |
| extensive |
| extensively |
| extent |
| extents |
| exterior |
| exterminating |
| extermination |
| external |
| externally |
| extinct |
| extinction |
| extinguish |
| extinguished |
| extinguishing |
| extinguishment |
| extirpate |
| extirpation |
| extolled |
| extort |
| extorted |
| extra |
| extract |
| extracted |
| extracting |
| extraction |
| extracts |
| extraordinary |
| extravagance |
| extravagances |
| extravagant |
| extravagantly |
| extreme |
| extremely |
| extremeness |
| extremes |
| extremest |
| extremists |
| extremities |
| extremity |
| extricate |
| extricating |
| extrinsic |
| exuberant |
| exult |
| exultant |
| exultantly |
| exultation |
| exulted |
| exulting |
| exultingly |
| exults |
| eye |
| eyebrows |
| eyed |
| eyeglass |
| eyeing |
| eyelashes |
| eyelid |
| eyelids |
| eyes |
| eyrie |
| ezekiel |
| fable |
| fables |
| fabric |
| fabricate |
| fabrics |
| fabulous |
| fac |
| facade |
| facades |
| face |
| faced |
| faces |
| facetious |
| facial |
| facile |
| facilis |
| facilitate |
| facilitated |
| facilities |
| facility |
| facing |
| facsimiles |
| fact |
| faction |
| factions |
| factitious |
| facto |
| factories |
| factors |
| factory |
| facts |
| faculties |
| faculty |
| fade |
| faded |
| fades |
| fading |
| faery |
| fail |
| failed |
| failing |
| fails |
| failure |
| failures |
| fain |
| faint |
| fainted |
| fainter |
| faintest |
| fainting |
| faintings |
| faintly |
| faintness |
| faints |
| fair |
| faire |
| fairer |
| fairest |
| fairies |
| fairly |
| fairness |
| fairy |
| fait |
| faith |
| faithful |
| faithfully |
| faithless |
| falkland |
| fall |
| fallacious |
| fallacy |
| fallen |
| fallin |
| falling |
| falls |
| falona |
| false |
| falsehood |
| falsely |
| falsify |
| falsities |
| falsity |
| falstaffian |
| falter |
| faltered |
| faltering |
| falteringly |
| falterings |
| fama |
| fame |
| famed |
| familiar |
| familiarity |
| familiarized |
| familiars |
| families |
| family |
| famine |
| famous |
| fan |
| fanatic |
| fanatical |
| fanatico |
| fanatics |
| fancied |
| fancies |
| fanciful |
| fancy |
| fancying |
| fandango |
| fane |
| fanfaronade |
| fanged |
| fangs |
| fanlight |
| fanlights |
| fanned |
| fans |
| fantaisiste |
| fantasia |
| fantasies |
| fantastic |
| fantastically |
| fantasy |
| faound |
| far |
| farce |
| fare |
| fared |
| farewell |
| farm |
| farmer |
| farmers |
| farmhouse |
| farmhouses |
| farming |
| farms |
| farmstead |
| farmyard |
| farr |
| farrago |
| farther |
| farthermost |
| farthest |
| fascinate |
| fascinated |
| fascinatedly |
| fascinates |
| fascinating |
| fascinatingly |
| fascination |
| fashion |
| fashionable |
| fashionably |
| fashioned |
| fashioning |
| fashions |
| fast |
| fasted |
| fasten |
| fastened |
| fastening |
| fastenings |
| faster |
| fastidious |
| fastidiously |
| fasting |
| fat |
| fatal |
| fatalists |
| fatality |
| fatally |
| fate |
| fated |
| fateful |
| fates |
| father |
| fatherland |
| fatherly |
| fathers |
| fathom |
| fathomed |
| fathoming |
| fathomless |
| fathoms |
| fatigue |
| fatigued |
| fatigues |
| fatiguing |
| fatquack |
| fattened |
| fatty |
| fatui |
| faubourg |
| faucal |
| fault |
| faultiness |
| faults |
| faulty |
| faun |
| fauns |
| faut |
| favor |
| favored |
| favorite |
| favour |
| favourable |
| favourably |
| favoured |
| favourite |
| favourites |
| favours |
| fawn |
| fawning |
| fay |
| fays |
| fear |
| feared |
| fearful |
| fearfully |
| fearing |
| fearless |
| fearlessly |
| fearlessness |
| fears |
| fearsome |
| fearsomely |
| feasible |
| feast |
| feasted |
| feasts |
| feat |
| feather |
| feathered |
| feathers |
| feathery |
| feats |
| feature |
| features |
| feb |
| febrile |
| february |
| fed |
| federal |
| feeble |
| feebler |
| feeblest |
| feebly |
| feed |
| feeding |
| feel |
| feelers |
| feeling |
| feelings |
| feels |
| feered |
| feet |
| feign |
| feigned |
| feignedly |
| feint |
| felicity |
| feline |
| felix |
| fell |
| felled |
| feller |
| felling |
| fellow |
| fellows |
| fellowship |
| fells |
| felon |
| felt |
| feltspar |
| female |
| females |
| feminine |
| femoris |
| fence |
| fenced |
| fences |
| fender |
| fenner |
| fenton |
| fer |
| ferdinand |
| fern |
| ferocious |
| ferocity |
| ferry |
| fertile |
| fertility |
| ferule |
| fervent |
| fervently |
| fervid |
| fervor |
| fervour |
| festered |
| festering |
| festival |
| festivals |
| festive |
| festivity |
| festoons |
| fetched |
| fetching |
| fete |
| fetid |
| fetter |
| fettered |
| fetterless |
| fetters |
| feudal |
| fever |
| fevered |
| feverish |
| feverishly |
| few |
| fewer |
| ff |
| fhtagn |
| fibe |
| fibre |
| fibres |
| fibrous |
| fibula |
| fickleness |
| fiction |
| fictions |
| fictitious |
| fiddle |
| fiddlestick |
| fide |
| fidelity |
| fidget |
| fie |
| field |
| fields |
| fiend |
| fiendish |
| fiendishly |
| fierce |
| fiercely |
| fierceness |
| fiercest |
| fiery |
| fife |
| fifteen |
| fifteenth |
| fifth |
| fiftieth |
| fifty |
| fig |
| figaro |
| figgurs |
| fight |
| fighting |
| figment |
| figurative |
| figuratively |
| figure |
| figured |
| figures |
| fiji |
| filched |
| file |
| filed |
| files |
| filial |
| filigreed |
| filing |
| filius |
| fill |
| filled |
| fillet |
| filleted |
| filling |
| fills |
| film |
| fils |
| filtered |
| filth |
| filthy |
| final |
| finale |
| finally |
| financial |
| financier |
| find |
| finder |
| finding |
| finds |
| fine |
| finely |
| finer |
| finesse |
| finest |
| finger |
| fingernails |
| fingers |
| finicky |
| finish |
| finished |
| finishing |
| finny |
| fins |
| fir |
| fire |
| firearms |
| fireball |
| fired |
| fireflies |
| firemen |
| fireplace |
| fireplaces |
| fires |
| fireside |
| firesides |
| firing |
| firm |
| firma |
| firmament |
| firmanent |
| firmest |
| firmly |
| firmness |
| firs |
| first |
| firstly |
| fish |
| fisher |
| fisherfolk |
| fishermen |
| fishers |
| fishes |
| fishily |
| fishin |
| fishing |
| fishy |
| fissure |
| fissures |
| fist |
| fists |
| fit |
| fitful |
| fitfully |
| fitness |
| fits |
| fitted |
| fitten |
| fitting |
| fittings |
| fitz |
| five |
| fix |
| fixed |
| fixedly |
| fixing |
| fixt |
| fixture |
| fixtures |
| fizz |
| fizzes |
| fizzing |
| flabby |
| flaccid |
| flag |
| flagged |
| flagging |
| flagon |
| flagrant |
| flagrantly |
| flags |
| flagstones |
| flailing |
| flakes |
| flambeaux |
| flamboyant |
| flame |
| flames |
| flaming |
| flanders |
| flanked |
| flapped |
| flapping |
| flared |
| flaring |
| flash |
| flashed |
| flashes |
| flashing |
| flashlight |
| flashy |
| flasks |
| flat |
| flatness |
| flatten |
| flattened |
| flatter |
| flattered |
| flattery |
| flatu |
| flatzplatz |
| flaunted |
| flaunting |
| flaunts |
| flavius |
| flaw |
| flayed |
| fled |
| fledged |
| flee |
| fleecy |
| fleeing |
| flees |
| fleet |
| fleeting |
| fleetly |
| fleets |
| flesh |
| fleshless |
| fleshly |
| fleshy |
| fletcher |
| fleur |
| flew |
| flexibility |
| flexible |
| flicker |
| flickered |
| flickering |
| flickers |
| flies |
| flight |
| flights |
| flimen |
| flimsy |
| fling |
| flinging |
| flint |
| flirt |
| flirtations |
| flirting |
| flitted |
| flitting |
| float |
| floated |
| floating |
| flock |
| flocked |
| flocking |
| flocks |
| flog |
| flogging |
| floggings |
| flood |
| flooded |
| flooding |
| floor |
| floored |
| flooring |
| floors |
| flopping |
| florence |
| florentin |
| florid |
| florins |
| flos |
| flounces |
| floundered |
| floundering |
| flour |
| flourish |
| flourished |
| flourishing |
| flout |
| flouted |
| flow |
| flowed |
| flower |
| flowers |
| flowery |
| flowing |
| flown |
| flows |
| fluctuate |
| fluctuating |
| fluctuations |
| flud |
| flue |
| fluently |
| fluid |
| fluids |
| flung |
| flush |
| flushed |
| flustered |
| flute |
| fluted |
| flutes |
| flutter |
| fluttered |
| fluttering |
| flutterings |
| flux |
| fly |
| flying |
| flyleaves |
| flyspecked |
| foam |
| foamed |
| foaming |
| foamless |
| fob |
| focal |
| focus |
| focussed |
| focussing |
| foe |
| foes |
| foetid |
| foetor |
| fog |
| foible |
| foiled |
| foils |
| fois |
| fol |
| fold |
| folded |
| folding |
| folds |
| foliage |
| folio |
| folk |
| folklore |
| folks |
| follered |
| follies |
| follow |
| followed |
| followers |
| following |
| follows |
| folly |
| fomalhaut |
| fond |
| fonder |
| fondest |
| fondly |
| fondness |
| font |
| food |
| foodless |
| fool |
| foolhardiness |
| foolish |
| fools |
| foot |
| footed |
| footfall |
| footfalls |
| footholds |
| footing |
| footman |
| footmen |
| footnote |
| footpads |
| footprints |
| footrace |
| footstep |
| footsteps |
| footstool |
| foppery |
| for |
| foraging |
| forbade |
| forbear |
| forbearance |
| forbearing |
| forbid |
| forbidden |
| forbidding |
| forbids |
| forbore |
| force |
| forced |
| forces |
| forcible |
| forcibly |
| forcing |
| fore |
| foreboded |
| foreboding |
| forebodings |
| forebore |
| foredoomed |
| forefathers |
| forefinger |
| forego |
| foregoing |
| foreground |
| forehead |
| foreign |
| foreigner |
| foreigners |
| foreman |
| foremost |
| forenoon |
| forensica |
| foreplanned |
| foreruns |
| foresaw |
| foreseen |
| foreshadow |
| foreshadowing |
| foresight |
| forest |
| forested |
| forests |
| forethought |
| foretold |
| foretopsail |
| forever |
| forewarned |
| forfeited |
| forged |
| forget |
| forgetful |
| forgetfulness |
| forgetting |
| forgive |
| forgiveness |
| forgot |
| forgotten |
| fork |
| forked |
| forky |
| forlorn |
| form |
| formal |
| formation |
| formations |
| formed |
| former |
| formerly |
| formidable |
| forming |
| formless |
| forms |
| formula |
| formulae |
| formulated |
| forrad |
| forsake |
| forsaken |
| forsakes |
| forsook |
| forsooth |
| forsyth |
| fort |
| forte |
| forth |
| forthcoming |
| forthwith |
| forties |
| fortifications |
| fortified |
| fortitude |
| fortnight |
| fortress |
| fortuitous |
| fortunate |
| fortunately |
| fortunato |
| fortune |
| fortunes |
| forty |
| forum |
| forward |
| forwards |
| fossillus |
| foster |
| fosterage |
| fostered |
| fostering |
| fought |
| foul |
| fouled |
| foulness |
| found |
| foundation |
| foundations |
| founded |
| founder |
| foundered |
| founders |
| fount |
| fountain |
| fountains |
| four |
| fours |
| fourteen |
| fourteenth |
| fourth |
| fowl |
| fox |
| fra |
| fraction |
| fracture |
| fractured |
| fragile |
| fragility |
| fragment |
| fragmentary |
| fragments |
| fragrance |
| fragrant |
| frail |
| frame |
| framed |
| frames |
| framework |
| france |
| francisco |
| francs |
| frank |
| frankenstein |
| frankish |
| frankly |
| frankness |
| frantic |
| frantically |
| franticly |
| fraser |
| fraternal |
| fraternity |
| fratricide |
| fraud |
| frauds |
| fraught |
| frayed |
| fraying |
| frayle |
| frazer |
| freak |
| fred |
| frederick |
| fredericksburg |
| free |
| freed |
| freedom |
| freedoms |
| freely |
| freemasonry |
| freeze |
| freezes |
| freezing |
| freight |
| freighted |
| freighter |
| frementi |
| french |
| frenchman |
| frenchwoman |
| frenzied |
| frenziedly |
| frenzy |
| frequency |
| frequent |
| frequented |
| frequenting |
| frequently |
| frescos |
| fresh |
| freshened |
| freshest |
| freshets |
| freshly |
| freshness |
| frets |
| fretted |
| fretting |
| freud |
| freyhere |
| fricassée |
| friction |
| friday |
| friend |
| friendless |
| friendly |
| friends |
| friendship |
| friendships |
| frieze |
| friezes |
| frigate |
| fright |
| frighten |
| frightened |
| frightens |
| frightful |
| frightfully |
| frigid |
| frigidity |
| fringe |
| fringed |
| frippery |
| frisked |
| frisking |
| frivolity |
| frivolous |
| fro |
| frock |
| frog |
| frogpondium |
| frogs |
| froissart |
| frolic |
| frolicsome |
| from |
| front |
| frontage |
| fronting |
| frontispiece |
| fronts |
| frost |
| frostily |
| frosts |
| frosty |
| froth |
| frothing |
| frown |
| frowned |
| frowning |
| frowns |
| frows |
| froze |
| frozen |
| fru |
| frugal |
| fruit |
| fruiterer |
| fruitful |
| fruition |
| fruitless |
| fruits |
| frustrate |
| frustrated |
| frxg |
| frxwn |
| fry |
| frye |
| fryes |
| fudge |
| fuel |
| fugitive |
| fugitives |
| fugue |
| fulfil |
| fulfill |
| fulfilled |
| fulfilling |
| fulfilment |
| fulgently |
| fulgurite |
| fulgurites |
| full |
| fuller |
| fullest |
| fullin |
| fullness |
| fully |
| fulness |
| fulsomely |
| fum |
| fumbled |
| fumbling |
| fume |
| fumes |
| fumigate |
| fun |
| function |
| functionaries |
| functionary |
| functions |
| funds |
| funeral |
| funerals |
| funereal |
| funeste |
| fungi |
| fungous |
| fungus |
| funnel |
| funnin |
| funny |
| fur |
| furies |
| furious |
| furiously |
| furius |
| furled |
| furlong |
| furnace |
| furnaces |
| furnish |
| furnished |
| furnishing |
| furnishings |
| furniture |
| furren |
| furrier |
| furrow |
| furrows |
| furry |
| furs |
| further |
| furtherance |
| furthering |
| furthermore |
| furthest |
| furtive |
| furtively |
| furtiveness |
| fury |
| furze |
| fuseli |
| fusion |
| fuss |
| fussy |
| fust |
| futile |
| futility |
| future |
| futurism |
| futurity |
| fuzzy |
| fxr |
| fxwl |
| fxxl |
| gabalah |
| gabinius |
| gable |
| gables |
| gad |
| gagne |
| gaieties |
| gaiety |
| gaily |
| gain |
| gained |
| gaining |
| gainsay |
| gainsayed |
| gait |
| gala |
| galaxy |
| gale |
| gales |
| gall |
| gallant |
| gallantly |
| galled |
| galleon |
| galleons |
| galleries |
| gallery |
| galley |
| galleys |
| galling |
| gallons |
| galloped |
| gallopin |
| galloping |
| gallows |
| galopped |
| galpin |
| galvanic |
| galvanised |
| galvanism |
| galvez |
| gambler |
| gambling |
| gambols |
| gambrel |
| game |
| gamekeeper |
| gamekeepers |
| games |
| gamesome |
| gaming |
| gammell |
| gammoned |
| gang |
| gangs |
| gangway |
| ganzas |
| gaol |
| gaoler |
| gap |
| gaping |
| gaps |
| garb |
| garbed |
| garden |
| gardener |
| gardening |
| gardens |
| gargantua |
| gargoyle |
| gargoyles |
| garish |
| garlanded |
| garment |
| garments |
| garnered |
| garret |
| garrets |
| garrett |
| garrick |
| garrison |
| garrulous |
| garrulously |
| garrulousness |
| garter |
| garters |
| gas |
| gaseous |
| gases |
| gash |
| gashes |
| gasless |
| gasoline |
| gasp |
| gasped |
| gaspin |
| gasping |
| gaspingly |
| gasps |
| gastronomy |
| gate |
| gates |
| gateway |
| gateways |
| gather |
| gathered |
| gathering |
| gathers |
| gaudy |
| gauges |
| gaunt |
| gauntlet |
| gauntleted |
| gauze |
| gave |
| gawd |
| gay |
| gayest |
| gaze |
| gazed |
| gazelle |
| gazes |
| gazette |
| gazing |
| ge |
| gelatinous |
| gem |
| gemmary |
| gems |
| gen |
| gendarme |
| genealogical |
| genealogy |
| genera |
| general |
| generality |
| generalization |
| generally |
| generate |
| generated |
| generation |
| generations |
| generator |
| generosity |
| generous |
| generously |
| geneva |
| genevese |
| genial |
| geniality |
| genially |
| genius |
| geniuses |
| genoese |
| gentilhomme |
| gentle |
| gentleman |
| gentlemanly |
| gentlemen |
| gentleness |
| gentler |
| gentlest |
| gentlewoman |
| gently |
| gentry |
| genuine |
| genuinely |
| genuineness |
| genus |
| geoffrey |
| geographer |
| geographical |
| geographically |
| geological |
| geologists |
| geology |
| geometrical |
| geometry |
| george |
| georgian |
| georgio |
| geraniums |
| germ |
| germain |
| german |
| germany |
| gerrit |
| gesticulate |
| gesticulations |
| gesture |
| gestures |
| get |
| gets |
| getting |
| gewgaws |
| gh |
| ghast |
| ghastliest |
| ghastly |
| ghazi |
| ghost |
| ghostly |
| ghosts |
| ghoul |
| ghoulish |
| ghouls |
| giant |
| gib |
| gibber |
| gibbered |
| gibbering |
| gibberish |
| gibbers |
| gibbon |
| gibbous |
| giddiness |
| giddy |
| gifford |
| gift |
| gifted |
| gifts |
| gigantic |
| gilded |
| gills |
| gilman |
| gilt |
| gimlet |
| gimlets |
| gin |
| ginger |
| gingerly |
| giovanni |
| gipsey |
| gird |
| girdle |
| girdled |
| girl |
| girlish |
| girls |
| girt |
| girth |
| girting |
| gist |
| git |
| gits |
| gittin |
| give |
| given |
| giver |
| gives |
| giving |
| glaciation |
| glacier |
| glad |
| gladdens |
| glade |
| glades |
| gladiatorial |
| gladly |
| gladness |
| glamour |
| glance |
| glanced |
| glances |
| glancing |
| gland |
| glanvill |
| glare |
| glared |
| glaring |
| glass |
| glasses |
| glasshouse |
| glassily |
| glassy |
| glaze |
| glazed |
| glazing |
| gleam |
| gleamed |
| gleaming |
| gleams |
| glean |
| gleaned |
| glee |
| glen |
| glendinning |
| glens |
| glide |
| glided |
| glides |
| gliding |
| glimmer |
| glimmered |
| glimmering |
| glimmers |
| glimpse |
| glimpsed |
| glimpses |
| glistened |
| glistening |
| glitter |
| glittered |
| glittering |
| gloaming |
| globe |
| globes |
| gloom |
| gloomily |
| gloomy |
| gloried |
| glories |
| glorified |
| glorifying |
| glorious |
| gloriously |
| glory |
| gloss |
| glossy |
| glove |
| gloved |
| glover |
| gloves |
| glow |
| glowed |
| glowing |
| glows |
| glut |
| glutinous |
| glutted |
| gnai |
| gnarled |
| gnashed |
| gnashes |
| gnashing |
| gnawed |
| gnawing |
| gnophkehs |
| gnorri |
| go |
| goaded |
| goading |
| goal |
| goat |
| goatish |
| goats |
| gobletful |
| goblets |
| goblins |
| god |
| goddess |
| goddesses |
| godfrey |
| godhead |
| godless |
| godlike |
| gods |
| goes |
| goest |
| gog |
| goggle |
| goignard |
| goin |
| going |
| goings |
| gol |
| golconda |
| gold |
| golden |
| goldsmith |
| golf |
| golly |
| gondola |
| gone |
| gongs |
| good |
| goodly |
| goodman |
| goodness |
| goods |
| goole |
| goose |
| gooseflesh |
| goosetherumfoodle |
| gore |
| gorge |
| gorgeous |
| gorgeously |
| gorges |
| gorgias |
| gorilla |
| goring |
| gory |
| gossamer |
| gossip |
| got |
| gothic |
| gott |
| gotten |
| gouge |
| gouged |
| gougings |
| gout |
| gouty |
| gov |
| govern |
| governance |
| governed |
| governing |
| government |
| governments |
| governors |
| gown |
| goya |
| grabs |
| grace |
| graceful |
| gracefully |
| gracefulness |
| graces |
| gracious |
| graciously |
| gradation |
| gradations |
| grade |
| grades |
| gradual |
| gradually |
| graduate |
| graduated |
| gran |
| granary |
| grand |
| grandam |
| grandchildren |
| grande |
| grandeur |
| grandfather |
| grandiloquence |
| grandjean |
| grandmother |
| grandmothers |
| grandson |
| granite |
| grano |
| grant |
| granted |
| granting |
| granulated |
| graoun |
| graound |
| grape |
| grapnel |
| grapple |
| grappling |
| grasp |
| grasped |
| grasping |
| grass |
| grasses |
| grasshoppers |
| grassy |
| grate |
| grated |
| grateful |
| gratification |
| gratifie |
| gratified |
| gratify |
| gratifying |
| grating |
| gratitude |
| gratulation |
| grave |
| gravel |
| gravely |
| graven |
| graver |
| graves |
| gravesend |
| gravest |
| gravestones |
| graveyard |
| graveyards |
| gravitating |
| gravitation |
| gravity |
| gray |
| grayish |
| grazed |
| grazes |
| grazing |
| grease |
| greaser |
| greasily |
| greasiness |
| great |
| greater |
| greatest |
| greatly |
| greatness |
| greaves |
| grecian |
| grecians |
| greece |
| greedily |
| greedy |
| greek |
| greeks |
| green |
| greene |
| greenery |
| greenest |
| greenish |
| greenland |
| greenwich |
| greeted |
| gregory |
| gresset |
| grew |
| grey |
| greyed |
| greyish |
| greyness |
| grief |
| griefs |
| grieve |
| grieved |
| grieving |
| grim |
| grimaces |
| grimacing |
| grimm |
| grimy |
| grin |
| grinders |
| grinding |
| grinned |
| grinning |
| grins |
| grip |
| grisette |
| grisly |
| griswold |
| grkdl |
| groan |
| groaned |
| groans |
| grocery |
| grooms |
| grope |
| groped |
| groping |
| gropingly |
| gross |
| grossly |
| grotesque |
| grotesquely |
| grotesqueness |
| grotesquerie |
| grotesques |
| grotto |
| grottoes |
| ground |
| grounded |
| grounds |
| groundwork |
| group |
| groupe |
| grouped |
| groupes |
| grouping |
| groups |
| grove |
| grovel |
| grovelled |
| grovelling |
| groves |
| grow |
| growing |
| growl |
| growled |
| growling |
| grown |
| grows |
| growth |
| growths |
| grub |
| grubs |
| grudge |
| grudgingly |
| gruesome |
| gruesomely |
| gruff |
| grumble |
| grumbling |
| grumblingly |
| grunted |
| grunting |
| gruntundguzzell |
| grxwl |
| grâve |
| gualtier |
| guarantee |
| guard |
| guarda |
| guarded |
| guardedly |
| guardian |
| guardians |
| guardianship |
| guarding |
| guards |
| guerre |
| guess |
| guessed |
| guesser |
| guesses |
| guessing |
| guesswork |
| guest |
| guests |
| guffaw |
| guidance |
| guide |
| guided |
| guides |
| guiding |
| guido |
| guilders |
| guile |
| guileless |
| guilelessness |
| guilt |
| guiltless |
| guiltlessness |
| guilty |
| guinea |
| guineas |
| guise |
| guitar |
| gulch |
| gulf |
| gulfs |
| gullible |
| gulliver |
| gulph |
| gulping |
| gum |
| gums |
| gun |
| gunning |
| gunpowder |
| guns |
| gurgled |
| gurgling |
| gush |
| gushed |
| gust |
| gustaf |
| gusts |
| gusty |
| guts |
| gutta |
| gutter |
| gutters |
| guttural |
| guyon |
| gx |
| gxt |
| gxxd |
| gxxse |
| gypsies |
| gypsy |
| gyratory |
| ha |
| haardrada |
| hab |
| habet |
| habiliment |
| habiliments |
| habit |
| habitable |
| habitat |
| habitation |
| habitations |
| habited |
| habits |
| habitual |
| habitually |
| habitués |
| hack |
| hackney |
| had |
| hades |
| hadoth |
| hadst |
| haeckel |
| haemus |
| haff |
| hag |
| haggard |
| haggardness |
| hail |
| hailed |
| hailing |
| hain |
| hair |
| haired |
| hairs |
| hairy |
| halcyon |
| half |
| halfway |
| hall |
| hallmark |
| halloo |
| hallowe |
| hallowmass |
| halls |
| hallucination |
| hallway |
| halo |
| halsey |
| halt |
| halted |
| halting |
| hamburgh |
| hamlet |
| hamlets |
| hammer |
| hammers |
| hammond |
| hamper |
| hampshire |
| han |
| hand |
| handbills |
| handed |
| handily |
| handiwork |
| handkerchief |
| handkerchiefs |
| handle |
| handled |
| handles |
| handling |
| handmaid |
| hands |
| handsom |
| handsome |
| handsomely |
| handsomest |
| handwriting |
| handy |
| hang |
| hanged |
| hangers |
| hanging |
| hangings |
| hangman |
| hangs |
| hankered |
| hannah |
| hans |
| haour |
| haouse |
| haousekeeper |
| haouses |
| haow |
| haowever |
| hapless |
| happen |
| happened |
| happening |
| happenings |
| happens |
| happier |
| happiest |
| happily |
| happiness |
| happy |
| harangue |
| harass |
| harassed |
| harassing |
| harbour |
| harbourage |
| harboured |
| harbours |
| hard |
| harden |
| hardened |
| hardens |
| harder |
| hardheartedness |
| hardly |
| hardness |
| hardship |
| hardships |
| hardware |
| hardy |
| hare |
| harem |
| hares |
| hark |
| harkened |
| harlaem |
| harley |
| harm |
| harmed |
| harmful |
| harmfully |
| harmless |
| harmlessly |
| harmonic |
| harmonies |
| harmonized |
| harmony |
| harnessed |
| harold |
| harolde |
| harp |
| harpies |
| harris |
| harrison |
| harrowing |
| harry |
| harsh |
| harshest |
| harshness |
| hartley |
| hartwell |
| harvard |
| harvest |
| harvests |
| has |
| hasheesh |
| hasp |
| hast |
| haste |
| hasten |
| hastened |
| hastening |
| hastens |
| hastily |
| hasting |
| hastings |
| hasty |
| hat |
| hatch |
| hatches |
| hatchet |
| hatchway |
| hate |
| hated |
| hateful |
| hath |
| hatheg |
| hathorne |
| hating |
| hatless |
| hatred |
| hats |
| hatteras |
| haubrion |
| haughtiest |
| haughtily |
| haughtiness |
| haughty |
| hauled |
| haunt |
| haunted |
| haunting |
| hauntingly |
| haunts |
| hauteur |
| have |
| haven |
| haverhill |
| havin |
| having |
| havn |
| havoc |
| hawk |
| hawkins |
| hawks |
| hay |
| hayti |
| hazard |
| hazarded |
| hazardous |
| haze |
| hazel |
| hazle |
| hazy |
| he |
| head |
| headache |
| headboard |
| headed |
| headin |
| headlands |
| headless |
| headline |
| headlong |
| headquarters |
| heads |
| headstone |
| headway |
| heal |
| healed |
| healing |
| health |
| healthily |
| healthy |
| heap |
| heaped |
| heaps |
| hear |
| heard |
| hearer |
| hearers |
| hearing |
| hearken |
| hearkened |
| hearkening |
| hears |
| hearse |
| heart |
| hearted |
| heartened |
| heartfelt |
| heartful |
| hearth |
| hearths |
| heartily |
| heartless |
| hearts |
| hearty |
| heat |
| heated |
| heath |
| heathen |
| heathens |
| heather |
| heaths |
| heatless |
| heats |
| heave |
| heaved |
| heaven |
| heavenly |
| heavens |
| heavier |
| heaviest |
| heavily |
| heaviness |
| heaving |
| heavy |
| hebby |
| hebrew |
| hebrus |
| hectic |
| hedelin |
| hedged |
| hedges |
| heed |
| heeded |
| heeding |
| heedlessly |
| heedlessness |
| heel |
| heeled |
| heels |
| heem |
| heerd |
| hees |
| heh |
| heigho |
| height |
| heighten |
| heightened |
| heightening |
| heights |
| heir |
| heiress |
| heirloom |
| heirs |
| heirship |
| heisenberg |
| helas |
| held |
| helena |
| heliogabalus |
| hell |
| hellas |
| hellespont |
| hellish |
| hells |
| helm |
| helmet |
| helmeted |
| heloise |
| help |
| helped |
| helpers |
| helpful |
| helping |
| helpless |
| helplessly |
| helplessness |
| helps |
| helseggen |
| helvia |
| helvius |
| hem |
| hemisphere |
| hemispherical |
| hemlock |
| hemmed |
| hems |
| hen |
| hence |
| henceforth |
| henceforward |
| henna |
| henri |
| henris |
| henry |
| hens |
| henson |
| her |
| heraclides |
| heraclitus |
| herb |
| herbert |
| herbless |
| herculean |
| herd |
| herds |
| here |
| hereabaouts |
| hereabouts |
| hereafter |
| hereditary |
| heredity |
| herein |
| heresy |
| heretical |
| heretofore |
| hereupon |
| heritage |
| herman |
| hermann |
| hermes |
| hermit |
| hermitess |
| hero |
| herod |
| heroded |
| herodes |
| heroes |
| heroic |
| heroism |
| herrero |
| hers |
| herschel |
| herself |
| hesitancy |
| hesitate |
| hesitated |
| hesitates |
| hesitating |
| hesitation |
| hessian |
| heterodox |
| heterogeneous |
| hetfield |
| hev |
| hevin |
| hewn |
| hey |
| hez |
| hi |
| hibernate |
| hickories |
| hickory |
| hid |
| hidden |
| hide |
| hideous |
| hideously |
| hideousness |
| hides |
| hiding |
| hieroglyphed |
| hieroglyphical |
| hieroglyphics |
| hieronymus |
| high |
| higher |
| highest |
| highland |
| highlands |
| highly |
| highness |
| highway |
| hilarity |
| hill |
| hillock |
| hillocks |
| hills |
| hillside |
| hillsides |
| hilly |
| him |
| himself |
| hind |
| hindered |
| hindoo |
| hindostan |
| hindrance |
| hindrances |
| hinges |
| hinnon |
| hint |
| hinted |
| hinting |
| hints |
| hipped |
| hippocratian |
| hippodrome |
| hippopotami |
| hips |
| hiram |
| hire |
| hired |
| his |
| hispanicised |
| hissed |
| hisself |
| hissing |
| histoire |
| historian |
| historic |
| historical |
| histories |
| history |
| hit |
| hitching |
| hither |
| hitherto |
| hittin |
| hitting |
| hive |
| hna |
| ho |
| hoadley |
| hoard |
| hoarded |
| hoarse |
| hoarsely |
| hoarser |
| hoary |
| hoax |
| hoaxes |
| hoaxy |
| hobbies |
| hobbling |
| hobby |
| hoe |
| hog |
| hogarth |
| hoggishly |
| hogs |
| hogshead |
| hogsheads |
| holberg |
| holborn |
| hold |
| holder |
| holders |
| holdest |
| holding |
| holds |
| hole |
| holes |
| holiday |
| holidays |
| holland |
| hollander |
| hollow |
| hollowed |
| hollowly |
| hollowness |
| hollows |
| holt |
| holy |
| homage |
| home |
| homeless |
| homely |
| homer |
| homes |
| homesick |
| homestead |
| homeward |
| homewards |
| homicidal |
| homilies |
| hominis |
| hommy |
| homo |
| homogeneity |
| homogeneous |
| homologous |
| homouioisios |
| homousios |
| honest |
