!pip install spacy
!python -m spacy download en_core_web_sm
!python -m spacy download fr_core_news_smPour essayer les exemples présents dans ce tutoriel :

Pour avancer dans ce chapitre, nous avons besoin de quelques installations préalables:
Il est également utile de définir la fonction suivante, issue de notre chapitre précédent :
def clean_text(doc):
# Tokenize, remove stop words and punctuation, and lemmatize
cleaned_tokens = [token.lemma_ for token in doc if not token.is_stop and not token.is_punct]
# Join tokens back into a single string
cleaned_text = ' '.join(cleaned_tokens)
return cleaned_text1 Introduction
Nous avons vu, précédemment, l’intérêt de nettoyer les données pour dégrossir le volume d’information présent dans nos données non structurées. L’objectif de ce chapitre est d’approfondir notre compréhension de l’approche fréquentiste appliquée aux données textuelles. Nous allons évoquer la manière dont cette analyse fréquentiste permet de synthétiser l’information présente dans un corpus textuel. Nous allons également voir la manière dont on peut raffiner l’approche bag of words en tenant compte de l’ordre de la proximité des termes dans une phrase.
1.1 Données
Nous allons reprendre le jeu de données anglo-saxon du chapitre précédent, à savoir des textes des auteurs fantastiques Edgar Allan Poe (EAP), HP Lovecraft (HPL) et Mary Wollstonecraft Shelley (MWS).
import pandas as pd
url='https://github.com/GU4243-ADS/spring2018-project1-ginnyqg/raw/master/data/spooky.csv'
#1. Import des données
horror = pd.read_csv(url,encoding='latin-1')
#2. Majuscules aux noms des colonnes
horror.columns = horror.columns.str.capitalize()
#3. Retirer le prefixe id
horror['ID'] = horror['Id'].str.replace("id","")
horror = horror.set_index('Id')2 La mesure TF-IDF (term frequency - inverse document frequency)
2.1 La matrice documents - termes
Comme nous l’avons évoqué précédemment, nous construisons une représentation synthétique de notre corpus comme un sac de mots dans lesquels on pioche plus ou moins fréquemment des mots selon leur fréquence d’apparition. C’est bien sûr une représentation simpliste de la réalité : les séquences de mots ne sont pas une suite aléatoire indépendante de mots.
Cependant, avant d’évoquer ces enjeux, il nous reste à aller au bout de l’approche sac de mots. La représentation la plus caractéristique de ce paradigme est la matrice document-terme, principalement utilisée pour comparer des corpus. Celle-ci consiste à créer une matrice où chaque document est représenté par la présence ou l’absence des termes de notre corpus. L’idée est de compter le nombre de fois où les mots (les termes, en colonne) sont présents dans chaque phrase ou libellé (le document, en ligne). Cette matrice fournit alors une représentation numérique des données textuelles.
Considérons un corpus constitué des trois phrases suivantes :
- “La pratique du tricot et du crochet”
- “Transmettre la passion du timbre”
- “Vivre de sa passion”
La matrice document-terme associée à ce corpus est la suivante :
| crochet | de | du | et | la | passion | pratique | sa | timbre | transmettre | tricot | vivre | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| La pratique du tricot et du crochet | 1 | 0 | 2 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| Transmettre sa passion du timbre | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| Vivre de sa passion | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
Chaque phrase du corpus est associée à un vecteur numérique. Par exemple,
la phrase “La pratique du tricot et du crochet”, qui n’a pas de sens en soi pour une machine, devient un vecteur numérique intelligible pour elle égal à [1, 0, 2, 1, 1, 0, 1, 0, 0, 0, 1, 0]. Ce vecteur numérique est une représentation creuse (sparse) du langage puisque chaque document (ligne) ne comportera qu’une petite partie du vocabulaire total (l’ensemble des colonnes). Pour tous les mots qui n’apparaîtront pas dans le document, on aura des 0, d’où un vecteur sparse. Comme nous le verrons par la suite, cette représentation numérique diffère grandement des approches modernes d’embeddings, basées sur l’idée de représentation denses.
2.2 Utilisation pour l’extraction d’informations
Différents documents peuvent alors être rapprochés sur la base de ces mesures. C’est l’une des manières de procéder des moteurs de recherche même si les meilleurs utilisent des approches bien plus sophistiquées. La métrique tf-idf (term frequency–inverse document frequency) permet de calculer un score de proximité entre un terme de recherche et un document à partir de deux composantes :
\[ \text{tf-idf}(t, d, D) = \text{tf}(t, d) \times \text{idf}(t, D) \]
avec \(t\) un terme particulier (par exemple un mot), \(d\) un document particulier et \(D\) l’ensemble de documents dans le corpus.
La partie
tfcalcule une fonction croissante de la fréquence du terme de recherche dans le document à l’étude ;La partie
idfcalcule une fonction inversement proportionnelle à la fréquence du terme dans l’ensemble des documents (ou corpus).La première partie (term-frequency, TF) est la fréquence d’apparition du terme terme \(t\) dans le document \(d\). Il existe des mesures de normalisation pour éviter de biaiser la mesure en cas de documents longs.
\[ \text{tf}(t, d) = \frac{f_{t,d}}{\sum_{t' \in d} f_{t',d}} \]
où \(f_{t,d}\) est le nombre brut de fois que le terme \(t\) apparaît dans le document \(d\) et le dénominateur est le nombre de termes dans le document \(d\).
- La seconde partie (inverse document frequency, IDF) mesure la rareté, ou au contraire l’aspect commun, d’un terme dans l’ensemble du corpus. Si \(N\) est le nombre total de documents dans le corpus \(D\), cette partie de la mesure sera
\[ \text{idf}(t, D) = \log \left( \frac{N}{|\{d \in D : t \in d\}|} \right) \]
Le dénominateur \(( |\{d \in D : t \in d\}| )\) correspond au nombre de documents contenant le terme \(t\), s’il apparaît. Plus le mot est rare, plus sa présence dans un document sera surpondérée.
De nombreux moteurs de recherche utilisent cette logique pour rechercher les documents les plus pertinents pour répondre à des termes de recherche. C’est notamment le cas d’ ElasticSearch, le logiciel qui permet d’implémenter des moteurs de recherche efficaces. Pour classer les documents les plus pertinents par rapport à des termes de recherche, ce logiciel utilise notamment la mesure de distance BM25 qui est une version sophistiquée de la mesure TF-IDF.
2.3 Exemple
Prenons une illustration à partir d’un petit corpus. Le code suivant implémente une mesure TF-IDF. Celle-ci est légèrement différente de celle définie ci-dessus pour s’assurer de ne pas effectuer de division par zéro.
import numpy as np
# Documents d'exemple
documents = [
"Le corbeau et le renard",
"Rusé comme un renard",
"Le chat est orange comme un renard"
]
# Tokenisation
def preprocess(doc):
return doc.lower().split()
tokenized_docs = [preprocess(doc) for doc in documents]
# Term frequency (TF)
def term_frequency(term, tokenized_doc):
term_count = tokenized_doc.count(term)
return term_count / len(tokenized_doc)
# Inverse document frequency (DF)
def document_frequency(term, tokenized_docs):
return sum(1 for doc in tokenized_docs if term in doc)
# Calculate inverse document frequency (IDF)
def inverse_document_frequency(word, corpus):
# Normalisation avec + 1 pour éviter la division par zéro
count_of_documents = len(corpus) + 1
count_of_documents_with_word = sum([1 for doc in corpus if word in doc]) + 1
idf = np.log10(count_of_documents/count_of_documents_with_word) + 1
return idf
# Calculate TF-IDF scores in each document
def tf_idf_term(term):
tf_idf_scores = pd.DataFrame(
[
[
term_frequency(term, doc),
inverse_document_frequency(term, tokenized_docs)
] for doc in tokenized_docs
],
columns = ["TF", "IDF"]
)
tf_idf_scores["TF-IDF"] = tf_idf_scores["TF"] * tf_idf_scores["IDF"]
return tf_idf_scoresCommençons par calculer TF-IDF du mot “chat” pour chaque document. De manière naturelle, c’est le troisième document, le seul où apparaît le mot qui a la valeur maximale :
tf_idf_term("chat")| TF | IDF | TF-IDF | |
|---|---|---|---|
| 0 | 0.000000 | 1.30103 | 0.000000 |
| 1 | 0.000000 | 1.30103 | 0.000000 |
| 2 | 0.142857 | 1.30103 | 0.185861 |
Qu’en est-il du terme renard qui apparaît dans tous les documents (dont la partie \(\text{idf}\) est donc égale à 1) ? Dans ce cas, c’est le document où le mot est le plus fréquent, en l’occurrence le 2e, qui a la mesure maximale.
tf_idf_term("renard")| TF | IDF | TF-IDF | |
|---|---|---|---|
| 0 | 0.200000 | 1.0 | 0.200000 |
| 1 | 0.250000 | 1.0 | 0.250000 |
| 2 | 0.142857 | 1.0 | 0.142857 |
2.4 Application
L’exemple précédent ne passait pas très bien à l’échelle. Heureusement, Scikit propose une implémentation de la recherche par vecteur TF-IDF que nous pouvons explorer avec un nouvel exercice.