| honestly |
| honesty |
| honey |
| honeyed |
| honeysuckle |
| honor |
| honorable |
| honored |
| honors |
| honour |
| honourable |
| honoured |
| honours |
| hoo |
| hood |
| hoof |
| hook |
| hooked |
| hooking |
| hoop |
| hooper |
| hooved |
| hooves |
| hop |
| hope |
| hoped |
| hopeful |
| hopeless |
| hopelessly |
| hopelessness |
| hopes |
| hoping |
| hopkins |
| hopless |
| hoppin |
| hopping |
| horace |
| horde |
| hordes |
| horizon |
| horizontal |
| horizontally |
| horn |
| horned |
| horns |
| horrendum |
| horreur |
| horrible |
| horribly |
| horrid |
| horridly |
| horrific |
| horrified |
| horrizon |
| horror |
| horrorless |
| horrors |
| horse |
| horseback |
| horseman |
| horsemen |
| horses |
| hose |
| hospitable |
| hospital |
| hospitality |
| hospitals |
| hosses |
| host |
| hostages |
| hostel |
| hostess |
| hostile |
| hostility |
| hosts |
| hot |
| hotel |
| hotels |
| hotholm |
| hottentot |
| hottest |
| houghton |
| hound |
| hour |
| hourly |
| hours |
| house |
| housed |
| household |
| housekeeper |
| houseless |
| houses |
| housewife |
| housework |
| hove |
| hovel |
| hovels |
| hover |
| hovered |
| hovering |
| hovers |
| how |
| however |
| howl |
| howled |
| howling |
| howlings |
| howls |
| hoyle |
| hsan |
| hu |
| hub |
| hubbub |
| huddle |
| huddled |
| huddles |
| huddling |
| hue |
| hued |
| hues |
| hug |
| huge |
| hugh |
| hulk |
| hull |
| hulls |
| hum |
| human |
| humane |
| humanities |
| humanity |
| humanized |
| humankind |
| humanly |
| humanness |
| humble |
| humbled |
| humboldt |
| humdrum |
| humid |
| humiliation |
| humility |
| hummed |
| humming |
| hummock |
| hummocks |
| humor |
| humored |
| humoredly |
| humour |
| humoured |
| humped |
| humph |
| humphrey |
| hundred |
| hundredfold |
| hundreds |
| hundredth |
| hung |
| hungarians |
| hungary |
| hunger |
| hungry |
| hunks |
| hunt |
| hunted |
| hunter |
| hunting |
| huntingdon |
| huntress |
| huomo |
| hurl |
| hurled |
| hurlygurly |
| hurrah |
| hurricane |
| hurried |
| hurriedly |
| hurries |
| hurry |
| hurrying |
| hurt |
| hurtless |
| husban |
| husband |
| husbandman |
| husbands |
| hush |
| hushed |
| hushing |
| huskiness |
| husky |
| hut |
| hutchins |
| huts |
| huzzy |
| hx |
| hxg |
| hxllx |
| hxme |
| hxmx |
| hxw |
| hxwl |
| hyacinth |
| hyaline |
| hybrid |
| hybrids |
| hyde |
| hydes |
| hydra |
| hydrangea |
| hydrogen |
| hyena |
| hygienic |
| hymettus |
| hymn |
| hymns |
| hyper |
| hypnotic |
| hypnotised |
| hypochondriac |
| hypocrisy |
| hypocritical |
| hypocritically |
| hypothenuse |
| hypotheses |
| hypothesis |
| hypothetical |
| hysterical |
| hysterics |
| ian |
| ib |
| iberus |
| ibid |
| ibidus |
| ibn |
| icarus |
| ice |
| ices |
| ich |
| ichor |
| ichthyic |
| iciness |
| icy |
| idea |
| ideal |
| idealised |
| ideality |
| idealized |
| ideals |
| ideas |
| idee |
| idees |
| identical |
| identification |
| identified |
| identifies |
| identify |
| identifying |
| identity |
| idiocy |
| idiom |
| idiomatic |
| idiosyncrasy |
| idiosyncratic |
| idiot |
| idiotcy |
| idiotic |
| idiotically |
| idiots |
| idle |
| idleness |
| idlers |
| idly |
| idol |
| idolatrous |
| idolatry |
| idolized |
| idols |
| idris |
| if |
| ignes |
| ignited |
| ignoble |
| ignominious |
| ignominy |
| ignoramus |
| ignorance |
| ignorant |
| ignorantly |
| ignoratio |
| ignore |
| ignotum |
| ii |
| iii |
| il |
| ilarnek |
| ilek |
| ill |
| illegible |
| illimitable |
| illinois |
| illiterate |
| illness |
| illnesses |
| illogically |
| ills |
| illumed |
| illuminate |
| illuminated |
| illuminating |
| illumination |
| illumine |
| illumined |
| illusion |
| illusions |
| illustrate |
| illustrated |
| illustration |
| illustrations |
| illustrious |
| illyrian |
| image |
| imaged |
| imagery |
| images |
| imaginable |
| imaginary |
| imagination |
| imaginations |
| imaginative |
| imagine |
| imagined |
| imagines |
| imagining |
| imaginings |
| imbedded |
| imbibe |
| imbibed |
| imbibes |
| imbue |
| imbued |
| imitate |
| imitated |
| imitating |
| imitation |
| imitative |
| immaculate |
| immaculateness |
| immaterial |
| immateriality |
| immature |
| immeasurable |
| immeasurably |
| immediate |
| immediately |
| immedicable |
| immedicinable |
| immemorial |
| immemorially |
| immense |
| immensely |
| immensity |
| immerse |
| immersed |
| immersion |
| immethodical |
| imminent |
| immobile |
| immolation |
| immortal |
| immortalise |
| immortality |
| immovability |
| immovable |
| immovably |
| immoveable |
| immundane |
| immunity |
| immured |
| immutable |
| imp |
| impacts |
| impaired |
| impairment |
| impalpability |
| impalpable |
| imparadized |
| impart |
| imparted |
| impartial |
| impartiality |
| imparts |
| impassable |
| impassioned |
| impassive |
| impatience |
| impatient |
| impatiently |
| impeded |
| impediment |
| impediments |
| impelled |
| impels |
| impend |
| impended |
| impending |
| impends |
| impenetrable |
| impenetrably |
| imperative |
| imperatively |
| imperceptible |
| imperceptibly |
| imperfect |
| imperfection |
| imperfectly |
| imperial |
| imperiled |
| imperious |
| imperiously |
| imperishable |
| imperium |
| impersonal |
| impertinence |
| impertinences |
| impertinent |
| impervious |
| impetuosity |
| impetuous |
| impetuously |
| impetus |
| impinging |
| impious |
| implant |
| implanted |
| implements |
| implicated |
| implications |
| implicit |
| implicitly |
| implied |
| implies |
| implore |
| implored |
| imply |
| import |
| importance |
| important |
| imported |
| importunate |
| importuning |
| imposed |
| imposing |
| impositions |
| impossibile |
| impossibilities |
| impossibility |
| impossible |
| impost |
| impostor |
| imposture |
| impostures |
| impotence |
| impotent |
| impracticability |
| impracticable |
| imprecations |
| impregnable |
| impregnated |
| impregnating |
| impregnation |
| impress |
| impressed |
| impresses |
| impressing |
| impression |
| impressionistic |
| impressions |
| impressive |
| impressiveness |
| imprimus |
| imprint |
| imprinted |
| imprisoned |
| imprisonment |
| improbability |
| improbable |
| impromptu |
| impromptus |
| impropriety |
| improve |
| improved |
| improvement |
| improvements |
| improvidence |
| improvisatori |
| improvised |
| improviso |
| imprudence |
| imprudent |
| imprudently |
| imps |
| impudent |
| impulse |
| impulses |
| impulsive |
| impune |
| impunity |
| in |
| inability |
| inaccessible |
| inaccuracy |
| inaccurate |
| inaccurately |
| inaction |
| inactive |
| inadequate |
| inadvertence |
| inane |
| inanimate |
| inapplicable |
| inappreciable |
| inappropriate |
| inappropriateness |
| inaptitude |
| inarticulate |
| inarticulateness |
| inasmuch |
| inattentive |
| inaudible |
| inaudibly |
| inbreeding |
| incalculable |
| incandescence |
| incantation |
| incantations |
| incapable |
| incapacity |
| incarnate |
| incarnated |
| incarnation |
| incense |
| incensed |
| incentive |
| incessant |
| incessantly |
| inch |
| inches |
| inchoate |
| incident |
| incidents |
| incinerate |
| incinerated |
| incinerator |
| incipient |
| incision |
| incisions |
| incitement |
| incivility |
| inclemency |
| inclement |
| inclination |
| inclinations |
| incline |
| inclined |
| inclosure |
| include |
| included |
| includes |
| including |
| incognitae |
| incoherence |
| incoherent |
| incoherently |
| income |
| incommoded |
| incommodious |
| incommunicable |
| incomparable |
| incomparably |
| incompatible |
| incomplete |
| incomprehensible |
| inconceivable |
| inconceivably |
| inconclusive |
| incongruities |
| incongruity |
| incongruous |
| inconsequence |
| inconsequential |
| inconsiderable |
| inconsistency |
| inconsistent |
| inconspicuously |
| inconstant |
| incontestably |
| incontrovertible |
| inconvenience |
| inconveniences |
| inconvenient |
| inconveniently |
| incorporated |
| incorporation |
| incorruptible |
| increase |
| increased |
| increases |
| increasing |
| increasingly |
| incredible |
| incredibly |
| incredulity |
| incredulous |
| incredulously |
| incubus |
| inculpate |
| incumbent |
| incurable |
| incurr |
| incurred |
| incursion |
| incursions |
| indaginé |
| indebted |
| indecent |
| indecision |
| indecisive |
| indecisively |
| indeed |
| indefatigable |
| indefinable |
| indefinite |
| indefinitely |
| indelible |
| indelibly |
| indelicate |
| indemnity |
| indentations |
| indenture |
| indentures |
| independance |
| independant |
| independence |
| independent |
| independently |
| indescribable |
| indescribably |
| indeterminate |
| indeterminately |
| index |
| india |
| indian |
| indians |
| indicate |
| indicated |
| indicates |
| indicating |
| indication |
| indications |
| indicative |
| indifference |
| indifferent |
| indigent |
| indignant |
| indignantly |
| indignation |
| indirect |
| indiscernible |
| indiscretions |
| indiscriminate |
| indispensable |
| indisposed |
| indisposition |
| indisputably |
| indissoluble |
| indissolubly |
| indistinct |
| indistinctly |
| indistinguishable |
| indite |
| inditer |
| inditing |
| indivduationis |
| individual |
| individuality |
| individualized |
| individuallity |
| individually |
| individuals |
| indivisible |
| indolence |
| indolent |
| indoors |
| indubitably |
| induce |
| induced |
| inducement |
| inducing |
| induct |
| induction |
| inductions |
| inductive |
| indulge |
| indulged |
| indulgence |
| indulges |
| indulging |
| indus |
| industrious |
| industriously |
| industry |
| ineffable |
| ineffaceably |
| ineffective |
| ineffectual |
| inefficient |
| ineptum |
| inequalities |
| inequality |
| ineradicable |
| inert |
| inertia |
| inertiæ |
| inertness |
| inestimable |
| inevitable |
| inevitably |
| inexcusably |
| inexhaustible |
| inexorable |
| inexpensive |
| inexperience |
| inexplicable |
| inexplicably |
| inexpressible |
| inexpressibles |
| inexpressibly |
| inexpressive |
| inextinguishable |
| inextricable |
| inextricably |
| infallible |
| infallibly |
| infamous |
| infamy |
| infancy |
| infant |
| infantile |
| infantine |
| infants |
| infatuation |
| infected |
| infection |
| infectious |
| infer |
| inference |
| inferences |
| inferior |
| inferiority |
| inferiors |
| infernal |
| infernall |
| infernally |
| inferred |
| infested |
| infidelity |
| infidels |
| infinite |
| infinitely |
| infinities |
| infinitude |
| infinity |
| infirm |
| infirmities |
| infirmity |
| infix |
| infixed |
| inflamed |
| inflammatory |
| inflated |
| inflation |
| inflections |
| inflexible |
| inflexibly |
| inflict |
| inflicted |
| influence |
| influenced |
| influences |
| influential |
| influx |
| info |
| inform |
| informant |
| informants |
| information |
| informe |
| informed |
| informing |
| informs |
| infrequent |
| infuse |
| infused |
| infusing |
| ing |
| ingenious |
| ingens |
| ingenuity |
| ingenuous |
| ingiusto |
| inglitch |
| inglorious |
| ingloriously |
| ingolstadt |
| ingrain |
| ingratiating |
| ingratitude |
| ingredients |
| ingress |
| inhabit |
| inhabitant |
| inhabitants |
| inhabited |
| inhabiting |
| inhalation |
| inhalations |
| inhaling |
| inharmonious |
| inherit |
| inheritance |
| inherited |
| inhuman |
| inhumanly |
| inhumation |
| inhumed |
| inimitable |
| iniquities |
| initial |
| initials |
| initiate |
| initiated |
| initiating |
| initiative |
| injected |
| injudicious |
| injunction |
| injunctions |
| injure |
| injured |
| injurer |
| injuriae |
| injuries |
| injurious |
| injury |
| injustice |
| injy |
| ink |
| inkling |
| inky |
| inlaid |
| inland |
| inlet |
| inly |
| inmate |
| inmates |
| inmost |
| inn |
| innate |
| inner |
| innermost |
| innkeeper |
| innocence |
| innocent |
| innocently |
| innovation |
| innsmouth |
| innumerable |
| inoccupation |
| inopportuneness |
| inordinate |
| inordinately |
| inorganic |
| inorganization |
| inquest |
| inquietude |
| inquire |
| inquired |
| inquirendo |
| inquirer |
| inquiries |
| inquiring |
| inquiry |
| inquisition |
| inquisitive |
| inquisitiveness |
| inquisitorial |
| inroads |
| ins |
| insane |
| insanely |
| insanity |
| insatiable |
| insatiate |
| inscribed |
| inscription |
| inscriptions |
| inscrutability |
| inscrutable |
| insect |
| insects |
| insensate |
| insensibility |
| insensible |
| insensibly |
| insensitive |
| inseparable |
| insert |
| inserted |
| insertion |
| inserts |
| inside |
| insidious |
| insight |
| insignia |
| insignificance |
| insignificant |
| insinuate |
| insinuated |
| insinuations |
| insipid |
| insipidity |
| insist |
| insisted |
| insistence |
| insistent |
| insistently |
| insisting |
| insists |
| insolence |
| insolent |
| insolubility |
| insoluble |
| insomnia |
| inspecting |
| inspection |
| inspector |
| inspiration |
| inspire |
| inspired |
| inspires |
| inspiring |
| inspirited |
| inspiriting |
| inst |
| instability |
| install |
| instance |
| instanced |
| instances |
| instant |
| instantaneous |
| instantaneously |
| instantiae |
| instantly |
| instead |
| instigate |
| instigated |
| instigating |
| instil |
| instilled |
| instinct |
| instinctive |
| instinctively |
| instincts |
| institute |
| instituted |
| institution |
| institutions |
| instruct |
| instructed |
| instruction |
| instructions |
| instructor |
| instructors |
| instructorship |
| instructress |
| instrument |
| instrumental |
| instrumentality |
| instruments |
| insufferable |
| insufferably |
| insufficient |
| insulated |
| insult |
| insulted |
| insultingly |
| insults |
| insuperable |
| insupportable |
| insurance |
| insure |
| insurmountable |
| int |
| intact |
| intangible |
| inted |
| integral |
| integrated |
| integrity |
| intellect |
| intellects |
| intellectual |
| intellectually |
| intelligence |
| intelligences |
| intelligent |
| intelligently |
| intelligible |
| intemperance |
| intemperate |
| intend |
| intended |
| intending |
| intends |
| intense |
| intensely |
| intensified |
| intensify |
| intensities |
| intensity |
| intent |
| intention |
| intentional |
| intentionally |
| intentions |
| intently |
| intentness |
| intents |
| intercept |
| intercepted |
| interchange |
| interchanged |
| intercourse |
| interest |
| interested |
| interesting |
| interests |
| interfere |
| interfered |
| interference |
| interferin |
| interim |
| interior |
| interiorly |
| interjectional |
| interloper |
| intermarried |
| intermarrying |
| intermediaries |
| intermediate |
| interment |
| interments |
| interminable |
| interminableness |
| interminably |
| intermingled |
| intermingling |
| intermittent |
| intermixed |
| internal |
| internally |
| international |
| interposed |
| interpret |
| interpretation |
| interpreted |
| interpreter |
| interred |
| interregnum |
| interrogators |
| interrupt |
| interrupted |
| interrupting |
| interruption |
| interruptions |
| intersect |
| intersection |
| interspaces |
| intersperse |
| interspersed |
| intersperses |
| interspersing |
| interstices |
| interupted |
| interval |
| intervals |
| intervene |
| intervened |
| intervening |
| intervention |
| interview |
| interviews |
| interweaving |
| intimacies |
| intimacy |
| intimate |
| intimated |
| intimately |
| intimates |
| intimation |
| intimidate |
| intimidated |
| into |
| intolerable |
| intolerably |
| intolerant |
| intonation |
| intoxicate |
| intoxicated |
| intoxicating |
| intoxication |
| intra |
| intracacies |
| intractable |
| intrepid |
| intricacies |
| intricacy |
| intricate |
| intricately |
| intriguant |
| intrigue |
| intrigues |
| intriguing |
| intrinsic |
| introduce |
| introduced |
| introducing |
| introduction |
| intrude |
| intruded |
| intruder |
| intruders |
| intruding |
| intrusion |
| intrusions |
| intrusive |
| intuition |
| intuitions |
| intuitive |
| inundating |
| inundation |
| inurned |
| inutility |
| inutos |
| invade |
| invaded |
| invader |
| invaders |
| invalid |
| invalidism |
| invariable |
| invariably |
| invasion |
| invent |
| invented |
| invention |
| inventions |
| inventive |
| inventor |
| inventus |
| inversion |
| inverts |
| invest |
| invested |
| investigate |
| investigated |
| investigating |
| investigation |
| investigations |
| investigator |
| investigators |
| investment |
| invests |
| inveterate |
| invidious |
| invigorated |
| invincible |
| inviolate |
| invisible |
| invitation |
| invitations |
| invite |
| invited |
| invites |
| inviting |
| invitingly |
| invoked |
| involuntarily |
| involuntary |
| involute |
| involutions |
| involve |
| involved |
| involving |
| inward |
| inwardly |
| ionia |
| ionian |
| ionic |
| ipswich |
| iranon |
| irascibility |
| irdonozur |
| ireland |
| irem |
| iridescent |
| irish |
| irksome |
| iron |
| ironclad |
| ironic |
| ironical |
| ironically |
| irons |
| irony |
| irradiate |
| irradiated |
| irradiating |
| irradiation |
| irrational |
| irrationality |
| irrationally |
| irreclaimable |
| irrecoverably |
| irreducible |
| irreflection |
| irregular |
| irregularity |
| irregularly |
| irrelevant |
| irrelevantly |
| irremediable |
| irreparable |
| irreparably |
| irrepressible |
| irreproachable |
| irresistably |
| irresistible |
| irresistibly |
| irresolution |
| irresponsible |
| irretrievable |
| irreverence |
| irrevocable |
| irrevocably |
| irrisisbable |
| irritability |
| irritable |
| irritate |
| irritated |
| irritating |
| irritation |
| is |
| ise |
| ish |
| isidore |
| isis |
| islam |
| island |
| islanded |
| islander |
| islanders |
| islands |
| isle |
| isles |
| islesen |
| islet |
| isolated |
| isolation |
| israelitish |
| iss |
| issachar |
| issuance |
| issue |
| issued |
| issues |
| issuing |
| isæus |
| it |
| italian |
| italians |
| italics |
| italicus |
| italy |
| itchiatuckanee |
| item |
| items |
| itinerant |
| its |
| itself |
| ives |
| ivi |
| ivied |
| ivory |
| ivy |
| ix |
| iz |
| iä |
| jabbering |
| jack |
| jacket |
| jacques |
| jade |
| jaded |
| jagged |
| jail |
| jailor |
| jambs |
| james |
| jammed |
| jan |
| janisaries |
| january |
| janus |
| jar |
| jardin |
| jaren |
| jargon |
| jarred |
| jarring |
| jauntily |
| jaunty |
| java |
| javelin |
| jaw |
| jaws |
| je |
| jealous |
| jealously |
| jealousy |
| jean |
| jedgment |
| jefferson |
| jehovah |
| jehovy |
| jellies |
| jelly |
| jenkin |
| jeopardize |
| jeopardized |
| jeopardy |
| jeremiad |
| jeremy |
| jeremys |
| jerk |
| jerked |
| jerking |
| jerky |
| jermyn |
| jermyns |
| jersey |
| jervas |
| jest |
| jesting |
| jestingly |
| jests |
| jet |
| jetty |
| jeu |
| jew |
| jewel |
| jewelled |
| jewellery |
| jewelry |
| jewels |
| jewish |
| jews |
| jib |
| jine |
| jingled |
| jingling |
| jis |
| job |
| jocose |
| joe |
| joel |
| jog |
| jogged |
| johann |
| johannisberger |
| johansen |
| john |
| johns |
| johnson |
| join |
| joined |
| joining |
| joins |
| joint |
| joints |
| joke |
| joking |
| jolly |
| jonas |
| jonathan |
| jones |
| jos |
| joseph |
| jostle |
| jostled |
| jostling |
| jottings |
| jouissent |
| journal |
| journalist |
| journalists |
| journals |
| journey |
| journeyed |
| journeying |
| journeyings |
| journeys |
| journied |
| journies |
| jove |
| jovial |
| jovially |
| jovis |
| joy |
| joyeuse |
| joyful |
| joyfully |
| joying |
| joyous |
| joys |
| juan |
| judge |
| judged |
| judgement |
| judges |
| judging |
| judgment |
| judgments |
| judicial |
| judicious |
| jug |
| juice |
| juices |
| jules |
| julie |
| julien |
| juliet |
| julius |
| july |
| jumble |
| jump |
| jumped |
| jumping |
| junction |
| juncture |
| june |
| jung |
| jungle |
| jungles |
| junianus |
| junior |
| juniors |
| junius |
| junzt |
| jup |
| jupiter |
| jura |
| juras |
| jury |
| jus |
| just |
| juster |
| justice |
| justification |
| justified |
| justify |
| justine |
| justly |
| jutted |
| jutting |
| juxta |
| juxtaposition |
| jxhn |
| ka |
| kadath |
| kadatheron |
| kadiphonek |
| kah |
| kaleidoscopic |
| kalends |
| kaliri |
| kalos |
| kanadaw |
| kanaky |
| kanakys |
| kapou |
| karazza |
| karthian |
| kate |
| katrine |
| keel |
| keen |
| keener |
| keenest |
| keenly |
| keenness |
| keep |
| keeper |
| keepers |
| keeping |
| keeps |
| keepsake |
| keer |
| keerful |
| keg |
| kegs |
| keildhelm |
| kempelen |
| ken |
| kennel |
| kent |
| kep |
| kepler |
| kept |
| kerseymere |
| ketch |
| kettle |
| kettles |
| key |
| keyhole |
| keys |
| keziah |
| kick |
| kickapo |
| kickapoo |
| kickapoos |
| kicked |
| kicking |
| kicks |
| kid |
| kidd |
| kidnapping |
| kiel |
| kilderry |
| kill |
| killarney |
| killed |
| killer |
| killin |
| killing |
| kilt |
| kin |
| kind |
| kinder |
| kindle |
| kindled |
| kindliness |
| kindling |
| kindly |
| kindness |
| kindred |
| kinds |
| kinetic |
| king |
| kingdom |
| kingdoms |
| kingly |
| kings |
| kingsport |
| kingsporter |
| kinsfolk |
| kinship |
| kinsman |
| kinsmen |
| kiosk |
| kirschenwasser |
| kirwin |
| kishan |
| kiss |
| kissam |
| kissed |
| kisses |
| kitchen |
| kitten |
| kittens |
| kla |
| kled |
| klenze |
| klimm |
| knack |
| knapsack |
| knead |
| knee |
| kneel |
| knees |
| knells |
| knelt |
| knew |
| knickerbocker |
| knife |
| knight |
| knightly |
| knights |
| knit |
| knob |
| knobs |
| knock |
| knocked |
| knocker |
| knockers |
| knocking |
| knoll |
| knot |
| knothole |
| knots |
| knotty |
| know |
| knowed |
| knowest |
| knoweth |
| knowing |
| knowingly |
| knowledge |
| known |
| knows |
| knxw |
| kock |
| kra |
| kranon |
| kraut |
| krempe |
| kritik |
| kulten |
| kultur |
| kupris |
| kuranes |
| kynaratholis |
| la |
| labels |
| labor |
| laboratory |
| labored |
| laboring |
| laborious |
| laboriously |
| labors |
| labour |
| laboured |
| labourer |
| labourers |
| labouring |
| labours |
| labyrinth |
| labyrinthine |
| labyrinths |
| lace |
| lacessit |
| lacey |
| lachadive |
| lachrymatory |
| lack |
| lacked |
| lacking |
| lackobreath |
| laconic |
| laconically |
| lactea |
| lacus |
| lad |
| ladder |
| ladders |
| laden |
| ladies |
| ladle |
| lads |
| lady |
| lafayette |
| laffin |
| lafitte |
| lagging |
| laid |
| lain |
| lair |
| lake |
| lakelet |
| lakelets |
| lakes |
| lalande |
| lamartine |
| lamb |
| lambent |
| lambs |
| lame |
| lamely |
| lameness |
| lament |
| lamentable |
| lamentation |
| lamented |
| lamenting |
| laments |
| lammas |
| lamp |
| lamplessly |
| lamps |
| lance |
| land |
| landaff |
| landed |
| landgrave |
| landing |
| landlady |
| landlord |
| landor |
| lands |
| landscape |
| landscapes |
| landward |
| lane |
| lanes |
| langton |
| language |
| languages |
| languid |
| languidly |
| languor |
| languour |
| lanscape |
| lantern |
| lanterns |
| lanthorns |
| laocoön |
| laoud |
| lap |
| lapel |
| lapham |
| lapis |
| lapped |
| lappin |
| lapping |
| lapse |
| lapsed |
| lapsing |
| lar |
| larboard |
| large |
| largely |
| larger |
| largest |
| lark |
| larned |
| larnt |
| las |
| lasalle |
| lascia |
| lash |
| lashed |
| lashes |
| lashing |
| lass |
| lassitude |
| last |
| lasted |
| lasting |
| lastly |
| lasts |
| latch |
| late |
| lately |
| lateness |
| latent |
| latently |
| later |
| lateral |
| laterally |
| latest |
| lath |
| lather |
| lathered |
| lathi |
| latin |
| latitude |
| latona |
| latour |
| latter |
| latterly |
| lattice |
| latticed |
| laudable |
| laudanum |
| lauding |
| laugh |
| laughable |
| laughed |
| laughing |
| laughingly |
| laughs |
| laughter |
| launcelot |
| launch |
| launched |
| launching |
| laundry |
| laurel |
| laurels |
| lausanne |
| laved |
| lavenza |
| lavinia |
| lavinny |
| lavish |
| lavished |
| law |
| lawless |
| lawn |
| lawns |
| lawrence |
| laws |
| lawyer |
| lawyers |
| lax |
| lay |
| layers |
| laying |
| layman |
| lays |
| lazuli |
| le |
| lead |
| leaded |
| leaden |
| leader |
| leaders |
| leadership |
| leading |
| leads |
| leaf |
| leafless |
| leafy |
| league |
| leagues |
| leak |
| leaked |
| lean |
| leaned |
| leaning |
| leans |
| leap |
| leaped |
| leaping |
| leaps |
| leapt |
| learn |
| learned |
| learnedly |
| learning |
| learns |
| learnt |
| lease |
| least |
| leather |
| leathern |
| leave |
| leaved |
| leaves |
| leaving |
| leavitt |
| lecture |
| lecturer |
| lectures |
| lecturing |
| led |
| leda |
| ledge |
| ledger |
| ledges |
| lee |
| leech |
| leeches |
| leeds |
| leer |
| leered |
| leering |
| leeringly |
| leers |
| leetle |
| leeward |
| lef |
| leff |
| lefferts |
| left |
| leg |
| legacy |
| legal |
| legally |
| legate |
| legend |
| legendry |
| legends |
| leghorn |
| legible |
| legion |
| legionaries |
| legionarii |
| legions |
| legislative |
| legislators |
| legislature |
| legitimate |
| legrand |
| legrasse |
| legs |
| leipsic |
| leisure |
| leisurely |
| lemuria |
| lend |
| lender |
| lending |
| leng |
| length |
| lengthen |
| lengthened |
| lengths |
| lenient |
| lenity |
| lens |
| lenses |
| lent |
| lenticular |
| leo |
| leonardo |
| leonidas |
| leonville |
| leopard |
| leprous |
| lerion |
| les |
| lesion |
| less |
| lessen |
| lessened |
| lessening |
| lesser |
| lesson |
| lessons |
| lest |
| let |
| lethal |
| lethargic |
| lethargy |
| lets |
| letter |
| lettered |
| letters |
| letting |
| lettres |
| levantine |
| levatas |
| levee |
| level |
| levelled |
| levelling |
| levels |
| lever |
| levers |
| levique |
| levite |
| levities |
| levity |
| lex |
| lh |
| liability |
| liable |
| liberal |
| liberally |
| liberate |
| liberated |
| liberation |
| liberties |
| liberty |
| libo |
| librarian |
| library |
| libya |
| licence |
| license |
| licentiousness |
| lichen |
| lichened |
| lichens |
| licked |
| lictors |
| lid |
| lids |
| lie |
| lied |
| lies |
| lieth |
| lieu |
| lieut |
| lieutenant |
| life |
| lifeboats |
| lifeless |
| lifelessness |
| lifelong |
| lifetime |
| lift |
| lifted |
| lifting |
| lifts |
| ligaments |
| ligeia |
| light |
| lighted |
| lighten |
| lightened |
| lighter |
| lightest |
| lighthearted |
| lighthouse |
| lighting |
| lightly |
| lightness |
| lightnin |
| lightning |
| lightnings |
| lights |
| lightsome |
| like |
| liked |
| likelihood |
| likeliness |
| likely |
| likeness |
| likenesses |
| likens |
| likewise |
| liking |
| lilied |
| lilies |
| lily |
| limb |
| limbo |
| limbs |
| lime |
| limit |
| limitation |
| limitations |
| limited |
| limiting |
| limitless |
| limits |
| limned |
| limply |
| linden |
| line |
| lineage |
| lineament |
| lineaments |
| lined |
| linen |
| liner |
| lines |
| linger |
| lingered |
| lingering |
| lingers |
| linguistic |
| linguists |
| lining |
| linings |
| link |
| linkage |
| linked |
| links |
| lintel |
| lintels |
| lion |
| lionel |
| lions |
| lip |
| lips |
| liqueur |
| liqueurs |
| liquid |
| liquor |
| liquorish |
| liriodendron |
| lisped |
| list |
| listen |
| listened |
| listener |
| listeners |
| listenin |
| listening |
| listenings |
| listens |
| listless |
| listlessly |
| listlessness |
| lists |
| lit |
| litany |
| litera |
| literal |
| literally |
| literary |
| literatim |
| literature |
| lithe |
| lithographs |
| litigations |
| litten |
| litter |
| litterateur |
| littered |
| litters |
| little |
| littleness |
| littlewit |
| livadia |
| live |
| lived |
| liveliest |
| livelihood |
| lively |
| liverpool |
| livery |
| lives |
| liveth |
| livid |
| lividly |
| livin |
| living |
| livre |
| livy |
| lizard |
| ll |
| lo |
| load |
| loaded |
| loading |
| loadstone |
| loaf |
| loafer |
| loam |
| loath |
| loathe |
| loathed |
| loathing |
| loathsome |