AstuceExercice 1 : TF-IDF : calcul de fréquence
- Utiliser le vectoriseur TF-IdF de
scikit-learnpour transformer notre corpus en une matricedocument x terms. Au passage, utiliser l’optionstop_wordspour ne pas provoquer une inflation de la taille de la matrice. Nommer le modèletfidfet le jeu entraînétfs. - Après avoir construit la matrice de documents x terms avec le code suivant, rechercher les lignes où les termes ayant la structure
abandonsont non-nuls. - Trouver les 50 extraits où le score TF-IDF du mot “fear” est le plus élevé et l’auteur associé. Déterminer la répartition des auteurs dans ces 50 documents.
- Observer les 10 scores où TF-IDF de “fear” sont les plus élevés
Aide pour la question 2
feature_names = tfidf.get_feature_names_out()
corpus_index = [n for n in list(tfidf.vocabulary_.keys())]
horror_dense = pd.DataFrame(tfs.todense(), columns=feature_names)Le vectoriseur obtenu à l’issue de la question 1 est le suivant :
TfidfVectorizer(stop_words=['an', 'yourselves', 'twelve', 'whom', 'their', 'by',
'fifteen', 'somehow', 'formerly', 'without',
'across', 'already', 'side', 'whence', 'ca', 'off',
"'d", 'after', 'ourselves', 'does', 'fifty', '‘re',
'make', 'hereafter', 'anywhere', 'becoming', 'one',
'before', 'here', 'what', ...])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
/home/runner/work/python-datascientist/python-datascientist/.venv/lib/python3.13/site-packages/sklearn/feature_extraction/text.py:412: UserWarning: Your stop_words may be inconsistent with your preprocessing. Tokenizing the stop words generated tokens ['ll', 've'] not in stop_words.
warnings.warn(| aaem | ab | aback | abaft | abandon | abandoned | abandoning | abandonment | abaout | abased | ... | zodiacal | zoilus | zokkar | zone | zones | zopyrus | zorry | zubmizzion | zuro | á¼ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.267616 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 24783 columns
Les lignes où le terme “abandon” apparait sont les suivantes (question 2) :
Index([ 4, 116, 215, 571, 839, 1042, 1052, 1069, 2247, 2317,
2505, 3023, 3058, 3245, 3380, 3764, 3886, 4425, 5289, 5576,
5694, 6812, 7500, 9013, 9021, 9077, 9560, 11229, 11395, 11451,
11588, 11827, 11989, 11998, 12122, 12158, 12189, 13666, 15259, 16516,
16524, 16759, 17547, 18019, 18072, 18126, 18204, 18251],
dtype='int64')La matrice document-terme associée à celles-ci est la suivante :
| aaem | ab | aback | abaft | abandon | abandoned | abandoning | abandonment | abaout | abased | ... | zodiacal | zoilus | zokkar | zone | zones | zopyrus | zorry | zubmizzion | zuro | á¼ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.267616 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 116 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.359676 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 215 | 0.0 | 0.0 | 0.0 | 0.0 | 0.249090 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 571 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.153280 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 839 | 0.0 | 0.0 | 0.0 | 0.0 | 0.312172 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 24783 columns
On remarque ici l’inconvénient de ne pas avoir fait de racinisation. Les variations de “abandon” sont éclatées sur de nombreuses colonnes. “abandoned” est aussi différent d’“abandon” que de “fear”. C’est l’un des problèmes de l’approche bag of words.
Text 50
dtype: int64Les 10 scores les plus élevés sont les suivants :
['We could not fear we did not.',
'"And now I do not fear death.',
'Be of heart and fear nothing.',
'Indeed I had no fear on her account.',
'I smiled, for what had I to fear?',
'I did not like everything about what I saw, and felt again the fear I had had.',
'At length, in an abrupt manner she asked, "Where is he?" "O, fear not," she continued, "fear not that I should entertain hope Yet tell me, have you found him?',
'I have not the slightest fear for the result.',
'"I fear you are right there," said the Prefect.']On remarque que les scores les plus élevés sont soient des extraits courts où le mot apparait une seule fois, soit des extraits plus longs où le mot “fear” apparaît plusieurs fois.
3 Un premier enrichissement de l’approche sac de mots : les n-grams
Nous avons évoqué deux principales limites à l’approche sac de mot : l’absence de prise en compte du contexte et la représentation sparse du langage qui rend les rapprochements entre texte parfois moyennement pertinents. Dans le paradigme du sac de mots, il est néanmoins possible de prendre en compte la séquence d’enchainement de sèmes (tokens) par le biais des ngrams.
Pour rappel, jusqu’à présent, dans l’approche bag of words, l’ordre des mots n’avait pas d’importance. On considère qu’un texte est une collection de mots tirés indépendamment, de manière plus ou moins fréquente en fonction de leur probabilité d’occurrence. Cependant, tirer un mot particulier n’affecte pas les chances de tirer certains mots ensuite, de manière conditionnelle.