| loathsomely |
| loathsomeness |
| loaves |
| lobby |
| lobe |
| lobster |
| lobsters |
| local |
| locale |
| localities |
| locality |
| locate |
| location |
| loch |
| lock |
| locke |
| locked |
| locket |
| locking |
| locks |
| locomotion |
| locomotive |
| locust |
| locusts |
| locution |
| lodge |
| lodged |
| lodger |
| lodgers |
| lodging |
| lodgings |
| lofoden |
| loft |
| loftier |
| loftiest |
| loftily |
| lofty |
| log |
| loge |
| logged |
| logic |
| logical |
| logically |
| logick |
| logs |
| loin |
| loiter |
| loitered |
| lol |
| lollipop |
| lomar |
| lomarians |
| lombard |
| lombardic |
| lombardy |
| lomond |
| london |
| londoner |
| londoners |
| lone |
| loneliness |
| lonely |
| loneness |
| long |
| longboat |
| longed |
| longer |
| longest |
| longevity |
| longing |
| longings |
| longitude |
| longitudinal |
| longitudinally |
| look |
| looked |
| lookin |
| looking |
| lookout |
| looks |
| loom |
| loomed |
| loomfixer |
| looming |
| loop |
| loops |
| loose |
| loosed |
| loosely |
| loosen |
| loosened |
| loosening |
| loot |
| lope |
| loped |
| loping |
| lor |
| lord |
| lordly |
| lords |
| lore |
| lose |
| loser |
| loses |
| losin |
| losing |
| loss |
| losses |
| lost |
| lot |
| loth |
| lothario |
| lotos |
| lots |
| lottery |
| loud |
| louder |
| loudest |
| loudly |
| loudness |
| louis |
| louisa |
| lounger |
| loungers |
| lounging |
| loutish |
| love |
| loved |
| loveless |
| lovelier |
| loveliest |
| loveliness |
| lovely |
| lover |
| lovers |
| loves |
| loving |
| lovingly |
| low |
| lowe |
| lowed |
| lower |
| lowered |
| lowest |
| lowliness |
| lowly |
| lowness |
| loyal |
| loyalty |
| lozenge |
| ls |
| lucan |
| lucerne |
| luchesi |
| lucid |
| luck |
| luckily |
| luckless |
| lucky |
| lucrative |
| ludicrous |
| ludicrously |
| lugubrious |
| lui |
| lukewarm |
| lull |
| lullaby |
| lulled |
| lulling |
| lumbered |
| lumbering |
| lumbers |
| lumen |
| luminance |
| luminary |
| luminiferous |
| luminosity |
| luminous |
| luminousness |
| lumps |
| luna |
| lunacy |
| lunar |
| lunarian |
| lunarians |
| lunatic |
| lunatico |
| lunatics |
| lunch |
| lunched |
| lung |
| lungs |
| lurch |
| lurched |
| lurching |
| lure |
| lured |
| lurid |
| lurk |
| lurked |
| lurking |
| lurks |
| lustra |
| lustre |
| lustrous |
| lustrum |
| lutanist |
| lutanists |
| lute |
| lutes |
| luther |
| luton |
| luxor |
| luxuriance |
| luxuriances |
| luxuriant |
| luxuriantly |
| luxuries |
| luxurious |
| luxuriously |
| luxury |
| lxg |
| lxrd |
| lxxk |
| lydia |
| lyeh |
| lying |
| lynched |
| lynx |
| lyons |
| lyrae |
| lyre |
| lyrics |
| lys |
| lysias |
| ma |
| macabre |
| macbeth |
| macduff |
| mace |
| macedonia |
| maces |
| machen |
| machiavelli |
| machicolated |
| machinations |
| machine |
| machinery |
| machines |
| mackey |
| mad |
| madam |
| madame |
| maddened |
| maddening |
| maddeningly |
| maddest |
| made |
| madeline |
| mademoiselle |
| madhouse |
| madly |
| madman |
| madmen |
| madness |
| madnesses |
| madre |
| maelstrom |
| maelström |
| maelzel |
| maenalus |
| magazine |
| magazines |
| maggoty |
| magic |
| magical |
| magically |
| magician |
| magistrate |
| magistrates |
| magnalia |
| magnanimous |
| magnet |
| magnetic |
| magnetics |
| magnificence |
| magnificent |
| magnifico |
| magnified |
| magnify |
| magnitude |
| magnolias |
| magnus |
| maguntinae |
| magus |
| mahomet |
| mahometans |
| mai |
| maid |
| maiden |
| maidens |
| maillard |
| maillardet |
| maimed |
| maiming |
| main |
| maine |
| mainland |
| mainly |
| maintain |
| maintained |
| maintaining |
| maintains |
| maintenance |
| mainz |
| mais |
| maison |
| maisons |
| maius |
| majestic |
| majestically |
| majesty |
| major |
| majority |
| make |
| maker |
| makes |
| makeshift |
| maketh |
| making |
| makri |
| mal |
| malabar |
| maladies |
| malady |
| malay |
| malays |
| malcolm |
| malcontent |
| male |
| malevolence |
| malevolent |
| malformed |
| malforming |
| malibran |
| malice |
| maliceful |
| malicious |
| malign |
| malignancy |
| malignant |
| malignity |
| malignly |
| malitia |
| malkowski |
| mallet |
| malodorous |
| malone |
| maltese |
| maltreated |
| maltreating |
| mamie |
| mamma |
| mammal |
| mammalia |
| mammalian |
| mammals |
| man |
| manacled |
| manage |
| manageable |
| managed |
| management |
| manages |
| manchester |
| mandate |
| mandragora |
| mangled |
| mangy |
| manhood |
| mania |
| maniac |
| maniacal |
| maniacally |
| manifest |
| manifestation |
| manifestations |
| manifested |
| manifestly |
| manifold |
| manipulation |
| manipulations |
| mankind |
| manly |
| mann |
| manner |
| mannerisms |
| manners |
| manoeuvre |
| manoeuvres |
| manoevres |
| manoir |
| manon |
| manor |
| mansarde |
| mansardes |
| manservant |
| mansfield |
| mansion |
| mansions |
| mantel |
| mantelet |
| mantelpieces |
| mantle |
| mantled |
| manton |
| manual |
| manuel |
| manufactories |
| manufacture |
| manufactured |
| manufacturer |
| manufacturers |
| manuscript |
| manuscripts |
| manuscrit |
| manuxet |
| many |
| maounds |
| maouth |
| maouths |
| map |
| maple |
| maples |
| maps |
| marble |
| marbles |
| marcellinus |
| march |
| marched |
| marchers |
| marchesa |
| marco |
| marcy |
| mare |
| margaret |
| margin |
| marginal |
| margine |
| margins |
| maria |
| marian |
| marie |
| marinade |
| marine |
| mariner |
| marines |
| maritime |
| mark |
| markbrünnen |
| marked |
| markedly |
| market |
| markets |
| marking |
| marks |
| marlin |
| marmontel |
| marmora |
| maro |
| marquis |
| marred |
| marriage |
| marriages |
| married |
| marrow |
| marry |
| marrying |
| marsh |
| marshes |
| marshy |
| marston |
| marsyas |
| martense |
| martenses |
| martha |
| marthy |
| martial |
| martin |
| martyr |
| marvel |
| marvelled |
| marvelling |
| marvellous |
| marvellously |
| marvells |
| marvels |
| marx |
| mary |
| masculine |
| mask |
| masked |
| maskers |
| masks |
| mason |
| masonic |
| masonry |
| masque |
| masquerade |
| masqueraded |
| masqueraders |
| masquerades |
| mass |
| massa |
| massachusetts |
| massacre |
| massacred |
| massacring |
| masse |
| massed |
| masses |
| massive |
| massy |
| mast |
| masted |
| master |
| mastered |
| masterful |
| masterly |
| masterminds |
| masterpiece |
| masters |
| mastery |
| mastication |
| mastiff |
| masts |
| match |
| matched |
| matches |
| matchless |
| matchmen |
| mate |
| mater |
| material |
| materialism |
| materialist |
| materiality |
| materially |
| materials |
| maternal |
| maternity |
| mates |
| mathematical |
| mathematically |
| mathematician |
| mathematicians |
| mathematics |
| mather |
| mathilda |
| matlock |
| matt |
| matted |
| matter |
| mattered |
| matters |
| matthew |
| mattock |
| mature |
| matured |
| maturing |
| maturity |
| maumee |
| maurice |
| mausolea |
| mausolean |
| mausolus |
| mauvais |
| maw |
| may |
| maybe |
| maze |
| mazes |
| mazurewicz |
| mazurka |
| mazy |
| mdcxlvii |
| me |
| meadow |
| meadows |
| meads |
| meagre |
| meal |
| meals |
| mean |
| meandering |
| meanderings |
| meaner |
| meaness |
| meanest |
| meaning |
| meaningless |
| meaningly |
| meanly |
| meanness |
| means |
| meant |
| meantime |
| meanwhile |
| meas |
| measurable |
| measure |
| measured |
| measureless |
| measures |
| meat |
| mebbe |
| mecca |
| mechanical |
| mechanically |
| mechanics |
| mechanism |
| mechanistic |
| medallion |
| medallions |
| medals |
| meddling |
| medean |
| medecine |
| mediaeval |
| mediaevalists |
| median |
| mediate |
| mediation |
| medical |
| medicean |
| mediceens |
| medicinal |
| medicine |
| medicines |
| mediocre |
| meditate |
| meditated |
| meditating |
| meditation |
| meditations |
| meditatively |
| mediterranean |
| medium |
| medley |
| medoc |
| meed |
| meek |
| meer |
| meerschaum |
| meet |
| meetin |
| meeting |
| meetings |
| meets |
| mehitabel |
| mein |
| melancholy |
| melbourne |
| mele |
| melete |
| mellow |
| mellowing |
| melodies |
| melodious |
| melodrama |
| melody |
| melon |
| melt |
| melted |
| melting |
| mem |
| member |
| members |
| membership |
| membrane |
| membraneous |
| meme |
| memoirs |
| memorable |
| memorandum |
| memorial |
| memorials |
| memories |
| memorised |
| memory |
| memphis |
| men |
| menace |
| menaced |
| menacing |
| menages |
| mended |
| mender |
| mendicant |
| mene |
| menehoult |
| menes |
| menfolks |
| menhoult |
| menial |
| menials |
| mennais |
| mental |
| mentality |
| mentally |
| mention |
| mentioned |
| mentioning |
| mentions |
| mentoni |
| mentors |
| mercantile |
| mercator |
| mercenary |
| merchandise |
| merchant |
| merchantman |
| merchants |
| merciful |
| mercifully |
| merciless |
| mercury |
| mercy |
| mere |
| merely |
| merest |
| merge |
| merged |
| merges |
| meridian |
| merit |
| merited |
| merits |
| mermaid |
| merriest |
| merriment |
| merrival |
| merry |
| mervyn |
| mes |
| mesalliance |
| meserve |
| mesmeric |
| mesmerism |
| mesmerized |
| mesmerizing |
| mesopotamia |
| mess |
| message |
| messages |
| messenger |
| messengers |
| messieurs |
| messrs |
| messy |
| mestizo |
| met |
| metabolism |
| metal |
| metallic |
| metals |
| metamorphosed |
| metamorphosis |
| metaphor |
| metaphysical |
| metaphysician |
| metaphysicians |
| metaphysics |
| metaphysithe |
| metempsychosis |
| meteor |
| meteoric |
| methinks |
| method |
| methodical |
| methodically |
| methodist |
| methodized |
| methods |
| methought |
| metropolis |
| metzengerstein |
| mewed |
| mexican |
| mexicans |
| mexico |
| mglw |
| mia |
| miasma |
| miasmal |
| mice |
| michel |
| microscope |
| microscopes |
| microscopic |
| mid |
| middle |
| middling |
| midianites |
| midnight |
| midst |
| midsummer |
| midway |
| midwife |
| mien |
| mienne |
| might |
| mightier |
| mightiest |
| mightily |
| mighty |
| mignaud |
| migrated |
| migrates |
| migration |
| miguel |
| mihi |
| milan |
| milanese |
| mild |
| milder |
| mildew |
| mildewed |
| mildness |
| mile |
| miles |
| military |
| militates |
| militating |
| militia |
| milk |
| milky |
| mill |
| mille |
| milled |
| miller |
| million |
| millionaire |
| millionaires |
| millions |
| mills |
| milton |
| milwaukee |
| mime |
| mimic |
| mimicking |
| minaret |
| minarets |
| mince |
| mind |
| minded |
| minding |
| mindless |
| minds |
| mine |
| mineral |
| mineralizing |
| mineralogist |
| miners |
| mines |
| mingle |
| mingled |
| mingles |
| mingling |
| miniature |
| minion |
| minister |
| ministered |
| ministerial |
| ministers |
| ministrations |
| minor |
| minority |
| minot |
| minotaur |
| minuscules |
| minute |
| minutely |
| minuteness |
| minutes |
| minutest |
| minutiae |
| mio |
| miracle |
| miracles |
| miraculous |
| miraculously |
| miranda |
| mire |
| mirror |
| mirrored |
| mirrors |
| mirth |
| mirthful |
| mis |
| misadventure |
| misanthrope |
| misanthropic |
| misanthropy |
| misapplied |
| misapprehended |
| miscalculated |
| miscalculation |
| miscalculations |
| miscellaneous |
| mischance |
| mischances |
| mischief |
| mischievous |
| misconceived |
| misconducted |
| miscreants |
| misdeed |
| misdirect |
| miser |
| miserable |
| miserably |
| miseries |
| misery |
| misfortune |
| misfortunes |
| mishap |
| misinformed |
| miskatonic |
| mislaid |
| misled |
| misproportioned |
| misrepresentations |
| misrule |
| miss |
| missed |
| misses |
| misshapen |
| missiles |
| missin |
| missing |
| mission |
| mist |
| mistake |
| mistaken |
| mistakes |
| mistaking |
| mister |
| mistiness |
| mistook |
| mistress |
| mistrust |
| mists |
| misty |
| misunderstanding |
| misunderstood |
| misuse |
| mithridates |
| mitigated |
| mix |
| mixed |
| mixes |
| mixin |
| mixing |
| mixture |
| mnar |
| mneme |
| moan |
| moaning |
| moanings |
| moans |
| moat |
| mob |
| mobile |
| mobilia |
| moccasined |
| mock |
| mocked |
| mockeries |
| mockery |
| mocking |
| mockingly |
| mocks |
| mode |
| model |
| modelled |
| models |
| moderate |
| moderated |
| moderately |
| moderation |
| modern |
| modernity |
| moderns |
| modes |
| modest |
| modeste |
| modestly |
| modesty |
| modicum |
| modification |
| modifications |
| modified |
| modify |
| modulated |
| modulation |
| modus |
| moiety |
| moissart |
| moist |
| moisture |
| molded |
| mole |
| molecular |
| moles |
| molestation |
| mollified |
| molucca |
| moment |
| momentarily |
| momentary |
| momently |
| momentous |
| moments |
| mon |
| monarch |
| monarchy |
| monck |
| monday |
| money |
| moneyless |
| moneypenny |
| mongrel |
| mongrels |
| moniteur |
| monk |
| monkey |
| monkeys |
| monkish |
| monks |
| monody |
| monograph |
| monolith |
| monolithic |
| monoliths |
| monomania |
| monopoly |
| monos |
| monotone |
| monotonous |
| monotonously |
| monotony |
| monsieur |
| monster |
| monsters |
| monstrosities |
| monstrosity |
| monstrous |
| monstrously |
| monstrum |
| mont |
| montani |
| montanvert |
| month |
| monthly |
| months |
| montresors |
| monument |
| mood |
| moodily |
| moods |
| moody |
| moon |
| moonbeams |
| moonin |
| moonless |
| moonlight |
| moonlit |
| moons |
| moor |
| moored |
| moorish |
| mop |
| moral |
| morale |
| moralisers |
| moralist |
| moralists |
| moralizing |
| morals |
| morass |
| moraux |
| morbid |
| morbidity |
| morbidly |
| morceau |
| more |
| morea |
| moreau |
| moreland |
| morella |
| moreover |
| morgan |
| morgue |
| moriturus |
| moritz |
| morn |
| mornin |
| morning |
| morphine |
| morrow |
| morry |
| morryster |
| morsel |
| morsels |
| mortal |
| mortali |
| mortality |
| mortals |
| mortar |
| mortification |
| mortified |
| mortify |
| mortis |
| morto |
| mortuary |
| mortuorum |
| mortuus |
| morty |
| mos |
| mosaic |
| mosaics |
| mosaiques |
| moscow |
| moses |
| moshe |
| moskoe |
| moslemin |
| moslems |
| mosque |
| mosques |
| moss |
| mossy |
| most |
| mostly |
| mosäiques |
| moth |
| mother |
| mothers |
| motion |
| motioned |
| motioning |
| motionless |
| motionlessness |
| motions |
| motivation |
| motive |
| motives |
| motley |
| motor |
| motors |
| mots |
| motto |
| mouff |
| mought |
| mould |
| moulded |
| mouldering |
| moulders |
| moulding |
| mouldy |
| moultrie |
| mound |
| mounds |
| mount |
| mountain |
| mountaineer |
| mountaineers |
| mountainous |
| mountains |
| mountainside |
| mountainward |
| mounted |
| mounting |
| mourn |
| mourned |
| mourner |
| mourners |
| mournful |
| mournfully |
| mourning |
| mouse |
| mouser |
| mousseux |
| mouth |
| mouthed |
| mouths |
| move |
| moveable |
| moved |
| moveless |
| movement |
| movements |
| moves |
| movin |
| moving |
| mown |
| mowry |
| mozart |
| mr |
| mrs |
| ms |
| mss |
| mtg |
| much |
| mud |
| muddled |
| muddy |
| mudler |
| muffled |
| muffling |
| muhammad |
| muhammadan |
| mulattoes |
| mulberries |
| mulct |
| mule |
| multi |
| multicolor |
| multifarious |
| multiform |
| multiple |
| multiplication |
| multiplicity |
| multiplied |
| multiplies |
| multiply |
| multiplying |
| multitude |
| multitudes |
| multitudinous |
| mumble |
| mumbled |
| mumblethumb |
| mumbling |
| mummer |
| mummified |
| municipal |
| municipality |
| munificence |
| munificent |
| munroe |
| munt |
| murd |
| murder |
| murdered |
| murderer |
| murderers |
| murderess |
| murdering |
| murderous |
| murders |
| muriton |
| murky |
| murmur |
| murmured |
| murmuring |
| murmurs |
| murray |
| mus |
| muscle |
| muscles |
| muscular |
| muse |
| mused |
| muses |
| muset |
| museum |
| museums |
| mushrooms |
| mushy |
| music |
| musical |
| musically |
| musician |
| musicians |
| musides |
| musing |
| musingly |
| musings |
| musique |
| musk |
| musket |
| muskets |
| muslin |
| must |
| musta |
| mustachios |
| mustard |
| muster |
| mustiness |
| musty |
| musée |
| mutability |
| mutable |
| mutation |
| mutations |
| mute |
| muted |
| mutely |
| mutilated |
| mutilation |
| mutiny |
| mutter |
| muttered |
| muttering |
| mutteringly |
| mutterings |
| mutters |
| mutual |
| mutually |
| muzzle |
| muñoz |
| mwanu |
| my |
| mynheer |
| myriad |
| myriads |
| myrmidons |
| myrrh |
| myrrha |
| myrtle |
| myrtles |
| myself |
| mysteries |
| mysterious |
| mystery |
| mystic |
| mystical |
| mystically |
| mystics |
| mystific |
| mystification |
| mystified |
| mystifique |
| myth |
| mythical |
| mythological |
| mythology |
| myths |
| ménageais |
| même |
| müller |
| nafh |
| nagl |
| nahab |
| naiad |
| naiads |
| nail |
| nailed |
| nails |
| naive |
| naivete |
| naked |
| nakedness |
| namby |
| name |
| named |
| nameless |
| namely |
| names |
| namesake |
| nantz |
| naow |
| naowadays |
| nape |
| naples |
| napoleon |
| napoli |
| naps |
| naraxa |
| narcotic |
| narcotics |
| narg |
| nargai |
| narragansett |
| narragansetts |
| narrate |
| narrated |
| narrating |
| narration |
| narrations |
| narrative |
| narratives |
| narrator |
| narrow |
| narrowed |
| narrower |
| narrowest |
| narrowly |
| narthos |
| nascent |
| nascitur |
| nassau |
| nastiness |
| nasty |
| nat |
| nathelesse |
| nation |
| national |
| nationality |
| nations |
| native |
| natives |
| nativity |
| naturae |
| natural |
| naturalists |
| naturally |
| nature |
| natured |
| natures |
| naught |
| nauseated |
| nauseating |
| nauseous |
| nautical |
| naval |
| navies |
| navigate |
| navigation |
| navigator |
| navigators |
| navis |
| navy |
| nay |
| ncey |
| nd |
| ne |
| neal |
| neanderthal |
| neapolis |
| neapolitan |
| neapolitans |
| near |
| nearby |
| neared |
| nearer |
| nearest |
| nearly |
| nears |
| neat |
| neater |
| neatly |
| neatness |
| neb |
| nebber |
| neber |
| nebulosity |
| nebulous |
| nebulously |
| nebulæ |
| necessaries |
| necessarily |
| necessary |
| necessitated |
| necessitous |
| necessity |
| neck |
| necks |
| necromancy |
| necronomicon |
| necropolis |
| need |
| needed |
| needle |
| needles |
| needless |
| needlessly |
| needs |
| negative |
| neglect |
| neglected |
| neglectful |
| negligence |
| negligently |
| negotiating |
| negotium |
| negro |
| negroes |
| negroid |
| neigh |
| neighbor |
| neighborhood |
| neighboring |
| neighbors |
| neighbour |
| neighbourhood |
| neighbourhoods |
| neighbouring |
| neighbours |
| neighed |
| neither |
| nem |
| nemesis |
| nemo |
| nemorensis |
| nephew |
| nephren |
| neptune |
| neptunian |
| nereids |
| nerve |
| nerveless |
| nerves |
| nerving |
| nervous |
| nervously |
| nervousness |
| nessus |
| nest |
| nestling |
| nests |
| net |
| nether |
| netherland |
| nethermost |
| nets |
| nettled |
| network |
| networks |
| neuralgia |
| neuralgic |
| neurotic |
| neurotically |
| neutral |
| neutrality |
| nevair |
| never |
| nevermore |
| nevertheless |
| nevil |
| nevis |
| new |
| newbury |
| newburyport |
| newcomer |
| newcomers |
| newer |
| newest |
| newfoundland |
| newly |
| newport |
| news |
| newspaper |
| newspapers |
| newton |
| nex |
| next |
| nez |
| nglui |
| ngranek |
| niagara |
| nib |
| nibble |
| nibbles |
| nice |
| nicely |
| nicer |
| nicest |
| nicety |
| niche |
| niches |
| nicholas |
| nichols |
| nick |
| nickel |
| nicolino |
| niece |
| nier |
| nigger |
| niggerless |
| niggers |
| niggurath |
| nigh |
| night |
| nightcap |
| nighted |
| nightingale |
| nightly |
| nightmare |
| nightmares |
| nightmarish |
| nightmarishly |
| nightmarishness |
| nights |
| nihil |
| nihility |
| nihilo |
| nile |
| nill |
| nimble |
| nimbus |
| nine |
| nineteen |
| nineteenth |
| nineties |
| ninety |
| nineveh |
| ninon |
| ninth |
| niobe |
| nipped |
| nipping |
| nipt |
| nir |
| nis |
| nith |
| nithra |
| nitokris |
| nitre |
| nitrogen |
| nitrous |
| no |
| nobility |
| noble |
| nobleman |
| noblemen |
| nobler |
| nobles |
| noblest |
| nobly |
| nobody |
| nocturnal |
| nocturnally |
| nod |
| nodded |
| nodding |
| nodens |
| noffin |
| noise |
| noiseless |
| noiselessly |
| noises |
| noisily |
| noisome |
| noisy |
| nom |
| nomad |
| nomenclature |
| nominate |
| nommy |
| non |
| nonce |
| nonchalance |
| nondescript |
| none |
| nonentity |
| nonsense |
| nook |
| noon |
| noonday |
| noontide |
| noose |
| nooseneck |
| nooses |
| noovers |
| nopolis |
| nor |
| nordic |
| nordland |
| normal |
| normality |
| normally |
| norman |
| north |
| northam |
| northeast |
| northerly |
| northern |
| northernmost |
| northward |
| northwardly |
| northwards |
| northwest |
| northwesterly |
| northwestern |
| norton |
| norway |
| norwegian |
| norwegians |
| norwich |
| nose |
| noses |
| nosology |
| nostril |
| nostrils |
| not |
| notable |
| notably |
| notary |
| note |
| noted |
| notes |
| nothin |
| nothing |
| nothingness |
| notice |
| noticeable |
| noticeably |
| noticed |
| notices |
| noticing |
| notification |
| noting |
| notion |
| notions |
| noton |
| notoriety |
| notorious |
| notoriously |
| notre |
| noturwissenchaft |
| notwithstanding |
| nought |
| noumena |
| nourished |
| nourishment |
| nourjahad |
| nouvelette |
| nouvelle |
| nov |
| nova |
| novalis |
| novel |
| novelists |
| novels |
| novelties |
| novelty |
| november |
| novice |
| now |
| nowadays |
| nowhere |
| noxious |
| nt |
| nthlei |
| nubian |
| nuclei |
| nucleus |
| nudging |
| nues |
| nugent |
| nuisance |
| null |
| nullity |
| numantius |
| numbed |
| number |
| numbered |
| numberless |
| numbers |
| numbness |
| numerous |
| nun |
| nunlike |
| nuptials |
| nurse |
| nursed |
| nurses |
| nursing |
| nursling |
| nurslings |
| nurtured |
| nut |
| nuther |
| nutriment |
| nutrition |
| nuts |
| nuzzle |
| nx |
| nxbxdy |
| nxne |
| nxr |
| nxthing |
| nxw |
| nyarlathotep |
| nyl |
| oak |
| oaken |
| oaks |
| oar |
| oars |
| oarsmen |
| oasis |
| oath |
| oaths |
| oatmeal |
| ob |
| obdurate |
| obed |
| obedience |
| obedient |
| obeisance |
| obeisances |
| obelisks |
| obey |
| obeyed |
| obeying |
| object |
| objection |
| objectionable |
| objections |
| objective |
| objectivity |
| objectless |
| objects |
| obligation |
| obligations |
| oblige |
| obliged |
| obliquely |
| obliterate |
| obliterated |
| obliterates |
| obliterating |
| oblivion |
| oblivious |
| oblong |
| obnoxious |
| obscene |
| obscure |
| obscured |
| obscurely |
| obscuring |
| obscuringly |
| obscurity |
| obsequie |
| observ |
| observable |
| observance |
| observant |
| observation |
| observations |
| observe |
| observed |
| observer |
| observes |
| observing |
| obsessions |
| obst |
| obstacle |
| obstacles |
| obstinacy |
| obstinate |
| obstinately |
| obstreperous |
| obstruction |
| obstructions |
| obstrusive |
| obtain |
| obtained |
| obtaining |
| obtains |
| obtrude |
| obtruded |
| obtrusive |
| obtuse |
| obviate |
| obviated |
| obvious |
| obviously |
| obviousness |
| occasion |
| occasional |
| occasionally |
| occasioned |
| occasions |
| occidit |
| occultation |
| occultism |
| occupancy |
| occupant |
| occupants |
| occupation |
| occupations |
| occupied |
| occupy |
| occupying |
| occur |
| occured |
| occurred |
| occurrence |
| occurrences |
| occurring |
| occurs |
| ocean |
| oceanic |
| oceanographic |
| oceans |
| oceanward |
| ocracoke |
| octagonal |
| octaves |
| octavo |
| october |
| octopus |
| ocular |
| odd |
| oddities |
| oddity |
| oddly |
| ode |
| odenheimer |
| odigies |
| odious |
| odor |
| odoriferous |
| odorous |
| odors |
| odour |
| odours |
| odysseus |
| oedipus |
| oeil |
| of |
| off |
| offals |
| offcasts |
| offen |
| offence |
| offend |
| offended |
| offending |
| offensive |
| offer |
| offered |
| offering |
| offerings |
| offers |
| office |
| officer |
| officers |
| offices |
| official |
| officially |
| officials |
| officious |
| officiousness |
| offish |
| offspring |
| oft |
| often |
| oftener |
| ognor |
| ogs |
| oh |
| ohio |
| oiga |
| oil |
| oily |
| oinos |
| oiseau |
| ol |
| olathoë |
| olaus |
| old |
| oldeb |
| olden |
| older |
| oldest |
| ole |
| olfactory |
| olive |
| oliver |
| olives |
| olney |
| olympiad |
| olympian |
| oman |
| ombra |
| omega |
| omelette |
| omen |
| omened |
| ominous |
| ominously |
| omission |
| omitted |
| omne |
| omni |
| omnibus |
| omnipotence |
| omnipotent |
| omnipresence |
| omnipresent |
| omniprevalence |
| omniscience |
| omnivorous |
| on |
| once |
| onct |
| ond |
| one |
| oneness |
| onerous |
| ones |
| oneself |
| onesiphorus |
| onga |
| ongas |
| only |
| onslaught |
| onto |
| onward |
| onwards |
| onyx |
| onyxes |
| oonai |
| ooth |
| ooze |
| oozed |
| oozing |
| oozy |
| opal |
| opals |
| opaque |
| open |
| opened |
| opener |
| openin |
| opening |
| openings |
| openly |
| openness |
| opens |
| opera |
| operandi |
| operate |
| operated |
| operating |
| operation |
| operations |
| operative |
| operator |
| opiate |
| opiates |
| opinion |
| opinions |
| opium |
| oporto |
| oppodeldoc |
| opponent |
| opponents |
| opportunely |
| opportunities |
| opportunity |
| opposable |
| oppose |
| opposed |
| opposing |
| opposite |
| opposition |
| oppress |
| oppressed |
| oppresses |
| oppression |
| oppressive |
| oppressively |
| oppressor |
| oppressors |
| optic |
| optical |
| opulence |
| or |
| oral |
| orange |
| orations |
| orator |
| orb |
| orbit |
| orbs |
| orchard |
| orchestra |
| orchids |
| ordeal |
| order |
| ordered |
| ordering |
| orderly |
| orders |
| ordinarily |
| ordinary |
| orfeo |
| organ |
| organic |
| organisation |
| organisations |
| organise |
| organised |
| organism |
| organisms |
| organization |
| organized |
| organless |
| organs |
| orgiastic |
| orgies |
| orgy |
| oriels |
| oriental |
| orientalists |
| origin |
| original |
| originality |
| originally |
| originate |
| originated |
| oriole |
| orion |
| orkney |
| orleans |
| ornament |
| ornamental |
| ornamented |
| ornaments |
| ornate |
| orne |
| orontes |
| orphan |
| orta |
| orter |
| orthodox |
| orthographically |
| ortolan |
| ortolans |
| os |
| osborn |
| osborne |
| oscillation |
| ose |
| oslo |
| ossa |
| osseous |
| ossi |
| ossian |
| ossification |
| ossuary |
| ostracised |
| ostrogoth |
| otaheité |
| otello |
| other |
| others |
| otherwise |
| ottawa |
| otterholm |
| ottoman |
| ottomans |
| ought |
| oukranos |
| ounce |
| ounces |
| our |
| ourang |
| ours |
| ourselves |
| out |
| outang |
| outangs |
| outbidding |
| outbreak |
| outbreaks |
| outbuildings |
| outburst |
| outbursts |
| outcast |
| outcasts |
| outcome |
| outcropping |
| outcroppings |
| outcry |
| outdid |
| outdo |
| outen |
| outer |
| outfit |
| outfitted |
| outgrown |
| outgrowth |
| outlawed |
| outlay |
| outlet |
| outline |
| outlined |
| outlines |
| outnumbered |
| outposts |
| outpouring |
| outrage |
| outraged |
| outrageous |
| outrages |
| outre |
| outreaching |
| outrider |
| outright |
| outrun |
| outré |
| outs |
| outset |
| outshining |
| outshone |
| outside |
| outsideness |
| outsider |
| outsiders |
| outskirts |
| outspeed |
| outspread |
| outstretched |
| outstripped |
| outstripping |
| outward |
| outwardly |
| outwards |
| outwits |
| ov |
| oval |
| oven |
| over |
| overawed |
| overboard |
| overburthened |
| overcame |
| overcast |
| overcharged |
| overcoat |
| overcome |
| overcoming |
| overdone |
| overdue |
| overestimated |
| overflow |
| overflowed |
| overflowing |
| overflowings |
| overgrown |
| overgrowth |
| overhang |
| overhanging |
| overhangs |
| overhead |
| overhear |
| overheard |
| overhung |
| overinformed |
| overjoyed |
| overleap |
| overlooked |
| overlooking |
| overmantel |
| overmastered |
| overnourished |
| overpowered |
| overpowering |
| overran |
| overrated |
| overreaching |