Une manière d’introduire des liens entre les séries de tokens sont les n-grams. On s’intéresse non seulement aux mots et à leur fréquence, mais aussi aux mots qui suivent. Cette approche est essentielle pour désambiguiser les homonymes. Le calcul de n-grams 1 constitue la méthode la plus simple pour tenir compte du contexte.
Pour être en mesure de mener cette analyse, il est nécessaire de télécharger un corpus supplémentaire :
import nltk
nltk.download('genesis')
nltk.corpus.genesis.words('english-web.txt')[nltk_data] Downloading package genesis to /home/runner/nltk_data...
[nltk_data] Package genesis is already up-to-date!['In', 'the', 'beginning', 'God', 'created', 'the', ...]NLTK offre des méthodes pour tenir compte du contexte. Pour ce faire, nous calculons les n-grams, c’est-à-dire l’ensemble des co-occurrences successives de mots n-à-n. En général, on se contente de bi-grams, au mieux de tri-grams :
- les modèles de classification, analyse du sentiment, comparaison de documents, etc. qui comparent des n-grams avec n trop grands sont rapidement confrontés au problème de données sparse, cela réduit la capacité prédictive des modèles ;
- les performances décroissent très rapidement en fonction de n, et les coûts de stockage des données augmentent rapidement (environ n fois plus élevé que la base de données initiale).
On va, rapidement, regarder dans quel contexte apparaît le mot fear dans
l’oeuvre d’Edgar Allan Poe (EAP). Pour cela, on transforme d’abord
le corpus EAP en tokens NLTK :
eap_clean = horror.loc[horror["Author"] == "EAP"]
eap_clean = ' '.join(eap_clean['Text'])
tokens = eap_clean.split()
print(tokens[:10])
text = nltk.Text(tokens)
print(text)['This', 'process,', 'however,', 'afforded', 'me', 'no', 'means', 'of', 'ascertaining', 'the']
<Text: This process, however, afforded me no means of...>Vous aurez besoin des fonctions BigramCollocationFinder.from_words et BigramAssocMeasures.likelihood_ratio :
AstuceExercice 2 : n-grams et contexte du mot fear
- Utiliser la méthode
concordancepour afficher le contexte dans lequel apparaît le termefear. - Sélectionner et afficher les meilleures collocations, par exemple selon le critère du ratio de vraisemblance.
Lorsque deux mots sont fortement associés, cela est parfois dû au fait qu’ils apparaissent rarement. Il est donc parfois nécessaire d’appliquer des filtres, par exemple ignorer les bigrammes qui apparaissent moins de 5 fois dans le corpus.
Refaire la question précédente en utilisant toujours un modèle
BigramCollocationFindersuivi de la méthodeapply_freq_filterpour ne conserver que les bigrammes présents au moins 5 fois. Puis, au lieu d’utiliser la méthode de maximum de vraisemblance, testez la méthodenltk.collocations.BigramAssocMeasures().jaccard.Ne s’intéresser qu’aux collocations qui concernent le mot fear
Avec la méthode concordance (question 1),
la liste devrait ressembler à celle-ci :
Exemples d'occurences du terme 'fear' :
Displaying 13 of 13 matches:
d quick unequal spoken apparently in fear as well as in anger. What he said wa
hutters were close fastened, through fear of robbers, and so I knew that he co
to details. I even went so far as to fear that, as I occasioned much trouble,
years of age, was heard to express a fear "that she should never see Marie aga
ich must be entirely remodelled, for fear of serious accident I mean the steel
my arm, and I attended her home. 'I fear that I shall never see Marie again.'
clusion here is absurd. "I very much fear it is so," replied Monsieur Maillard
bt of ultimately seeing the Pole. "I fear you are right there," said the Prefe
er occurred before.' Indeed I had no fear on her account. For a moment there w
erhaps so," said I; "but, Legrand, I fear you are no artist. It is my firm int
raps with a hammer. Be of heart and fear nothing. My daughter, Mademoiselle M
e splendor. I have not the slightest fear for the result. The face was so far
arriers of iron that hemmed me in. I fear you have mesmerized" adding immediat
Même si on peut facilement voir le mot avant et après, cette liste est assez difficile à interpréter car elle recoupe beaucoup d’informations.
La collocation consiste à trouver les bi-grammes qui
apparaissent le plus fréquemment ensemble. Parmi toutes les paires de deux mots observées,
il s’agit de sélectionner, à partir d’un modèle statistique, les “meilleures”.