| overruled |
| overrun |
| overscored |
| oversensitive |
| overshadowed |
| overshadows |
| overshoot |
| overshot |
| oversight |
| oversights |
| overspread |
| overstep |
| overstowed |
| overstrained |
| overtake |
| overtaken |
| overtakes |
| overtaking |
| overtaxed |
| overthrew |
| overthrow |
| overthrown |
| overtone |
| overtones |
| overtook |
| overtopped |
| overtopping |
| overturn |
| overturned |
| overturning |
| overwhelm |
| overwhelmed |
| overwhelming |
| overwhelmingly |
| overworking |
| owd |
| owe |
| owed |
| owest |
| owing |
| owl |
| owls |
| own |
| owned |
| owner |
| owners |
| ownership |
| owning |
| owns |
| ox |
| oxford |
| oxonian |
| oxus |
| oxydracae |
| oxygen |
| oye |
| oyer |
| oysters |
| pa |
| pabulum |
| pace |
| paced |
| paces |
| pacific |
| pacing |
| pack |
| packages |
| packed |
| packet |
| packets |
| packing |
| packs |
| padded |
| paddings |
| paddle |
| padlock |
| padlocks |
| pads |
| paestum |
| pagan |
| paganly |
| page |
| pageantry |
| pages |
| pagoda |
| pagodas |
| paid |
| pail |
| pain |
| paine |
| pained |
| painful |
| painfully |
| paining |
| painless |
| pains |
| painstaking |
| painstakingly |
| paint |
| painted |
| painter |
| painters |
| painting |
| paintings |
| paints |
| pair |
| pajama |
| palace |
| palaces |
| palaeography |
| palais |
| palanquins |
| palate |
| palaver |
| palazzo |
| pale |
| paled |
| paleness |
| paling |
| palings |
| pall |
| pallas |
| palled |
| pallet |
| palli |
| palliative |
| pallid |
| pallor |
| palm |
| palpability |
| palpable |
| palpably |
| palpitate |
| palpitated |
| palpitates |
| palpitating |
| palpitations |
| palsied |
| palsying |
| paltry |
| pamby |
| pampered |
| pamphlet |
| pan |
| pandaemoniac |
| pandemonium |
| pandora |
| pane |
| paned |
| panel |
| panelled |
| panelling |
| panels |
| panes |
| pang |
| pangs |
| panic |
| pannels |
| panorama |
| panoramas |
| panoramic |
| pansies |
| pantaloons |
| panted |
| panting |
| paowerful |
| papa |
| paper |
| papers |
| papier |
| papillon |
| papillotes |
| papyrus |
| par |
| parable |
| paracelsus |
| parachutes |
| paradisaical |
| paradise |
| paradox |
| paradoxical |
| paragrab |
| paragraph |
| paragraphs |
| paralized |
| parallel |
| parallelism |
| paralyse |
| paralysed |
| paralysis |
| paralytic |
| paralyze |
| paralyzed |
| paralyzing |
| paramount |
| parapets |
| paraphernalia |
| paraphrased |
| parasites |
| parasol |
| parcel |
| parcels |
| parched |
| parchment |
| pardon |
| pardoned |
| pardonne |
| pardons |
| pareamo |
| parent |
| parentheses |
| parents |
| parfumerie |
| paris |
| parish |
| parisian |
| parisians |
| park |
| parked |
| parker |
| parks |
| parley |
| parliament |
| parliamentary |
| parlor |
| parmi |
| parnassus |
| parody |
| paroxisms |
| paroxysm |
| paroxysms |
| parson |
| part |
| partake |
| partaken |
| partaking |
| parte |
| parted |
| parterres |
| parthenon |
| parti |
| partial |
| partiality |
| partially |
| participants |
| participate |
| participates |
| participation |
| particle |
| particles |
| particular |
| particularizing |
| particularly |
| particulars |
| parties |
| parting |
| partisan |
| partisans |
| partition |
| partitions |
| partizan |
| partizans |
| partly |
| partner |
| partners |
| partook |
| partridge |
| parts |
| party |
| parvenu |
| pas |
| pascal |
| pasquinade |
| pasquinaded |
| pass |
| passable |
| passage |
| passages |
| passageway |
| passed |
| passenger |
| passengers |
| passer |
| passers |
| passes |
| passing |
| passion |
| passionate |
| passionately |
| passionless |
| passions |
| passive |
| passon |
| past |
| pastime |
| pastimes |
| pastor |
| pastoral |
| pasturage |
| pasture |
| pastures |
| pat |
| patch |
| patched |
| patches |
| patent |
| paternal |
| paternity |
| paterson |
| pates |
| path |
| pathetic |
| pathetically |
| pathless |
| pathology |
| paths |
| pathway |
| patience |
| patient |
| patiently |
| patients |
| patois |
| patriarch |
| patriarchal |
| patrician |
| patrimony |
| patriot |
| patriotic |
| patriots |
| patrol |
| patrolled |
| patrolman |
| patron |
| patronage |
| patronize |
| patronized |
| patronizing |
| patted |
| patter |
| pattering |
| pattern |
| patterned |
| patterns |
| patting |
| paul |
| paupers |
| pause |
| paused |
| pauses |
| pausing |
| paved |
| pavement |
| pavements |
| pavia |
| pavilions |
| paving |
| pavée |
| paw |
| pawed |
| pawing |
| paws |
| pay |
| paying |
| payment |
| payne |
| pe |
| pea |
| peaaema |
| peabody |
| peace |
| peaceable |
| peaceably |
| peaceful |
| peak |
| peaked |
| peaks |
| peal |
| peals |
| pear |
| pearl |
| pearls |
| pearly |
| peasant |
| peasantry |
| peasants |
| peat |
| pebble |
| pebbles |
| peck |
| pecking |
| pectoral |
| peculiar |
| peculiarities |
| peculiarity |
| peculiarly |
| pecuniary |
| pedantry |
| pedants |
| peddler |
| pedestal |
| pedestrian |
| pedestrians |
| pediment |
| peeled |
| peeling |
| peep |
| peeped |
| peeping |
| peer |
| peerage |
| peered |
| peering |
| peers |
| peevish |
| peevishness |
| peg |
| pegs |
| peine |
| pele |
| peleg |
| pelf |
| pelief |
| pelion |
| pelissier |
| pell |
| peltries |
| pemmican |
| pen |
| penalty |
| penance |
| pencil |
| pending |
| pendulous |
| pendulum |
| pendulums |
| penetrate |
| penetrated |
| penetrates |
| penetrating |
| penetration |
| penetrations |
| peninsula |
| pennant |
| penned |
| pennies |
| penny |
| pennyless |
| pension |
| pensioners |
| pensive |
| penstruthal |
| pentelicus |
| penurious |
| penury |
| peon |
| people |
| peopled |
| pepper |
| pequots |
| per |
| peradventure |
| perambulans |
| perambulations |
| peray |
| perceive |
| perceived |
| perceives |
| perceiving |
| perceptible |
| perceptibly |
| perception |
| perceptions |
| percha |
| perchance |
| perched |
| percival |
| percy |
| perdidit |
| perdita |
| perds |
| perdu |
| peregrinations |
| peremptorily |
| peremptory |
| perennial |
| perfect |
| perfection |
| perfectionate |
| perfectionists |
| perfections |
| perfectly |
| perfidy |
| perforations |
| perforce |
| perform |
| performance |
| performed |
| performers |
| performing |
| performs |
| perfume |
| perfumed |
| perfumery |
| perfumes |
| perfunctory |
| perhaps |
| pericranium |
| perigee |
| perihelion |
| peril |
| perilous |
| perilously |
| perils |
| period |
| periodic |
| periodical |
| periodically |
| periodicals |
| periods |
| perish |
| perishable |
| perished |
| perishing |
| peristyle |
| peristyles |
| periwigs |
| permanence |
| permanent |
| permanently |
| permeate |
| permeated |
| permeates |
| permissible |
| permission |
| permit |
| permits |
| permitted |
| permitting |
| pernicious |
| perpendicular |
| perpendicularity |
| perpendicularly |
| perpetrate |
| perpetrated |
| perpetration |
| perpetrator |
| perpetrators |
| perpetua |
| perpetual |
| perpetually |
| perpetuate |
| perpetuated |
| perpetuation |
| perplex |
| perplexed |
| perplexing |
| perplexities |
| perplexity |
| perquisitions |
| persecute |
| persecuted |
| persecution |
| persecutor |
| persecutors |
| persei |
| persephone |
| persepolis |
| perseus |
| perseverance |
| persevere |
| perseveres |
| persevering |
| perseveringly |
| persia |
| persian |
| persist |
| persisted |
| persistence |
| persistent |
| person |
| personae |
| personage |
| personages |
| personal |
| personally |
| personated |
| personified |
| persons |
| perspective |
| perspiration |
| perspiring |
| persuade |
| persuaded |
| persuading |
| persuasion |
| persuasions |
| persuasive |
| perth |
| perticcler |
| pertinaciously |
| pertinacity |
| pertinent |
| perturbation |
| perturbed |
| perturbing |
| peru |
| perus |
| perusal |
| peruse |
| perused |
| perusing |
| pervade |
| pervaded |
| pervades |
| pervading |
| pervasive |
| perverse |
| perverseness |
| perversion |
| perversity |
| pervert |
| pervious |
| pest |
| pestering |
| pestilence |
| pestilences |
| pestilent |
| pestilential |
| pesty |
| pet |
| peter |
| peterin |
| peters |
| petersburgh |
| petition |
| petitioners |
| petitmaître |
| petrified |
| petrifying |
| petronius |
| petrovitch |
| petrus |
| pets |
| petticoat |
| petticoats |
| pettitt |
| petto |
| petty |
| petulant |
| petulantly |
| pevishly |
| pew |
| pfaal |
| pfaall |
| ph |
| phantasies |
| phantasm |
| phantasma |
| phantasmagoric |
| phantasmal |
| phantasmally |
| phantasms |
| phantasy |
| phantom |
| phantoms |
| pharaoh |
| phase |
| phaseless |
| phases |
| pheasants |
| phebe |
| phenomena |
| phenomenal |
| phenomenally |
| phenomenon |
| phial |
| philadelphia |
| philanthropic |
| philanthropist |
| philanthropy |
| philip |
| philippic |
| philistine |
| philistines |
| philosopher |
| philosophers |
| philosophic |
| philosophical |
| philosophically |
| philosophie |
| philosophise |
| philosophy |
| phiz |
| phlegethon |
| phlegmatic |
| phlegraei |
| phobic |
| phone |
| phosphorescence |
| phosphorescent |
| phosphorescently |
| phosphoric |
| photograph |
| photographed |
| photographs |
| phrase |
| phraseology |
| phrases |
| phrenological |
| phrenologists |
| phrenology |
| phrensy |
| phrenzied |
| phrenzy |
| phrygian |
| phthisis |
| physical |
| physically |
| physician |
| physicians |
| physics |
| physiognomy |
| physiologist |
| physiology |
| physique |
| piano |
| piazza |
| piazzas |
| pick |
| pickaxe |
| picked |
| pickin |
| picking |
| pickman |
| picks |
| picter |
| picters |
| pictorial |
| picture |
| pictured |
| pictures |
| picturesque |
| picturesquely |
| picturesqueness |
| pie |
| piece |
| pieced |
| pieces |
| piecing |
| pier |
| pierce |
| pierced |
| piercing |
| pierre |
| piety |
| pig |
| pigafetta |
| pigeon |
| pigeons |
| pigger |
| pigment |
| pigmy |
| pigs |
| pike |
| pilasters |
| pilau |
| pile |
| piled |
| piles |
| pilgrim |
| pilgrimage |
| pilier |
| piling |
| pillaged |
| pillar |
| pillared |
| pillars |
| pillow |
| pillows |
| pilot |
| piloted |
| pilots |
| piltdown |
| pin |
| pinacle |
| pince |
| pinch |
| pinched |
| pindar |
| pine |
| pineal |
| pined |
| pines |
| piningly |
| pinion |
| pinioned |
| pinions |
| pink |
| pinkish |
| pinnace |
| pinnacle |
| pinnacles |
| pinned |
| pinta |
| pinxit |
| piny |
| pioneer |
| pioneers |
| pious |
| piously |
| pipe |
| piped |
| pipes |
| piping |
| pipings |
| piquant |
| pique |
| piqued |
| piraeus |
| pirate |
| pirates |
| pirouette |
| pirouetted |
| pisa |
| pistol |
| pistols |
| piston |
| pit |
| pitch |
| pitched |
| pitcher |
| pitchforks |
| pitching |
| pitchy |
| piteous |
| piteously |
| pitiable |
| pitied |
| pitiful |
| pitifully |
| pitiless |
| pitilessly |
| pits |
| pittance |
| pitted |
| pittoresque |
| pity |
| pitying |
| pityless |
| piu |
| piute |
| pivot |
| pivots |
| pizziness |
| pizzness |
| placard |
| place |
| placed |
| places |
| placid |
| placidity |
| placidly |
| placing |
| plague |
| plagues |
| plaguy |
| plain |
| plainly |
| plainpalais |
| plains |
| plaint |
| plaintive |
| plaints |
| plaited |
| plan |
| planck |
| plane |
| planes |
| planet |
| planetary |
| planets |
| plank |
| planked |
| planking |
| plankings |
| planks |
| planned |
| planning |
| plans |
| plant |
| plantations |
| planted |
| plantes |
| planting |
| plants |
| plaster |
| plastered |
| plastic |
| plasticity |
| plate |
| plateau |
| platform |
| platinum |
| plato |
| platonist |
| platter |
| platters |
| plausibility |
| plausible |
| plausibly |
| play |
| played |
| player |
| players |
| playfellows |
| playful |
| playfully |
| playfulness |
| playground |
| playing |
| playmate |
| playmates |
| plays |
| plaything |
| plaza |
| plazas |
| plea |
| plead |
| pleading |
| pleadings |
| pleas |
| pleasant |
| pleasanter |
| pleasantly |
| pleasantry |
| please |
| pleased |
| pleases |
| pleasing |
| pleasurable |
| pleasure |
| pleasureable |
| pleasures |
| plebeian |
| pledge |
| pledged |
| pleiades |
| plenteously |
| plentiful |
| plentifully |
| plentifulness |
| plenty |
| plicable |
| plied |
| plodded |
| plot |
| plots |
| plotted |
| plotting |
| plough |
| ploughed |
| ploughman |
| plouton |
| pluck |
| plucked |
| plucking |
| plum |
| plumage |
| plumb |
| plumbing |
| plume |
| plumed |
| plumes |
| plunderer |
| plunge |
| plunged |
| plunging |
| plungings |
| plutarch |
| pluto |
| ply |
| plying |
| pnakotic |
| poacher |
| poaching |
| pocketed |
| pockets |
| poem |
| poems |
| poet |
| poetess |
| poetic |
| poetical |
| poetick |
| poetry |
| poets |
| poh |
| poi |
| poignancy |
| poignant |
| poignantly |
| poinard |
| point |
| pointed |
| pointing |
| pointless |
| points |
| poison |
| poisoned |
| poisoning |
| poisonous |
| poke |
| poked |
| poking |
| polar |
| pole |
| poles |
| police |
| policeman |
| policemen |
| policial |
| policy |
| polish |
| polished |
| polite |
| politely |
| politian |
| politic |
| political |
| politician |
| politicians |
| politics |
| poll |
| pollute |
| pollutes |
| polyhedron |
| polynesian |
| polypheme |
| polypous |
| polytechnic |
| pomp |
| pompeius |
| pompelo |
| pompey |
| pompilius |
| pomposity |
| pompous |
| pon |
| ponape |
| pond |
| ponder |
| ponderable |
| pondered |
| pondering |
| ponderous |
| ponders |
| ponds |
| ponte |
| ponto |
| poodle |
| pool |
| pools |
| poop |
| poor |
| poorer |
| poorest |
| poorhouse |
| poorly |
| pop |
| pope |
| popish |
| poplar |
| poplars |
| poppies |
| popping |
| poppy |
| populace |
| popular |
| popularity |
| population |
| populous |
| porcelain |
| pore |
| pored |
| pores |
| porgi |
| poring |
| pork |
| porous |
| porphyrogene |
| porphyry |
| porpoise |
| port |
| portable |
| portal |
| portals |
| portcullis |
| portend |
| portended |
| portent |
| portentous |
| portentousness |
| portents |
| porter |
| porthole |
| portholes |
| porticos |
| portion |
| portions |
| portmanteau |
| porto |
| portrait |
| portraite |
| portraits |
| portraiture |
| portray |
| portrayed |
| portraying |
| ports |
| portsmouth |
| portuguese |
| pose |
| poseidonis |
| posing |
| position |
| positions |
| positive |
| positively |
| positiveness |
| possess |
| possessed |
| possesses |
| possessing |
| possession |
| possessions |
| possessor |
| possessors |
| possibilities |
| possibility |
| possibilty |
| possible |
| possibly |
| possum |
| post |
| postage |
| poster |
| posteriori |
| posterity |
| postpone |
| postponement |
| posts |
| postscript |
| postulating |
| postumius |
| posture |
| postures |
| pot |
| potency |
| potent |
| potentates |
| potential |
| potently |
| potion |
| pots |
| potter |
| poultry |
| pounced |
| pounded |
| pounding |
| pounds |
| pour |
| poured |
| pouring |
| pours |
| pourtrayed |
| pover |
| poverty |
| powder |
| powdered |
| power |
| powerful |
| powerfully |
| powerfulness |
| powering |
| powerless |
| powers |
| pox |
| pp |
| practicable |
| practical |
| practically |
| practice |
| practiced |
| practices |
| practise |
| practised |
| practising |
| practitioner |
| practitioners |
| prairie |
| praise |
| praised |
| praises |
| praising |
| pratol |
| pratt |
| prattle |
| prattled |
| prattling |
| pray |
| prayed |
| prayer |
| prayers |
| praying |
| pre |
| preached |
| preachers |
| preachin |
| prearranged |
| precarious |
| precariously |
| precaution |
| precautions |
| precede |
| preceded |
| precedent |
| precedes |
| preceding |
| preceptor |
| precepts |
| precincts |
| precious |
| precipice |
| precipices |
| precipitancy |
| precipitate |
| precipitated |
| precipitately |
| precipitating |
| precipitation |
| precipitous |
| precipitously |
| precise |
| precisely |
| precision |
| preclude |
| precluded |
| precocious |
| precociously |
| precociousness |
| preconceived |
| preconcert |
| preconcertedly |
| predatory |
| predecessors |
| predicament |
| predict |
| predicted |
| predictions |
| predilection |
| predisposed |
| predisposing |
| predominant |
| predominate |
| predominated |
| predominating |
| preeches |
| preeminence |
| preeminent |
| prefaced |
| prefect |
| prefecture |
| prefer |
| preferable |
| preferably |
| preference |
| preferment |
| preferred |
| preferring |
| prefixed |
| pregnancy |
| pregnant |
| prehensile |
| prehistoric |
| preignac |
| prejudice |
| prejudiced |
| prejudices |
| preliminaries |
| preliminary |
| prelude |
| premature |
| premeditated |
| premier |
| premise |
| premises |
| premonitions |
| prepar |
| preparation |
| preparations |
| preparatory |
| prepare |
| prepared |
| preparing |
| preponderating |
| prepossessions |
| preposterous |
| prerogative |
| presburg |
| presbyterian |
| prescribed |
| prescription |
| prescriptive |
| presence |
| presences |
| present |
| presentable |
| presentant |
| presentation |
| presented |
| presentiment |
| presenting |
| presently |
| presentment |
| presents |
| preserv |
| preservation |
| preserve |
| preserved |
| preserver |
| preserves |
| preserving |
| preside |
| presided |
| president |
| presiding |
| press |
| pressed |
| pressing |
| pressure |
| prestige |
| preston |
| presumable |
| presumably |
| presume |
| presumption |
| presumptive |
| presumptuous |
| presumtuous |
| pretence |
| pretences |
| pretend |
| pretended |
| pretender |
| pretense |
| pretension |
| pretensions |
| preternatural |
| prettily |
| pretty |
| prevail |
| prevailed |
| prevailing |
| prevalence |
| prevalent |
| prevarication |
| prevent |
| prevented |
| preventing |
| prevention |
| prevents |
| previous |
| previously |
| prey |
| preyed |
| preys |
| price |
| priceless |
| prices |
| prick |
| pricked |
| pride |
| priest |
| priestcraft |
| priestess |
| priestesses |
| priesthood |
| priestley |
| priestly |
| priests |
| prig |
| prim |
| prima |
| primal |
| primarily |
| primary |
| prime |
| primeval |
| primitive |
| primness |
| primum |
| primæval |
| prince |
| princely |
| princes |
| princess |
| principal |
| principality |
| principally |
| principia |
| principium |
| principle |
| principles |
| printed |
| printer |
| printing |
| prints |
| prior |
| priori |
| priority |
| prismatic |
| prisms |
| prison |
| prisoner |
| prisoners |
| prisons |
| pristine |
| privacy |
| private |
| privateerin |
| privateersman |
| privately |
| privation |
| privilege |
| privileges |
| prize |
| prized |
| pro |
| probabilities |
| probability |
| probable |
| probably |
| probe |
| probed |
| probes |
| probing |
| problem |
| problematical |
| problems |
| proboscis |
| proceed |
| proceeded |
| proceeding |
| proceedings |
| proceeds |
| process |
| processes |
| procession |
| processions |
| proche |
| proclaim |
| proclaimed |
| proclaiming |
| proclamation |
| proconsul |
| procure |
| procured |
| procuring |
| prodding |
| prodigal |
| prodigality |
| prodigies |
| prodigious |
| prodigiously |
| produce |
| produced |
| produces |
| producing |
| product |
| production |
| productions |
| products |
| prof |
| profanation |
| profane |
| profanely |
| profanity |
| profess |
| professed |
| professes |
| professing |
| profession |
| professional |
| professionally |
| professor |
| professors |
| professorship |
| proffered |
| proffit |
| proficiency |
| profile |
| profit |
| profited |
| profitlessly |
| profits |
| profligacy |
| profligate |
| profound |
| profoundest |
| profoundly |
| profundity |
| profuse |
| profusely |
| profuseness |
| profusion |
| prognosticated |
| prognostications |
| prognosticators |
| programme |
| progress |
| progressed |
| progression |
| progressive |
| progressively |
| prohibited |
| project |
| projected |
| projecting |
| projection |
| projections |
| projector |
| projectors |
| projects |
| prolately |
| prolong |
| prolongation |
| prolonged |
| prolonging |
| promenade |
| prometheus |
| prominence |
| prominences |
| prominent |
| promiscuous |
| promiscuously |
| promise |
| promised |
| promises |
| promising |
| promontories |
| promontory |
| prompt |
| prompted |
| promptings |
| promptly |
| prone |
| proneness |
| pronounce |
| pronounced |
| pronouncing |
| pronunciation |
| proof |
| proofs |
| propagated |
| propel |
| propeller |
| propellers |
| propelling |
| propensities |
| propensity |
| proper |
| properly |
| properties |
| property |
| prophecies |
| prophecy |
| prophesied |
| prophesy |
| prophet |
| prophetess |
| prophetic |
| propontis |
| proportion |
| proportionably |
| proportionate |
| proportionately |
| proportioned |
| proportions |
| proposal |
| proposals |
| propose |
| proposed |
| proposition |
| propositions |
| propounded |
| propounding |
| propped |
| propping |
| proprieties |
| proprietor |
| proprietors |
| propriety |
| proprætor |
| props |
| propulsion |
| propulsive |
| prosaic |
| prose |
| prosecute |
| prosecuted |
| prosecution |
| proselyte |
| prosier |
| prospect |
| prospectively |
| prospector |
| prospects |
| prosperity |
| prospero |
| prosperous |
| prostrate |
| prostrated |
| prostrating |
| prosy |
| protect |
| protected |
| protecting |
| protection |
| protector |
| protectoral |
| protectorate |
| protectors |
| protectorship |
| protectress |
| protects |
| proteges |
| protest |
| protestantism |
| protestations |
| protested |
| protracted |
| protruded |
| protruding |
| protuberance |
| proud |
| proudly |
| prove |
| proved |
| proven |
| proverb |
| proverbially |
| proverbs |
| proves |
| provide |
| provided |
| providence |
| providential |
| providentially |
| providing |
| province |
| provinces |
| provincial |
| provincials |
| proving |
| provision |
| provisions |
| proviso |
| provocation |
| provocative |
| provoke |
| provoked |
| provokingly |
| prow |
| prowler |
| prowling |
| proxenoi |
| proximate |
| proximity |
| prudence |
| prudent |
| prudential |
| pruderies |
| prudery |
| prussia |
| prussian |
| pryin |
| prying |
| præter |
| præternatural |
| prætexta |
| prætorian |
| prævalent |
| préparées |
| pseudo |
| psyche |
| psychic |
| psychically |
| psychological |
| psychologically |
| psychology |
| psychosis |
| pth |
| ptolemais |
| public |
| publication |
| publications |
| publicity |
| publick |
| publicly |
| published |
| publishing |
| publius |
| puckered |
| puddle |
| puddles |
| pudicitae |
| puerile |
| puff |
| puffed |
| puffin |
| puffings |
| puffy |
| pugnacious |
| pull |
| pulled |
| pulling |
| pulls |
| pulp |
| pulpit |
| pulpy |
| pulsation |
| pulsations |
| pulse |
| pulseless |
| pulses |
| pulsing |
| pump |
| pumped |
| pumps |
| punch |
| puncheon |
| puncheons |
| punctilios |
| punctual |
| punctuality |
| punctually |
| punctuated |
| pundit |
| pundita |
| pungencies |
| pungent |
| punish |
| punished |
| punishing |
| punishment |
| punishments |
| punning |
| puny |
| pupil |
| pupils |
| puppy |
| purchase |
| purchased |
| purchaser |
| purchases |
| purchasing |
| pure |
| purely |
| purer |
| purest |
| purgatory |
| purge |
| purification |
| purified |
| purify |
| purifying |
| puritan |
| puritanism |
| puritans |
| purity |
| purlieus |
| purling |
| purloined |
| purloiner |
| purple |
| purplish |
| purport |
| purported |
| purports |
| purpose |
| purposed |
| purposeful |
| purposeless |
| purposely |
| purposes |
| purred |
| purring |
| purse |
| purses |
| pursuance |
| pursuant |
| pursue |
| pursued |
| pursuer |
| pursuers |
| pursues |
| pursuing |
| pursuit |
| pursuits |
| pursy |
| purveyors |
| puseyism |
| push |
| pushed |
| pushing |
| puss |
| put |
| putrescently |
| putrid |
| puts |
| putting |
| putty |
| puzzle |
| puzzled |
| puzzlement |
| puzzles |
| puzzling |
| puzzlingly |
| pxh |
| pxll |
| pxxr |
| pyramid |
| pyramids |
| père |
| qu |
| quack |
| quacking |
| quadrant |
| quadrupled |
| quailed |
| quaint |
| quaintly |
| quake |
| qualche |
| qualification |
| qualifications |
| qualified |
| qualify |
| qualities |
| quality |
| qualm |
| qualms |
| quantities |
| quantity |
| quantum |
| quarrel |
| quarrels |
| quarried |
| quarry |
| quart |
| quarter |
| quartered |
| quarterly |
| quarters |
| quartier |
| quarto |
| quasi |
| quaver |
| que |
| queen |
| queenly |
| queer |
| queerer |
| queerest |
| queerly |
| queerness |
| quel |
| quelled |
| queller |
| quelling |
| quench |
| quenched |
| queries |
| querulous |
| query |
| quest |
| question |
| questioned |
| questioners |
| questioning |
| questionings |
| questions |
| questo |
| quests |
| queued |
| qui |
| quia |
| quick |
| quickened |
| quicker |
| quickly |
| quicksands |
| quid |
| quiescence |
| quiet |
| quieted |
| quieting |
| quietly |
| quietness |
| quietude |
| quill |
| quintessence |
| quit |
| quite |
| quito |
| quits |
| quitted |
| quittin |
| quitting |
| quiver |
| quivered |
| quivering |
| quivers |
| quixotic |
| quiz |
| quizzed |
| quizzem |
| quizzical |
| quondam |
| quotation |
| quotations |
| quote |
| quoted |
| quæstor |
| raabe |
| rabbit |
| rabbits |
| rabble |
| raccolto |
| race |
| raced |
| races |
| rachan |
| rack |
| racked |
| racking |
| radial |
| radiance |
| radiant |
| radiantly |
| radiate |
| radiating |
| radiation |
| radiations |
| radical |
| radicalism |
| radically |
| radicalness |
| radii |
| radio |
| radius |
| rafaelle |
| raft |
| rafters |
| rafts |
| rag |
| ragamuffin |
| rage |
| raged |
| ragged |
| raggiar |
| raging |
| rags |
| raid |
| raider |
| raiders |
| rail |
| railed |
| railing |
| railings |
| railroad |
| railrud |
| rails |
| railway |
| raiment |
| rain |
| rainbow |
| rained |
| rainfall |
| rains |
| rainy |
| raise |
| raised |
| raises |
| raising |
| raisonnement |
| rake |
| rallied |
| rally |
| ram |
| ramble |
| rambled |
| rambles |
| rambling |
| ramblings |
| ramifications |
| ramparts |
| rams |
| ramus |
| ran |
| rancour |
| randolph |
| random |
| randy |
| rang |
| range |
| ranged |
| ranger |
| rank |
| rankle |
| rankling |
| ranks |
| ransack |
| ransacked |
| ransacking |
| rant |
| ranted |
| rantipole |
| raound |
| rap |
| raphael |
| raphaelites |
| rapid |
| rapidity |
| rapidly |
| rapier |
| rapped |
| rapping |
| raps |
| rapt |
| rapture |
| raptured |
| raptures |
| rapturous |
| rapturously |
| rare |
| rarefaction |
| rarefied |
| rarely |
| rarer |
| rarest |
| rarified |
| rascal |
| rascality |
| rascally |
| rash |
| rashly |
| rashness |
| rat |
| rate |
| rated |
| rather |
| raths |
| ratio |
| ratiocination |
| rational |
| rationale |
| rationalism |
| rationally |
| rats |
| rattle |
| rattled |
| rattletrap |
| rattling |
| raucous |
| ravages |
| rave |
| raved |
| raven |
| ravenna |
| ravenous |
| ravine |
| ravines |
| raving |
| ravings |
| ravished |
| ravishing |
| ravisius |
| raw |
| rawness |
| ray |
| raylessness |
| raymond |
| rays |
| razor |
| razorlike |
| re |
| reach |
| reached |
| reaches |
| reaching |
| reaction |
| read |
| reader |
| readers |
| readier |
| readily |
| readin |
| readiness |
| reading |
| readjusted |
| reads |
| ready |
| reaffirmed |
| reagent |
| real |
| realise |
| realised |
| realising |
| realist |
| realistic |
| realities |
| reality |
| realization |
| realize |
| realized |
| reallity |
| really |
| realm |
| realms |
| reanimated |
| reanimating |
| reanimation |
| reap |
| reaper |
| reappeared |
| reapproached |
| rear |
| reared |
| reason |
| reasonable |
| reasonably |
| reasoned |
| reasoner |
| reasoners |
| reasoning |
| reasonings |
| reasons |
| reassumed |
| reassure |
| reassured |
| reassuring |
| rebel |
| rebellion |
| rebels |
| rebuild |
| rebuilt |
| rebuke |
| rebuked |
| rebukes |
| rebut |
| rebuts |
| recall |
| recalled |
| recalling |
| recalls |