On obtient donc avec cette méthode (question 2):
[('of', 'the'),
('in', 'the'),
('had', 'been'),
('to', 'be'),
('have', 'been'),
('I', 'had'),
('It', 'was'),
('it', 'is'),
('could', 'not'),
('from', 'the'),
('upon', 'the'),
('more', 'than'),
('it', 'was'),
('would', 'have'),
('with', 'a'),
('did', 'not'),
('I', 'am'),
('the', 'a'),
('at', 'once'),
('might', 'have')]Si on modélise les meilleures collocations :
"Gad Fly"
'Hum Drum,'
'Rowdy Dow,'
Brevet Brigadier
Barrière du
ugh ugh
Ourang Outang
Chess Player
John A.
A. B.
hu hu
General John
'Oppodeldoc,' whoever
mille, mille,
Brigadier GeneralCette liste a un peu plus de sens, on a des noms de personnages, de lieux mais aussi des termes fréquemment employés ensemble (Chess Player par exemple).
En ce qui concerne les collocations du mot fear :
[('fear', 'of'), ('fear', 'God'), ('I', 'fear'), ('the', 'fear'), ('The', 'fear'), ('fear', 'him'), ('you', 'fear')]Si on mène la même analyse pour le terme love, on remarque que de manière logique, on retrouve bien des sujets généralement accolés au verbe :
[('love', 'me'), ('love', 'he'), ('will', 'love'), ('I', 'love'), ('love', ','), ('you', 'love'), ('the', 'love')]4 Quelques applications
Nous venons d’évoquer un premier cas d’application de l’approche bag of words qui est le rapprochement de textes par leurs termes communs. Ce n’est pas le seul cas d’application de l’approche précédente. Nous allons en évoquer deux qui nous amènent vers la modélisation du langage : la reconnaissance d’entités nommées et la classification.
4.1 Reconnaissance des entités nommées
La reconnaissance d’entités nommées, également connue sous l’acronyme NER pour named entity recognition, est une méthode d’extraction d’information permettant d’identifier, dans un texte, la nature de certains termes dans une certain classification : lieu, personne, quantité, etc.
Pour illustrer cela, reprenons le Comte de Monte Cristo et regardons sur un petit morceau de cette oeuvre ce qu’implique la reconnaissance d’entités nommées :
import requests
import re
url = "https://www.gutenberg.org/files/17989/17989-0.txt"
response = requests.get(url)
response.encoding = 'utf-8' # Assure le bon décodage
raw = response.text
dumas = (
raw
.split("*** START OF THE PROJECT GUTENBERG EBOOK 17989 ***")[1]
.split("*** END OF THE PROJECT GUTENBERG EBOOK 17989 ***")[0]
1)
def clean_text(text):
text = text.lower() # mettre les mots en minuscule
text = " ".join(text.split())
return text
dumas = clean_text(dumas)
dumas[10000:10500]- 1
- On extrait de manière un petit peu simpliste le contenu de l’ouvrage
" mes yeux. --vous avez donc vu l'empereur aussi? --il est entré chez le maréchal pendant que j'y étais. --et vous lui avez parlé? --c'est-à-dire que c'est lui qui m'a parlé, monsieur, dit dantès en souriant. --et que vous a-t-il dit? --il m'a fait des questions sur le bâtiment, sur l'époque de son départ pour marseille, sur la route qu'il avait suivie et sur la cargaison qu'il portait. je crois que s'il eût été vide, et que j'en eusse été le maître, son intention eût été de l'acheter; mais je lu"import spacy
from spacy import displacy
nlp = spacy.load("fr_core_news_sm")
doc = nlp(dumas[15000:17000])
# displacy.render(doc, style="ent", jupyter=True)La reconnaissance d’entités nommées disponible par défaut dans les librairies généralistes est souvent décevante ; il est souvent nécessaire d’enrichir les règles par défaut par des règles ad hoc, propres à chaque corpus.
En pratique, récemment, l’approche de reconnaissance d’entités nommées a été utilisée par Etalab pour pseudonymiser des documents administratifs. Il s’agit d’identifier certaines informations sensibles (état civil, adresse…) par reconnaissance d’entités pour les remplacer par des pseudonymes.
4.2 Classification de données textuelles : l’algorithme Fasttext
Fasttext est un réseau de neurone à une couche développé par Meta en 2016 pour faire de la classification de texte ou de la modélisation de langage. Comme nous allons pouvoir le voir, ce modèle va nous amener à faire la transition avec une modélisation plus raffinée du langage, bien que celle de Fasttext soit beaucoup plus frustre que celle des grands modèles de langage (LLM). L’un des principaux cas d’utilisation de Fasttext est la classification supervisée de données textuelles. Il s’agit, à partir d’un texte, de déterminer sa catégorie d’appartenance. Par exemple, à partir d’un texte de chanson, s’il s’agit de rap ou de rock. Ce modèle est supervisé puisqu’il apprend à reconnnaître les features, en l’occurrence des morceaux de texte, qui permettent d’avoir une bonne performance de prédiction sur le jeu d’entraînement puis de test.
Le concept de feature peut sembler étonnant pour des données textuelles, qui sont, par essence, non structurées. Pour des données structurées, la démarche évoquée dans la partie modélisation apparaîssait naturelle : nous avions des variables observées dans nos données pour les features et l’algorithme de classification consistait à trouver la combinaison entre elles permettant de prédire, au mieux, le label. Avec des données textuelles, ce concept de feature observé n’est plus naturel. Il est nécessaire de le construire à partir d’un texte. L’information destructurée devient de l’information structurée. C’est là qu’interviennent les concepts que nous avons vu jusqu’à présent.
FastText est un “sac de n-gram”. Il considère donc que les features sont à construire à partir des mots de notre corpus mais aussi des ngrams à plusieurs niveaux. L’architecture générale de FastText ressemble à celle-ci :
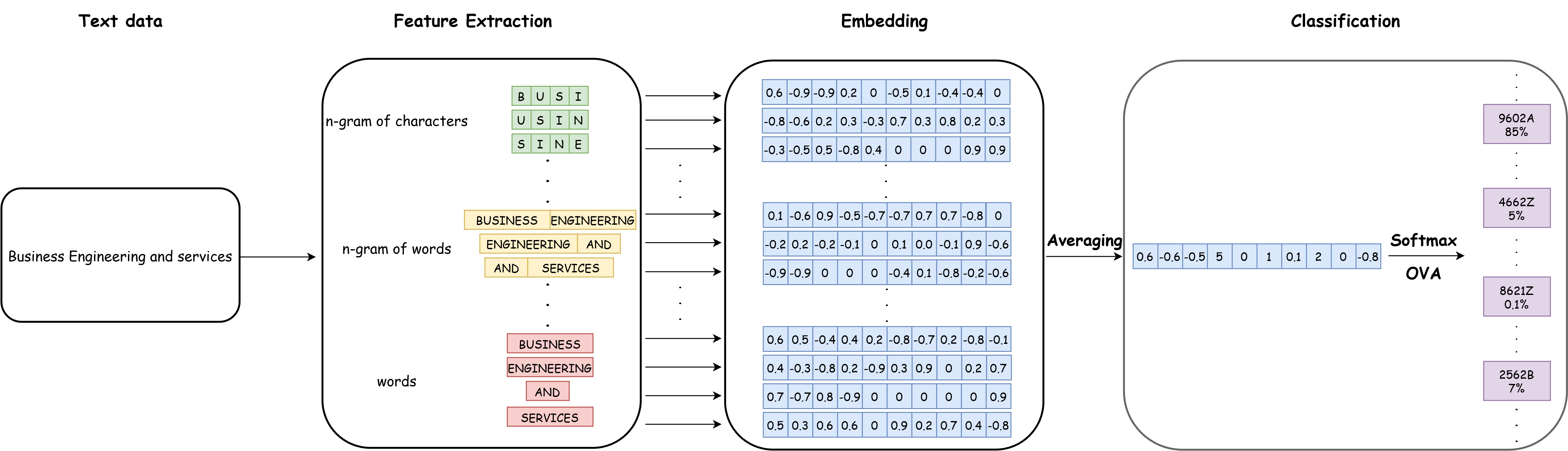
FastTextCe qui nous intéresse ici est la partie gauche de ce diagramme, la “feature extraction” car la partie embedding correspond à des concepts que nous verrons lors des prochains chapitres. Avec l’exemple de cette figure, on voit que le texte “Business engineering and services” est tokenisé comme nous avons pu le voir plus tôt en mots. Mais Fasttext créé également des ngrams à plusieurs niveaux. Par exemple, il va créer des bigrams de mots : “Business engineering”, “engineering and”, “and services”. mais aussi des quadrigrammes de caractères “busi”, “usin” et “sine”. Ensuite, Fasttext transformera tous ces termes en vecteurs numériques. Contrairement à ce que nous avons vu jusqu’à présent, ces vecteurs ne sont pas des fréquences d’apparition dans le corpus (principe de la matrice origine-document), ce sont des plongements de mots (word embedding). Nous découvrirons leurs principes dans les prochains chapitres.
Ce modèle Fasttext est très utilisé dans la statistique publique car de nombreuses sources de données textuelles sont à hiérarchiser dans des nomenclatures agrégées.