| recede |
| receded |
| receding |
| receipt |
| receipted |
| receive |
| received |
| receiver |
| receivers |
| receives |
| receiving |
| recent |
| recently |
| receptacles |
| reception |
| receptive |
| recess |
| recesses |
| recherche |
| recherchés |
| recieve |
| recipients |
| reciprocity |
| recital |
| recitations |
| recitative |
| recited |
| reckless |
| recklessly |
| recklessness |
| reckon |
| reckoned |
| reckoning |
| reclined |
| reclining |
| recluse |
| recognisable |
| recognise |
| recognised |
| recognises |
| recognising |
| recognition |
| recognize |
| recognized |
| recognizing |
| recoiling |
| recollect |
| recollected |
| recollection |
| recollections |
| recombining |
| recommandable |
| recommence |
| recommenced |
| recommencing |
| recommend |
| recommendation |
| recommended |
| recommending |
| recompence |
| recompense |
| recompensing |
| reconcile |
| reconciled |
| reconnoitre |
| reconsider |
| recontre |
| record |
| recorded |
| recording |
| records |
| recount |
| recourse |
| recover |
| recovered |
| recovering |
| recovery |
| recreant |
| recreated |
| recreations |
| recrimination |
| recrossed |
| recrossing |
| recruit |
| recruits |
| rectangle |
| rectangular |
| rectangularly |
| recumbent |
| recuperating |
| recur |
| recurred |
| recurrence |
| recurrent |
| recusant |
| red |
| reddening |
| redder |
| redeem |
| redeeming |
| redivert |
| redly |
| redolent |
| redoubled |
| redress |
| redresser |
| reduce |
| reduced |
| reducing |
| reduction |
| redundance |
| reduplication |
| reed |
| reeds |
| reedy |
| reef |
| reefed |
| reefs |
| reek |
| reeked |
| reeking |
| reel |
| reeled |
| reeler |
| reeling |
| reels |
| refastened |
| refection |
| refer |
| referable |
| reference |
| references |
| referrable |
| referred |
| referrible |
| referring |
| refin |
| refine |
| refined |
| refinedly |
| refinement |
| refinery |
| refitting |
| reflect |
| reflected |
| reflecting |
| reflection |
| reflections |
| reflectors |
| reflux |
| reform |
| reformation |
| refract |
| refracted |
| refracting |
| refraction |
| refrain |
| refrained |
| refreshed |
| refreshing |
| refrigerating |
| refuge |
| refusal |
| refusals |
| refuse |
| refused |
| refuses |
| refusing |
| refutation |
| refuted |
| reg |
| regain |
| regained |
| regaining |
| regal |
| regality |
| regally |
| regard |
| regarded |
| regarding |
| regardless |
| regards |
| regenerated |
| regenerating |
| regenerators |
| regia |
| regimen |
| regiment |
| regiments |
| region |
| regional |
| regions |
| register |
| registered |
| regni |
| regnum |
| regret |
| regretful |
| regretfully |
| regrets |
| regretted |
| regular |
| regularity |
| regularly |
| regulate |
| regulated |
| regulations |
| rehearsed |
| reid |
| reign |
| reigned |
| reigneth |
| reigning |
| reigns |
| reinem |
| reinforcement |
| reinforcements |
| reins |
| reinstate |
| reiterating |
| reject |
| rejected |
| rejecting |
| rejects |
| rejoice |
| rejoiced |
| rejoices |
| rejoin |
| rejoinder |
| rejoined |
| rekindled |
| relapse |
| relapsed |
| relapsing |
| relate |
| related |
| relates |
| relating |
| relation |
| relations |
| relationship |
| relative |
| relatives |
| relativity |
| relaxed |
| relaxing |
| release |
| released |
| relent |
| relented |
| relentless |
| relevancy |
| relevant |
| reliable |
| reliance |
| relic |
| relick |
| relics |
| relied |
| relief |
| reliefs |
| relieve |
| relieved |
| relieves |
| relieving |
| religion |
| religions |
| religious |
| relinquish |
| relinquished |
| relinquishing |
| relique |
| reliques |
| relish |
| relished |
| reluctance |
| reluctant |
| reluctantly |
| rely |
| remain |
| remainder |
| remained |
| remainest |
| remaining |
| remains |
| remanded |
| remark |
| remarkable |
| remarkably |
| remarked |
| remarking |
| remarks |
| remedied |
| remedies |
| remediless |
| remedy |
| remember |
| rememberance |
| remembered |
| remembering |
| remembers |
| remembrance |
| remigius |
| remind |
| reminded |
| reminder |
| reminding |
| reminds |
| reminiscence |
| reminiscences |
| remissness |
| remittances |
| remnant |
| remnants |
| remodelled |
| remonstrance |
| remonstrances |
| remonstrate |
| remonstrated |
| remorse |
| remorseless |
| remote |
| remotely |
| remoteness |
| remoter |
| remotest |
| remounted |
| removal |
| remove |
| removed |
| removes |
| removing |
| remuneration |
| renamed |
| rencontre |
| rencounters |
| rend |
| render |
| rendered |
| rendering |
| renders |
| rendezvous |
| rending |
| renelle |
| renew |
| renewal |
| renewed |
| renewing |
| renounce |
| renounced |
| renovated |
| renovating |
| renovation |
| renown |
| renowned |
| rent |
| rented |
| renting |
| rents |
| repaid |
| repair |
| repaired |
| repairing |
| repartees |
| repassed |
| repast |
| repasts |
| repay |
| repaying |
| repayment |
| repeat |
| repeated |
| repeatedly |
| repeaters |
| repeating |
| repelled |
| repellent |
| repellently |
| repent |
| repentance |
| repentant |
| repenting |
| repeople |
| reperuse |
| repetition |
| repetitions |
| repine |
| repined |
| repinings |
| replace |
| replaced |
| replacing |
| replenish |
| replete |
| repletion |
| replica |
| replied |
| replies |
| reply |
| replying |
| report |
| reported |
| reporters |
| reporting |
| reports |
| repose |
| reposed |
| reposes |
| reposing |
| reprehensible |
| represent |
| representation |
| representations |
| representative |
| representatives |
| represented |
| representing |
| represents |
| repress |
| repressed |
| repression |
| reproach |
| reproached |
| reproaches |
| reprobated |
| reproduce |
| reproof |
| reprove |
| reptile |
| reptiles |
| reptilian |
| republic |
| republican |
| republicanism |
| republish |
| repugnance |
| repulse |
| repulsed |
| repulsion |
| repulsive |
| repulsively |
| reputation |
| repute |
| reputed |
| reputedly |
| request |
| requested |
| requesting |
| requests |
| require |
| required |
| requirements |
| requires |
| requiring |
| requisite |
| requisition |
| rescue |
| rescued |
| rescuers |
| research |
| researches |
| resemblance |
| resemble |
| resembled |
| resembles |
| resembling |
| resented |
| resentful |
| resentment |
| reserve |
| reserved |
| reserves |
| reserving |
| reside |
| resided |
| residence |
| resident |
| residents |
| residing |
| residual |
| resign |
| resignation |
| resigned |
| resignedly |
| resilience |
| resilient |
| resins |
| resist |
| resistance |
| resisted |
| resistless |
| resistlessly |
| resolute |
| resolutely |
| resolution |
| resolutions |
| resolv |
| resolve |
| resolved |
| resolvent |
| resolves |
| resolving |
| resonant |
| resort |
| resorted |
| resorting |
| resound |
| resounded |
| resounding |
| resource |
| resources |
| resourses |
| respect |
| respectaable |
| respectable |
| respected |
| respectful |
| respectfully |
| respecting |
| respective |
| respectively |
| respects |
| respiration |
| respite |
| resplendent |
| respond |
| responded |
| responding |
| response |
| responses |
| responsibilities |
| responsible |
| responsiveness |
| rest |
| restaurant |
| restaurateur |
| rested |
| resting |
| restive |
| restless |
| restlessly |
| restlessness |
| restoration |
| restorations |
| restore |
| restored |
| restoring |
| restrain |
| restrained |
| restrains |
| restraint |
| restraints |
| restriction |
| restrictions |
| rests |
| result |
| resulted |
| resulting |
| results |
| resume |
| resumed |
| resumes |
| resuming |
| resumption |
| resurgence |
| resurrection |
| resurrexit |
| resuscitation |
| retail |
| retain |
| retained |
| retaining |
| retains |
| retaliate |
| retaliations |
| retard |
| retardation |
| retarded |
| retarding |
| retention |
| retentive |
| reticence |
| reticent |
| retina |
| retire |
| retired |
| retirement |
| retires |
| retiring |
| retorts |
| retouch |
| retouched |
| retrace |
| retraced |
| retracing |
| retract |
| retreat |
| retreated |
| retreating |
| retribution |
| retrieval |
| retro |
| retrogradation |
| retrograde |
| retrograding |
| retrogression |
| retrospection |
| return |
| returned |
| returning |
| returns |
| reuss |
| reveal |
| revealed |
| revealing |
| revel |
| revelation |
| revelations |
| revelled |
| reveller |
| revellers |
| revelling |
| revelry |
| revels |
| revenge |
| revenue |
| reverberant |
| reverberated |
| reverberation |
| revere |
| reverence |
| reverenced |
| reverend |
| reverent |
| reverential |
| reverently |
| reverie |
| reveries |
| reverse |
| reversed |
| reverses |
| revert |
| reverted |
| revery |
| reviendrai |
| review |
| revisit |
| revival |
| revive |
| revived |
| revives |
| revivification |
| reviving |
| revoke |
| revolt |
| revolted |
| revolting |
| revoltingly |
| revolution |
| revolutions |
| revolve |
| revolved |
| revolver |
| revolves |
| revolving |
| revulsion |
| revulsive |
| reward |
| rewarded |
| rewards |
| rewins |
| reynolds |
| reëmbarked |
| reëntered |
| rhapsodical |
| rhapsodies |
| rhetoric |
| rhetorical |
| rhetorician |
| rheumatism |
| rheumy |
| rhine |
| rhinelander |
| rhinoceros |
| rhoades |
| rhoby |
| rhode |
| rhone |
| rhymes |
| rhythm |
| rhythmic |
| rhythmical |
| rhythmically |
| rialto |
| ribald |
| ribband |
| ribbon |
| ribbons |
| ribs |
| ricci |
| rice |
| rich |
| richbourg |
| richer |
| riches |
| richest |
| richly |
| richmond |
| richness |
| rick |
| rickety |
| rid |
| ridden |
| riddle |
| riddled |
| riddles |
| ride |
| rider |
| rides |
| ridge |
| ridged |
| ridgepole |
| ridgepoles |
| ridges |
| ridgy |
| ridicule |
| ridiculed |
| ridiculer |
| ridiculous |
| ridiculously |
| riding |
| riemannian |
| rife |
| rifkin |
| rifle |
| rift |
| rifted |
| rifts |
| rigging |
| right |
| righted |
| righteous |
| rightful |
| rightly |
| rights |
| rigid |
| rigidity |
| rigidly |
| rigmarole |
| rigorous |
| rigorously |
| rim |
| rimembra |
| rimesters |
| rimless |
| rims |
| ring |
| ringin |
| ringing |
| ringlets |
| rings |
| rinsed |
| rio |
| riot |
| rioted |
| rioters |
| riots |
| ripe |
| ripen |
| ripening |
| riper |
| ripped |
| ripping |
| ripple |
| ripples |
| rippling |
| rise |
| risen |
| risers |
| rises |
| risforo |
| rising |
| risk |
| risked |
| rite |
| rites |
| ritmo |
| ritual |
| rituals |
| ritzner |
| rival |
| rivalry |
| rivals |
| riven |
| river |
| rivers |
| rivet |
| riveted |
| rivetted |
| rivulet |
| rivulets |
| road |
| roads |
| roadway |
| roam |
| roamed |
| roamers |
| roaming |
| roams |
| roan |
| roanoke |
| roar |
| roared |
| roaring |
| roarings |
| roasted |
| rob |
| robbed |
| robber |
| robbers |
| robbery |
| robbing |
| robbins |
| robe |
| robed |
| robert |
| roberts |
| robes |
| robin |
| robust |
| rocher |
| rochester |
| rock |
| rocked |
| rocks |
| rocky |
| rod |
| rode |
| roderick |
| rodosto |
| rodriguez |
| rods |
| rogers |
| rogêt |
| roi |
| roll |
| rolled |
| rollin |
| rolling |
| roman |
| romance |
| romanised |
| romans |
| romantic |
| romanticist |
| rome |
| romero |
| romnod |
| ronald |
| roncesvalles |
| roodmas |
| roof |
| roofed |
| roofs |
| rooks |
| room |
| roomed |
| rooming |
| rooms |
| roomy |
| root |
| rooted |
| roots |
| rope |
| ropes |
| roquelaire |
| rose |
| roseal |
| roseate |
| rosemary |
| roses |
| ross |
| rosse |
| rosy |
| rot |
| rotted |
| rotten |
| rottenness |
| rotterdam |
| rottin |
| rotting |
| rotund |
| rotundity |
| rough |
| roughened |
| rougher |
| roughly |
| roule |
| roulet |
| roulets |
| round |
| roundabout |
| rounded |
| roundness |
| rounds |
| rous |
| rouse |
| roused |
| rouses |
| rousseau |
| rout |
| route |
| routed |
| routes |
| routine |
| roving |
| row |
| rowboat |
| rowdy |
| rowed |
| rowels |
| rowena |
| rowers |
| rowing |
| rowley |
| rows |
| royal |
| royalists |
| royalty |
| roysterers |
| rub |
| rubbed |
| rubber |
| rubberiness |
| rubbery |
| rubbing |
| rubbish |
| rubens |
| rubies |
| rubini |
| ruby |
| rud |
| rudder |
| rudderless |
| ruddier |
| ruddily |
| ruddy |
| rude |
| rudely |
| rudeness |
| rudiment |
| rudimental |
| rudimentary |
| rudiments |
| rue |
| ruffians |
| ruffle |
| ruffled |
| ruffles |
| rufus |
| rugged |
| ruggedness |
| ruin |
| ruined |
| ruining |
| ruinous |
| ruins |
| rule |
| ruled |
| ruler |
| rulership |
| rules |
| ruleth |
| ruling |
| rum |
| rumble |
| rumbled |
| rumbling |
| rumblings |
| rumgudgeon |
| ruminating |
| rummaging |
| rumor |
| rumors |
| rumour |
| rumoured |
| rumours |
| rumpled |
| run |
| rune |
| rung |
| runnin |
| running |
| runs |
| runway |
| rural |
| rush |
| rushed |
| rushes |
| rushin |
| rushing |
| russia |
| russian |
| rusted |
| rustic |
| rustics |
| rustle |
| rustled |
| rustling |
| rusty |
| ruth |
| ruthless |
| ruthlessly |
| ruthlessness |
| ruts |
| rutted |
| rxlling |
| ry |
| rye |
| ryland |
| rèduit |
| rôle |
| sa |
| sabage |
| sabaoth |
| sabbat |
| sabbath |
| sabbaths |
| sable |
| sachem |
| sack |
| sacking |
| sacks |
| sacred |
| sacrifice |
| sacrificed |
| sacrifices |
| sacrificing |
| sacrifise |
| sacrilege |
| sacré |
| sad |
| saddened |
| saddest |
| saddle |
| sadly |
| sadness |
| saducismus |
| safe |
| safeguard |
| safely |
| safer |
| safest |
| safety |
| saffron |
| safie |
| sag |
| sagacious |
| sagaciously |
| sagacity |
| sage |
| sages |
| sagging |
| said |
| sail |
| sailed |
| sailing |
| sailor |
| sailors |
| sails |
| saint |
| saintly |
| sake |
| sakes |
| salad |
| salary |
| sale |
| salem |
| saleve |
| salient |
| salis |
| salle |
| sallied |
| sallies |
| sallow |
| sally |
| salon |
| saloon |
| saloons |
| salsafette |
| salt |
| saltant |
| saltness |
| salts |
| salutations |
| salute |
| saluted |
| saluto |
| salvation |
| salvatorish |
| sam |
| samaria |
| same |
| sameness |
| sample |
| sampled |
| sampling |
| sampson |
| samuel |
| san |
| sanctimoniousness |
| sanctity |
| sanctum |
| sand |
| sandalled |
| sandalwood |
| sandflesen |
| sands |
| sandy |
| sane |
| saner |
| sang |
| sangsue |
| sangsues |
| sanguinary |
| sanguine |
| sanguinis |
| sanitarium |
| sanity |
| sank |
| sans |
| sanscrit |
| sanskrit |
| sansu |
| sante |
| saound |
| saouth |
| sapling |
| saplings |
| sapped |
| sapphires |
| saraband |
| saracen |
| saracenic |
| saracens |
| saratoga |
| sarcastic |
| sarcophagi |
| sarcophagus |
| sardanapalus |
| sardonic |
| sardonically |
| sardonyx |
| sargent |
| sarkis |
| sarnath |
| sartain |
| sarten |
| sarved |
| sash |
| sashes |
| sassafras |
| sasso |
| sat |
| satan |
| satanic |
| satanism |
| sate |
| satellite |
| satellites |
| satiate |
| satiated |
| satiating |
| satiety |
| satin |
| satinet |
| satires |
| satirical |
| satirist |
| satisfaction |
| satisfactorily |
| satisfactory |
| satisfied |
| satisfy |
| satisfyin |
| satisfying |
| saturated |
| saturday |
| saturn |
| saturnian |
| satyr |
| sauce |
| saucers |
| sauer |
| sauerkraut |
| sauntered |
| sauntering |
| saurians |
| sausage |
| sauterne |
| savage |
| savagely |
| savages |
| savans |
| save |
| saved |
| saves |
| saville |
| saving |
| saviour |
| savor |
| savouring |
| savoury |
| savoy |
| saw |
| sawing |
| saws |
| sawyer |
| saxon |
| say |
| sayest |
| sayin |
| saying |
| sayings |
| says |
| scabby |
| scaffold |
| scalable |
| scalding |
| scale |
| scaled |
| scaleless |
| scales |
| scaling |
| scalp |
| scaly |
| scamp |
| scampering |
| scampers |
| scanned |
| scanning |
| scant |
| scantiness |
| scantlings |
| scanty |
| scar |
| scarabæus |
| scarce |
| scarcely |
| scarcity |
| scare |
| scarecrow |
| scared |
| scarf |
| scarlet |
| scarred |
| scatter |
| scattered |
| scattering |
| scene |
| scenery |
| scenes |
| scenic |
| scent |
| scented |
| scentless |
| scents |
| sceptical |
| scepticism |
| sceptre |
| schaack |
| schacabao |
| scheme |
| schemed |
| schemes |
| schiavi |
| schiedam |
| schiller |
| schiraz |
| schlumberger |
| schmidt |
| schneider |
| scholar |
| scholarly |
| school |
| schoolboy |
| schoolboys |
| schooled |
| schoolfellow |
| schoolfellows |
| schooling |
| schoolmaster |
| schoolmasters |
| schools |
| schooner |
| schultz |
| schweinkopf |
| science |
| sciences |
| scientific |
| scientifically |
| scientist |
| scientists |
| scimetar |
| scimitar |
| scion |
| scions |
| scipio |
| scoff |
| scoffed |
| scoffing |
| scoffs |
| scold |
| scooped |
| scope |
| scorched |
| scorching |
| score |
| scored |
| scores |
| scorn |
| scorned |
| scornful |
| scorning |
| scotch |
| scotland |
| scott |
| scoundrel |
| scoundrelly |
| scoundrels |
| scourge |
| scouts |
| scowl |
| scowling |
| scraggy |
| scramble |
| scrambled |
| scrambling |
| scrap |
| scrape |
| scraped |
| scraping |
| scraps |
| scratched |
| scratching |
| scratchings |
| scrawl |
| scrawled |
| scream |
| screamed |
| screamin |
| screaming |
| screams |
| screechin |
| screeching |
| screen |
| screens |
| screw |
| screwed |
| scribble |
| scribbler |
| scribonius |
| scripta |
| scripter |
| scriptural |
| scriptures |
| scrofulous |
| scroll |
| scrolls |
| scrub |
| scruple |
| scruples |
| scrupulous |
| scrupulously |
| scrutinized |
| scrutinizing |
| scrutiny |
| scud |
| scudded |
| scuffle |
| scuffling |
| scull |
| scullion |
| sculptor |
| sculptors |
| sculptural |
| sculpture |
| sculptured |
| sculptures |
| scum |
| scurce |
| scurrying |
| scurryings |
| scuttled |
| scymetars |
| scythe |
| scythes |
| scythian |
| scythians |
| se |
| sea |
| seabright |
| seafaring |
| seal |
| sealed |
| sealing |
| seaman |
| seamed |
| seamen |
| seaport |
| search |
| searched |
| searchers |
| searches |
| searchest |
| searching |
| searchings |
| searchlight |
| seared |
| searing |
| seas |
| seashore |
| season |
| seasonable |
| seasons |
| seat |
| seated |
| seating |
| seaton |
| seats |
| seaward |
| seaweed |
| secede |
| seceded |
| secession |
| sech |
| secluded |
| seclusion |
| secon |
| second |
| secondary |
| seconded |
| secondly |
| seconds |
| secrecy |
| secret |
| secretary |
| secreted |
| secreting |
| secretive |
| secretiveness |
| secretly |
| secrets |
| section |
| sections |
| sects |
| secundum |
| secundus |
| secure |
| secured |
| securely |
| securing |
| securities |
| security |
| sedge |
| sedges |
| seduce |
| seduced |
| seductions |
| see |
| seed |
| seediness |
| seeds |
| seedsman |
| seeing |
| seek |
| seeker |
| seekers |
| seekest |
| seeking |
| seekings |
| seeks |
| seem |
| seemed |
| seemest |
| seeming |
| seemingly |
| seems |
| seen |
| seeped |
| seeping |
| sees |
| seest |
| seething |
| sefton |
| segment |
| segonde |
| seine |
| seize |
| seized |
| seizing |
| seizure |
| seldom |
| select |
| selected |
| selecting |
| selection |
| selectiveness |
| selectman |
| selects |
| self |
| selfconcentrated |
| selfish |
| selfishness |
| selfsame |
| selina |
| sell |
| selle |
| sellin |
| selling |
| selvatic |
| selves |
| semblance |
| semele |
| semi |
| semicircle |
| semicircular |
| semitic |
| senate |
| senatorial |
| senatus |
| sence |
| senct |
| send |
| sending |
| sends |
| senility |
| senior |
| sensation |
| sensations |
| sense |
| sensed |
| senseless |
| senses |
| sensibilities |
| sensibility |
| sensible |
| sensibly |
| sensitive |
| sensitiveness |
| sensorium |
| sensual |
| sent |
| sentence |
| sentences |
| sententious |
| sentience |
| sentient |
| sentiment |
| sentimental |
| sentiments |
| sentinel |
| sentries |
| sentry |
| senty |
| sep |
| separate |
| separated |
| separately |
| separates |
| separating |
| separation |
| seperate |
| seperated |
| seperation |
| september |
| septic |
| sepulchral |
| sepulchre |
| sepulchred |
| sepulchres |
| sepulchrum |
| sepulture |
| sepultus |
| sequel |
| sequence |
| sera |
| seraglio |
| serai |
| serannian |
| seraph |
| seraphic |
| sere |
| serene |
| serenity |
| sereno |
| serge |
| series |
| seringa |
| serious |
| seriously |
| seriousness |
| sermon |
| serpent |
| serpents |
| servant |
| servants |
| serve |
| served |
| serves |
| servi |
| service |
| serviceable |
| services |
| servile |
| serving |
| serviss |
| servitor |
| servitors |
| servitude |
| ses |
| sesquipedalian |
| session |
| set |
| seth |
| sets |
| settin |
| setting |
| settings |
| settle |
| settled |
| settlement |
| settlers |
| settles |
| settling |
| seul |
| seulement |
| seven |
| seventeen |
| seventeenth |
| seventh |
| seventy |
| several |
| severally |
| severe |
| severed |
| severely |
| severing |
| severity |
| sewer |
| sewers |
| sex |
| sexes |
| sexton |
| señor |
| shabby |
| shackles |
| shade |
| shaded |
| shades |
| shadow |
| shadowed |
| shadowingly |
| shadows |
| shadowy |
| shady |
| shaft |
| shafts |
| shaggy |
| shake |
| shaken |
| shakes |
| shakespear |
| shakespeare |
| shakiness |
| shaking |
| shakspeare |
| shaky |
| shall |
| shallop |
| shallow |
| shallowness |
| shallows |
| shalmanezer |
| shalt |
| sham |
| shamble |
| shambled |
| shambling |
| shame |
| shamed |
| shameful |
| shamefully |
| shang |
| shank |
| shaoutin |
| shape |
| shaped |
| shapeless |
| shapes |
| share |
| shared |
| sharer |
| sharers |
| sharing |
| shark |
| sharp |
| sharpened |
| sharper |
| sharply |
| sharpness |
| shattered |
| shaven |
| shaving |
| shawls |
| she |
| sheared |
| shears |
| sheath |
| sheathe |
| sheathed |
| shed |
| shedding |
| sheds |
| sheehan |
| sheep |
| sheepishly |
| sheer |
| sheet |
| sheets |
| shelf |
| shell |
| shelled |
| shells |
| shelter |
| sheltered |
| sheltering |
| shelterless |
| shelves |
| shelving |
| shepherd |
| shepherded |
| shepherds |
| shepley |
| sheppard |
| shet |
| shew |
| shewed |
| shewing |
| shewn |
| shews |
| shicken |
| shield |
| shielded |
| shift |
| shifted |
| shifting |
| shifts |
| shilling |
| shimmered |
| shimmering |
| shimmers |
| shine |
| shines |
| shingled |
| shingles |
| shining |
| shiny |
| ship |
| shipbuilding |
| shipmate |
| shipped |
| shippin |
| shipping |
| ships |
| shirt |
| shiver |
| shivered |
| shivering |
| shiveringly |
| shivers |
| shivery |
| shoals |
| shock |
| shocked |
| shocking |
| shockingly |
| shod |
| shoemaker |
| shoes |
| shoggoth |
| shone |
| shonson |
| shook |
| shoot |
| shooting |
| shoots |
| shop |
| shopkeeper |
| shopping |
| shops |
| shore |
| shoreless |
| shores |
| shorn |
| short |
| shorten |
| shortened |
| shorter |
| shortly |
| shot |
| shots |
| shou |
| should |
| shoulder |
| shouldered |
| shoulders |
| shouldst |
| shout |
| shouted |
| shouting |
| shoutings |
| shouts |
| shoved |
| show |
| showed |
| shower |
| showered |
| showers |
| showing |
| shown |
| shows |
| showy |
| shrank |
| shreds |
| shrewd |
| shrewdness |
| shriek |
| shrieked |
| shrieking |
| shriekingly |
| shrieks |
| shrill |
| shriller |
| shrilling |
| shrilly |
| shrine |
| shrines |
| shrink |
| shrinkage |
| shrinking |
| shrinks |
| shrivel |
| shrivelled |
| shroud |
| shrouded |
| shrouding |
| shrouds |
| shrub |
| shrubberies |
| shrubbery |
| shrubs |
| shrugged |
| shrunk |
| shrunken |
| shub |
| shud |
| shudder |
| shuddered |
| shuddering |
| shudderingly |
| shudders |
| shuffle |
| shuffled |
| shuffling |
| shun |
| shunned |
| shunning |
| shuns |
| shut |
| shuts |
| shutter |
| shuttered |
| shutters |
| shuttin |
| shutting |
| shuttlecock |
| si |
| sibyl |
| sic |
| sicilian |
| sicily |
| sick |
| sickbed |
| sicken |
| sickened |
| sickening |
| sickeningly |
| sickle |
| sickly |
| sickness |
| side |
| sidelong |
| sides |
| sidetracked |
| sidewalk |
| sidewalks |
| sidewise |
| sidled |
| sidney |
| sidrak |
| sie |
| siege |
| sieur |
| sieve |
| sift |
| sifted |
| sigh |
| sighed |
| sighing |
| sighs |
| sight |
| sighted |
| sightless |
| sightlessly |
| sights |
| sightseeing |
| sign |
| signal |
| signalizing |
| signature |
| signboards |
| signed |
| significance |
| significant |
| significantly |
| signified |
| signing |
| signor |
| signora |
| signs |
| silence |
| silenced |
| silent |
| silently |
| silhouette |
| silhouetted |
| silhouetting |
| silius |
| silk |
| silken |
| sill |
| silly |
| silva |
| silver |
| silverware |
| silvery |
| sime |
| simia |
| simian |
| similar |
| similarity |
| similarly |
| simile |
| similes |
| similitude |
| simoon |
| simple |
| simplest |
| simpleton |
| simplicity |
| simply |
| simpson |
| simultaneous |
| simultaneously |
| sin |
| sinara |
| since |
| sincere |
| sincerely |
| sincerest |
| sincerity |
| sinciput |
| sine |
| sinecures |
| sinful |
| sing |
| singed |
| singer |
| singin |
| singing |
| single |
| singleness |
| singly |
| sings |
| singular |
| singularity |
| singularly |
| sinister |
| sinivate |
| sink |
| sinking |
| sinks |
| sinless |
| sinned |
| sinner |
| sinuous |
| sipped |
| sir |
| sire |
| sirocco |
| sis |
| sister |
| sisters |
| sit |
| site |
| sits |
| sitter |
| sitting |
| sittings |
| situated |
| situation |
| situations |
| six |
| sixteen |
| sixteenth |
| sixth |
| sixthly |
| sixty |
| size |
| sized |
| sizes |
| skai |
| skeered |
| skeert |
| skein |
| skeleton |
| skeletons |
| skeptical |
| sketch |
| sketched |
| sketches |
| sketchy |
| skies |
| skiey |
| skiff |
| skilful |
| skilfully |
| skill |
| skilled |
| skim |
| skimmed |
| skimming |
| skims |
| skin |
| skinned |
| skins |
| skipped |
| skirmishes |
| skirted |
| skirting |
| skirts |
| skulking |
| skull |
| skulls |
| sky |
| skylight |
| skyline |
| slab |
| slabs |
| slack |
| slacken |
| slackened |
| slackenin |
| slackening |
| slader |
| slain |
| slake |
| slammed |
| slamming |
| slander |
| slandered |
| slang |
| slant |
| slanting |
| slantwise |
| slashed |
| slate |
| slater |
| slatternly |
| slaughter |
| slaughtered |
| slave |
| slavered |
| slavering |
| slavery |
| slaves |
| slay |
| slayer |
| slayeth |
| slayin |
| slaying |
| sledge |
| sleek |
| sleep |
| sleeper |
| sleepers |
| sleeping |
| sleepless |
| sleeplessly |
| sleeps |
| sleepy |
| sleeve |
| sleeves |
| slender |
| slept |
| slew |
| slid |
| slide |
| sliding |
| slight |
| slighter |
| slightest |
| slightly |
| slim |
| slime |
| slimy |
| slinking |
| slip |
| slipped |
| slippers |
| slippery |
| slipping |
| slips |
| slipt |
| slit |
| slithered |
| sliver |
| slobberingly |
| sloop |
| slope |
| sloped |
| slopes |
| sloping |
| slopping |
| sloth |
| slothful |
| slouched |
| slough |
| slovenly |
| slow |
| slowly |
| slowness |
| sluggish |
| slum |
| slumber |
| slumbered |
| slumberer |
| slumbering |
| slumbers |
| slums |
| slunk |
| slushy |
| sluys |
| slxw |
| sly |
| slyass |
| slyly |
| smack |
| small |
| smaller |
| smallest |
| smart |
| smarting |
| smartly |
| smeared |
| smell |
| smelled |
| smelling |
| smells |
| smelt |
| smile |
| smiled |
| smiles |
| smiling |
| smilingly |
| smith |
| smitherton |
| smoke |
| smoked |
| smokeless |
| smoking |
| smoky |
| smooth |
| smoothed |
| smoother |
| smoothly |
| smote |
| smother |
| smothered |
| smothering |
| smug |
| smuggle |
| smuggled |
| snail |
| snake |
| snakes |
| snap |
| snapped |
| snapping |
| snapt |
| snares |
| snarled |
| snarling |
| snatch |
| snatched |
| snatchers |
| snatches |
| snatching |
| sneer |
| sneered |
| snob |
| snobbs |
| snow |
| snowball |
| snowdrifts |
| snowed |
| snowing |
| snowless |
| snows |
| snowy |
| snub |
| snuff |
| snuffy |
| snug |
| snugger |
| snugly |
| so |
| soaked |
| soaking |
| soames |
| soar |
| soared |
| soaring |
| soarings |
| soars |
| sob |
| sobbed |
| sobbing |
| sober |
| sobriety |
| sobs |
| sociable |
| social |
| socially |
| societies |
| society |
| sociologist |
| socket |
| sockets |
| socrates |
| sod |
| sodales |
| sodden |
| sods |
| sofa |
| soft |
| soften |
| softened |
| softening |
| softer |
| softest |
| softly |
| softness |
| soho |
| soient |
| soil |
| soiled |
| sojourn |
| sojourners |
| sojourning |
| solace |
| solar |
| sold |
| soldier |
| soldiers |
| soldiery |
| sole |
| soleil |
| solely |
| solemn |
| solemnity |
| solemnly |
| soles |
| solicited |
| solicitous |
| solicitously |
| solicitude |
| solid |
| solidity |
| soliloquies |
| soliloquy |
| solitary |
| solitude |
| solitudes |
| solomon |
| solstice |
| solsticial |
| solstitial |
| soluble |
| solution |
| solutions |
| solve |
| solved |
| solving |
| sombre |
| some |
| somebody |
| somehaow |
| somehow |
| someone |
| somethin |
| something |
| sometime |
| sometimes |
| somewhat |
| somewhere |
| somnambulism |
| somnambulist |
| somnolent |
| somthing |
| son |
| sona |
| song |
| songs |
| sonido |
| sonnets |
| sonorous |
| sonorously |
| sons |
| sonum |
| soon |
| sooner |
| sooth |
| soothe |
| soothed |
| soothing |
| soothings |
| sophia |
| sophist |
| sophisticated |
| sophistication |
| sophists |
| sorcery |
| sorcier |
| sordid |
| sore |
| sorely |
| sores |
| sorrow |
| sorrowed |
| sorrowful |
| sorrowfully |
| sorrowing |
| sorrows |
| sorry |
| sort |
| sorta |
| sorts |
| sospiri |
| sot |
| sothoth |
| sotto |
| sought |
| soul |
| souled |
| soulless |
| souls |
| sound |
| sounded |
| soundest |
| sounding |
| soundless |
| soundly |
| sounds |
| soup |
| sour |
| source |
| sources |
| sourit |
| south |
| southeast |
| southeastern |
| southeastward |
| southerly |
| southern |
| southward |
| southwardly |
| southwards |
| southwest |
| southwesterly |
| souvenirs |
| sovereign |
| sovereignty |
| sow |
| sowing |
| sown |
| spa |
| space |
| spaces |
| spacious |
| spade |
| spades |
| spain |
| spake |
| spallanzani |
| span |
| spangled |
| spaniard |
| spaniards |
| spanish |
| spanked |
| spanker |
| spanned |
| spar |
| spare |
| spared |
| spareness |
| spark |
| sparkled |
| sparkling |
| sparks |
| sparse |
| sparsely |
| spartan |
| spasm |
| spasmodic |
| spasmodically |
| spasms |
| spatial |
| spattering |
| spawn |
| spawned |
| spawning |
| speak |
| speaker |
| speaking |
| speaks |
| spears |
| special |
| specialised |
| specialist |
| specially |
| specie |
| species |
| specific |
| specifically |
| specified |
| specimen |
| specimens |
| specious |
| speck |
| specked |
| speckled |
| spect |
| spectacle |
| spectacled |
| spectacles |
| spectacularly |
| spectator |
| spectators |
| spectral |
| spectre |
| spectres |
| spectrum |
| speculate |
| speculated |
| speculating |
| speculation |
| speculations |
| speculative |
| speculatively |
| speculator |
| speculum |
| sped |
| speech |
| speeches |
| speechless |
| speed |
| speeded |
| speedily |
| speeding |
| speedy |
| spell |
| spells |
| spelt |
| spencer |
| spend |
| spending |
| spent |
| sphere |
| spheres |
| spherical |
| spheroidal |
| sphinx |
| sphynxes |
| spices |
| spicing |
| spicy |
| spider |
| spiders |
| spies |
| spike |
| spikes |
| spiky |
| spilled |
| spin |
| spinal |
| spindling |
| spinning |
| spins |
| spiral |
| spirals |
| spire |
| spires |
| spirit |
| spirited |
| spiritless |
| spirits |
| spiritual |
| spirituality |
| spit |
| spite |
| splash |
| splashed |
| splashin |
| splashing |
| splendid |
| splendidly |
| splendor |
| splendour |
| splenetic |
| spliced |
| splinter |
| splintered |
| splintering |
| splinters |
| split |
| splitting |
| spoil |
| spoiled |
| spoils |
| spoilt |
| spoke |
| spoken |
| spontaneous |
| spontaneously |
| sport |
| sported |
| sporting |
| sportive |
| sports |
| spot |
| spots |
| spotted |
| spouting |
| sprang |
| sprawled |
| sprawling |
| spray |
| sprayer |
| spread |
| spreading |
| spreads |
| sprightliest |
| sprightly |
| spring |
| springfield |
| springing |
| springs |
| springy |
| sprinkle |
| sprinkling |
| sprinklings |
| sprite |
| sprouted |
| sprouting |
| sprung |
| spun |
| spunging |
| spur |
| spurn |
| spurned |
| spurred |
| spurzheimites |
| sputter |
| sputtered |
| sputtering |
| spy |
| squad |
| squadrons |
| squalid |
| squalidness |
| squall |
| squalling |
| squalor |
| squander |
| squar |
| square |
| squarely |
| squares |
| squat |
| squatted |
| squatter |
| squatters |
| squatting |
| squawking |
| squeaking |
| squealing |
| squeals |
| squeeze |
| squeezed |
| squid |
| squint |
| squire |
| squirmed |
| squirmin |
| squirrels |
| st |
| stab |
| stabbing |
| stability |
| stable |
| stables |
| stably |
| stack |
| stael |
| staff |
| stafford |
| stag |
| stage |
| stages |
| stagger |
| staggered |
| staggering |
| stagnation |
| staid |
| stain |
| stained |
| stains |
| stair |
| staircase |
| staircases |
| stairs |
| stairway |
| stake |
| stakes |
| stale |
| staleness |
| stalked |
| stalking |
| stall |
| stalled |
| stalls |
| stalwart |
| stamboul |
| stamen |
| stamp |
| stamped |
| stampede |
| stamping |
| stampt |
| stand |
| standard |
| standards |
| standing |
| stands |
| standstill |
| stanza |
| stanzas |
| staples |
| stapleton |
| star |
| starboard |
| stare |
| stared |
| stares |
| starfish |
| staring |
| stark |
| starred |
| starry |
| stars |
| start |
| started |
| startin |
| starting |
| startle |
| startled |
| startling |
| starts |
| starvation |
| starving |
| state |
| stated |
| stately |
| statement |
| states |
| statesmen |
| static |
| stating |
| station |
| stationary |
| stationed |
| stations |
| statuary |
| statue |
| statues |
| statuette |
| stature |
| status |
| stave |
| stay |
| stayed |
| stays |
| stead |
| steadied |
| steadily |
| steady |
| steadying |
| steal |
| stealing |
| steals |
| stealth |
| stealthily |
| stealthy |
| steam |
| steamboat |
| steamed |
| steams |
| stedfast |
| steed |
| steeds |
| steel |
| steely |
| steen |
| steep |
| steeped |
| steeper |
| steeple |
| steepled |
| steeples |
| steeply |
| steeps |
| steer |
| steered |
| stem |
| stemmed |
| stemming |
| stems |
| stench |
| stenches |
| stentorian |
| step |
| stephanie |
| stephen |
| stepped |
| stepping |
| steps |
| sterb |
| stereotomy |
| sterile |
| sterling |
| stern |
| sterner |
| sterness |
| sternest |
| sternly |
| sternness |
| stertorous |
| steward |
| stewing |
| stick |
| stickin |
| stickiness |
| sticking |
| sticks |
| sticky |
| stiff |
| stiffened |
| stiffening |
| stiffly |
| stiffness |
| stifle |
| stifled |
| stifling |
| stigma |
| stigmata |
| stiletto |
| still |
| stillness |
| stills |
| stilpo |
| stilted |
| stimulant |
| stimulants |
| stimulated |
| stimulates |
| stimuli |
| stimulus |
| sting |
| stinging |
| stings |
| stinking |
| stir |
| stirred |
| stirring |
| stirs |
| stock |
| stocked |
| stockings |
| stocks |
| stole |
| stolen |
| stolid |
| stolidity |
| stomach |
| stompin |
| stone |
| stonehenge |
| stones |
| stony |
| stood |
| stoop |
| stooped |
| stooping |
| stoops |
| stop |
| stoppage |
| stopped |
| stopping |
| stops |
| stopt |
| storage |
| store |
| stored |
| storehouse |
| stores |
| storied |
| stories |
| storm |
| stormed |
| storms |
| stormy |
| story |
| stout |
| stouter |
| stoutest |
| stoutly |
| stove |
| stovepipe |
| stovepipes |
| stowage |
| stowageroom |
| stowed |
| stragglers |
| straggling |
| straight |
| straighten |
| straightened |
| straightforward |
| straightway |
| strain |
| strained |
| strainin |
| straining |
| strains |
| strait |
| straitjacket |
| strand |
| stranded |
| strands |
| strange |
| strangely |
| strangeness |
| strangenesses |
| stranger |
| strangers |
| strangest |
| strangle |
| strangled |
| strangley |
| strap |
| strasbourg |
| strata |
| stratagem |
| straw |
| stray |
| strayed |
| streak |
| streaked |
| streaks |
| stream |
| streamed |
| streamer |
| streaming |
| streamlet |
| streamlets |
| streams |
| street |
| streets |
| strength |
| strengthen |
| strengthened |
| strenuous |
| strenuously |
| stress |
| stretch |
| stretched |
| stretches |
| stretching |
| strew |
| strewed |
| strewing |
| strewn |
| stricken |
| strict |
| strictest |
| strictly |
| strictness |
| stride |
| strident |
| strides |
| stridor |
| strife |
| strike |
| striken |
| strikes |
| striking |
| strikingly |
| string |
| stringed |
| strings |
| strip |
| striped |
| stripling |
| strips |
| strive |
| strived |
| striven |
| strives |
| striving |
| strode |
| stroke |
| stroked |
| strokes |
| stroll |
| strolled |
| strolling |
| strong |
| stronger |
| strongest |
| stronghold |
| strongly |
| strove |
| strowed |
| strown |
| struck |
| structure |
| structures |
| struggle |
| struggled |
| struggles |
| struggling |
| strung |
| ström |
| stubble |
| stubborn |
| stubbornness |
| stubbs |
| stubby |
| stucco |
| stuccoed |
| stuck |
| stud |
| studded |
| studding |
| student |
| students |
| studied |
| studies |
| studio |
| studious |
| studiously |
| study |
| studying |
| stuff |
| stuffed |
| stuffs |
| stuffundpuff |
| stultifying |
| stumble |
| stumbled |
| stumbling |
| stumps |
| stumpy |
| stung |
| stunned |
| stunning |
| stunted |
| stupefied |
| stupendous |
| stupid |
| stupidity |
| stupidly |
| stupified |
| stupor |
| sturdily |
| sturdy |
| stxp |
| sty |
| stygian |
| style |
| styled |
| styles |
| stylus |
| suarven |
| suavity |
| sub |
| subalterns |
| subcenturio |
| subconscious |
| subconsciously |
| subdivisions |
| subdue |
| subdued |
| subduing |
| subject |
| subjected |
| subjection |
| subjective |
| subjects |
| subjoined |
| sublimating |
| sublimation |
| sublime |
| sublimely |
| sublimest |
| sublimity |
| submarine |
| submerge |
| submerged |
| submerging |
| submission |
| submissive |
| submit |
| submitted |
| subordinate |
| subscription |
| subscriptions |
| subsequent |
| subsequently |
| subservient |
| subside |
| subsided |
| subsist |
| subsisted |
| subsistence |
| substance |
| substances |
| substantial |
| substantiality |
| substantially |
| substantive |
| substitute |
| substituted |
| substituting |
| subtended |
| subtends |
| subterranean |
| subterraneous |
| subterrene |
| subtle |
| subtler |
| subtlest |
| subtlety |
| subtly |
| subtractions |
| suburbs |
| subway |
| subways |
| succeed |
| succeeded |
| succeeding |
| succeeds |
| success |
| successes |
| successful |
| successfully |
| succession |
| successive |
| successively |
| succinctly |
| succour |
| succouring |
| succourless |
| succumb |
| succumbed |
| such |
| sucked |
| sucking |
| suction |
| sudden |
| suddenly |
| suddenness |
| suddent |
| suffer |
| sufferance |
| suffered |
| sufferer |
| sufferers |
| suffering |
| sufferings |
| suffers |
| suffice |
| sufficed |
| sufficient |
| sufficiently |
| suffocated |
| suffocating |
| suffocation |
| suffrage |
| suffuse |
| suffused |
| suffusion |
| sugar |
| suggest |
| suggested |
| suggesting |
| suggestion |
| suggestions |
| suggestive |
| suggests |
| suicidal |
| suicide |
| suit |
| suitable |
| suite |
| suited |
| suitor |
| suitors |
| suky |
| sul |
| sulky |
| sullen |
| sulleness |
| sullenly |
| sullenness |
| sullied |
| sulphur |
| sulphuric |
| sulphurous |
| sultan |
| sum |
| sumatry |
| summary |
| summed |
| summer |
| summers |
| summit |
| summits |
| summon |
| summoned |
| summoning |
| summons |
| sumptuous |
| sumptuously |
| sums |
| sun |
| sunbeam |
| sunbeams |
| sunburn |
| sunburned |
| sunda |
| sunday |
| sundays |
| sunder |
| sundials |
| sundown |
| sundry |
| sunfish |
| sung |
| sunk |
| sunken |
| sunless |
| sunlight |
| sunnier |
| sunny |
| sunrise |
| suns |
| sunset |
| sunshine |
| sunship |
| sunt |
| sunup |
| super |
| superabundant |
| superadded |
| superb |
| superbus |
| supercargo |
| supererogation |
| supererogatory |
| superficial |
| superficially |
| superfluities |
| superfluity |
| superfluous |
| superhuman |
| superimposed |
| superinduced |
| superinduces |
| superintend |
| superintended |
| superintendence |
| superintendent |
| superior |
| superiority |
| superiors |
| superlatively |
| supernal |
| supernatural |
| supernaturalism |
| supernaturally |
| supernormal |
| supernumerary |
| superscription |
| superseded |
| superstition |
| superstitions |
| superstitious |
| superstructure |
| supervened |
| supervision |
| supine |
| supinely |
| supped |
| supper |
| supple |
| suppliant |
| supplicating |
| supplication |
| supplied |
| supplies |
| supply |
| supplying |
| support |
| supported |
| supporters |
| supporting |
| supports |
| suppose |
| supposed |
| supposedly |
| supposes |
| supposing |
| supposition |
| supposititious |
| suppress |
| suppressed |
| suppressing |
| suppression |
| supremacy |
| supreme |
| supremely |
| supremeness |
| supressed |
| sur |
| surcharged |
| surcingle |
| sure |
| surely |
| surest |
| surf |
| surface |
| surfaced |
| surfaces |
| surge |
| surged |
| surgeon |
| surgeons |
| surgery |
| surgical |
| surgically |
| surging |
| surliness |
| surmised |
| surmises |
| surmount |
| surmounted |
| surmounting |
| surname |
| surnamed |
| surpass |
| surpassed |
| surpassing |
| surpassingly |
| surplus |
| surpris |
| surprise |
| surprised |
| surprising |
| surprisingly |
| surrender |
| surrendered |
| surreptitiously |
| surrey |
| surround |
| surrounded |
| surrounding |
| surroundings |
| survey |
| surveyed |
| surveying |
| survival |
| survive |
| survived |
| survives |
| surviving |
| survivor |
| survivors |
| susceptibility |
| susceptible |
| suspect |
| suspected |
| suspecting |
| suspects |
| suspend |
| suspended |
| suspenders |
| suspending |
| suspense |
| suspensions |
| suspicion |
| suspicions |
| suspicious |
| suspiciously |
| sustain |
| sustained |
| sustaining |
| sustenance |
| suthin |
| swaggerers |
| swallow |
| swallowed |
| swallowing |
| swallows |
| swam |
| swammerdamm |
| swamp |
| swamping |
| swamps |
| swan |
| swar |
| sward |
| swarm |
| swarmed |
| swarming |
| swarms |
| swart |
| swarthy |
| swastika |
| swath |
| swathed |
| swaths |
| sway |
| swayed |
| swaying |
| swear |
| swears |
| sweat |
| swede |
| swedenborg |
| sweep |
| sweepest |
| sweeping |
| sweeps |
| sweet |
| sweeter |
| sweetest |
| sweetly |
| sweetness |
| sweets |
| swell |
| swelled |
| swelling |
| swells |
| sweltering |
| swelters |
| swept |
| swerved |
| swerving |
| swift |
| swifter |
| swiftly |
| swiftness |
| swilled |
| swim |
| swimmer |
| swimmers |
| swimmin |
| swimming |
| swine |
| swing |
| swinging |
| swirled |
| swirling |
| swishin |
| swiss |
| switch |
| switched |
| switzerland |
| swollen |
| swoon |
| swooned |
| swooning |
| swoop |
| sword |
| swords |
| swore |
| sworn |
| swung |
| sx |
| sxrrxws |
| sxw |
| sy |
| sybils |
| sycamore |
| sydney |
| syfe |
| syllabification |
| syllable |
| syllabled |
| syllables |
| sylvan |
| symbol |
| symbolic |
| symbolised |
| symbolism |
| symbolists |
| symbols |
| symmetries |
| symmetry |
| sympathetic |
| sympathies |
| sympathise |
| sympathised |
| sympathize |
| sympathized |
| sympathizes |
| sympathizing |
| sympathy |
| symphonic |
| symptom |
| symptoms |
| synchronised |
| synchronous |
| synthetic |
| syphon |
| syracusans |
| syracuse |
| syria |
| syrian |
| syrians |
| syrups |
| system |
| systematic |
| systematizing |
| systems |
| ta |
| tabards |
| tabitha |
| table |
| tables |
| tablet |
| tablets |
| tabulation |
| taci |
| tacit |
| taciturn |
| taciturnity |
| tack |
| tacked |
| taffety |
| taffrail |
| tail |
| tailor |
| tailors |
| tails |
| taint |
| tainted |
| take |
| taken |
| takes |
| takin |
| taking |
| talbot |
| talbots |
| tale |
| talent |
| talented |
| talents |
| tales |
| talisman |
| talk |
| talkative |
| talked |
| talkin |
| talking |
| talks |
| tall |
| taller |
| tallest |
| tallied |
| talons |
| tame |
| tamed |
| tameless |
| tamely |
| tamer |
| tampered |
| tampering |
| tan |
| tanarian |
| tanbark |
| tangent |
| tangible |
| tangibly |
| tangle |
| tangled |
| tangles |
| tank |
| tankards |
| tantalisingly |
| tantalization |
| tantalize |
| tantalized |
| tantum |
| taown |
| tap |
| tape |
| taper |
| tapering |
| tapers |
| tapestried |
| tapestries |
| tapestry |
| tapis |
| tappa |
| tapped |
| taps |
| tar |
| taran |
| tardily |
| tardy |
| target |
| tarn |
| tarnish |
| tarnished |
| tarpaulin |
| tarraco |
| tarred |
| tarried |
| tarry |
| tartan |
| tartarus |
| tartary |
| task |
| tasking |
| tasks |
| taste |
| tasted |
| tasteful |
| tastes |
| tasty |
| tat |
| tattered |
| tatters |
| tattle |
| tattoo |
| taught |
| taunt |
| tavern |
| taverns |
| tawdry |
| tawny |
| tax |
| taxed |
| taxi |
| tay |
| te |
| tea |
| teach |
| teacher |
| teachers |
| teaching |
| teak |
| team |
| teapot |
| tear |
| tearful |
| tearing |
| tears |
| technical |
| technically |
| technique |
| tedious |
| tedium |
| tee |
| teem |
| teeming |
| teeth |
| teetotum |
| tegea |
| tegeans |
| teian |
| teios |
| tekel |
| telegraph |
| telegraphy |
| telepathic |
| telepathy |
| telephone |
| telephoned |
| telephoning |
| telescope |
| telescopes |
| tell |
| telled |
| teller |
| tellin |
| telling |
| tells |
| tellurium |
| teloth |
| temoins |
| temper |
| temperament |
| temperamentally |
| temperate |
| temperature |
| tempered |
| temperment |
| tempers |
| tempest |
| tempests |
| tempestuous |
| temple |
| templed |
| temples |
| templeton |
| tempo |
| tempora |
| temporal |
| temporarily |
| temporary |
| temps |
| tempt |
| temptation |
| temptations |
| tempted |
| ten |
| tenacity |
| tenant |
| tenanted |
| tenantless |
| tenants |
| tend |
| tended |
| tendencies |
| tendency |
| tender |
| tenderest |
| tenderly |
| tenderness |
| tending |
| tendons |
| tendre |
| tendrils |
| tenebrarum |
| tenebris |
| tenebrous |
| tenebrousness |
| tenement |
| tenements |
| tenets |
| tenfold |
| tenor |
| tenour |
| tens |
| tense |
| tension |
| tentacled |
| tentacles |
| tentatively |
| tenth |
| tenths |
| tents |
| tenty |
| tenuity |
| tenuous |
| ter |
| teratologically |
| term |
| termed |
| terminate |
| terminated |
| terminates |
| terminating |
| termination |
| terminer |
| terms |
| terra |
| terrace |
| terraced |
| terraces |
| terrae |
| terrain |
| terraqueous |
| terrestrial |
| terrible |
| terribly |
| terrific |
| terrifically |
| terrified |
| terrifiedly |
| terrify |
| terrifying |
| territories |
| territory |
| terror |
| terrorists |
| terrors |
| tertiary |
| tertullian |
| tessellated |
| test |
| testamentary |
| testator |
| tested |
| testified |
| testify |
| testifying |
| testimonies |
| testimony |
| tests |
| tete |
| tethered |
| teufel |
| teuffel |
| tew |
| text |
| textor |
| texts |
| texture |
| th |
| thalarion |
| thames |
| than |
| thank |
| thanked |
| thankful |
| thankfully |
| thankfulness |
| thankless |
| thanks |
| thanksgiving |
| thar |
| that |
| thatch |
| thatched |
| thaw |
| thawed |
| the |
| theatre |
| theatres |
| theatrical |
| theatricalism |
| theatrically |
| thee |
| their |
| theirs |
| them |
| theme |
| themes |
| themselves |
| then |
| thence |
| thenceforward |
| theodatus |
| theodore |
| theodoric |
| theodosius |
| theology |
| theophrastus |
| theoretically |
| theories |
| theorist |
| theorize |
| theory |
| theosophical |
| theosophist |
| there |
| thereabouts |
| thereafter |
| thereby |
| therefore |
| therefrom |
| therein |
| thereof |
| thereunto |
| thereupon |
| therewith |
| these |
| theseus |
| thet |
| they |
| thick |
| thickened |
| thicker |
| thickest |
| thicket |
| thickets |
| thickly |
| thickness |
| thief |
| thieves |
| thigh |
| thin |
| thine |
| thing |
| things |
| thingum |
| thingumajig |
| think |
| thinker |
| thinkers |
| thinkin |
| thinking |
| thinks |
| thinly |
| thinned |
| thinner |
| thinnest |
| third |
| thirds |
| thirst |
| thirsted |
| thirsty |
| thirteen |
| thirteenth |
| thirties |
| thirtieth |
| thirty |
| this |
| thither |
| tho |
| thomas |
| thompson |
| thonon |
| thorn |
| thorns |
| thorough |
| thoroughfare |
| thoroughly |
| thoroughness |
| those |
| thou |
| though |
| thought |
| thoughtful |
| thoughtfully |
| thoughtfulness |
| thoughtless |
| thoughtlessly |
| thoughtlessness |
| thoughts |
| thousand |
| thousandfold |
| thousands |
| thousandth |
| thr |
| thraa |
| thrace |
| thran |
| thrashed |
| thrashing |
| thread |
| threaded |
| threading |
| threads |
| threat |
| threatened |
| threatening |
| threateningly |
| threatens |
| threats |
| three |
| threshold |
| thresholds |
| threw |
| thrice |
| thrifty |
| thrill |
| thrilled |
| thrilling |
| thrillingly |
| thrills |
| thro |
| throat |
| throats |
| throb |
| throbbing |
| throbbings |
| throes |
| throne |
| throned |
| throng |
| thronged |
| thronging |
| through |
| throughout |
| throw |
| throwed |
| throwers |
| throwing |
| thrown |
| throws |
| thrush |
| thrust |
| thrusting |
| thud |
| thul |
| thule |
| thumb |
| thump |
| thumped |
| thunder |
| thunderbolt |
| thunderbolts |
| thundering |
| thunderously |
| thunders |
| thunderstorm |
| thunderstorms |
| thunderstricken |
| thunderstruck |
| thurai |
| thurber |
| thursday |
| thus |
| thutty |
| thwart |
| thwarted |
| thy |
| thya |
| thyeste |
| thyme |
| thyself |
| théâtre |
| tiara |
| tiaraed |
| tib |
| tiber |
| tiberius |
| tibia |
| ticket |
| ticking |
| tickings |
| tickle |
| tickled |
| tidal |
| tide |
| tides |
| tidings |
| tie |
| tieck |
| tied |
| tier |
| tierra |
| tiers |
| ties |
| tiger |
| tigers |
| tight |
| tightened |
| tightening |
| tightly |
| tilbury |
| tiled |
| tiles |
| till |
| tillers |
| tillinghast |
| tills |
| tilted |
| tilton |
| tim |
| timber |
| timbers |
| timbre |
| timbreless |
| timbuctoo |
| time |
| timed |
| timeless |
| timely |
| timepiece |
| timers |
| times |
| timid |
| timidity |
| timon |
| timorous |
| tin |
| tinctured |
| ting |
| tinge |
| tinged |
| tinges |
| tingle |
| tingling |
| tink |
| tinkling |
| tinned |
| tinsel |
| tint |
| tinted |
| tintern |
| tints |
| tiny |
| tip |
| tipped |
| tippler |
| tips |
| tiptoed |
| tirade |
| tired |
| tiresome |
| tiré |
| tis |
| tissue |
| tissues |
| titan |
| titanic |
| titans |
| titian |
| titillation |
| title |
| titled |
| titles |
| titter |
| tittered |
| tittering |
| titteringly |
| tiz |
| to |
| toad |
| toast |
| tobacco |
| tobacconist |
| tobey |
| toctor |
| today |
| todder |
| toe |
| toes |
| toga |
| togas |
| together |
| toil |
| toiled |
| toilet |
| toiling |
| toils |
| toilsome |
| token |
| tokens |
| told |
| toledo |
| tolerable |
| tolerably |
| tolerance |
| tolerant |
| tolerated |
| toleration |
| toll |
| tolled |
| tom |
| tomahawk |
| tomb |
| tombs |
| tome |
| tomes |
| tomorrow |
| tompkins |
| toms |
| tonal |
| tone |
| toned |
| tones |
| tong |
| tongue |
| tongued |
| tongues |
| tonight |
| tons |
| too |
| took |
| tool |
| tools |
| toothed |
| toothpick |
| top |
| topic |
| topical |
| topics |
| topmast |
| topmost |
| topography |
| topped |
| toppling |
| tops |
| topsiturviness |
| topsy |
| torch |
| torches |
| torchlight |
| tore |
| torment |
| tormented |
| tormenting |
| tormentor |
| tormentors |
| torments |
| torn |
| tornado |
| torny |
| torpedo |
| torpedoed |
| torpid |
| torpor |
| torrent |
| torrential |
| torrents |
| torso |
| tortoise |
| tortoni |
| tortuous |
| torture |
| tortured |
| torturers |
| tortures |
| torturing |
| toss |
| tossed |
| tossin |
| total |
| totality |
| totally |
| totter |
| tottered |
| tottering |
| tottle |
| totum |
| touch |
| touched |
| touches |
| touching |
| tour |
| tourist |
| tourniquet |
| tous |
| tousand |
| tout |
| tow |
| toward |
| towards |
| towed |
| tower |
| towered |
| towering |
| towers |
| town |
| towns |
| townsfolk |
| township |
| toy |
| toys |
| trace |
| traceable |
| traced |
| tracery |
| traces |
| tracing |
| track |
| tracked |
| tracking |
| tracks |
| tract |
| tractable |
| trade |
| traded |
| trader |
| traders |
| tradin |
| trading |
| tradition |
| traditionally |
| traditions |
| traduced |
| traffic |
| tragedies |
| tragedy |
| tragic |
| tragical |
| trail |
| trailing |
| train |
| trained |
| trainer |
| training |
| trains |
| traipsin |
| trait |
| traitor |
| traits |
| tram |
| trammpled |
| tramp |
| tramping |
| trample |
| trampled |
| trance |
| trances |
| tranquil |
| tranquillity |
| tranquillize |
| tranquilly |
| trans |
| transact |
| transacted |
| transacting |
| transaction |
| transactions |
| transcend |
| transcendant |
| transcended |
| transcendent |
| transcendental |
| transcendentals |
| transcending |
| transcribe |
| transcribed |
| transcript |
| transcripts |
| transfer |
| transference |
| transferred |
| transferring |
| transfigured |
| transfix |
| transfixed |
| transformation |
| transformations |
| transformed |
| transforming |
| transfusion |
| transgress |
| transient |
| transiently |
| transition |
| transitions |
| transitory |
| translate |
| translated |
| translation |
| translations |
| translucency |
| translucent |
| transmigrated |
| transmission |
| transmit |
| transmits |
| transmitted |
| transmitter |
| transmitting |
| transmute |
| transmuted |
| transmutes |
| transom |
| transparency |
| transparent |
| transport |
| transportation |
| transported |
| transpositions |
| transversely |
| traordinary |
| trap |
| trapper |
| trapping |
| trappings |
| traps |
| trash |
| trashiness |
| travel |
| travelled |
| traveller |
| travellers |
| travelling |
| travels |
| traverse |
| traversed |
| traversing |
| travesty |
| tray |
| treacheries |
| treacherous |
| tread |
| treadin |
| treading |
| treads |
| treason |
| treasure |
| treasured |
| treasures |
| treasuries |
| treat |
| treated |
| treating |
| treatise |
| treatises |
| treatment |
| treble |
| trebled |
| tree |
| treeless |
| trees |
| trefoil |
| trellice |
| trellis |
| trellised |
| trelliswork |
| tremaine |
| tremble |
| trembled |
| trembles |
| trembling |
| tremblingly |
| tremendous |
| tremendously |
| tremont |
| tremor |
| tremors |
| tremulous |
| tremulously |
| tremulousness |
| trenched |
| trencher |
| trend |
| trepanning |
| trepidancy |
| trepidation |
| trespassed |
| tressel |
| tressels |
| tresses |
| trever |
| trevor |
| tri |
| trial |
| triangular |
| triangularly |
| tribal |
| tribe |
| tribes |
| tribesmen |
| tribunal |
| tribunaux |
| tribune |
| tributes |
| trice |
| trick |
| trickle |
| trickled |
| trickling |
| tricks |
| trident |
| tried |
| triennial |
| tries |
| trifle |
| trifled |
| trifles |
| trifling |
| trim |
| trimmed |
| trimmings |
| trinculo |
| trinity |
| trink |
| trinket |
| trinkets |
| trinomial |
| trio |
| trip |
| triple |
| triplicate |
| tripods |
| trips |
| tript |
| trist |
| trite |
| tritons |
| triumph |
| triumphal |
| triumphant |
| triumphantly |
| triumphatus |
| triumphed |
| triumphing |
| triumphs |
| trivial |
| triviality |
| trod |
| trodden |
| trois |
| troisiême |
| trolleys |
| troof |
| troop |
| troopers |
| troops |
| trophies |
| tropical |
| tropics |
| trot |
| trotted |
| trotter |
| trouble |
| troubled |
| troubles |
| troublesome |
| trough |
| trout |
| trove |
| trowel |
| truant |
| trubble |
| truce |
| truck |
| truckmen |
| trucks |
| true |
| truer |
| truest |
| truffe |
| truism |
| truly |
| trump |
| trumpet |
| trumpets |
| trunk |
| trunks |
| trust |
| trusted |
| trusting |
| trustworthy |
| truth |
| truths |
| try |
| tryin |
| trying |
| ts |
| tsan |
| tu |
| tub |
| tubber |
| tube |
| tubes |
| tucked |
| tuckermann |
| tudor |