Voici un exemple d’utilisation d’un tel modèle pour la classification d’activités
Informations additionnelles
NoteEnvironnement Python
Ce site a été construit automatiquement par le biais d’une action Github utilisant le logiciel de publication reproductible Quarto
L’environnement utilisé pour obtenir les résultats est reproductible par le biais d’uv. Le fichier pyproject.toml utilisé pour construire cet environnement est disponible sur le dépôt linogaliana/python-datascientist
pyproject.toml
[project]
name = "python-datascientist"
version = "0.1.0"
description = "Source code for Lino Galiana's Python for data science course"
readme = "README.md"
requires-python = ">=3.13,<3.14"
dependencies = [
"altair>=6.0.0",
"cartiflette",
"contextily==1.6.2",
"duckdb>=0.10.1",
"folium>=0.19.6",
"gdal==3.11.4",
"graphviz==0.20.3",
"great-tables>=0.12.0",
"gt-extras>=0.0.8",
"ipykernel>=6.29.5",
"jupyter>=1.1.1",
"jupyter-cache>=1.0.0",
"kaleido>=0.2.1",
"langchain-community>=0.3.27",
"loguru==0.7.3",
"markdown>=3.8",
"nbclient>=0.10.0",
"nbformat>=5.10.4",
"nltk>=3.9.1",
"pandas>=3.0",
"pip>=25.1.1",
"plotly>=6.1.2",
"plotnine>=0.15",
"polars>=1.8.2",
"pyarrow>=17.0.0",
"pynsee>=0.1.8",
"python-dotenv>=1.0.1",
"python-frontmatter>=1.1.0",
"pywaffle>=1.1.1",
"requests>=2.32.3",
"scikit-image>=0.24.0",
"scikit-learn>=1.8.0",
"scipy>=1.13.0",
"seaborn>=0.13.2",
"selenium<4.39.0",
"spacy>=3.8.4",
"webdriver-manager>=4.0.2",
"wordcloud==1.9.3",
]
[tool.uv.sources]
cartiflette = { git = "https://github.com/inseefrlab/cartiflette" }
gdal = [
{ index = "gdal-wheels", marker = "sys_platform == 'linux'" },
{ index = "geospatial_wheels", marker = "sys_platform == 'win32'" },
]
[[tool.uv.index]]
name = "geospatial_wheels"
url = "https://nathanjmcdougall.github.io/geospatial-wheels-index/"
explicit = true
[[tool.uv.index]]
name = "gdal-wheels"
url = "https://gitlab.com/api/v4/projects/61637378/packages/pypi/simple"
explicit = true
[dependency-groups]
dev = [
"nb-clean>=4.0.1",
]
Pour utiliser exactement le même environnement (version de Python et packages), se reporter à la documentation d’uv.
NoteHistorique du fichier
| SHA | Date | Author | Description |
|---|---|---|---|
| d128ca0d | 2025-08-21 22:13:54 | Lino Galiana | Try/Except ici aussi |
| 91431fa2 | 2025-06-09 17:08:00 | Lino Galiana | Improve homepage hero banner (#612) |
| d6b67125 | 2025-05-23 18:03:48 | Lino Galiana | Traduction des chapitres NLP (#603) |
| e1617833 | 2025-05-23 10:08:11 | lgaliana | update uv env & remove discarded code |
| cb655535 | 2024-12-11 08:20:54 | lgaliana | PCA |
| 5df69ccf | 2024-12-05 17:56:47 | lgaliana | up |
| 1b7188a1 | 2024-12-05 13:21:11 | lgaliana | Embedding chapter |
| 5108922f | 2024-08-08 18:43:37 | Lino Galiana | Improve notebook generation and tests on PR (#536) |
| 8d23a533 | 2024-07-10 18:45:54 | Julien PRAMIL | Modifs 02_exoclean.qmd (#523) |
| f32915b9 | 2024-07-09 18:41:00 | Julien PRAMIL | Add badges NLP chapter (#522) |
| 6f2a5658 | 2024-06-16 16:23:01 | linogaliana | Détails tf-idf |
| 8cb248ab | 2024-06-16 16:09:45 | linogaliana | TF-IDF |
| fcdd7b4d | 2024-06-14 15:11:24 | linogaliana | Add spacy corpus |
| 4f41cf6a | 2024-06-14 15:00:41 | Lino Galiana | Une partie sur les sacs de mots plus cohérente (#501) |
| 06d003a1 | 2024-04-23 10:09:22 | Lino Galiana | Continue la restructuration des sous-parties (#492) |
| 005d89b8 | 2023-12-20 17:23:04 | Lino Galiana | Finalise l’affichage des statistiques Git (#478) |
| 3437373a | 2023-12-16 20:11:06 | Lino Galiana | Améliore l’exercice sur le LASSO (#473) |