| tuesday |
| tuh |
| tuition |
| tuk |
| tulane |
| tulip |
| tulipiferum |
| tulips |
| tumble |
| tumbled |
| tumbledown |
| tumblers |
| tumbling |
| tumuli |
| tumult |
| tumults |
| tumultuous |
| tumultuously |
| tune |
| tuned |
| tunes |
| tunic |
| tunnel |
| tunnels |
| tunéd |
| turbaned |
| turbanless |
| turbans |
| turbar |
| turbid |
| turbulence |
| turbulent |
| turf |
| turgot |
| turk |
| turkey |
| turkish |
| turks |
| turmoil |
| turn |
| turned |
| turning |
| turnip |
| turns |
| turret |
| turrets |
| turrible |
| turtle |
| turvy |
| tutelage |
| tutored |
| tutta |
| tutto |
| twan |
| twas |
| twattle |
| twelfth |
| twelve |
| twelvemonth |
| twenties |
| twentieth |
| twenty |
| twice |
| twig |
| twigs |
| twilight |
| twilights |
| twin |
| twined |
| twinge |
| twining |
| twinkled |
| twinkling |
| twins |
| twirl |
| twirling |
| twist |
| twisted |
| twisting |
| twistings |
| twists |
| twitched |
| twitching |
| two |
| twofold |
| twoness |
| twos |
| tx |
| txld |
| tyché |
| tyger |
| type |
| types |
| typhoid |
| typhus |
| typical |
| typified |
| typifies |
| typographical |
| typography |
| tyrannical |
| tyrannizing |
| tyranny |
| tyrant |
| tyrants |
| tyro |
| tête |
| ud |
| ugh |
| ugliness |
| ugly |
| ulster |
| ulswater |
| ulthar |
| ultima |
| ultimate |
| ultimately |
| ultimatum |
| ultra |
| ultramarine |
| ultras |
| ululation |
| ululations |
| ulysses |
| umbrageous |
| un |
| una |
| unabated |
| unable |
| unaccommodating |
| unaccountable |
| unaccountably |
| unaccounted |
| unaccustomed |
| unacquainted |
| unacted |
| unadapted |
| unadept |
| unadepts |
| unaffected |
| unaided |
| unalienable |
| unalloyed |
| unalterable |
| unaltered |
| unamazed |
| unanimity |
| unanimous |
| unanimously |
| unannounced |
| unanswerability |
| unanswerable |
| unanticipated |
| unappeasable |
| unarmed |
| unassailable |
| unassassinated |
| unassisted |
| unassuming |
| unattainable |
| unattended |
| unatteneded |
| unaussprechlichen |
| unavailing |
| unavoidable |
| unaware |
| unawares |
| unbalanced |
| unbearable |
| unbecoming |
| unbefriended |
| unbeheld |
| unbelief |
| unbelievable |
| unbending |
| unbent |
| unbetrayed |
| unbidden |
| unbitted |
| unblamed |
| unbodied |
| unbonneted |
| unborn |
| unborrow |
| unbound |
| unbounded |
| unbreathing |
| unbridled |
| unbroken |
| unbrokenly |
| unburied |
| unburthen |
| uncalculating |
| uncannily |
| uncanny |
| uncarpeted |
| uncased |
| unceasing |
| unceasingly |
| uncertain |
| uncertainly |
| uncertainty |
| uncertitude |
| unchained |
| unchallenged |
| unchangeable |
| unchanged |
| unchecked |
| uncials |
| unclassified |
| uncle |
| unclean |
| uncleared |
| uncles |
| unclosed |
| unclosing |
| unclothed |
| unclouded |
| uncomfortable |
| uncomfortably |
| uncommon |
| uncommonly |
| uncommunicable |
| uncommunicative |
| uncomplaining |
| uncompromising |
| uncongenial |
| unconnected |
| unconscious |
| unconsciously |
| unconsciousness |
| uncontrollable |
| unconvinced |
| unconvulsive |
| uncorporeal |
| uncounted |
| uncourteously |
| uncouth |
| uncovered |
| uncovering |
| unction |
| uncultivated |
| uncultured |
| uncurl |
| und |
| undamaged |
| undammed |
| undauntedly |
| undecayed |
| undeceive |
| undecipherable |
| undefiled |
| undefinable |
| undefined |
| undeniable |
| undeniably |
| under |
| underbrush |
| undercurrent |
| underduk |
| underfoot |
| undergo |
| undergoing |
| undergone |
| undergraduate |
| underground |
| undergrowth |
| underlined |
| underlings |
| underlining |
| undermine |
| undermined |
| underneath |
| undersea |
| undersized |
| understand |
| understanding |
| understandings |
| understood |
| undertake |
| undertaken |
| undertaker |
| undertakers |
| undertaking |
| undertakings |
| undertook |
| undervalue |
| undervalued |
| underwent |
| underwood |
| underworld |
| undesirable |
| undesiring |
| undestroyed |
| undetermined |
| undeveloped |
| undeviating |
| undid |
| undignified |
| undimensioned |
| undiminished |
| undiscovered |
| undisturbed |
| undivided |
| undoing |
| undoubted |
| undoubtedly |
| undreamable |
| undress |
| undue |
| undulant |
| undulantly |
| undulated |
| undulating |
| undulation |
| undulations |
| unduly |
| undying |
| unearth |
| unearthed |
| unearthing |
| unearthly |
| uneasily |
| uneasiness |
| uneasy |
| uneclipsed |
| uneducated |
| unembalmed |
| unemployed |
| unending |
| unendurable |
| unequal |
| unequivocal |
| unequivocally |
| uneradicated |
| uneraseable |
| unerring |
| uneven |
| unevenly |
| unexampled |
| unexpected |
| unexpectedly |
| unexplainable |
| unexplained |
| unexplored |
| unexposed |
| unextinguishable |
| unfading |
| unfailing |
| unfair |
| unfaithful |
| unfalteringly |
| unfamiliar |
| unfashioned |
| unfasten |
| unfastened |
| unfathomable |
| unfathomed |
| unfavourable |
| unfavourably |
| unfeeling |
| unfelt |
| unfinished |
| unfit |
| unfitness |
| unfitted |
| unflinching |
| unfold |
| unfolded |
| unforeseeing |
| unforeseen |
| unforested |
| unforgotten |
| unformed |
| unfortified |
| unfortunate |
| unfortunately |
| unfrequently |
| unfriended |
| unfruitful |
| unfulfilled |
| ungenteel |
| ungentlemanly |
| ungovernable |
| ungoverned |
| ungracious |
| ungrateful |
| ungratefully |
| ungratitude |
| ungreeted |
| unguarded |
| unguessed |
| unguided |
| unhallowed |
| unhand |
| unhappily |
| unhappiness |
| unhappy |
| unharmed |
| unhealthful |
| unhealthy |
| unheard |
| unheeded |
| unheralded |
| unhesitatingly |
| unhewn |
| unhinged |
| unholy |
| unhonoured |
| unhurried |
| unidentifiable |
| unidentified |
| uniform |
| uniformity |
| uniformly |
| unimaginable |
| unimaginative |
| unimagined |
| unimpeded |
| unimportant |
| unimpressive |
| unimproved |
| unincorporate |
| uninfected |
| uninformed |
| uninjured |
| uninquiring |
| uninscribable |
| unintelligent |
| unintelligible |
| uninterested |
| uninterrupted |
| uninterruptedly |
| union |
| unique |
| uniquity |
| unison |
| unit |
| unite |
| united |
| unites |
| uniting |
| unity |
| univarsal |
| universal |
| universally |
| universe |
| universes |
| university |
| unjust |
| unjustly |
| unkempt |
| unkemptness |
| unkind |
| unkindness |
| unknowing |
| unknown |
| unlaid |
| unlamented |
| unlawful |
| unlearned |
| unleashed |
| unless |
| unlettered |
| unlife |
| unlighted |
| unlike |
| unlimited |
| unlined |
| unlit |
| unlock |
| unlocked |
| unlocking |
| unlocks |
| unlooked |
| unloosened |
| unloved |
| unloveliness |
| unlucky |
| unmade |
| unman |
| unmanageable |
| unmanned |
| unmask |
| unmeaning |
| unmeasured |
| unmelodious |
| unmentionable |
| unmentioned |
| unmingled |
| unmistakable |
| unmistakably |
| unmitigated |
| unmixed |
| unmorality |
| unmotivated |
| unmoulded |
| unmourned |
| unmoved |
| unmoving |
| unmuzzled |
| unnamable |
| unnamed |
| unnatural |
| unnaturally |
| unnecessarily |
| unnecessary |
| unnerve |
| unnerved |
| unnerving |
| unnoticed |
| unnumbered |
| unobserved |
| unoccupied |
| unopened |
| unopposed |
| unorganized |
| unostentatious |
| unpacked |
| unpaid |
| unpainted |
| unparalleled |
| unpardonable |
| unparticipated |
| unparticled |
| unpaved |
| unpayable |
| unpeopled |
| unperceived |
| unperturbed |
| unphilosophical |
| unplaceable |
| unplaced |
| unplastered |
| unpleasant |
| unpleasantly |
| unpleasing |
| unplumbed |
| unpolluted |
| unpopular |
| unpossessed |
| unpractised |
| unprecedented |
| unprejudiced |
| unprepared |
| unpretending |
| unproductive |
| unpronounceable |
| unprotected |
| unqualified |
| unquenchable |
| unquenched |
| unquenshable |
| unquestionable |
| unquestionably |
| unquiet |
| unravel |
| unravelled |
| unreal |
| unreality |
| unreaped |
| unreason |
| unreasonable |
| unreasonably |
| unreasoning |
| unrecognisable |
| unrecognised |
| unrecognized |
| unredressed |
| unrefreshed |
| unrefreshing |
| unrelated |
| unrelaxed |
| unrelenting |
| unrelieved |
| unremembered |
| unremitting |
| unremittingly |
| unrepining |
| unreproved |
| unrequited |
| unreserved |
| unreservedly |
| unresisting |
| unresistingly |
| unresponsive |
| unrest |
| unrestrained |
| unrigged |
| unrivalled |
| unrolled |
| unrounded |
| unsafe |
| unsanctified |
| unsanctioned |
| unsanitary |
| unsatisfactory |
| unsatisfied |
| unsatisfying |
| unscaleable |
| unscrew |
| unscrewed |
| unscrupulous |
| unsearchableness |
| unseasonable |
| unseasonably |
| unseeing |
| unseemly |
| unseen |
| unselfish |
| unsettled |
| unshackled |
| unshaken |
| unshared |
| unsheathing |
| unshod |
| unsightly |
| unskilled |
| unsocial |
| unsoftened |
| unsolved |
| unsought |
| unspeakable |
| unspeakably |
| unspotted |
| unstable |
| unstained |
| unsteady |
| unstrung |
| unstung |
| unsubdued |
| unsuccessful |
| unsupported |
| unsurpassed |
| unsuspected |
| unt |
| untainted |
| untameable |
| untamed |
| untaught |
| untenable |
| untenanted |
| untended |
| unthinkable |
| unthinking |
| unthought |
| until |
| untill |
| untimed |
| untimely |
| untinged |
| untired |
| untiring |
| unto |
| untold |
| untouched |
| untoward |
| untraceable |
| untraditional |
| untraversed |
| untried |
| untrod |
| untrodden |
| untrue |
| untutored |
| untyed |
| unus |
| unused |
| unusual |
| unusually |
| unusualness |
| unutterable |
| unutterably |
| unvaried |
| unvarying |
| unveil |
| unveiled |
| unversed |
| unvisitable |
| unvisited |
| unwarranted |
| unwearied |
| unwelcome |
| unwhisperable |
| unwholesome |
| unwholesomely |
| unwieldy |
| unwilling |
| unwillingly |
| unwillingness |
| unwind |
| unwinking |
| unwisely |
| unwithheld |
| unwittingly |
| unwomanly |
| unwonted |
| unworthy |
| unwound |
| unwrap |
| unwrapping |
| unwrinkled |
| unwrought |
| unyielding |
| up |
| upbraid |
| updike |
| upham |
| upharsin |
| upheaval |
| upheaving |
| upholsterer |
| upholstery |
| upland |
| uplands |
| uplift |
| uplifted |
| uplifting |
| upon |
| upper |
| uppermost |
| upraise |
| uprearing |
| upright |
| uprising |
| uproar |
| uprooted |
| uprooting |
| uprose |
| upset |
| upside |
| upspringing |
| upstairs |
| upstart |
| upstream |
| upturned |
| upward |
| upwardly |
| upwards |
| urania |
| urban |
| urchin |
| urge |
| urged |
| urgency |
| urgent |
| urges |
| urging |
| urion |
| urn |
| urns |
| us |
| usage |
| usages |
| usbande |
| use |
| used |
| useful |
| usefulness |
| useless |
| uselessly |
| uselessness |
| users |
| uses |
| usher |
| ushered |
| ushers |
| using |
| uster |
| usual |
| usually |
| usurpation |
| usurped |
| usury |
| ut |
| utensils |
| utica |
| utilise |
| utilising |
| utilitarian |
| utilitarians |
| utility |
| utmost |
| utter |
| utterance |
| utterances |
| uttered |
| uttering |
| utterly |
| uttermost |
| utters |
| vacancy |
| vacant |
| vacantly |
| vacated |
| vacation |
| vacations |
| vacillated |
| vacillating |
| vacillation |
| vacua |
| vacuity |
| vacuous |
| vacuum |
| vad |
| vagabond |
| vagabonds |
| vagaries |
| vagary |
| vagrants |
| vague |
| vaguely |
| vagueness |
| vaguenesses |
| vaguer |
| vaguest |
| vail |
| vailed |
| vain |
| vainly |
| valdemar |
| vale |
| valence |
| valens |
| valentinianus |
| valerius |
| valet |
| valetudinarian |
| valiant |
| valiantly |
| valid |
| validity |
| valise |
| valley |
| valleys |
| vallies |
| valor |
| valour |
| valuable |
| valuables |
| value |
| valued |
| valueless |
| values |
| valve |
| vampire |
| van |
| vanes |
| vanilla |
| vanish |
| vanished |
| vanishes |
| vanishing |
| vanities |
| vanity |
| vankirk |
| vanny |
| vanquished |
| vantage |
| vaow |
| vapor |
| vaporous |
| vapors |
| vapory |
| vapour |
| vapours |
| variable |
| variance |
| variation |
| variations |
| varied |
| variegate |
| variegated |
| varieties |
| variety |
| various |
| variously |
| varius |
| variétés |
| varnish |
| varnished |
| vary |
| varying |
| vascones |
| vase |
| vases |
| vassal |
| vassals |
| vast |
| vaster |
| vastly |
| vastness |
| vat |
| vathek |
| vaucanson |
| vault |
| vaulted |
| vaulting |
| vaultings |
| vaults |
| vd |
| ve |
| veal |
| veer |
| veered |
| vega |
| vegetable |
| vegetables |
| vegetation |
| vehemence |
| vehemently |
| vehicle |
| vehicles |
| veil |
| veiled |
| veiling |
| veils |
| vein |
| veined |
| veins |
| vell |
| vellum |
| velocities |
| velocity |
| veloute |
| velouté |
| velvet |
| velvety |
| ven |
| venerable |
| venerableness |
| veneration |
| vengeance |
| vengeful |
| venial |
| venice |
| venny |
| venom |
| venomous |
| vent |
| venter |
| venters |
| ventilation |
| venting |
| ventricle |
| ventur |
| venture |
| ventured |
| ventures |
| venturesome |
| venturing |
| venus |
| ver |
| verandas |
| verbal |
| verbatim |
| verborum |
| verbose |
| verdant |
| verde |
| verdict |
| verdigris |
| verdure |
| verdured |
| verdurous |
| verge |
| verhaeren |
| veriest |
| verified |
| verily |
| veritable |
| veritably |
| vermicular |
| verminous |
| vernal |
| verney |
| vernunft |
| versatile |
| verse |
| versed |
| verses |
| versified |
| version |
| versions |
| vertical |
| vertically |
| vertiginous |
| vertu |
| verulam |
| verus |
| ververt |
| very |
| vessel |
| vessels |
| vest |
| vestibule |
| vestige |
| vestiges |
| vestigial |
| vesture |
| veterans |
| vetus |
| veulent |
| vex |
| vexation |
| vexations |
| vexed |
| vext |
| vi |
| via |
| viab |
| vial |
| viand |
| vibrated |
| vibrates |
| vibration |
| vibrations |
| vibratory |
| vibulanus |
| vicar |
| vice |
| vicegerents |
| vices |
| vicinity |
| vicious |
| viciously |
| viciousness |
| vicissitudes |
| victim |
| victims |
| victor |
| victoria |
| victorian |
| victories |
| victorious |
| victoriously |
| victory |
| vidocq |
| vie |
| vienna |
| view |
| viewed |
| viewing |
| viewless |
| views |
| vigil |
| vigilance |
| vigilant |
| vigiliae |
| vignetting |
| vigor |
| vigorous |
| vigorously |
| vigour |
| vii |
| viii |
| vile |
| vilest |
| vill |
| villa |
| village |
| villager |
| villagers |
| villages |
| villain |
| villainous |
| villains |
| villanous |
| villany |
| villas |
| vindictive |
| vindictiveness |
| vine |
| vines |
| vineyards |
| vingt |
| vini |
| vinous |
| vintage |
| vintages |
| viol |
| violate |
| violated |
| violating |
| violation |
| violations |
| violence |
| violent |
| violently |
| violet |
| violets |
| vipers |
| virgil |
| virgin |
| virginia |
| virtu |
| virtual |
| virtually |
| virtue |
| virtues |
| virtuosi |
| virtuous |
| virulence |
| virulent |
| vis |
| visage |
| visaged |
| visages |
| viscount |
| viscous |
| vise |
| visibility |
| visible |
| visibly |
| vision |
| visionaries |
| visionary |
| visions |
| visit |
| visitant |
| visitarem |
| visitation |
| visitations |
| visited |
| visiter |
| visiting |
| visitor |
| visitors |
| visits |
| viso |
| vista |
| vistas |
| visual |
| visualised |
| visually |
| vital |
| vitality |
| vitally |
| vitals |
| vitiges |
| vivacious |
| vivacity |
| vivat |
| vivid |
| vividly |
| vividness |
| vivified |
| vivifying |
| viz |
| vocal |
| vocation |
| vociferated |
| voice |
| voiced |
| voiceless |
| voices |
| void |
| voids |
| voilà |
| voissart |
| volcanic |
| volcanically |
| volcano |
| volcanoes |
| volition |
| volney |
| volubility |
| voluble |
| volume |
| volumes |
| voluminous |
| voluminously |
| voluntarily |
| voluntary |
| voluptuous |
| voluptuousness |
| von |
| vondervotteimittis |
| vondervotteimittiss |
| voodoo |
| voodooism |
| vool |
| voorish |
| vor |
| voracity |
| vord |
| vortex |
| vortices |
| votaries |
| vouch |
| vouchsafed |
| vougeot |
| vous |
| vow |
| vowed |
| vowel |
| vowing |
| vows |
| voyage |
| voyaged |
| voyager |
| voyages |
| vrai |
| vrows |
| vulgar |
| vulgarly |
| vull |
| vulnerable |
| vulture |
| vultures |
| vulturine |
| vurrgh |
| vy |
| wa |
| waddle |
| waddled |
| wade |
| wafers |
| wafted |
| wage |
| wager |
| wagged |
| waggeries |
| waggons |
| waging |
| wagon |
| wagons |
| wags |
| waif |
| wailing |
| wailings |
| wain |
| wainscots |
| waist |
| waistband |
| waistcoat |
| wait |
| waite |
| waited |
| waiters |
| waiting |
| waits |
| wake |
| waked |
| wakefield |
| wakeful |
| waken |
| wakened |
| waker |
| waking |
| wal |
| walakea |
| waldman |
| wales |
| walk |
| walked |
| walker |
| walking |
| walks |
| wall |
| wallace |
| wallachia |
| walled |
| wallenstein |
| wallet |
| walls |
| walnut |
| walnuts |
| walter |
| walton |
| waltzers |
| wan |
| wand |
| wander |
| wandered |
| wanderer |
| wanderers |
| wandering |
| wanderings |
| wanders |
| wane |
| waned |
| waning |
| wanly |
| wanness |
| want |
| wanted |
| wantin |
| wanting |
| wanton |
| wantonness |
| wants |
| war |
| warbling |
| ward |
| wards |
| ware |
| warehouse |
| warehouses |
| wares |
| warfare |
| warlike |
| warm |
| warmed |
| warmer |
| warmest |
| warming |
| warmly |
| warmth |
| warn |
| warned |
| warning |
| warnings |
| warrant |
| warranted |
| warren |
| warrens |
| warring |
| warrior |
| warriors |
| wars |
| warship |
| warton |
| wary |
| was |
| washed |
| washington |
| waste |
| wasted |
| wasteful |
| wasting |
| watch |
| watchdog |
| watched |
| watcher |
| watchers |
| watches |
| watchful |
| watchfulness |
| watching |
| watchman |
| watchword |
| water |
| watercolor |
| watered |
| waterfall |
| waterfalls |
| waterfront |
| waterfronts |
| watering |
| waterline |
| waterman |
| waters |
| watery |
| watson |
| wave |
| waved |
| waveless |
| waver |
| wavering |
| waves |
| waving |
| wax |
| waxed |
| waxen |
| waxes |
| way |
| wayfarer |
| wayfarers |
| waylaid |
| waylayings |
| ways |
| wayward |
| waywardness |
| wd |
| we |
| weak |
| weaken |
| weakened |
| weakening |
| weaker |
| weakling |
| weakness |
| wealth |
| wealthier |
| wealthiest |
| wealthy |
| wean |
| weaned |
| weapon |
| weapons |
| wear |
| wearer |
| wearers |
| wearied |
| wearily |
| wearin |
| weariness |
| wearing |
| wearisomeness |
| wears |
| weary |
| wearying |
| weasel |
| weather |
| weathered |
| weathering |
| weave |
| weaves |
| weaving |
| web |
| webb |
| webbed |
| webs |
| wedded |
| weddin |
| wedding |
| wedge |
| wedged |
| wedging |
| wednesday |
| weed |
| weeds |
| weedy |
| week |
| weekdays |
| weekly |
| weeks |
| weep |
| weeping |
| weeps |
| weigh |
| weighed |
| weighing |
| weight |
| weights |
| weighty |
| weilburg |
| weird |
| weirdly |
| weirdness |
| welcome |
| welcomed |
| welcoming |
| welded |
| welfare |
| well |
| welled |
| wells |
| weltering |
| welts |
| went |
| wept |
| were |
| wert |
| werter |
| wery |
| west |
| westering |
| western |
| westerner |
| westernmost |
| westminster |
| westmorland |
| westward |
| westwardly |
| wet |
| wgah |
| whaddya |
| whale |
| whaler |
| whales |
| whang |
| whar |
| wharf |
| wharves |
| what |
| whateley |
| whateleys |
| whatever |
| whatsoever |
| wheat |
| wheaton |
| wheel |
| wheeled |
| wheeler |
| wheeling |
| wheels |
| wheezing |
| whelms |
| when |
| whence |
| whenever |
| where |
| whereabouts |
| whereas |
| whereat |
| whereby |
| wherefore |
| wherefrom |
| wherein |
| whereof |
| whereon |
| whereto |
| whereunto |
| whereupon |
| wherever |
| wherewith |
| whether |
| which |
| whichever |
| whiff |
| whiffs |
| while |
| whiled |
| whilst |
| whim |
| whimper |
| whimpered |
| whimpering |
| whimpers |
| whims |
| whimsical |
| whimsicalities |
| whimsically |
| whine |
| whined |
| whining |
| whinnied |
| whip |
| whipped |
| whipping |
| whipple |
| whippoorwills |
| whir |
| whirl |
| whirled |
| whirling |
| whirlpool |
| whirlpools |
| whirlwind |
| whirring |
| whiskers |
| whiskey |
| whisper |
| whispered |
| whisperer |
| whispering |
| whisperingly |
| whispers |
| whist |
| whistle |
| whistled |
| whit |
| white |
| whitely |
| whitened |
| whiteness |
| whites |
| whitewashed |
| whither |
| whiting |
| whitish |
| whitman |
| whizz |
| who |
| whoever |
| whole |
| wholesale |
| wholesome |
| wholly |
| whom |
| whomsoever |
| whoop |
| whooping |
| whose |
| why |
| wick |
| wicked |
| wickedness |
| wicker |
| wid |
| widdy |
| wide |
| widely |
| widened |
| widener |
| widening |
| wider |
| widespread |
| widest |
| widow |
| widowed |
| widower |
| width |
| wield |
| wielded |
| wields |
| wife |
| wifeless |
| wig |
| wiggins |
| wilbur |
| wilcox |
| wild |
| wilder |
| wilderness |
| wildest |
| wildly |
| wildness |
| wilds |
| wilful |
| wilhelm |
| wilily |
| wilkie |
| wilkins |
| will |
| william |
| williams |
| williamson |
| willing |
| willingly |
| willow |
| willows |
| willowy |
| wills |
| willy |
| wilson |
| wilt |
| wimble |
| win |
| wind |
| windborne |
| windenough |
| windham |
| winding |
| windings |
| windlass |
| windless |
| windmill |
| window |
| windowless |
| windowlessly |
| windows |
| winds |
| windsor |
| windward |
| wine |
| wines |
| wing |
| winged |
| wings |
| wink |
| winked |
| winking |
| winks |
| winning |
| wins |
| winter |
| winters |
| wintry |
| wipe |
| wiped |
| wipin |
| wiping |
| wire |
| wireless |
| wires |
| wisconsin |
| wisdom |
| wise |
| wisely |
| wiser |
| wisest |
| wish |
| wished |
| wishes |
| wishing |
| wisp |
| wisps |
| wistful |
| wistfully |
| wit |
| witch |
| witchcraft |
| witches |
| with |
| withal |
| withaout |
| withdraw |
| withdrawal |
| withdrawing |
| withdrawn |
| withdrew |
| wither |
| withered |
| withering |
| withers |
| withheld |
| withhold |
| within |
| without |
| withstand |
| witness |
| witnessed |
| witnesses |
| witnessing |
| wits |
| witty |
| wives |
| wizard |
| wizardry |
| wizards |
| wizened |
| wo |
| woe |
| woeful |
| woes |
| woke |
| wolejko |
| wolf |
| wolfish |
| wolves |
| woman |
| womanhood |
| womanish |
| womb |
| women |
| womenfolk |
| womenfolks |
| won |
| wonder |
| wondered |
| wonderful |
| wonderfully |
| wonderin |
| wondering |
| wonderingly |
| wonders |
| wondrous |
| wonted |
| wood |
| wooded |
| wooden |
| woodland |
| woods |
| woodville |
| woodwork |
| woof |
| wooing |
| wool |
| woollen |
| woolwich |
| word |
| wordless |
| wordlessly |
| words |
| wordsworth |
| wordy |
| wore |
| work |
| worked |
| worker |
| working |
| workings |
| workman |
| workmanship |
| workmen |
| works |
| world |
| worldly |
| worlds |
| worm |
| wormed |
| wormius |
| worms |
| wormy |
| worn |
| worried |
| worry |
| worrying |
| worse |
| worship |
| worshiped |
| worshiper |
| worshipped |
| worshippers |
| worshipping |
| worst |
| worsted |
| worth |
| worthier |
| worthies |
| worthiest |
| worthily |
| worthless |
| worthlessness |
| worthy |
| would |
| wouldst |
| wound |
| wounded |
| wounds |
| wove |
| woven |
| wow |
| wraith |
| wraiths |
| wrap |
| wrapped |
| wrapper |
| wrapping |
| wrapt |
| wrath |
| wreak |
| wreaked |
| wreaking |
| wreath |
| wreathed |
| wreaths |
| wreck |
| wreckage |
| wrecked |
| wreckers |
| wrench |
| wrenched |
| wrested |
| wrestled |
| wretch |
| wretched |
| wretchedly |
| wretchedness |
| wretches |
| wriggle |
| wriggled |
| wriggling |
| wrings |
| wrinkle |
| wrinkled |
| wrinkles |
| wrist |
| wrists |
| writ |
| write |
| writer |
| writers |
| writes |
| writhe |
| writhed |
| writhing |
| writhings |
| writing |
| writings |
| written |
| wrong |
| wronged |
| wrote |
| wrought |
| wrung |
| wudn |
| wun |
| wust |
| wxn |
| wxw |
| wxxds |
| wyatt |
| xari |
| xdixus |
| xerxes |
| xf |
| xh |
| xii |
| xiith |
| xiv |
| xld |
| xnce |
| xnly |
| xr |
| xut |
| xwl |
| xwns |
| ya |
| yacht |
| yages |
| yahaah |
| yanked |
| yankee |
| yard |
| yards |
| yarn |
| yath |
| yawn |
| yawned |
| yawning |
| yawns |
| yayayayaaaa |
| ye |
| yea |
| year |
| yearn |
| yearned |
| yearning |
| yearnings |
| yearns |
| years |
| yell |
| yelled |
| yeller |
| yelling |
| yellow |
| yellowed |
| yellowish |
| yells |
| yelping |
| yelpings |
| yeoman |
| yer |
| yes |
| yesterday |
| yet |
| yew |
| yews |
| yi |
| yield |
| yielded |
| yielding |
| yields |
| yog |
| yoke |
| yon |
| yonder |
| yore |
| york |
| yorkshire |
| yorktown |
| you |
| young |
| younger |
| youngest |
| youngish |
| younguns |
| your |
| yours |
| yourself |
| yourselves |
| youth |
| youthful |
| youths |
| yule |
| yuletide |
| yxu |
| yxur |
| zadok |
| zaffre |
| zaiat |
| zaimi |
| zaire |
| zann |
| zar |
| zath |
| zay |
| zeal |
| zealand |
| zealous |
| zeb |
| zebulon |
| zechariah |
| zee |
| zenith |
| zenobia |
| zephyr |
| zephyrs |
| zerubbabel |
| zest |
| zette |
| zide |
| zigzag |
| zigzagging |
| zimmer |
| zircon |
| zit |
| zobna |
| zobnarian |
| zodiacal |
| zoilus |
| zokkar |
| zones |
| zorry |
| zubmizzion |
| zuro |
| ædile |
| ægyptus |
| æmilianus |
| æneid |
| ærial |
| æronaut |
| æronauts |
| æschylus |
| émeutes |
| οἶδα |
| υπνος |
Parameters
Fitted attributes
On obtient une précision satisfaisante:
Précision: 0.8429519918283963Les performances décomposées sont les suivantes:
precision recall f1-score support
EAP 0.85 0.85 0.85 1580
HPL 0.87 0.82 0.84 1127
MWS 0.81 0.86 0.83 1209
accuracy 0.84 3916
macro avg 0.84 0.84 0.84 3916
weighted avg 0.84 0.84 0.84 3916
Sans surprise, on obtient bien la prédiction de Mary Shelley:
np.str_('MWS')Finalement, si on regarde les probabilités estimées (question 5), on se rend compte que la prédiction est très certaine:
| author | proba | |
|---|---|---|
| 0 | EAP | 0.001675 |
| 1 | HPL | 0.084844 |
| 2 | MWS | 0.913481 |
AstuceComprendre la logique du classifieur naif de Bayes
Supposons que nous sommes dans un problème de classification avec des classes $(c_1,…,c_K) (ensemble noté \(\mathcal{C}\)). Nous plaçant dans le cadre de pensée du sac de mot, nous pouvons ne pas nous préoccuper des positions des mots dans les documents, qui complexifieraient beaucoup l’écriture de nos équations.
L’équation Équation 3.2 peut être réécrite
\[ \widehat{c} = \arg \max_{c \in \mathcal{C}} \mathbb{P}(w_1, ..., w_n|c)\mathbb{P}(c) \]
Dans le monde bayésien, on nomme \(\mathbb{P}(w_1, ..., w_n|c)\) la vraisemblance (likelihood) et \(\mathbb{P}(c)\) l’a priori (prior).
L’hypothèse Bayes naive permet de traiter un document comme une suite de tirages aléatoires dont les probabilités ne dépendent que de la catégorie. Dans ce cas, le tirage d’une phrase est une suite de tirages de mots et la probabilité composée est donc
\[ \mathbb{P}(w_1, ..., w_n|c) = \prod_{i=1}^n \mathbb{P}(w_i|c) \]
Par exemple, en simplifiant en deux classes, si les probabilités sont celles du Table 3.1, la phrase “afraid by Doctor Frankenstein” aura un peu moins de 1% de chance (0.8%) d’être écrite si l’autrice est Mary Shelley mais sera encore moins vraisemblable chez Lovecraft (0.006%) car si “afraid” est très probable chez lui, Frankenstein est un événement rare qui rend peu vraisemblable cette composition de mots.
| Mot (\(w_i\)) | Probabilité chez Mary Shelley | Probabilité chez Lovecraft |
|---|---|---|
| Afraid | 0.1 | 0.6 |
| By | 0.2 | 0.2 |
| Doctor | 0.2 | 0.05 |
| Frankenstein | 0.2 | 0.01 |
En composant ces différentes équations, on obtient
\[ \widehat{c} = \arg \max_{c \in \mathcal{C}} \mathbb{P}(c)\prod_{w \in \mathcal{W}}{\mathbb{P}(w|c)} \]
La contrepartie empirique de \(\mathbb{P}(c)\) est assez évidente: la fréquence observée de chaque catégorie (les auteurs) dans notre corpus. Autrement dit,
\[ \widehat{\mathbb{P}(c)} = \frac{n_c}{n_{doc}} \]
Quelle est la contrepartie empirique de \(\mathbb{P}(w_i|c)\) ? C’est la fréquence d’apparition du mot en question chez l’auteur. Pour le calculer, il suffit de compter le nombre de fois qu’il apparaît chez l’auteur et de diviser par le nombre de mots de l’auteur.
4 Le modèle Word2Vec, une représentation plus synthétique
4.1 Vers une représentation plus synthétique du langage
La représentation vectorielle issue de l’approche bag of words n’est pas très synthétique ni stable et surtout est assez frustre.
Si on a un petit corpus, on va avoir des problèmes à extrapoler puisque de nouveaux textes ont toutes les chances d’apporter de nouveaux mots, qui sont de nouvelles dimensions de features qui n’étaient pas présentes dans le corpus d’entraînement, ce qui conceptuellement est un problème puisque les algorithmes de machine learning n’ont pas vocation à prédire sur des caractéristiques sur lesquelles ils n’ont pas été entraîné1.
A l’inverse, plus on a de texte dans un corpus, plus notre représentation vectorielle sera importante. Par exemple, si votre sac de mot a vu tout le vocabulaire français, soit 60 000 mots selon l’Académie Française (les estimations étant de 200 000 pour la langue anglaise), cela fait des vecteurs de taille conséquente. Cependant, la diversité des textes est, en pratique, bien moindre: l’usage courant du Français nécessite plutôt autour de 3000 mots et la plupart des textes, notamment s’ils sont courts, n’utilisent pas un vocabulaire si complet. Ceci implique donc des vecteurs très peu denses, avec beaucoup de 0.
La vectorisation selon cette approche est donc peu efficace; le signal est peu compressé. Des représentations denses, c’est-à-dire de dimension plus faible mais portant toutes une information, semblent plus adéquate pour pouvoir généraliser notre modélisation du langage.
L’algorithme qui a rendu célèbre cette approche est le modèle Word2Vec, en quelques sortes le premier ancêtre commun des LLM modernes. La représentation vectorielle de Word2Vec est assez synthétique: la dimension de ces embeddings est entre 100 et 300.
4.2 Des relations sémantique entre les termes
Cette représentation dense va représenter une solution à une limite de l’approche bag of words que nous avons évoquée à de multiples reprises. Chacune de ces dimensions va représenter un facteur latent, c’est à dire une variable inobservée, de la même manière que les composantes principales produites par une ACP. Ces dimensions latentes peuvent être interprétées comme des dimensions “fondamentales” du langage
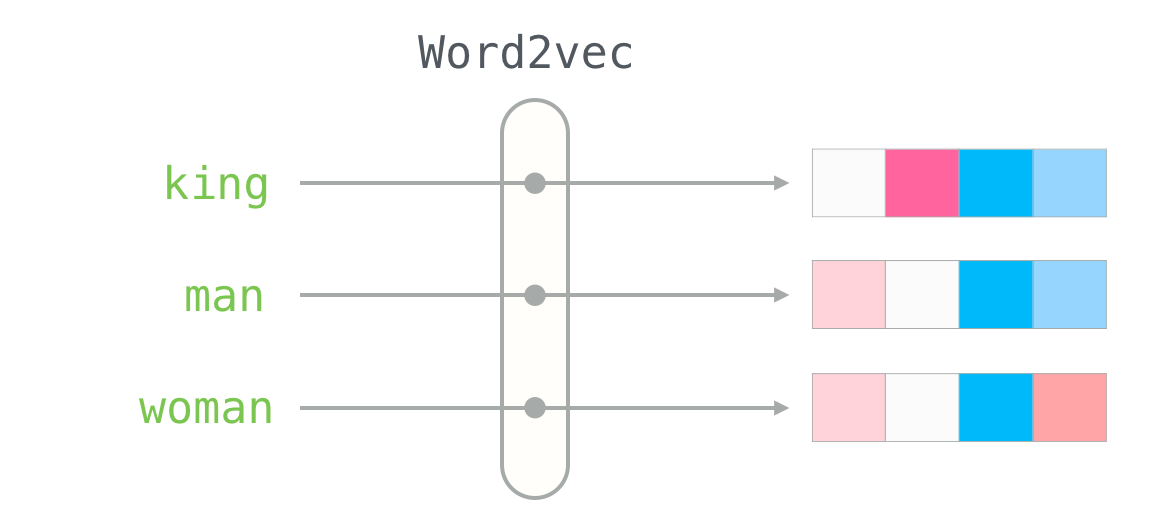
Par exemple, un humain sait qu’un document contenant le mot “Roi”
et un autre document contenant le mot “Reine” ont beaucoup de chance
d’aborder des sujets semblables. Un modèle Word2Vec bien entraîné va capter
qu’il existe un facteur latent de type “royauté”
et la similarité entre les vecteurs associés aux deux mots sera forte.
La magie va même plus loin : le modèle captera aussi qu’il existe un facteur latent de type “genre”, et va permettre de construire un espace sémantique dans lequel les relations arithmétiques entre vecteurs ont du sens. Par exemple,
\[ \text{king} - \text{man} + \text{woman} ≈ \text{queen} \]
ou, pour reprendre, l’exemple issu du papier originel Word2Vec (Mikolov 2013),
\[ \text{Paris} - \text{France} + \text{Italy} ≈ \text{Rome} \]
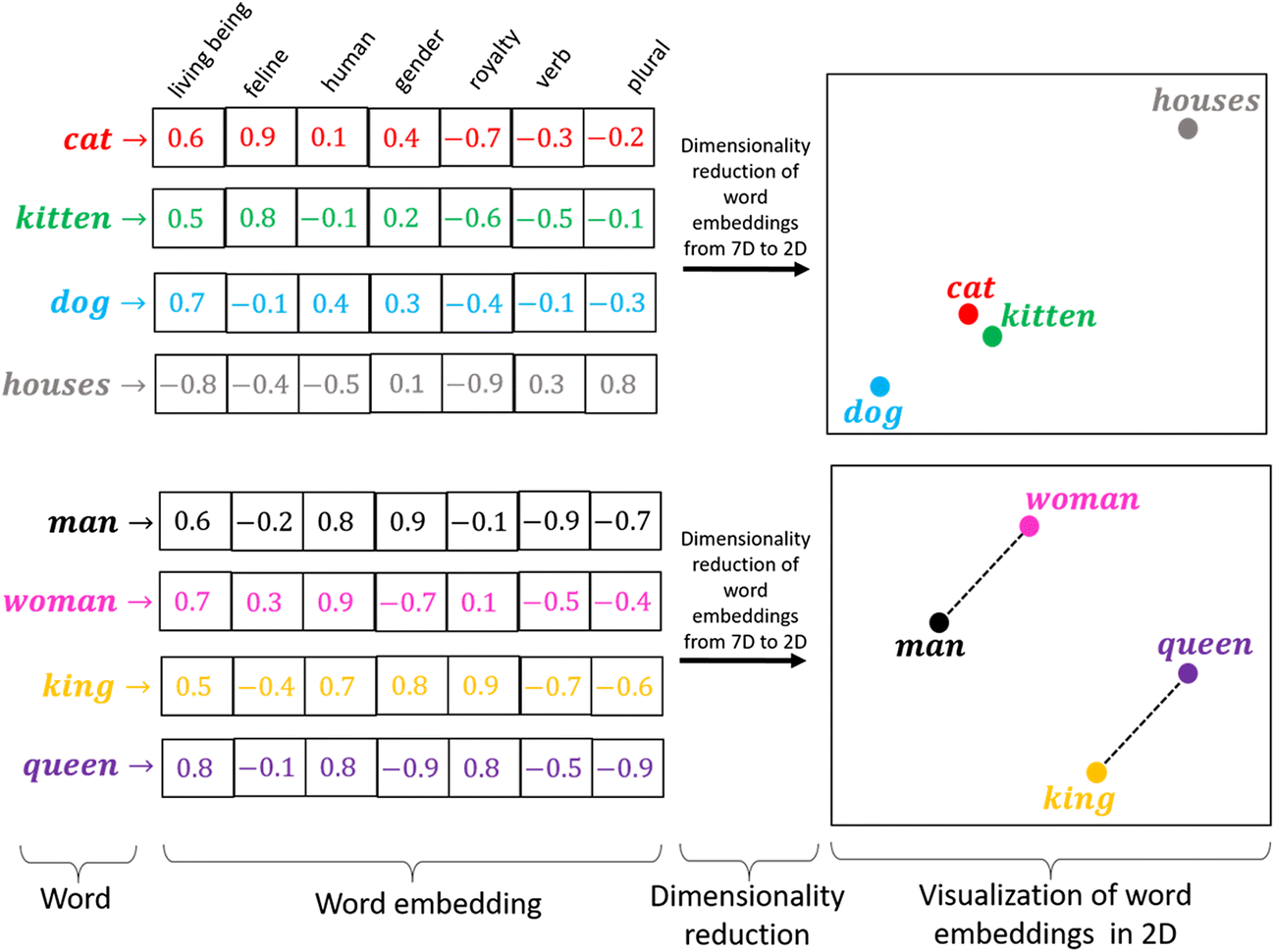
Un autre “miracle” de cette approche est qu’on obtient une forme de transfert entre les langues. Les relations sémantiques pouvant être similaires entre les langues, pour de nombreux mots usuels, on peut voir translater certaines langues les unes avec les autres si elles ont un socle commun (par exemple les langues occidentales). Ce concept est le point de départ des traducteurs automatiques et des IA multilingues
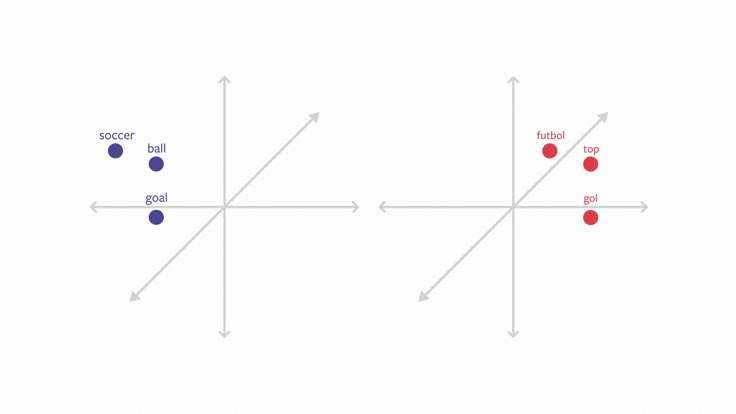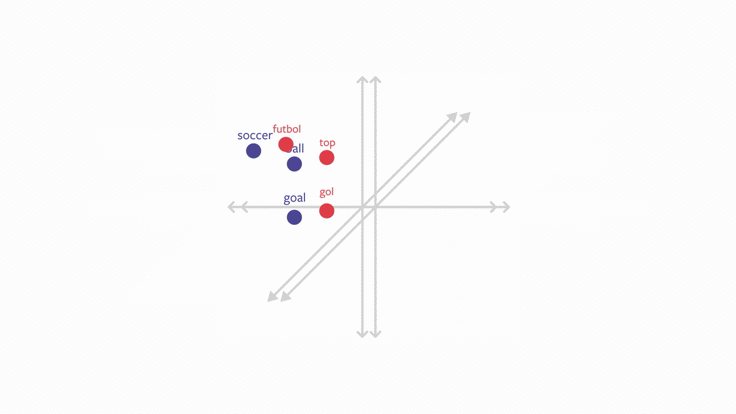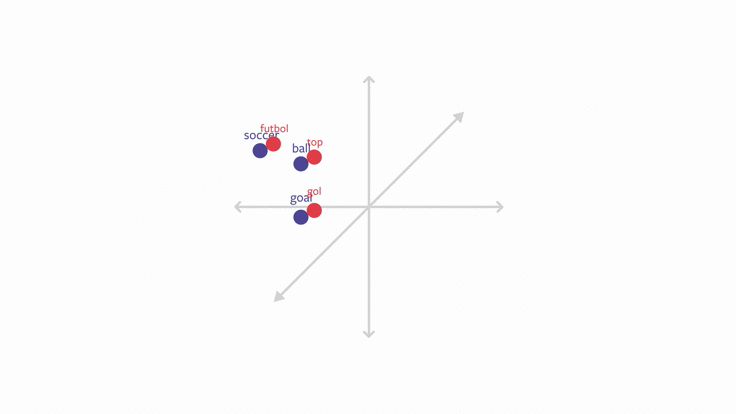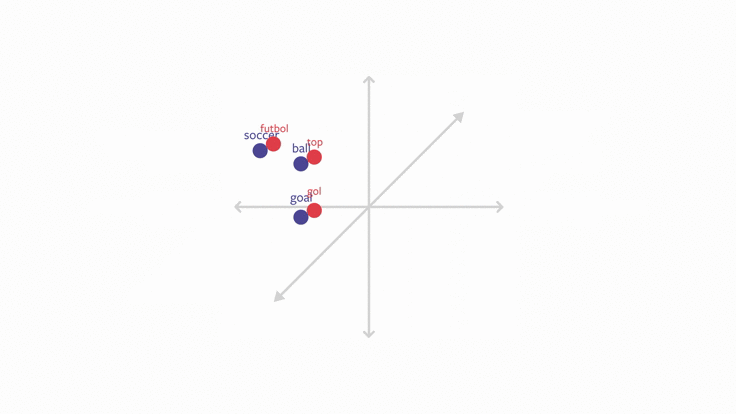
4.4 Modèles liés
Plusieurs modèles ont une filiation directe avec le modèle Word2Vec quoiqu’ils s’en distinguent par la nature de l’architecture utilisée.
C’est le cas, par exemple, du modèle modèle GloVe, développé en 2014 à Stanford,
qui ne repose pas sur des réseaux de neurones mais sur la construction d’une grande matrice de co-occurrences de mots. Pour chaque mot, il s’agit de calculer les fréquences d’apparition des autres mots dans une fenêtre de taille fixe autour de lui. La matrice de co-occurrences obtenue est ensuite factorisée par une décomposition en valeurs singulières.
Le modèle FastText, développé en 2016 par une équipe de Facebook, fonctionne de façon similaire à Word2Vec mais se distingue particulièrement sur deux points :
- En plus des mots eux-mêmes, le modèle apprend des représentations pour les n-grams de caractères (sous-séquences de caractères de taille \(n\), par exemple « tar », « art » et « rte » sont les trigrammes du mot « tarte »), ce qui le rend notamment robuste aux variations d’orthographe ;
- Le modèle a été optimisé pour que son entraînement soit particulièrement rapide.
Le modèle FastText est particulièrement performant pour les problématiques de classification automatique. L’Insee l’utilise par exemple pour plusieurs modèles de classification de libellés textuels dans des nomenclatures.
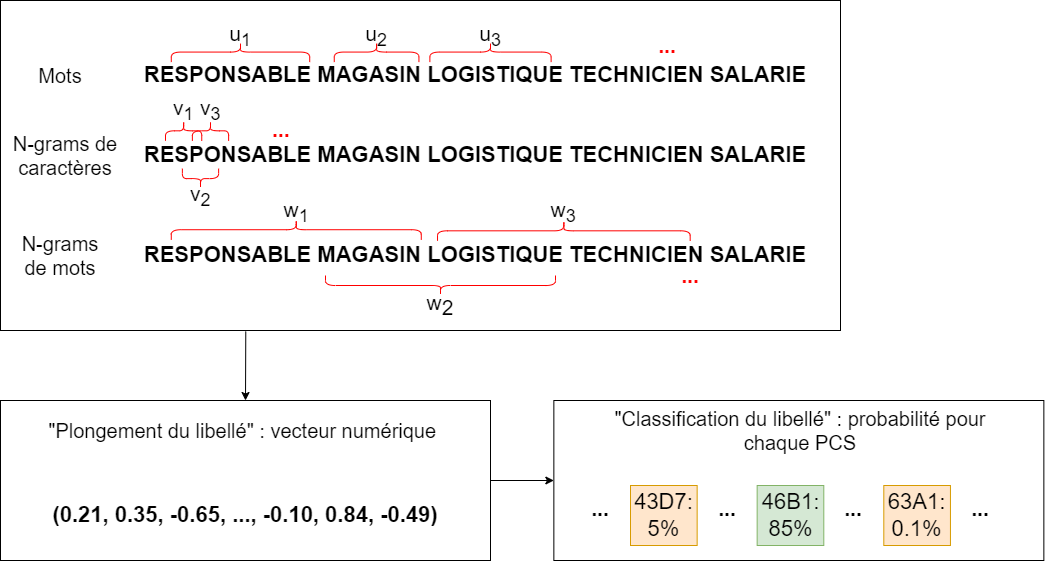
Voici un exemple sur un projet de classification automatisée des professions dans la typologie
des nomenclatures d’activités (les PCS) à partir d’un modèle entraîné par la librairie Fasttext :
Ces modèles sont héritiers de Word2Vec dans le sens où ils reprennent une représentation vectorielle dense de faible dimension de documents textuels. Word2Vec reste un modèle héritier de la logique sac de mot. La représentation d’une phrase ou d’un document est une forme de moyenne des représentations des mots qui les composent.
Depuis 2013, plusieurs révolutions ont amené à enrichir les modèles de langage pour aller au-delà d’une représentation par mot de ceux-ci. Des architectures beaucoup plus complexes pour représenter non seulement les mots sous forme d’embeddings mais aussi les phrases et les documents sont aujourd’hui à l’oeuvre et peuvent être reliées à la révolution des architectures transformers.
5 Les transformers: une représentation plus riche du langage
Si le modèle Word2Vec est entraîné de manière contextuelle, sa vocation est de donner une représentation vectorielle d’un mot de manière absolue, indépendamment du contexte. Par exemple, le terme “banc” aura exactement la même représentation vectorielle qu’il se trouve dans la phrase “Elle court vers le banc de sable” ou “Il t’attend sur un banc au parc”_. C’est une limite majeure de ce type d’approche et on se doute bien de l’importance du contexte pour l’interprétation du langage.
L’objectif des architectures transformers est de permettre des représentations vectorielles contextuelles. Autrement dit, un mot aura plusieurs représentations vectorielles, selon son contexte d’occurrence. Ces modèles s’appuient sur le mécanisme d’attention (Vaswani 2017). Avant cette approche, lorsqu’un modèle apprenait à vectoriser un texte et qu’il arrivait au énième mot, la seule mémoire qu’il gardait était celle du mot précédent. Par récurrence, cela signifiait qu’il gardait une mémoire des mots précédents mais celle-ci tendait à se dissiper. Par conséquent, pour un mot arrivant loin dans la phrase, il était probable que le contexte de début de phrase était oublié. Autrement dit, dans la phrase “à la plage, il allait explorer le banc”, il était fort probable qu’arrivé au mot “banc”, le modèle ait oublié le début de phrase qui avait pourtant de l’importance pour l’interprétation.
L’objectif du mécanisme d’attention est de créer une mémoire interne au modèle permettant, pour tout mot d’un texte, de pouvoir garder trace des autres mots. Bien-sûr tous ne sont pas pertinents pour interpréter le texte mais cela évite d’oublier ceux qui sont importants. L’innovation principale des dernières années en NLP a été de parvenir à créer des mécanismes d’attention à grande échelle sans pour autant rendre intractables les modèles. Les fenêtres de contexte des modèles les plus performants deviennent immenses. Par exemple le modèle Llama 3.1 (rendu public par Meta en Juillet 2024) propose une fenêtre de contexte de 128 000 tokens, soit environ 96 000 mots, l’équivalent du Hobbit de Tolkien. Autrement dit, pour déduire la subtilité du sens d’un mot, ce modèle peut parcourir un contexte aussi long qu’un roman d’environ 300 pages.
Les deux modèles qui ont marqué leur époque dans le domaine sont les modèles BERT développé en 2018 par Google (qui était déjà à l’origine de Word2Vec) et la première version du bien-connu GPT d’OpenAI, qui, en 2017, était le premier modèle préentraîné basé sur l’architecture transformer. Ces deux familles de transformer diffèrent dans la manière dont ils intègrent le contexte pour faire une prédiction. GPT est un modèle autorégressif, donc ne considère que les tokens avant celui dont on désire faire une prédiction. BERT utilise les tokens à gauche et à droite pour inférer le contexte. Ces deux grands modèles de langage entraînés sont entraînés par auto-renforcement, principalement sur des tâches de prédiction du prochain token (« The Hugging Face Course, 2022 » 2022). Depuis le succès de ChatGPT, les nouveaux modèles GPT (à partir de la version 3) ne sont plus open source. Pour les utiliser, il faut donc passer par les API d’OpenAI. Il existe néanmoins de nombreuses alternatives dont les poids sont ouverts, à défaut d’être open source2, qui permettent d’utiliser ces LLM par le biais de Python, par le biais, notamment, de la librairie transformers développée par Hugging Face.
Quand on travaille avec des corpus de taille restreinte, c’est généralement une mauvaise idée d’entraîner son propre modèle from scratch. Heureusement, des modèles pré-entraînés sur de très gros corpus sont disponibles. Ils permettent de réaliser du transfer learning, c’est-à-dire de bénéficier de la performance d’un modèle qui a été entraîné sur une autre tâche ou bien sur un autre corpus.
AstuceExercice 3
- Refaire un train/test split avec 500 lignes aléatoires
- Importer le modèle
all-MiniLM-L6-v2avec le packagesentence transformers. EncoderX_trainetX_test - Faire une classification avec une méthode simple, par exemple des SVC, s’appuyant sur les embeddings produits à la question précédente. Comme le jeu d’entraînement est réduit, vous pouvez faire de la validation croisée.
- Comprendre pourquoi les performances sont détériorées par rapport au classifieur naif de Bayes.
Réponse à la question 1:
random_rows = spooky_df.sample(500)
y = random_rows["author"]
X = random_rows['text']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)Réponse à la question 2:
from sentence_transformers import SentenceTransformer
from sklearn.svm import LinearSVC
model = SentenceTransformer(
"all-MiniLM-L6-v2", model_kwargs={"torch_dtype": "float16"}
)
X_train_vectors = model.encode(X_train.values)
X_test_vectors = model.encode(X_test.values)Réponse à la question 3:
from sklearn.model_selection import cross_val_score
clf = LinearSVC(max_iter=10000, C=0.1, dual="auto")
scores = cross_val_score(
clf, X_train_vectors, y_train,
cv=4, scoring='f1_micro', n_jobs=4
)
print(f"CV scores {scores}")
print(f"Mean F1 {np.mean(scores)}")Mais pourquoi, avec une méthode très compliquée, ne parvenons-nous pas à battre une méthode toute simple ?
On peut avancer plusieurs raisons :
- le
TF-IDFest un modèle simple, mais toujours très performant (on parle de “tough-to-beat baseline”). - la classification d’auteurs est une tâche très particulière et très ardue, qui ne fait pas justice aux embeddings. Comme on l’a dit précédemment, ces derniers se révèlent particulièrement pertinents lorsqu’il est question de similarité sémantique entre des textes (clustering, etc.).
Dans le cas de notre tâche de classification, il est probable que certains mots (noms de personnage, noms de lieux) soient suffisants pour classifier de manière pertinente, ce que ne permettent pas de capter les embeddings qui accordent à tous les mots la même importance.
Informations additionnelles
NoteEnvironnement Python
Ce site a été construit automatiquement par le biais d’une action Github utilisant le logiciel de publication reproductible Quarto
L’environnement utilisé pour obtenir les résultats est reproductible par le biais d’uv. Le fichier pyproject.toml utilisé pour construire cet environnement est disponible sur le dépôt linogaliana/python-datascientist
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
Pour utiliser exactement le même environnement (version de Python et packages), se reporter à la documentation d’uv.
NoteHistorique du fichier
| SHA | Date | Author | Description |
|---|---|---|---|
| 794ce14a | 2025-09-15 16:21:42 | lgaliana | retouche quelques abstracts |
| ca020f2a | 2025-08-22 09:25:48 | Lino Galiana | énième try/except pour l’API d’exemple de l’APE |
| 99ab48b0 | 2025-07-25 18:50:15 | Lino Galiana | Utilisation des callout classiques pour les box notes and co (#629) |
| 94648290 | 2025-07-22 18:57:48 | Lino Galiana | Fix boxes now that it is better supported by jupyter (#628) |
| 91431fa2 | 2025-06-09 17:08:00 | Lino Galiana | Improve homepage hero banner (#612) |
| 5f615403 | 2025-05-26 12:50:46 | lgaliana | Title and description for embedding chapter (english version) |
| d6b67125 | 2025-05-23 18:03:48 | Lino Galiana | Traduction des chapitres NLP (#603) |
| 24d4ff6d | 2024-12-09 15:22:19 | lgaliana | ensure non executable block |
| 3817cdc5 | 2024-12-09 13:34:56 | lgaliana | eval false pour le dernier exo |
| 8d097424 | 2024-12-09 13:34:16 | lgaliana | update embedding |
| 441da890 | 2024-12-08 20:28:21 | lgaliana | Utilise un service pytorch |
| 0ec1e15c | 2024-12-07 15:54:20 | lgaliana | Commence à décrire l’attention |
| 35443b75 | 2024-12-07 13:40:34 | lgaliana | Word2Vec |
| 89397cf2 | 2024-12-06 21:50:25 | lgaliana | Preprocessing |
| 4181dab1 | 2024-12-06 13:16:36 | lgaliana | Transition |
| 38b5152a | 2024-12-05 22:21:11 | lgaliana | détails sur l’approche proba |
| 5df69ccf | 2024-12-05 17:56:47 | lgaliana | up |
| 1b7188a1 | 2024-12-05 13:21:11 | lgaliana | Embedding chapter |
| c641de05 | 2024-08-22 11:37:13 | Lino Galiana | A series of fix for notebooks that were bugging (#545) |
| c5a9fb7a | 2024-07-22 09:56:18 | Julien PRAMIL | Fix bug in LDA chapter (#525) |
| c9f9f8a7 | 2024-04-24 15:09:35 | Lino Galiana | Dark mode and CSS improvements (#494) |
| 06d003a1 | 2024-04-23 10:09:22 | Lino Galiana | Continue la restructuration des sous-parties (#492) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 3437373a | 2023-12-16 20:11:06 | Lino Galiana | Améliore l’exercice sur le LASSO (#473) |
| 4cd44f35 | 2023-12-11 17:37:50 | Antoine Palazzolo | Relecture NLP (#474) |
| deaafb6f | 2023-12-11 13:44:34 | Thomas Faria | Relecture Thomas partie NLP (#472) |
| 1f23de28 | 2023-12-01 17:25:36 | Lino Galiana | Stockage des images sur S3 (#466) |
| 6855667d | 2023-11-29 10:21:01 | Romain Avouac | Corrections tp vectorisation + improve badge creation (#465) |
| 69cf52bd | 2023-11-21 16:12:37 | Antoine Palazzolo | [On-going] Suggestions chapitres modélisation (#452) |
| 652009df | 2023-10-09 13:56:34 | Lino Galiana | Finalise le cleaning (#430) |
| a7711832 | 2023-10-09 11:27:45 | Antoine Palazzolo | Relecture TD2 par Antoine (#418) |
| 154f09e4 | 2023-09-26 14:59:11 | Antoine Palazzolo | Des typos corrigées par Antoine (#411) |
| 9a4e2267 | 2023-08-28 17:11:52 | Lino Galiana | Action to check URL still exist (#399) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| 78ea2cbd | 2023-07-20 20:27:31 | Lino Galiana | Change titles levels (#381) |
| 29ff3f58 | 2023-07-07 14:17:53 | linogaliana | description everywhere |
| f21a24d3 | 2023-07-02 10:58:15 | Lino Galiana | Pipeline Quarto & Pages 🚀 (#365) |
| b3959852 | 2023-02-13 17:29:36 | Lino Galiana | Retire shortcode spoiler (#352) |
| f10815b5 | 2022-08-25 16:00:03 | Lino Galiana | Notebooks should now look more beautiful (#260) |
| d201e3cd | 2022-08-03 15:50:34 | Lino Galiana | Pimp la homepage ✨ (#249) |
| 12965bac | 2022-05-25 15:53:27 | Lino Galiana | :launch: Bascule vers quarto (#226) |
| 9c71d6e7 | 2022-03-08 10:34:26 | Lino Galiana | Plus d’éléments sur S3 (#218) |
| 70587527 | 2022-03-04 15:35:17 | Lino Galiana | Relecture Word2Vec (#216) |
| ce1f2b55 | 2022-02-16 13:54:27 | Lino Galiana | spacy corpus pre-downloaded |
| 66e2837c | 2021-12-24 16:54:45 | Lino Galiana | Fix a few typos in the new pipeline tutorial (#208) |
| 8ab1956a | 2021-12-23 21:07:30 | Romain Avouac | TP vectorization prediction authors (#206) |
| 09b60a18 | 2021-12-21 19:58:58 | Lino Galiana | Relecture suite du NLP (#205) |
| 495599d7 | 2021-12-19 18:33:05 | Lino Galiana | Des éléments supplémentaires dans la partie NLP (#202) |
| 2a8809fb | 2021-10-27 12:05:34 | Lino Galiana | Simplification des hooks pour gagner en flexibilité et clarté (#166) |
| 2e4d5862 | 2021-09-02 12:03:39 | Lino Galiana | Simplify badges generation (#130) |
| 4cdb759c | 2021-05-12 10:37:23 | Lino Galiana | :sparkles: :star2: Nouveau thème hugo :snake: :fire: (#105) |
| 7f9f97bc | 2021-04-30 21:44:04 | Lino Galiana | 🐳 + 🐍 New workflow (docker 🐳) and new dataset for modelization (2020 🇺🇸 elections) (#99) |
| d164635d | 2020-12-08 16:22:00 | Lino Galiana | :books: Première partie NLP (#87) |
Les références
Mikolov, Tomas. 2013. « Efficient estimation of word representations in vector space ». arXiv preprint arXiv:1301.3781 3781.
« The Hugging Face Course, 2022 ». 2022. https://huggingface.co/course.
Vaswani, A. 2017. « Attention is all you need ». Advances in Neural Information Processing Systems.
Notes de bas de page
This remark may seem surprising while generative AIs occupy an important place in our usage. Nevertheless, we must keep in mind that while you ask new questions to AIs, you ask them in terms they know: natural language in a language present in their training corpus, digital images that are therefore interpretable by a machine, etc. In other words, your prompt is not, in itself, unknown to the AI, it can interpret it even if its content is new and original.↩︎
Some organizations, like Meta for Llama, make available the post-training weights of their model on the Hugging Face platform, allowing reuse of these models if the license permits. Nevertheless, these are not open source models since the code used to train the models and constitute the learning corpora, derived from massive data collection by webscraping, and any additional annotations to make specialized versions, are not shared.↩︎
Citation
BibTeX
@book{galiana2025,
author = {Galiana, Lino},
title = {Python pour la data science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {fr}
}
Veuillez citer ce travail comme suit :
Galiana, Lino. 2025. Python pour la data science. https://doi.org/10.5281/zenodo.8229676.
4.3 Comment ces modèles sont-ils entraînés ?
Ces modèles sont entraînés à partir d’une tâche de prédiction résolue par un réseau de neurones simple, généralement avec une approche par renforcement.
L’idée fondamentale est que la signification d’un mot se comprend en regardant les mots qui apparaissent fréquemment dans son voisinage. Pour un mot donné, on va donc essayer de prédire les mots qui apparaissent dans une fenêtre autour du mot cible.
En répétant cette tâche de nombreuses fois et sur un corpus suffisamment varié, on obtient finalement des embeddings pour chaque mot du vocabulaire, qui présentent les propriétés discutées précédemment. L’ensemble des articles
Wikipediaest un des corpus de prédilection des personnes ayant construit des plongements lexicaux. Il comporte en effet des phrases complètes, contrairement à des informations issues de commentaires de réseaux sociaux, et propose des rapprochements intéressants entre des personnes, des lieux, etc.Le contexte d’un mot est défini par une fenêtre de taille fixe autour de ce mot. La taille de la fenêtre est un paramètre de la construction de l’embedding. Le corpus fournit un grand ensemble d’exemples mots-contexte, qui peuvent servir à entraîner un réseau de neurones.
Plus précisément, il existe deux approches, dont nous ne développerons pas les détails :