| 4cd44f35 | 2023-12-11 17:37:50 | Antoine Palazzolo | Relecture NLP (#474) |
| deaafb6f | 2023-12-11 13:44:34 | Thomas Faria | Relecture Thomas partie NLP (#472) |
| 1f23de28 | 2023-12-01 17:25:36 | Lino Galiana | Stockage des images sur S3 (#466) |
| a1ab3d94 | 2023-11-24 10:57:02 | Lino Galiana | Reprise des chapitres NLP (#459) |
| a06a2689 | 2023-11-23 18:23:28 | Antoine Palazzolo | 2ème relectures chapitres ML (#457) |
| 09654c71 | 2023-11-14 15:16:44 | Antoine Palazzolo | Suggestions Git & Visualisation (#449) |
| 889a71ba | 2023-11-10 11:40:51 | Antoine Palazzolo | Modification TP 3 (#443) |
| a7711832 | 2023-10-09 11:27:45 | Antoine Palazzolo | Relecture TD2 par Antoine (#418) |
| 154f09e4 | 2023-09-26 14:59:11 | Antoine Palazzolo | Des typos corrigées par Antoine (#411) |
| a8f90c2f | 2023-08-28 09:26:12 | Lino Galiana | Update featured paths (#396) |
| 80823022 | 2023-08-25 17:48:36 | Lino Galiana | Mise à jour des scripts de construction des notebooks (#395) |
| 3bdf3b06 | 2023-08-25 11:23:02 | Lino Galiana | Simplification de la structure 🤓 (#393) |
| f2905a7d | 2023-08-11 17:24:57 | Lino Galiana | Introduction de la partie NLP (#388) |
| 78ea2cbd | 2023-07-20 20:27:31 | Lino Galiana | Change titles levels (#381) |
| a9b384ed | 2023-07-18 18:07:16 | Lino Galiana | Sépare les notebooks (#373) |
| 29ff3f58 | 2023-07-07 14:17:53 | linogaliana | description everywhere |
| f21a24d3 | 2023-07-02 10:58:15 | Lino Galiana | Pipeline Quarto & Pages 🚀 (#365) |
| 934149d6 | 2023-02-13 11:45:23 | Lino Galiana | get_feature_names is deprecated in scikit 1.0.X versions (#351) |
| 164fa689 | 2022-11-30 09:13:45 | Lino Galiana | Travail partie NLP (#328) |
| f10815b5 | 2022-08-25 16:00:03 | Lino Galiana | Notebooks should now look more beautiful (#260) |
| 494a85ae | 2022-08-05 14:49:56 | Lino Galiana | Images featured ✨ (#252) |
| d201e3cd | 2022-08-03 15:50:34 | Lino Galiana | Pimp la homepage ✨ (#249) |
| 12965bac | 2022-05-25 15:53:27 | Lino Galiana | :launch: Bascule vers quarto (#226) |
| 9c71d6e7 | 2022-03-08 10:34:26 | Lino Galiana | Plus d’éléments sur S3 (#218) |
| 3299f1d9 | 2022-01-08 16:50:11 | Lino Galiana | Clean NLP notebooks (#215) |
| 09b60a18 | 2021-12-21 19:58:58 | Lino Galiana | Relecture suite du NLP (#205) |
| 495599d7 | 2021-12-19 18:33:05 | Lino Galiana | Des éléments supplémentaires dans la partie NLP (#202) |
| 17092b2e | 2021-12-13 09:17:13 | Lino Galiana | Retouches partie NLP (#199) |
| 3c874832 | 2021-12-13 08:46:52 | Lino Galiana | Notebooks NLP update (#198) |
| 2a8809fb | 2021-10-27 12:05:34 | Lino Galiana | Simplification des hooks pour gagner en flexibilité et clarté (#166) |
| 2e4d5862 | 2021-09-02 12:03:39 | Lino Galiana | Simplify badges generation (#130) |
| 49e2826f | 2021-05-13 18:11:20 | Lino Galiana | Corrige quelques images n’apparaissant pas (#108) |
| 4cdb759c | 2021-05-12 10:37:23 | Lino Galiana | :sparkles: :star2: Nouveau thème hugo :snake: :fire: (#105) |
| 7f9f97bc | 2021-04-30 21:44:04 | Lino Galiana | 🐳 + 🐍 New workflow (docker 🐳) and new dataset for modelization (2020 🇺🇸 elections) (#99) |
| d164635d | 2020-12-08 16:22:00 | Lino Galiana | :books: Première partie NLP (#87) |
Notes de bas de page
We use the term bigrams for two-word co-occurrences, trigrams for three-word ones, etc.↩︎
Citation
BibTeX
@book{galiana2025,
author = {Galiana, Lino},
title = {Python pour la data science},
date = {2025},
url = {https://pythonds.linogaliana.fr/},
doi = {10.5281/zenodo.8229676},
langid = {fr}
}
Veuillez citer ce travail comme suit :
Galiana, Lino. 2025. Python pour la data science. https://doi.org/10.5281/zenodo.8229676.